
논문에서 소개된 모델 아키텍처의 사용법을 간단히 정리하여 소개하는 포스팅입니다.
Introduction
지난 Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data 논문에서는 정형 데이터를 위한 Neural Oblivious Decision Ensembles (NODE) 아키텍처를 소개하였습니다. NODE 아키텍처는 oblivious decision trees의 앙상블을 일반화하며, gradient 기반의 end-to-end 방식과 multi-layer hierarchical representation learning의 장점을 모두 활용하였습니다.
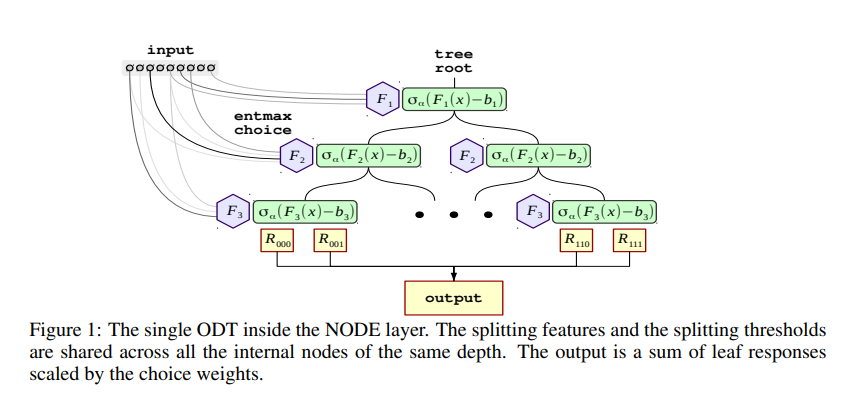
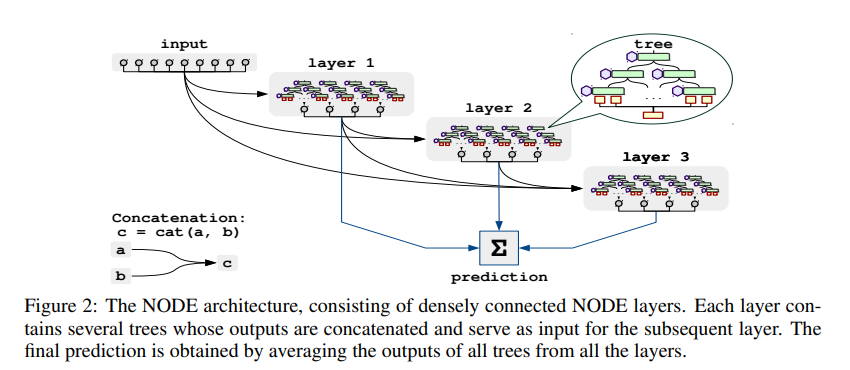
이번 포스팅에서는 pytorch_tabular 라이브러리를 통해 정형 데이터를 위한 NODE 아키텍처의 사용 방법에 대해 간단히 알아보겠습니다.
사용한 데이터셋은 Adult 데이터셋입니다. 다음과 같은 특징을 가집니다.
- 이진 분류 문제 (소득이 50K 이상인지 판별)
- 숫자형 특성과 범주형 특성이 모두 존재
모든 코드는 Google의 Colaboratory(Colab) 에서 구현되었습니다.
Setting
구현에 필요한 패키지를 설치합니다. Colab의 특성상 아래 !pip 코드 블럭을 실행한 후, 런타임을 다시 시작한 뒤 처음부터(!pip 부터) 실행해야 합니다.
# pytorch_tabular: NODE
!pip install -U pytorch_tabular[extra]
!pip install -U pytorch_tabularimport pandas as pd
import numpy as np
import os
import random
import torch
import warnings
warnings.filterwarnings(action='ignore')
from sklearn.model_selection import train_test_split
from sklearn.model_selection import ParameterGrid
from copy import deepcopy
from rich.progress import Progress
from pytorch_tabular import TabularModel
from pytorch_tabular.models import NodeConfig
from pytorch_tabular.config import DataConfig, OptimizerConfig, TrainerConfig
from pytorch_tabular.models.common.heads import LinearHeadConfigdef seed_everything(seed = 21):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = Truedef read_split_data():
df = pd.read_csv('/content/drive/MyDrive/Data/adult.csv')
df.income = np.where(df.income=='>50K', 1, 0)
X = {}
y = {}
X['train'], X['test'] = train_test_split(df, test_size = 0.10, random_state=21)
X['train'], X['val'] = train_test_split(X['train'], test_size = 0.10, random_state=21)
return XRun
seed_everything()
X = read_split_data()
cat_index = X['train'].select_dtypes(['object']).columns.to_list()
num_index = X['train'].select_dtypes(['int64']).columns.to_list()[:-1]
target = ['income']간단한 예시를 위해 데이터에 별다른 전처리를 수행하지 않았습니다. 논문에서는 안정적인 학습과 빠른 수렴을 위해 사이킷런의 quantile transform을 적용하였습니다.
각종 Config를 설정합니다. 10 에포크만 훈련합니다.
data_config = DataConfig(target=target,
continuous_cols=num_index,
categorical_cols=cat_index)
trainer_config = TrainerConfig(batch_size=64,
max_epochs=10,
accelerator='gpu',
early_stopping='valid_loss',
early_stopping_mode ='min',
early_stopping_patience=8,
checkpoints='valid_loss',
checkpoints_mode='min',
checkpoints_path='Node_Best',
load_best=True,
seed=21)
# 논문에서는 Quasi-Hyperbolic Adam 사용
optimizer_config = OptimizerConfig(optimizer='Adam',
optimizer_params={'weight_decay': 1e-5},
lr_scheduler=None)
head_config = LinearHeadConfig(layers="", # No additional layer in head, just a mapping layer to output_dim
dropout=0.1,
initialization="kaiming").__dict__ # Convert to dict to pass to the model config
model_config = NodeConfig(task='classification',
head='LinearHead',
head_config=head_config,
learning_rate=1e-3,
num_layers=2,
num_trees=1024,
depth=6,
additional_tree_output_dim=3,
choice_function='entmax15',
bin_function='entmoid15',
input_dropout=0.0,
embed_categorical=True,
embedding_dropout=0.1)
tabular_model = TabularModel(data_config=data_config,
model_config=model_config,
optimizer_config=optimizer_config,
trainer_config=trainer_config)
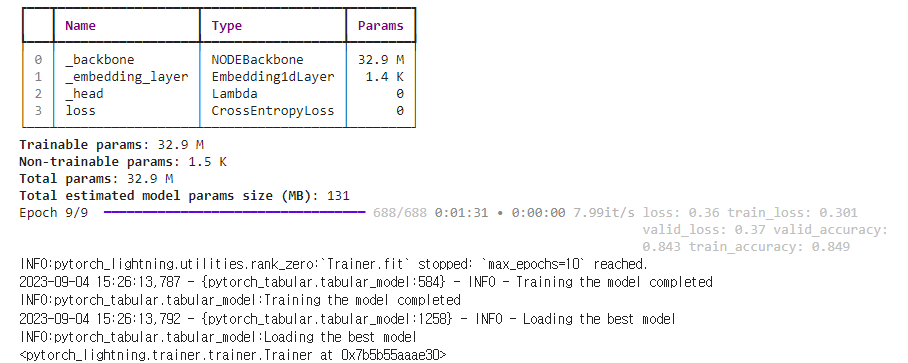
tabular_model.fit(train=X['train'],
validation=X['val'])출력
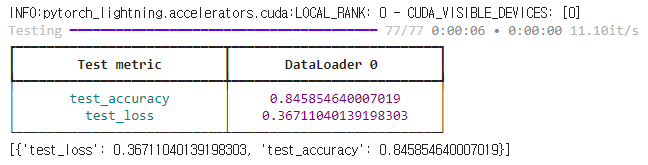
tabular_model.evaluate(X['test'])출력
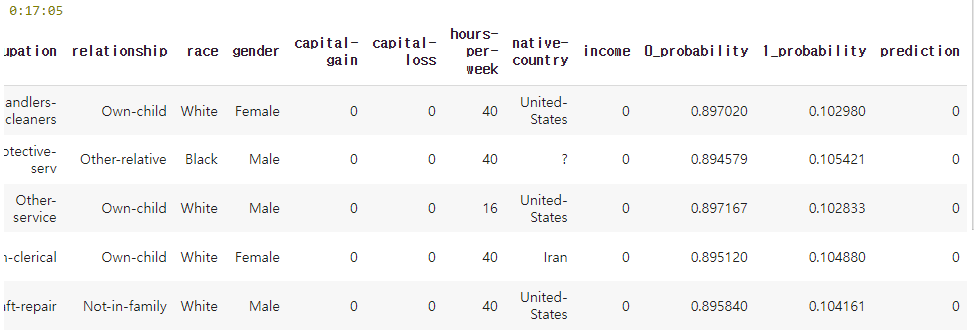
pred_df = tabular_model.predict(X['test'])
pred_df.head()출력
Tuning
사이킷런의 ParameterGrid를 사용하여 그리드 서치를 수행합니다. 하이퍼파라미터 방법은 pytorch_tabular의 github를 참고하였습니다.
seed_everything()
X = read_split_data()
cat_index = X['train'].select_dtypes(['object']).columns.to_list()
num_index = X['train'].select_dtypes(['int64']).columns.to_list()[:-1]
target = ['income']
results = []data_config = DataConfig(target=target,
continuous_cols=num_index,
categorical_cols=cat_index)
# 하이퍼파라미터 튜닝 방법 확인을 위해 간단히 5 에포크만 훈련
trainer_config = TrainerConfig(batch_size=64,
max_epochs=5,
accelerator='gpu',
early_stopping='valid_loss',
early_stopping_mode ='min',
early_stopping_patience=8,
checkpoints='valid_loss',
checkpoints_mode='min',
checkpoints_path='Node_Best',
load_best=True,
seed=21)
optimizer_config = OptimizerConfig(optimizer='Adam',
optimizer_params={'weight_decay': 1e-5},
lr_scheduler=None)
head_config = LinearHeadConfig(layers="",
dropout=0.1,
initialization="kaiming").__dict__
model_config = NodeConfig(task='classification',
head='LinearHead',
head_config=head_config,
learning_rate=1e-3,
num_layers=1,
num_trees=512,
depth=6,
additional_tree_output_dim=3,
choice_function='entmax15',
bin_function='entmoid15',
input_dropout=0.0,
embed_categorical=True,
embedding_dropout=0.1)
tabular_model = TabularModel(data_config=data_config,
model_config=model_config,
optimizer_config=optimizer_config,
trainer_config=trainer_config)
datamodule = tabular_model.prepare_dataloader(train=X['train'], validation=X['val'], seed=21)
model = tabular_model.prepare_model(datamodule)
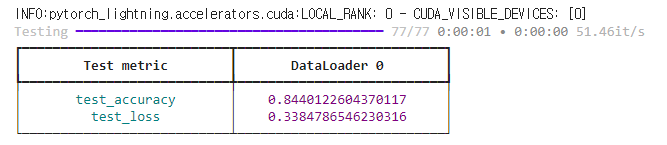
tabular_model.train(model, datamodule)출력

result = tabular_model.evaluate(X['test'])
result = result[0]
result["Type"] = "UnTuned"
results.append(result)출력
# Define the Grid
param_grid = {"model_config__num_layers": [2, 4],
"model_config__num_trees": [256],
"model_config__depth": [6],
"model_config__additional_tree_output_dim": [2, 3]}
trials = []
with Progress() as progress:
task = progress.add_task("[green]GridSearch...", total=sum(1 for _ in ParameterGrid(param_grid)))
for params in ParameterGrid(param_grid):
trainer_config_t = deepcopy(trainer_config)
optimizer_config_t = deepcopy(optimizer_config)
head_config_t = deepcopy(head_config)
model_config_t = deepcopy(model_config)
for name, param in params.items():
root, p = name.split("__")
if root == "model_config":
setattr(model_config_t, p, param)
elif root == "trainer_config":
setattr(trainer_config_t, p, param)
elif root == "optimizer_config":
setattr(optimizer_config_t, p, param)
elif root == "model_config~head_config":
model_config_t.head_config[p] = param
else:
warnings.warn(f"Unknown parameter defined. Ignoring {name}")
tabular_model_t = TabularModel(data_config=data_config,
model_config=model_config_t,
optimizer_config=optimizer_config_t,
trainer_config=trainer_config_t,)
model_t = tabular_model_t.prepare_model(datamodule)
tabular_model_t.train(model_t, datamodule)
result_t = tabular_model_t.evaluate(X['val'])[0]
params.update(result_t)
trials.append(params)
progress.update(task, advance=1)위 코드 블럭을 실행하면 param_grid에 맞게 하이퍼파라미터 탐색이 시작됩니다. 모든 경우의 수를 다 실행하고 나면 "pop from empty list" 에러가 출력되는데, 하이퍼파라미터 조합에 따른 모델 성능이 trials에 이미 저장되어 있으므로 아래 코드 블럭을 실행하면 됩니다.
trials_df = pd.DataFrame(trials)
trials_df.head()출력

# Params with lowest loss
trials_df.loc[trials_df.test_loss.idxmin()]출력
model_config__additional_tree_output_dim 3.000000
model_config__depth 6.000000
model_config__num_layers 2.000000
model_config__num_trees 256.000000
test_loss 0.337868
test_accuracy 0.846679
Name: 2, dtype: float64# Params with highest accuracy
trials_df.loc[trials_df.test_accuracy.idxmax()]출력
model_config__additional_tree_output_dim 2.000000
model_config__depth 6.000000
model_config__num_layers 4.000000
model_config__num_trees 256.000000
test_loss 0.346658
test_accuracy 0.846679
Name: 1, dtype: float64이상으로 NODE 아키텍처의 간단한 사용 방법에 대해 알아보았습니다. 위의 방법이 모델 성능을 위한 최적의 방법이 아닐 수 있습니다. 데이터 전처리 수행, 하이퍼파라미터 탐색 범위 수정, 모델 훈련 시 scheduler 사용 등 추가적인 방법으로 더 좋은 성능을 달성할 수도 있습니다.
해당 아키텍처에 대해 더 많은 정보를 확인하시려면 pytorch_tabular의 github를 참고해 주세요.
감사합니다.
