
본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Overview
본 포스팅에서는 Self-supervised learning을 위한 SimCLR 논문에 대해 간단히 알아봄. 원본 논문을 자세히 리뷰하는 것이 아닌, 핵심적인 개념만을 서술하므로 자세한 내용은 원본 논문을 참고.
이후 Joint Semi-supervised and Active Learning for Segmentation of Gigapixel Pathology Images with Cost-Effective Labeling 논문에서 해당 개념을 사용하니 알아두면 좋을 듯.
Self-supervised learning
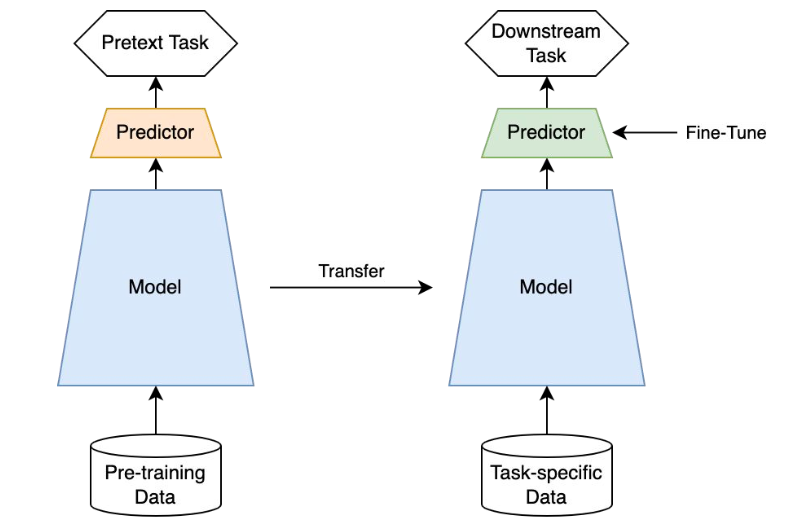
Self-supervised learning : Label이 없는 상황에서의 good initializing
[이미지 출처]
Pretext Task : 이미지의 회전 정도, 이미지 내의 직쏘 퍼즐 맞추기 등 레이블이 없는 상황에서 CNN을 훈련시키기 위한 사전 정의된 task → handcrafted task의 한계 존재
Self-supervised learning에는 Contrastive-based approaches 또한 존재하는데, SimCLR이 바로 Contrastive-based approaches.
SimCLR
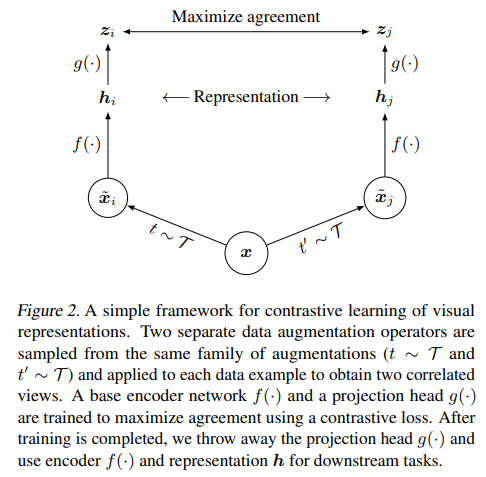
Contrastive learning이란 positive pair끼리는 같게, negative pair끼리는 다르게 구분하게 하여 모델을 학습하는 방법을 의미함.
SimCLR은 각 이미지에 서로 다른 두 data augmentation(rotation, flip 등)을 적용하여, 같은 이미지로부터 나온 결과들은 positive pair로 정의하고 서로 다른 이미지로부터 나온 결과들은 negative pair로 정의함.
Figure 2에서, 하나의 이미지 가 서로 다른 두 개의 augmentation을 거쳐 두 개의 이미지 로 나눠짐. 이렇게 변환된 두 이미지는 같은 이미지로부터 얻었기 때문에 positive pair로 정의함. 또 다른 이미지인 로부터 변환된 이미지 가 나왔다고 한다면, 과 는 서로 다른 이미지로부터 얻었기 때문에 negative pair로 정의됨 .
변환된 각 이미지는 CNN 기반의 네트워크 (논문에서는 ResNet)을 통과하여 Representation vector 로 변환되고, MLP 기반의 projection head를 거쳐 로 변환됨.
Output 를 기반으로 contrastive loss를 계산함. Loss 식은 아래와 같음. 유사도 은 으로 계산함.
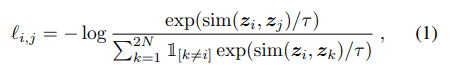
Batch size를 이라 한다면 각각 data augmentation을 거쳐서 배치마다 개의 sample을 얻을 수 있고, 각 sample 별로 한 쌍의 positive pair와 쌍의 negative pair를 얻을 수 있음. 위의 loss function은 positive pair 간의 similarity는 높이고, negative pair 간의 similarity는 최소화하도록 유도함. 해당 loss function을 NT-Xent(the normalized temperature-scaled cross entropy loss)라 명명함.
일반적으로 contrastive learning 방식으로 학습을 진행할 때, 좋은 퀄리티의 많은 negative pair가 필요하다고 알려져 있음. Batch 단위 학습이 진행되기 때문에, 많은 negative pair를 얻으려면 큰 batch size를 사용해야 함.
SimCLR은 기본적으로 4096의 batch size(총 8,192개의 sample)를 사용하였고, 빠른 학습을 위해 128코어의 google cloud TPU와 큰 크기의 batch size로 학습할 때 적절하다고 알려진 LARS optimizer를 이용하여 multi-device(분산학습)로 학습하였음.
Batch normalization을 적용할 때는 device 별로 평균과 표준 편차를 계산하여 적용하는 것이 아니라, 모든 device에서의 통계량을 집계해서 적용함. 이렇게 하면 positive sample이 포함된 device와 negative sample만으로 구성된 device들 간의 분포를 같게 normalize 하여 batch normalization 과정에서 발생하는 정보 손실을 최소화할 수 있음.
SimCLR에 대한 추가적인 정보 및 실험 결과 등은 원본 논문을 참고.
아래의 블로그를 참고하여 포스팅을 작성하였음.
https://rauleun.github.io/SimCLR
NT-Xent Loss에 대한 직관적인 설명을 보고 싶다면 아래의 블로그를 참고.
https://velog.io/@jhlee508/논문-정리-A-Simple-Framework-for-Contrastive-Learning-of-Visual-Representations
