Terabyte-scale Deep Multiple Instance Learning for Classification and Localization in Pathology
논문 정리

본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Overview
딥러닝 모델의 일반화 성능을 위해 대용량의 데이터셋은 필수적이나, 디지털 병리학의 경우 필요한 데이터를 충분히 모으기가 쉽지 않음.
하나의 WSI는 Giga-pixel 단위를 가지는 거대한 이미지이므로, WSI 자체를 CNN 모델에 바로 입력하는 것은 어려움. CNN에 입력할 수 있도록 WSI의 크기를 작게 resize 하는 방법이 있겠지만, 해상도가 작아짐에 따라 정보 손실을 피할 수 없음.
WSI를 CNN에 입력하는 또 다른 방법으로는 전체 이미지를 작은 patch(tile)로 잘라 입력하는 것임. 개별 patch는 512x512 등 모델에 입력할 수 있는 크기를 가지므로, patch-level의 classifier를 훈련시킬 수 있음.
다만 위 방법의 문제는 모델 훈련을 위해 patch-level의 label이 필요하다는 것임. 도메인 특성상 patch-level의 레이블링을 위해서는 숙련된 전문가(병리학자)가 필요하며, 하나의 WSI 당 만 개, 혹은 그 이상의 patch가 추출되므로 레이블링 작업에 많은 시간 및 비용이 소요됨.
이러한 문제 상황에서, slide-level의 label을 사용하며 patch-level의 classifier를 훈련시킬 수 있는 weak supervision - Multiple Instance Learning 기반 학습 방법론을 제안함.
Classification of a whole digital slide based on a tile-level classifier can be formalized under the classic MIL paradigm when only the slide-level class is known and the classes of each tile in the slide are unknown.
Method
MIL의 컨셉에 따라, 각 이미지 슬라이드 를 여러 개의 instance를 가지는 bag으로 생각할 수 있음. 이때, 각 bag의 instance는 WSI 내의 patch(tile)를 의미함.
양성(positive, 악성 종양이 있는 등) bag의 경우 bag에 포함된 instance 중 적어도 하나는 양성(악성 종양이 있는 patch)이며, 음성 bag의 경우 포함된 모든 instance가 음성이어야 함.
주어진 모든 bag()에 대하여, 모든 instance를 patch-level (binary) classifier에 입력하여 양성일 확률을 계산할 수 있음. 양성 bag의 경우 top-ranked instance(양성일 확률이 가장 높은 instance)의 확률 값이 1에 가까운 값이 나와야 하고, 음성 bag의 경우 top-ranked instance의 확률 값이 0에 가까워야 함.
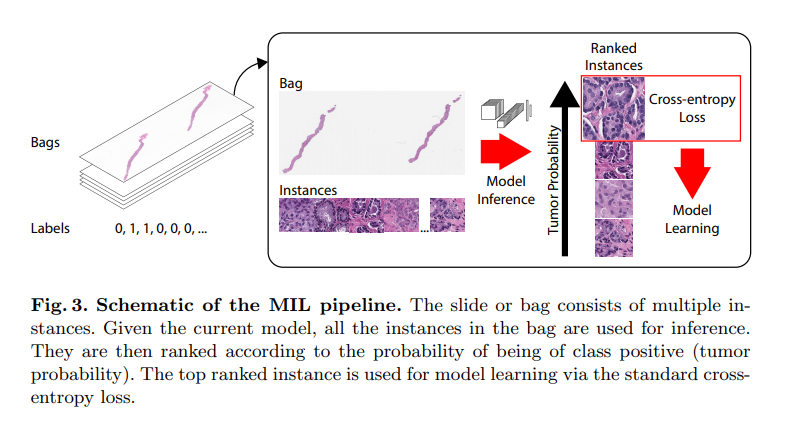
bag 의 top-ranked instance의 index를 라 할 때, 위와 같은 전제 조건을 다음의 loss function()으로 학습할 수 있음. 는 의 모든 instance (probability) score를 포함하는 list of vectors임.
loss function 은 cross-entropy 함수의 변형으로, 양성/음성 클래스의 불균형을 고려하여 가중치 을 추가하였음. 양성 클래스의 수가 훨씬 적으므로, 일반적으로 의 값을 크게 설정함. 본 논문에서는 또는 에서 좋은 결과를 얻었음.
해당 논문에서는 top rank에 속하는 하나의 patch만을 사용하여 backpropagation을 진행하였으나, 단 하나의 샘플을 기반으로 역전파를 진행하는 방법이 비효율적이라는 주장 또한 존재함→ 추가적인 조사 필요
Slide Tiling 설정 및 배율(Magnification)에 따른 성능 실험, 데이터셋의 크기에 따른 성능 감소 실험 등은 원본 논문의 나머지 부분을 참고.
