
본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Overview
본 포스팅에서는 Semi-supervised learning을 위한 FixMatch 논문에 대해 간단히 알아봄. 원본 논문을 자세히 리뷰하는 것이 아닌, 핵심적인 개념만을 서술하므로 자세한 내용은 원본 논문을 참고.
이후 Joint Semi-supervised and Active Learning for Segmentation of Gigapixel Pathology Images with Cost-Effective Labeling 논문에서 해당 개념을 사용하니 알아두면 좋을 듯.
Semi-supervised Learning
Semi-supervised learning : Exploit both labeled and unlabeled data → better performance
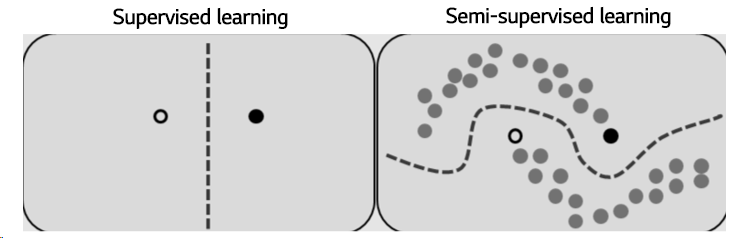
[이미지 출처]
Semi-supervised learning에서 unlabeled data를 활용하는 방법 중 하나는 pseudo labeling로, confidence가 높은 unlabeled sample의 예측 값을 pseudo label로 사용하여 labeled data로 취급함.
다른 방법으로는 consistency regularization(혹은 consistency loss)를 활용하는 방법임. Consistency loss의 개념은 데이터에 augmentation을 적용해도 모델의 출력이 동일해야 한다는 것임.
강아지 이미지를 뒤집든 아니든 모델의 출력은 “강아지”여야 함.
FixMatch
FixMatch는 pseudo labeling과 consistency regularization을 모두 활용한 semi-supervised learning 방법론임.
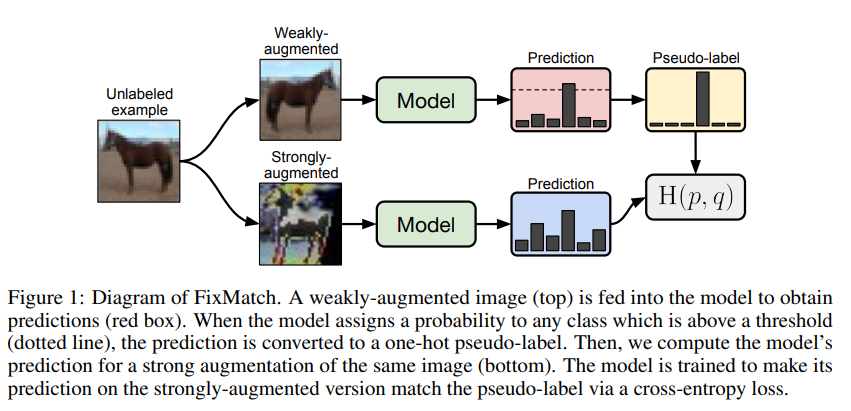
Unlabeled data에 대해, weak augmentation과 strong augmentation을 적용함.
Weak augmentation의 경우 회전 등 간단한 변형을 적용하고, strong augmentation의 경우 RandAugmentation, CTAugmentation 등 사람도 잘 알아보기 힘들 정도의 강한 변형을 적용함.
Augmentation을 적용한 unlabeled data를 모델에 입력한 후, softmax를 통과한 prediction 값을 얻음. 이후, 아래의 과정을 진행함.
- Weakly augmented에서, prediction의 최댓값이 threshold보다 클 경우 그 값을 pseudo label로 사용 (강아지 class의 prediction 값이 0.98이면, 해당 unlabeled data의 class를 “강아지”로 생각)
- Pseudo label과 strongly augmented의 prediction 값을 사용하여 cross-entropy loss 계산 (강아지를 강하게 변형시켜도 class는 강아지로 동일해야 함)
훈련 데이터셋에는 labeled data 또한 존재하므로, 아래의 수식을 통해 semi-supervised learning을 진행함.
먼저, labeled data에 대한 supervised loss를 아래와 같이 계산함.
는 label vector를 의미하며, 는 weakly augmented labeled data의 출력(확률) 값임. 는 데이터 에 weak augmentation을 적용한 것을 의미함. 즉, 는 weakly augmented labeled data에 대한 standard cross-entropy loss로 이해할 수 있음.
Unlabeled data의 경우, 아래의 loss function을 사용함.
는 unlabeled data에 weak augmentation 적용 후 모델을 통과시켜 얻은 prediction 값을 의미함. 에서 는 threshold() 보다 큰 prediction의 최댓값을 찾는 함수라고 생각하면 됨. threshold는 보통 0.8 ~ 0.95 사이의 값을 사용함.
는 기반으로 생성된 pseudo label이며, 해당 값과 strong augmentation 출력 값을 사용하여 cross entropy loss를 계산함. 는 데이터 에 strong augmentation을 적용한 것을 의미함.
이렇게 얻은 두 개의 loss 를 사용하여 final loss를 정의함.
는 0 ~ 1 사이 값이며, FixMatch의 경우 해당 값을 따로 조절할 필요가 없음.
추가적인 실험 세팅, 실험 결과 등은 원본 논문을 참고.
아래의 블로그를 참고하여 포스팅을 작성하였음.
https://gbjeong96.tistory.com/48
