
본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Introduction
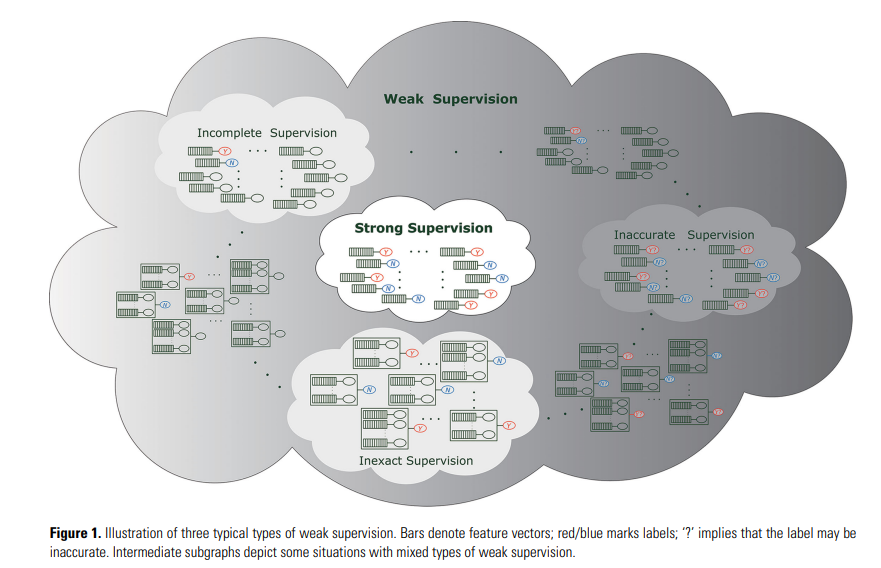
Weakly Supervised Learning(WSL)는 weak supervision 상황에서 예측 모델을 구축하는 다양한 연구를 포괄하는 용어임. 본 논문에서는 weak supervision을 크게 Incomplete supervision, Inexact supervision, Inaccurate supervision으로 구분하였음.
본 포스팅에서는 각 weak supervision의 간단한 정의 및 접근 방법에 대해서만 알아봄. 추가적인 내용은 원본 논문을 참고.
Incomplete Supervision
Incomplete supervision은 labeled data의 수가 절대적으로 부족한 상황을 의미함. 좋은 예측 모델을 학습할 만큼 labeled data가 없을 때, incomplete supervision 관련 접근 방법을 사용할 수 있음. Incomplete supervision 접근 방법에는 active learning과 semi-supervised learning 등이 있음.
Active learning에서는 oracle이라 불리는 존재를 가정하며(보통 human expert), Unlabeled instance를 oracle에게 질의(query)하여 해당 instance에 대한 ground-truth label을 얻음.
Semi-supervised learning에서는 외부(oracle 등)의 개입 없이 자동으로 unlabeled data를 활용하여 모델의 성능을 보다 향상시키고자 함.
아래의 이미지를 통해 incomplete supervision의 전체 프로세스를 확인할 수 있음.
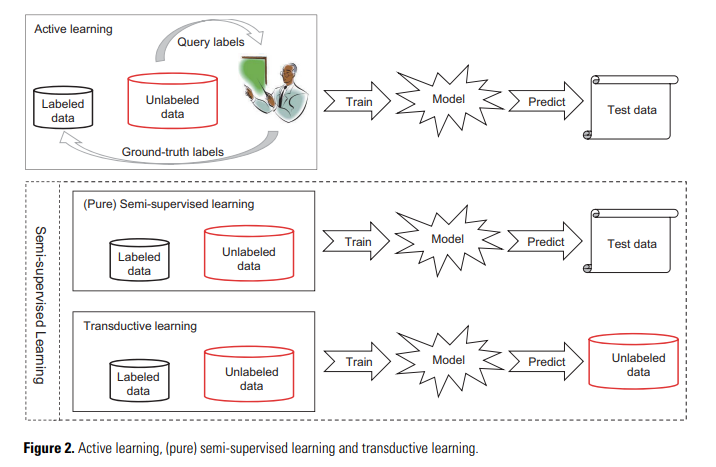
With human intervention
Active learning의 목표는 좋은 학습 모델을 만들기까지 필요한 query의 수를 최소화하는 것임.
Active learning에서는 어떤 instance를 선택하여 query 할지 결정해야 함. Unlabeled data 중 가장 가치 있는 instance를 query하며, 가치의 기준으로 informativeness와 representativeness를 사용할 수 있음.
Informativeness의 경우 해당 instance가 모델의 uncertainty를 얼마나 줄여주는지를 측정함. Instance 중 모델의 예측 값이 least confidence거나(예측 값의 분산이 큼 등), Ensemble을 사용할 경우 모델 간 예측 값 불일치가 가장 많은 instance를 선택함.
Representativeness의 경우 훈련 데이터의 분포를 가장 잘 대표할 수 있는 instance를 선택하여 query 함. Clustering 등의 기술을 활용하여 분포를 대표하는 instance를 찾을 수 있음.
Without human intervention
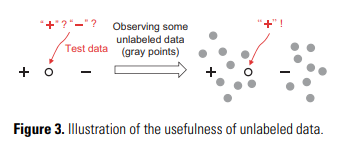
Active learning과 반대로, semi-supervised learning은 인간의 개입 없이 unlabeled data를 활용하고자 함. Semi-supervised learning에는 두 가지의 기본 가정 : Cluster assumption과 Manifold assumption이 있음.
The former assumes that data have inherent cluster structure, and thus, instances falling into the same cluster have the same class label. The latter assumes that data lie on a manifold, and thus, nearby instances have similar predictions.
Semi-supervised learning에는 크게 generative methods, graph-based methods, low-density separation methods and disagreement-based methods가 존재함.
자세한 내용은 원본 논문 참고.
Inexact Supervision
Inexact supervision은 supervision information은 주어졌지만, 원하는 만큼 정확하지 않은 경우를 의미함. 전형적인 예는 coarse-grained label 정보만 주어졌을 때임.
Coarse-grained label : 세밀하지 않은 label 정보. Object detection이나 segmentation을 수행할 때 bounding box나 pixel-level label이 아닌 image-level label만 주어진 상황 등.
Multiple Instance Learning
Inexact supervision 문제를 해결하려는 가장 대표적인 접근 방법은 Multiple Instance Learning(MIL)임. MIL의 경우 주어진 문제를 bag과 instance로 나누어, bag에 대한 예측을 수행함.

[이미지 출처]
MIL에서, 열쇠가 3개씩 있는 하나의 열쇠 꾸러미를 bag이라고 하면 열쇠 꾸러미 내의 각 열쇠를 instance라고 표현함.
MIL의 목표는 bag과 각 bag에 대한 label(문을 열 수 있는지 여부) 정보만을 가지고 새로운 bag에 대한 예측을 수행하는 것임. 위 그림에서는 문을 열 수 있는 열쇠 꾸러미에 모두 빨간색 열쇠가 존재하므로, 새로운 열쇠 꾸러미로는 문을 열 수 없을 것이라 짐작할 수 있음.
Bag과 bag에 대한 label 정보만으로 문을 열 수 있는 magic key에 대한 정보를 유추할 수 있음. 즉, bag-level label 정보만으로 instance-level의 예측 또한 가능함. 이러한 접근 방법을 기반으로 coarse-grained label 문제를 해결할 수 있음.
위에서 소개한 방법은 MIL 접근 방법 중 일부 방법만을 소개한 것입니다. 자세한 내용은 원본 논문을 참고해 주세요.
Inaccurate Supervision
Inaccurate supervision의 경우 supervision information이 항상 ground-truth가 아닌 경우를 의미함. 즉, 어떤 label 정보는 에러를 포함할 수 있음. 이러한 문제는 크라우드소싱을 활용한 labeling 작업으로 인해 발생할 수 있음.
Incomplete supervision, Inexact supervision, Inaccurate supervision을 따로따로 설명하였지만, 현실 세계에서는 이러한 문제 상황이 동시에 발생할 수 있음. 예를 들어, 적은 양의 image-level label 정보만 가지고 segmentation 모델을 학습하는 것임. 이 상황은 incomplete supervision, inexact supervision 문제가 동시에 발생함.
