본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
ABSTRACT
현재 시계열(time series)에 적용되는 딥러닝 모델은 해석하기에 너무 복잡함. 이러한 해석력(interpretability)의 부족은 의료, 자율주행 분야 등 현실 세계의 어플리케이션에서 큰 단점임. 시계열에 적용되는 모델의 설명력(explainability)은 컴퓨터 비전이나 자연어 처리 분야에 비해 큰 주목을 받지 못하였음. 본 논문에서는 시계열에 적용된 기존의 설명 가능한 인공지능(XAI) 방법의 개요를 살펴보고, 이를 통해 생성되는 설명의 유형을 설명함.
설명력(explainability), 해석력(interpretability), 해석 가능성, 설명 가능한, XAI 등은 결국 모델을 해석할 수 있다는 의미로 생각하셔도 됩니다.
INTRODUCTION
시계열 데이터는 어디에서나 존재하는 데이터이며, 시간적(temporal) 데이터에 적용할 수 있는 머신러닝 모델은 다양한 분야에 적용될 수 있음. 시계열에 적용될 수 있는 머신러닝 방법으로는 시계열 분류, 예측, 군집화 등이 있으며 이러한 작업을 수행하기 위해 딥러닝 기반의 모델을 주로 사용하였음.
시계열 데이터를 위한 딥러닝은 주로 Recurrent 기반의 네트워크와 CNN(with temporal convolution layers) 기반의 네트워크가 사용되었음. 이러한 딥러닝 네트워크는 모델의 정확도를 높이고, 이전에 수행하던 heavy한 데이터 전처리를 그만둘 수 있게 해주었음.
하지만 이러한 딥러닝 모델의 주요 단점 중 하나는 모델의 복잡성에 의한 해석력의 부족임. 의료 분야, 자율주행 분야 등 현실 세계의 어플리케이션에는 모델의 해석 가능성이 매우 중요하며, 시계열 데이터에 대한 대부분의 sota 모델은 해석 불가능하기 때문에 이는 시계열 모델의 큰 단점임. 컴퓨터 비전, 자연어 처리 분야에는 XAI에 대한 많은 연구가 이루어졌지만, 시계열 데이터에 적용할 수 있는 방법에는 아직 해야 할 일이 많이 남아있음.
시계열 데이터 설명에 대한 연구가 부족한 이유는 시계열의 직관적이지 않은 특성(한 번에 이해하기 어려움) 때문일 수 있음. 인간은 사진을 보거나 텍스트를 읽을 때 데이터에 포함된 기본 정보를 직관적이고 본능적으로 이해하지만, 시간적 데이터를 시간에 따라 변화하는 신호의 형태로 표현하는 데 익숙하지 않음. 이러한 현상은 시계열에 적용되는 XAI에 영향을 미칠 수 있으며, evaluation of explanations이 컴퓨터 비전이나 자연어 처리에 비해 질적으로 부족할 수 있음.
이러한 사항을 기반으로, 본 논문의 목적은 시계열 데이터로부터 학습된 모델의 설명력과 관련된 최신 기술을 검토하는 것임. 본 논문을 다음과 같이 요약할 수 있음.
- 시계열 데이터에 적용할 수 있는 XAI methods 개요
- 모델의 신뢰도, 안정성, 견고성을 높이는 데 사용할 수 있는 explainable methods 개요
- 시계열 데이터에 적용된 XAI의 설명 평가 방법 개요
- 시계열 데이터에 대한 최신 explainability methods, 한계와 잠재적 연구 분야 논의
XAI TERMINOLOGY AND DEFINITIONS
Purposes of explainability methods for time series
Explainability methods에는 항상 설명을 통해 달성하고자 하는 하나 이상의 목표가 존재함. 이러한 목표는 방법론의 선택, 설명의 범위 및 타겟에 따라 그 중요성이 결정됨. 잠재적 목표는 아래의 그림에서 자세히 확인할 수 있음.
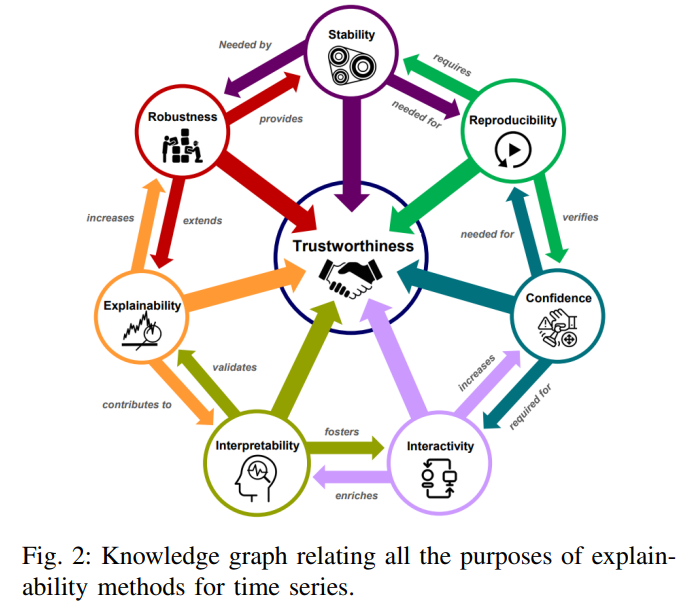
각각의 목적을 자세히 알아보면 다음과 같음.
Explainability
모델의 내부 기능을 분류하거나 설명하기 위해 모델이 취하는 모든 조치 또는 절차를 나타내는 모델의 능동적 특성. explainable AI는 모델의 기능을 명확히 이해하기 쉽도록 세부 사항이나 이유를 생성함.
Interpretability
모델이 인간에게 의미가 있는 level을 나타내는 모델의 수동적 특성. Interpretable 시스템은 사용자가 입력이 출력에 어떻게 수학적으로 매핑되는지 볼 수 있을 뿐만 아니라 연구할 수 있는 시스템을 의미함.
Trustworthiness
주어진 문제에 직면했을 때 모델이 의도한 대로 작동할지에 대한 확신. 모델이 결정에 대한 상세한 설명을 제공할 수 있을 때 신뢰를 얻을 수 있음.
Interactivity
사용자와의 상호 작용(Interactivity)은 explainable machine learning 모델의 목표 중 하나임. 이는 "사용자가 매우 중요한" 분야에서 특히 중요함.
Stability
센서의 노이즈 등 데이터 자체로 인한 노이즈와 같이 현실 세계에서 발생할 수 있는 작은 교란에 의해 모델이 현혹되지 않는다면 안정적(Stability)이라고 할 수 있음.
Robustness
사람이 의도적으로 생성했을 수 있는 교란을 견딜 수 있다면 모델은 견고(Robustness)하다고 간주됨.
Reproducibility
동일한 데이터에 대해 여러 번 실행했을 때 유사한 결과를 반복적으로 얻을 수 있다면 모델은 재현성(Reproducibility)이 있음.
Confidence
신뢰도(Confidence)는 이벤트가 실현될 확률을 뜻함. 신뢰도는 모델의 결정에 대한 신뢰를 정량화하는 것임. 논문 "White, grey, black: Effects of xai augmentation on the confidence in ai-based decision support systems."에서는 신뢰도를 "사용자가 AI 모델의 올바른 제안을 받았다고 얼마나 확신하는지에 대한 위험도 측정"으로 정의함. 예측에 대한 신뢰도가 높은 모델은 동일한 데이터 세트에서 반복적으로 실행할 때 유사한 예측을 얻을 수 있어야 하므로, 재현성이 있어야 함.
Explainability의 전체 목적은 너무 추상적이어서 스스로 해석할 수 없는 모델을 설명하는 것임. 수행해야 할 작업이 너무 복잡해서 해석 가능한 단순한 모델로 해결할 수 없거나, 너무 중요해서 이해할 수 없는 모델을 신뢰할 수 없는 특정 경우에 모델의 explainability는 특히 중요함. 복잡한 모델의 내부 동작을 설명하여 신뢰성을 제공하는 것이 이러한 문제에 도움이 될 수 있음.
XAI methods에서, 최종 사용자와의 상호 작용은 종종 무시됨. 많은 방법(method)들이 최종 사용자가 XAI를 통해 얻는 정보를 어떻게 받아들일지에 대한 고려 없이 모델 행동에 대한 인사이트를 제공함.
본 논문에서 제시되는 대부분의 방법은 시계열에 적용된 머신러닝 모델의 안정성, 견고성, 신뢰성을 보장할 수 없음. 따라서, 모델의 올바른 동작을 보장할 수 있는 평가 지표를 개발해야 할 필요성이 여전히 존재함.
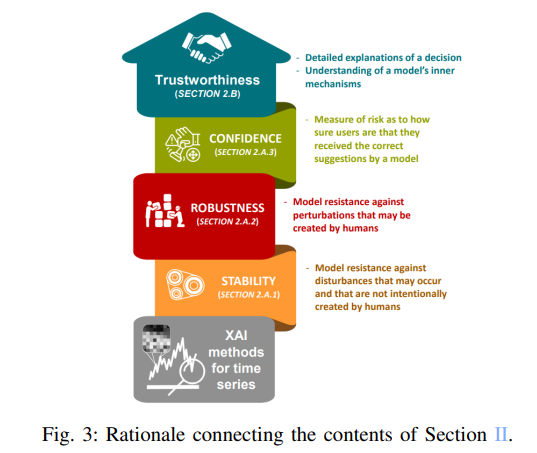
이 섹션의 남은 부분에서는 시계열 모델을 위한 XAI 방법이 시스템의 안정성, 견고성 및 신뢰성에 어떻게 기여할 수 있는지 설명하고자 함.
Stability, robustness and confidence of systems
AI 시스템이 환경에 미치는 영향의 위험성을 신중하게 평가해야 함. 자율주행 자동차를 예로 들어보면, 자율 시스템이 한 가지 잘못된 결정을 내릴 경우 보행자가 다치거나 사망할 수 있는 위험이 존재함. 이러한 작업은 매우 중요하고 위험한 작업임.
Classification 작업의 경우, AI 시스템의 품질을 인증하기 위해 정확도를 주로 사용하였음. 대부분의 경우 AI 시스템의 품질을 평가하는 데 만족스러운 인사이트를 제공하지만, 정확도에는 포함되지 않는 측면이 존재함. 예를 들어, 정확도는 입력이나 모델에 작은 교란이 가해지거나 데이터에 노이즈가 추가되었을 때 모델 출력이 변하지 않는다는 것을 증명할 수 없음. 이러한 상황은 실제 세계에서도 발생할 수 있기 때문에 정확도가 높다고 해서 시스템의 올바른 동작을 보장할 수는 없음.
수행해야 할 작업이 중요한 경우, AI 시스템이 모든 상황에서 잘 작동하는지 확인해야 하므로 추가적인 지표가 필요함. AI 시스템의 안정성, 견고성, 신뢰도에 대한 연구는 이러한 한계를 극복할 수 있는 방법이 될 수 있음.
Stability
앞서 설명하였듯, Stability는 입력이나 모델에 현실 세계에서 발생할 수 있는 작은 교란을 가해도 모델의 출력이 변하지 않는 것을 의미함. 자율주행 자동차 앞에 정지 표지판이 있다고 가정할 때, 정지 표지판의 빨간색 부분에 흰색 스티커가 붙어 있는 등 약간의 변화가 있을 수 있음.

출처 : K. Eykholt et al., "Robust Physical-World Attacks on Deep Learning Visual Classification,"
위 이미지의 출처 논문에서, 자율주행차에 배치된 모든 모델이 이러한 변형된 정지 표지판을 잘못 분류한다는 것을 확인하였음. 모델이 이를 정확하게 식별하지 못한다면, 사고로 이어질 수 있음.
입력 샘플에서 이러한 교란에 직면했을 때, 안정적인 모델은 샘플(스티커가 붙은 표지판)을 정지 신호로 정확하게 분류할 수 있어야 함. 그렇지 않다면, 적어도 발생한 상황이 비정상적이기 때문에 예측이 확실하지 않다고 시스템에 경고할 수 있어야 함.
Robustness
강건(Robustness)한 모델은 적대적 공격을 견딜 수 있는 모델로 정의됨. “Fooling a real car with adversarial traffic signs” 논문에서는 사람의 눈에 보이지 않는 노이즈를 추가하여 교통 표지판 이미지에 대한 적대적 공격을 수행하는 실험을 수행하였음. 실험 결과, 적당한 노이즈가 추가되면 자율주행차에 탑재된 모델이 수정된 이미지의 물체를 정확하게 식별하지 못하는 것으로 나타났음. 이러한 공격에 속은 모델은 견고하다고 할 수 없음.
특정 모델의 출력을 수정하기 위해 의도적으로 입력을 교란하는 또 다른 유형은 counterfactuals임. Counterfactuals "예측을 미리 정의된 출력으로 변경하는 특징값의 가장 작은 변화"로 정의할 수 있음. Counterfactuals perturbations는 수정된 샘플이 실제 세계에서 접할 수 있는 데이터의 기본 분포에 포함되어 있기 때문에 그럴듯하고 현실적임.
Confidence
AI 시스템이 공격 및 교란을 만나면 모델이 안정적이고 견고하게 유지된다는 보장을 할 수 없음. 자율주행차의 경우 시스템을 오도하여 잠재적인 사고로 이어질 수 있는 교란 또는 노이즈가 항상 존재할 수 있음. 노이즈와 교란을 처리하도록 시스템을 훈련시키는 것만으로는 시스템의 견고성과 안정성을 보장할 수 없음.
한 가지 방법은 검증 데이터셋의 다른 샘플들과 비교하여 예측 벡터가 얼마나 비정상적인지 평가하는 것임. 이를 통해 입력 데이터 분포와 거리가 먼 사례를 식별할 수 있으며, 모델이 확신을 가지고 분류할 수 없는 샘플을 식별할 수 있음. 이런 방법을 통해 예측에 대한 모델 결정 신뢰도와 관련된 점수를 계산할 수 있으며, 임계값을 정의하여 모델 신뢰도 점수가 이 임계값보다 낮으면 모델이 판단을 내리지 못하도록 할 수 있음.
일반적으로 불확실성(uncertainty)은 두 가지 범주, aleatoric uncertainty와 epistemic uncertainty로 분류할 수 있음. Aleatoric uncertainty는 동일한 실험을 여러 번 수행할 때 발생할 수 있는 위험으로 인해 결과가 달라질 수 있는 불확실성임. Epistemic uncertainty는 제한된 데이터와 지식으로 인해 발생함. 이는 모델이 입력 데이터의 분포와 거리가 먼 샘플을 접하거나 difficulty extrapolating을 수행할 때 발생함. 본 논문에서는 epistemic uncertainty에 초점을 맞춤.
User Trust
신뢰도와 견고성은 기술적 고려 사항으로 접근할 수 있지만, 사용자의 신뢰는 객관적인 지표가 아닌 다른 방법으로도 구축할 수 있음. AI 시스템에 대한 사용자의 신뢰는 주관적, 객관적으로 정의될 수 있음.
사용자와 AI 시스템 간의 상호작용은 자동화된 시스템과 사용자 간의 신뢰를 구축하는 핵심이 될 수 있음. 신뢰가 없으면 사용자는 특히 중요한 작업을 수행할 때 자동화 시스템을 신뢰하지 않을 것임. 예를 들어, 자율 주행에서 AI 시스템은 차량의 자율성에 대한 사용자의 신뢰 부족으로 어려움을 겪음. 자동화된 시스템이 특정 작업을 수행한 이유를 설명하는 피드백이 부족하여 이러한 어려움을 겪을 수 있음. 이러한 상호 작용은 반자동 시스템에서 특히 중요함.
이러한 상호작용은 AI가 사용자 또는 비즈니스 이해관계자와 대립할 때 특히 중요함. 사용자는 AI의 예측에 동의하지 않는 이유를 찾을 것이고, 따라서 사용자는 시스템의 결점을 찾거나 AI를 통해 새로운 것을 배울 수 있음. 이러한 과정은 AI 시스템과 사용자 간의 적절한 피드백과 상호 작용 없이는 달성할 수 없음. 상호작용에 의한 피드백이 없다면 운전자가 차량의 자율성에 운전 제어를 맡기는 것에 관련된 불확실성과 위험을 감당할 가능성은 거의 없을 것임.
한 가지 중요한 문제는 사용자에게 효율적인 상호작용과 피드백을 제공하는 방법임. 행동 후가 아닌 행동 전에 설명을 제공하면 자율 시스템에 대한 신뢰가 높아질 수 있음. 시스템이 수행할 동작을 사용자에게 설명하기 위해서는 동작이 수행되는 이유와 수행되는 방법을 설명하는 것이 적절할 것임.
반자율(semi-automated) 주행 시스템에서는 운전자에게 자율주행차가 해당 작업을 수행할지 여부를 결정할 수 있는 옵션을 제공하면 단순한 설명 제공 이상의 신뢰를 얻을 수 있음. 또한, 인간이 오류를 발견할 때마다 시스템을 수정할 수 있는 가능성을 제공함으로써 인간에서 시스템으로 피드백을 제공할 수도 있음. 이는 사용자와 시스템 모두의 개선으로 이어지는 협업적 탐색의 한 예가 될 수 있음.
AI와 인간 간의 상호작용에 관한 모든 연구는 인간 중심적이어야 함. "Living with complexity"에서 저자는 "우리가 바라는 방식이 아니라 사람들이 실제로 행동하는 방식에 맞게 기술을 설계해야 한다"고 주장하였음. 여기에는 포용성 및 접근성과 관련된 개념이 포함되며, 이는 FAT 및 FATE AI(Fairness, Accessibility, Transparency, Ethics)와 관련이 있음. 피드백에 대한 인간의 반응과 시스템과의 상호작용을 분석하여 지속적인 학습을 유도하고, 시스템에 대한 신뢰와 수용성을 높이는 상호작용 시스템을 점진적으로 설계해야 함.
시계열에 적용되는 설명 가능한 방법의 대부분은 개발자를 위한 설명을 생성함. 이러한 방법은 설명 가능성의 인간적 차원(human dimension)을 고려하지 않고 모델의 기술적 측면에 초점을 맞춤. 일반적으로 다른 유형의 사용자의 경우, 설명 가능한 자동화 시스템을 설계할 때 고려해야 할 분야는 머신러닝뿐만이 아님. 예를 들어, 운전자의 심리까지 고려하는 설명이 사용자(운전자)에게 유용할 수 있음.
XAI TECHNIQUES FOR TIME SERIES
이번 섹션에서는 예측을 설명하거나 모델이 학습한 내용을 설명함으로써 ML 모델에 대한 신뢰를 높일 수 있는 explainable methods을 소개함.
첫 번째로, CNN에 적용할 수 있는 post-hoc method를 소개함. Post-hoc method은 특징(feature) 값과 예측 간의 관계를 추출하여 모델의 동작을 근사함. Post-hoc은 설명 가능성을 모델의 구조에 통합하여 학습 단계가 끝날 때 이미 설명을 제공하는 Ante-hoc과 반대되는 개념임. Post-hoc method는 모든 유형의 모델에서 사용할 수 있는 model-agnositc 방법이거나, 특정 유형의 모델에서만 사용할 수 있는 model-specific 방법일 수 있음.
다음으로 자연어 처리 등에 사용되는 RNN에 적용할 수 있는 Ante-Hoc explainability methods를 소개하고, 마지막으로 시계열에 적용할 수 있는 data mining methods, explainability through representative 방법을 소개함.
XAI for Convolutional Neural Networks
CNN(applied on time series)에 적용할 수 있는 방법은 크게 backpropagation-based methods와 perturbation-based methods로 나눌 수 있음.
Backpropagation-based methods
Backpropagation methods는 한 번의 forward pass와 backward pass를 수행하여 설명을 제공함. Backpropagation 기반 방법은 이미지에 적용된 딥러닝을 설명할 때 주로 사용되었으며, 시계열에 적용된 딥러닝에도 사용할 수 있음.
CAM(Class Activation Map)은 CNN의 예측(출력)에 가장 큰 영향을 미치는 입력 이미지 데이터의 영역을 강조하는 post-hod method임. 시계열 데이터로 생각하면, CAM은 입력 시계열에서 예측 클래스를 최대한 대표할 수 있는 하위 시퀀스를 강조함.
CAM을 사용하기 위해서는 마지막 합성곱 layer 다음에 Global Pooling Average(GAP) layer가 필요함. GAP는 개의 feature map을 개의 값으로 매핑(평균 계산)하며, 높은 activation을 가진 채널은 높은 값으로 매핑됨. 매핑된 값들은 각 가중치와 함께 dense layer with softmax activation layer로 연결됨.
개의 가중치 합계를 계산함으로써 개의 히트맵을 생성할 수 있고, 히트맵을 입력 크기에 맞게 업샘플링 하여 특정 클래스와 가장 관련성이 높은 하위 영역을 식별할 수 있음. 입력 데이터가 시계열이라면, 생성된 CAM을 클래스 활성화 맵을 입력 시계열의 크기에 맞게 업샘플링 하여 특정 클래스와 가장 관련성이 높은 하위 시퀀스를 식별함. CAM 기반 방법의 단점은 반드시 합성곱 layer 다음에 GAP layer가 있어야 한다는 것임.
다른 방법으로, 현재 입력에 대한 layer의 편미분을 계산하고 입력에 곱하는 'Gradient*Input' method가 있음. 즉, 하나의 특정 인스턴스에 대한 뉴런과 필터의 activation을 계산함. 가장 활성화된 필터에 의해 처리된 입력 시퀀스가 예측에 가장 높은 기여도를 가짐.
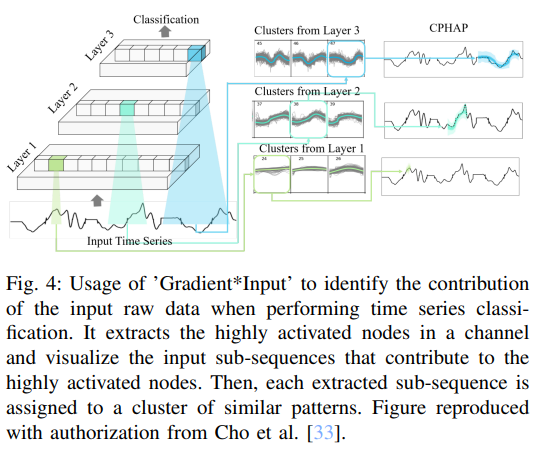
'Gradient*Input' method에는 설명을 생성하기 위해 뉴런의 activation만 필요하며, 분류와 회귀 문제 모두에 사용할 수 있음.
Perturbation-based methods
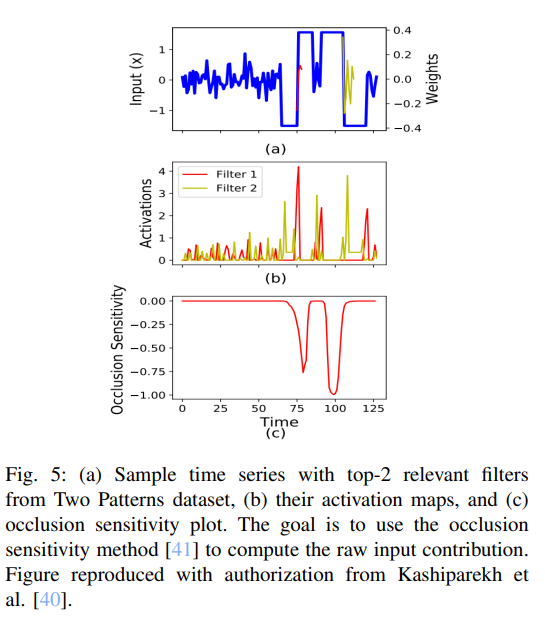
Perturbation-based methods는 원본 입력의 특성을 제거, 마스킹 또는 변경한 후 모델에 입력하고, 원본 입력과의 차이를 측정하여 입력 특성의 기여도를 직접 계산함. 원본 입력과의 차이가 클수록 변경된 입력 시퀀스의 기여도가 높다는 것을 의미함. 이론적으로, 모델의 서로 다른 출력 사이의 거리 값을 계산할 수 있다면 perturbation-based methods를 사용할 수 있음. 따라서, 해당 방법을 분류와 회귀 문제 모두에서 사용할 수 있음. 아래 이미지는 ConvTimeNet의 예시임.
XAI techniques for Recurrent neural networks
Time series와 같은 sequential 데이터를 처리하는 가장 유명한 모델은 RNN 기반의 모델임. Recurrent 모델을 설명할 수 있는 한 가지 방법은 어텐션 메커니즘을 사용하는 것임.
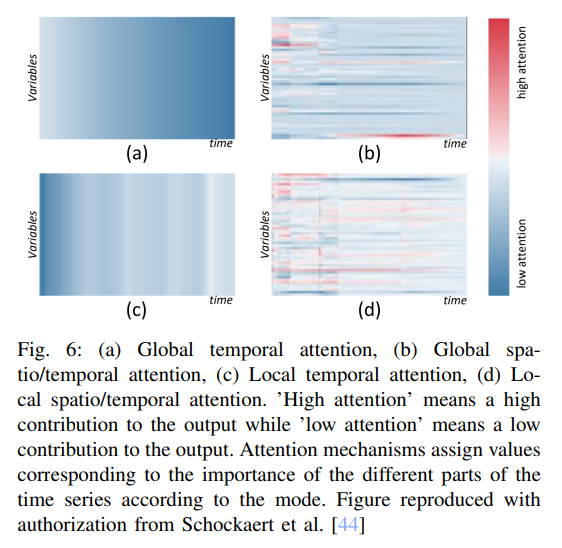
어텐션 메커니즘은 시계열의 여러 부분에 중요도에 해당하는 값을 할당함. 이는 RNN이 너무 긴 입력 시퀀스의 정보를 인코딩할 수 없는 문제를 극복하는 데 도움이 됨.
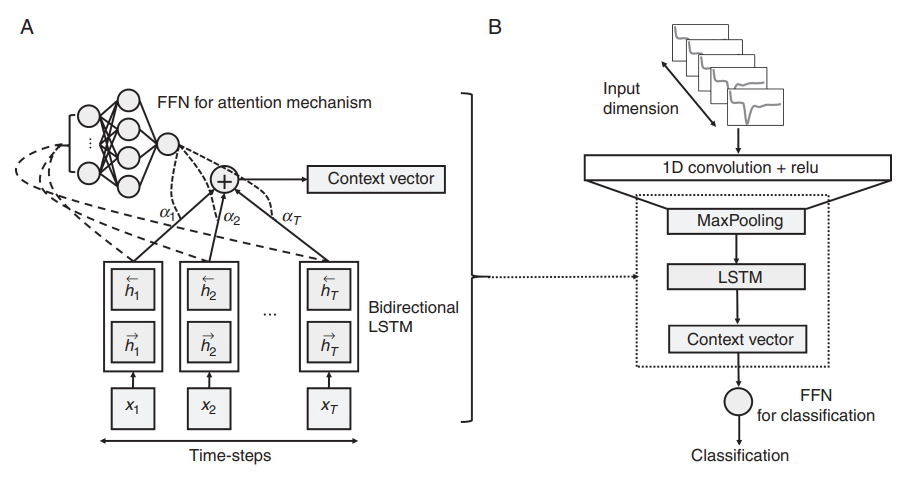
출처 : K. S. Choi, S. H. Choi, and B. Jeong, “Prediction of IDH genotype in gliomas with dynamic susceptibility contrast perfusion MR imaging using an explainable recurrent neural network,”
CNN을 feature extractor로 사용한 뒤, LSTM을 사용하여 temporal dependencies를 학습시키는 연구가 존재하였음. 학습된 LSTM의 hidden states와 output states는 피드포워드 신경망으로 입력되어 분류를 수행함. 이 피드포워드 layer의 가중치는 시계열의 다양한 time step의 중요성을 나타내는 어텐션 가중치임.
이 외에도, 각 time step의 어텐션 값을 계산하기 위해 전체 입력 시퀀스를 사용하여 더 focused attention을 계산한 연구, LSTM의 가중치에서 직접 variable attention을 계산한 연구 등이 존재하였음.
어텐션 메커니즘은 Recurrent 모델 뿐만 아니라 트랜스포머 아키텍처의 핵심으로, 트랜스포머는 시계열의 중요 변수(globally important variables)를 탐지할 수 있음.
정리하자면, 어텐션 메커니즘은 Ante-hoc methods로써, 네트워크 구조에 내장되고 학습 단계가 끝날 때 설명을 제공할 수 있음. 이는 앞서 소개한 CNN의 Post-hoc method와 대조적임. 소개한 어텐션 메커니즘 외에도, 대표적인 model-agnostic method인 SHAP(SHapley Additive exPlanations)을 사용하여 recurrent 모델의 출력을 설명하는 방법이 있음.
Data mining based XAI models
위에서 소개한 방법, 특히 CNN에 적용할 수 있는 explainability methods는 time series 뿐만 아니라 다른 도메인에도 사용할 수 있는 방법들임. 반면, 시계열 데이터에만 적용할 수 있는 explainability methods 또한 존재함. 이번 섹션에서 소개할 data mining methods가 그러함.
Time series classification을 해석하기 위한 여러 가지의 방법들이 data mining approaches를 사용하며, 몇몇은 다음 두 방법, Symbolic Aggregate Approximation(SAX)과 Fuzzy Logic을 확장한 것임.
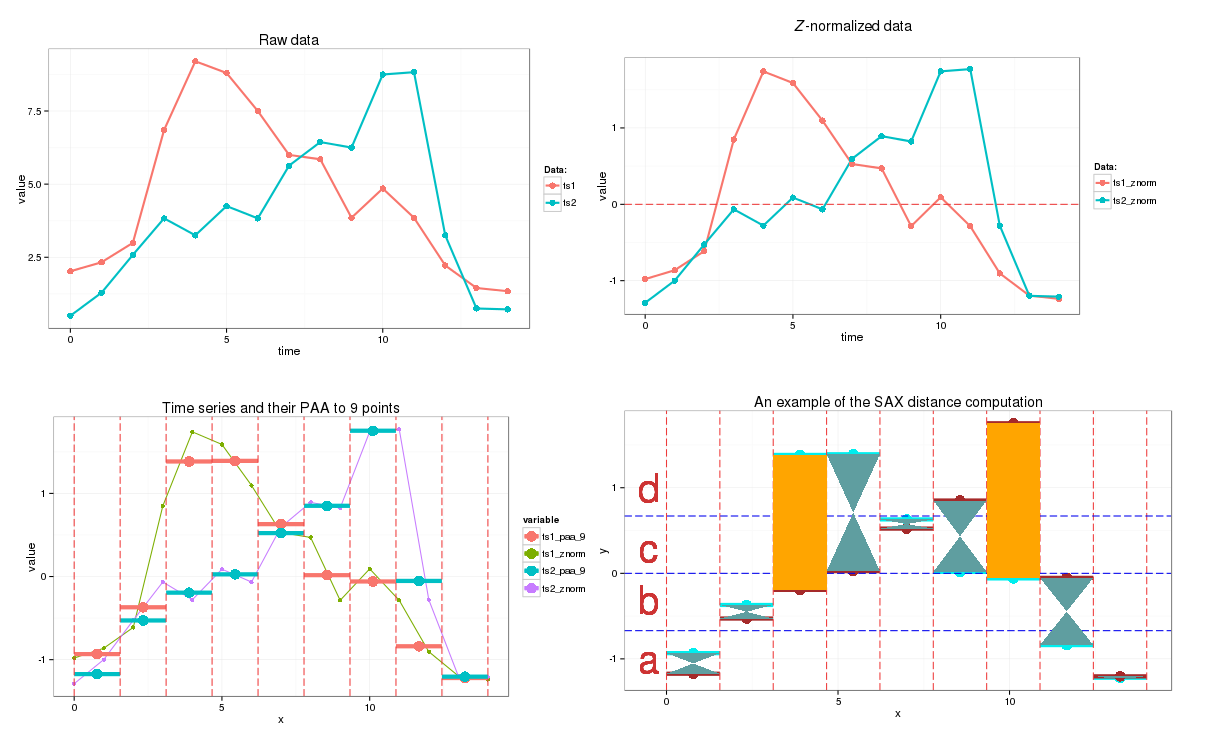
출처 : https://jmotif.github.io/sax-vsm_site/morea/algorithm/SAX.html
SAX는 입력 시계열을 문자열로 변환함. 알고리즘은 두 단계로 진행되는데, 입력 시계열을 piece-wise aggregate approximation (PAA) representation으로 변환한 후 해당 representation을 문자열로 변환함. 입력 데이터를 PAA representation으로 변환하기 위해, 시계열 데이터를 동일 사이즈의 세그먼트로 분할된 후 각 세그먼트 값의 평균을 계산함. 이후 각 세그먼트에 심볼이 할당됨.
입력 데이터가 정규분포를 따른다고 가정하면, 각 심볼은 정규분포 곡선 아래에서 동일한 크기의 영역을 가진 균등 확률에 따라 세그먼트에 할당되며 이후 입력 시계열은 심볼의 sequence로 변환됨. 이 방법은 시계열 데이터에서 발생하는 반복 패턴을 탐지하는 잘 알려진 방법임.
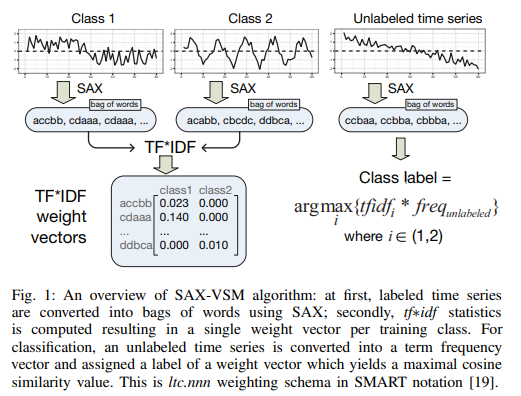
출처 : P. Senin and S. Malinchik, “Sax-vsm: Interpretable time series classification using sax and vector space model,”
SAX를 확장하여 시계열 분류를 수행한 연구가 존재함. SAX를 사용하여 raw data에서 해석 가능한 high level feature를 생성한 뒤, 각 representation의 best feature를 선택하여 성능과 해석 가능성을 모두 제공하였음. 이러한 접근 방식은 다양한 길이에 시계열에 적용될 수 있으며, 해석이 더 쉬움.
Fuzzy logic, fuzzy sets, computing the words approach는 explainability를 제공할 수 있는 다른 방법임. 이 방법들은 대략적인 추론과 모델 출력을 자연어 혹은 언어적 용어(linguistic terms)와 비슷하게 제공하는 것을 목표로 함. 어떤 면에는 인간의 사고 과정과 유사함.
Crisp rules에서는 '참' 또는 '거짓' 만이 출력으로 인정되지만, fuzzy logic에서는 0과 1 사이의 출력을 가질 수 있어 가능성의 정도를 알 수 있음. Fuzzy logic은 시계열 예측이나 숨겨진 temporal 패턴을 찾을 때 사용할 수 있으며, 신경망과 연결하여 시계열 예측 및 시계열 모델링을 수행할 수도 있음.
시계열 데이터와 텍스트 데이터를 사용하여 당뇨병을 예측하는 FRBS(fuzzy rule-based system), 다변량 시계열 예측을 위한 해석 가능한 시스템 FCM(fuzzy cognitive map), 해석 가능성을 유지하며 시계열 예측을 수행하는 neuro-fuzzy 모델 등 다양한 관련 연구가 존재함.
Explaining models through representative examples
다른 방법으로, example에 의해 설명을 제공하는 방법 또한 존재함. 이러한 방법은 훈련 데이터에서 가장 가까운 예제(example)를 제공하여 유사한 샘플의 일반적인 동작이 어떤 모습일지 설명함. 임베딩 공간에서 가장 가까운 예제를 찾기 위해 kNN 알고리즘 등을 사용할 수 있음.
시계열을 특정한 example로 설명하는 방법의 예로는 Shapelets로, 이는 클래스를 최대한 대표할 수 있는 시계열의 subsequence를 의미함.
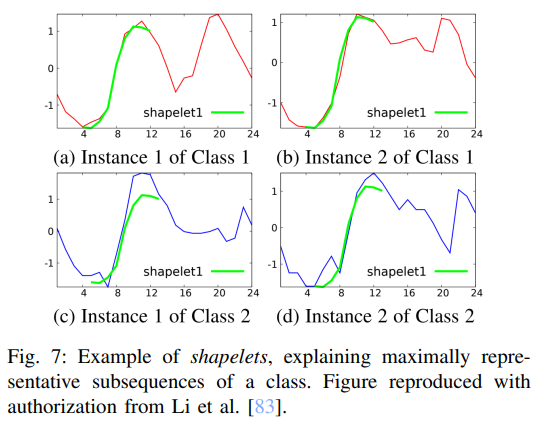
Shapelets는 당시 모델의 시계열 분류 한계를 뛰어넘기 위해 2011년에 최초로 제안되었음. Shapelets는 전통적인 시계열 분류 기법인 kNN보다 더 빠르고 정확하며 해석이 쉬움. Shapelets는 모든 subsequences 집합을 후보 shapelet과의 거리에 따라 두 개의 클래스로 분할할 때 정보 이득을 극대화하는 시퀀스로 계산됨. Shapelets 기반 방법의 한 가지 단점은 효율적인 훈련과 해석 가능성 사이에서 하나를 선택해야 한다는 것임.
모델이 보다 해석가능한(interpretable) shapelet을 학습하도록 하는 regularization term, 계산 시간을 줄이기 위한 PAA를 사용한 후보 Shapelets 도출 방법, shapelet을 찾고 시계열을 분류하는 새로운 방법(PAA, SAX 적용 등) 등 다양한 관련 연구가 존재함.
EXPLANATIONS SCALE
앞서 소개된 방법들은 local explanations과 global explanations를 제공함. 제공되는 explanations가 특정 샘플에 대해 유효한 경우 local, 샘플의 집합 또는 전체 데이터셋에 대해 유효하면 global 하다고 표현함.
Local explanations
Local explanations이란 각 설명을 샘플별로 제공하며, 한 샘플의 설명이 다른 샘플의 설명에 공유되지 않는 것을 의미함. CNN에 특화된 explainability methods는 local explanations를 주로 제공함.
Backpropagation 기반 방법은 하나의 예측에 대응되는 뉴런의 activation 값을 사용함. CAM을 예시로 들면, CAM은 마지막 convolution layer 이후 feature map의 각 채널별 평균값을 사용함. 이러한 activation 값은 매 예측마다 달라지므로, local parameter로 볼 수 있음. ConvTimeNet과 같은 perturbation 기반 방법은 입력 시계열의 sub-sequence를 변경하고, 기존 sub-sequence를 사용했을 때와 예측 값이 얼마나 달라지는지 확인함. 계산된 relevances(두 값의 차이)는 변경된 sub-sequence에 대한 값임(local explanations).
Recurrent 네트워크는 CNN과 같이 샘플 별로 예측을 수행하지만, RNN은 memory state를 가지고 있어 이전의 representation을 저장하고 있음. RNN의 latent representation은 각 예측 후 internal states가 재설정되는지 여부에 따라 하나 혹은 여러 개의 샘플을 처리할 수 있도록 설계되었음. 따라서, 이 파라미터의 선택(재설정 여부)은 RNN의 설명 범위에 영향을 미침. internal states가 하나의 인스턴스를 나타내면 local, 여러 개의 인스턴스를 나타내면 global explanations를 제공함.
Global explanations
Shapelets, SAX와 같은 방법은 데이터를 샘플 단위로 처리하지 않음. 예를 들어, candidate shapelet를 계산하는 범위는 제한되지 않아 전체 데이터셋에 대해 계산될 수 있음. 설명의 범위는 입력으로 주어진 시계열의 크기에 의해 정의됨.
몇몇 연구들은 local explanations를 사용하여 global explanations를 생성하는 방법을 제안하였음. 예를 들어, 한 클래스 내의 훈련 샘플로 CAM을 일반화하는 연구가 있음. 평균 CAM을 사용하면 클래스별 주요 판별 특징을 시각화할 수 있음.
클러스터링(군집화)를 사용하여 global explanations를 제공하는 방법 또한 존재함. backpropagation 기반 방법 Tsviz는 입력 데이터의 중요한 영역을 강조하고 주어진 예측에 대한 필터(feature map)의 중요도를 계산함. 유사한 activation 패턴을 보이는 필터는 동일한 concepts를 포착하기 때문에, activation 패턴에 따라 필터를 클러스터링하여 global insight 또한 제공함.

필터 대신 입력 시계열의 sub-sequence를 클러스터링하는 연구도 존재함. 각 클러스터는 동일한 노드를 활성화하는 temporal sequences 목록으로 구성됨. 이러한 클러스터에 불확실성이 존재하는 일반적인 시계열(테스트 데이터)을 할당함. 이는 시계열을 설명하는 하나의 방법이 될 수 있음.
PURPOSE AND INTENDED AUDIENCE OF EXPLANATIONS
Explanations의 범위는 explainability methods의 목적에 영향을 미침. Global explanations은 trustworthiness와 confidence를 제공할 수 있으며, local explanations는 예측에 대한 이유를 설명하므로 trustworthiness에 보다 집중함.
또한, 설명의 범위는 explainability methods의 대상(target)에도 영향을 미침. 머신러닝 전문가나 시스템 장애 발생 시 책임이 있는 관계자는 모델 전체의 동작을 설명하는 global explanations에 더 관심이 있을 수 있음. 반대로, 모델의 소비자는 특정 예측을 설명할 수 있는 local explanations에 더 관심이 있을 것임.
다음 섹션에서는 methods 대상에 따라 trustworthiness를 제공하는 몇 가지 방법을 소개하며, 그 다음으로 모델의 confidence를 높일 수 있는 방법을 소개함.
Providing trustworthiness through explanations for every audience
이번 섹션에서는 XAI methods를 사용하여 세 가지 대상(개발자, 의사 결정권자, 사용자)에게 trustworthiness를 제공하는 방법을 소개함.
Explanations for developers
개발자는 모델을 만드는 사람임. 지금까지 소개된 여러 방법들은 특정 도메인에 적용되는 것이 아니라, 알고리즘 또는 알고리즘 family에 초점을 맞추었음. 결과적으로 이러한 방법들이 제공하는 정보는 상당히 기술적이고 비전문가가 해석하기 어렵기 때문에, 대부분 개발자를 대상으로 함.
개발자를 위한 특정 도메인에서의 연구도 존재함. 해당 연구에서는 small x-ray diffraction time series dataset에서 분류를 수행하였으며, CAM을 사용하여 올바른 분류와 잘못된 분류의 원인을 파악하였음. 이러한 설명(CAM)은 오직 개발자에게만 흥미로울 수 있음.
일반적으로, 개발자는 예측에 대한 설명보다는 전체 모델을 설명할 수 있는 기술적 인사이트를 찾음. 따라서 개발자는 local explanations 보다는 global explanations에 관심이 많을 것임.
Explanations for end-users
사용자는 모델의 출력값을 사용함. 젊은 외과의의 수술 기술을 평가하는 시스템을 예로 들어 보면, 여기서 사용자는 숙련도에 따른 discriminative behaviors를 살펴봄으로써 스스로를 향상시키고자 하는 젊은 외과의사임. 모델이 자신을 초보자로 분류한 제스처를 식별함으로써 자신의 약점을 파악하고, 전문 외과의의 개입 없이도 스스로를 개선할 수 있는 방법을 찾을 수 있음.
의료 현장에서, 임상의는 심근경색 감지를 수행하는 방법을 사용할 수 있음. 여기서 해석 가능성은 모델 결과에 대한 확신과 신뢰를 구축하기 위해 제공됨. 실제로 이처럼 critical한 분야에서 사용자가 모델이 왜 그런 결정을 내렸는지 모른다면 모델을 신뢰할 수 없음.
일반적으로 사용자는 자신에게 영향을 미칠 수 있는 예측 또는 예측 그룹에 대한 설명을 찾음. 대부분의 경우, 사용자는 해석하기 어렵고 자신의 상황에 꼭 맞지 않을 수 있는 전체 모델에 대한 설명을 활용할 수 없음. 따라서, 사용자는 global explanations 보다는 local explanations에 관심이 많을 것임.
Explanations for decision makers
의사 결정권자는 AI에 대한 비전문가이며, 인공지능 시스템에 문제가 발생할 경우의 책임이 있음. 젊은 외과의사의 수술 기술을 평가하는 방법과 심근경색 감지 방법의 경우 의사 결정권자는 병원의 책임자임. 이들은 머신러닝 전문가는 아니지만, 시스템이 제대로 작동할 것이라는 보장이 필요함.
이들에게는 시스템 작동 방식에 대한 자세한 설명은 필요하지 않을 수 있지만, 결정에 대한 신뢰도는 필요할 수 있음. 신뢰도를 기반으로 시스템을 사용하는 것이 합리적인지, 아니면 너무 위험한지 추정할 수 있음.
Confidence
Explainable methods의 첫 번째 목적은 모델이 어떻게 작동하는지, 예측이 어떻게 이루어지는지에 대한 인사이트를 얻는 것임. 하지만, 모델이 어떻게 작동하는지 이해하는 것만으로는 충분하지 않음. 특히 critical한 작업의 경우 모델이 내린 결정에 대한 확신(Confidence)이 있어야 함. Explainable methods는 입력 분포에서 벗어난 샘플이나 적대적인 공격에 직면했을 때 모델이 더 강건하고 안정적으로 작동하도록 도울 수 있음.
아래는 시계열 데이터에 적용할 수 있는 confidence를 제공하는 XAI method임.
적대적 공격을 발견하기 위해 raw features contribution을 사용한 연구가 존재함. 해당 연구에서는 입력 시퀀스의 가장 두드러진(salient) 부분에 교란(perturbation)을 추가하여 분류 성능 변화를 확인하여 노이즈에 대한 모델의 민감도를 확인함.
특정 특성이 오분류를 일으킬 가능성을 정량화 하는 feature sensitivity 관련 연구도 있음. 해당 연구에서, 가장 두드러진(salient) 특징이 오분류를 유발할 가능성이 가장 높은 특징과 동일하며, 따라서 적의 공격에 쉽게 표적이 될 수 있다는 사실을 발견하였음. 이를 기반으로, 정확도를 크게 떨어뜨리지 않으면서 조작하기 쉬운 특성을 제거하는 방어 방법을 제안하였음.
다양한 프로토타입 학습을 위한 diversity penalty 관련 연구가 있음. Diversity penalty는 클래스 분리가 가장 어려운 잠재 공간의 영역에 집중하는 데 도움을 줌. 이는 입력 분포에서 멀리 떨어진 샘플을 분류할 때 모델이 더 안정적으로 작동하는 데 도움이 됨.
가장 두드러진 부분에 교란을 추가했던 방법과 반대로, 덜 두드러진 입력 부분에 교란을 추가하는 방법 또한 존재함. 해당 예측을 위해 덜 두드러진 입력 부분을 교란할 때 뉴런의 활성화가 더 안정적이라는 것을 기반으로 함.
Sax의 변형 overlapping interpretable Sax words의 각 문자는 최종 예측에 개별적으로 매우 작은 기여도를 가지므로, 이 방법은 노이즈에 덜 민감하게 반응함.
Adversarial Training (AT), Adversarial confidence enhanced training (ACET) 두 가지 훈련 절차를 결합한 연구도 존재함. AT는 적대적 공격에 대해 모델을 강력하게 만드는 데 더 효과적이며, ACET는 out of distribution 샘플을 처리하는 데 더 효과적임. 해당 연구에서 시각적 설명을 생성하는 방법인 RATIO를 제안하였음.
EVALUATING EXPLANATIONS
이번 섹션에선는 XAI 방법의 평가에 대해 알아봄. 제공되는 설명의 품질을 평가할 수 있는 대표적인 지표는 존재하지 않음. 이는 생성되는 설명의 특성이 다르고 입력 데이터 유형이 다르기 때문일 수 있음.
시계열 영역을 비롯한 여러 분야에서 생성된 설명의 품질을 객관적으로 평가할 수 있는 정량적 평가 접근법이 일부 존재하며, 전문가가 생성된 설명의 관련성을 평가하기 위해 정성적 평가를 수행할 수도 있음.
Qualitative evaluations
일부 방법은 생성된 설명에 대한 평가를 수행하지 않지만, 이러한 방법은 도메인 전문가를 사용하여 평가할 수 있음. 예를 들어 평균 CAM이 제공하는 글로벌 설명은 모든 로컬 특성 맵을 일일이 분석하지 않고, 각 클래스를 대표하는 모든 CAM을 평균화하여 계산한 글로벌 특성 맵을 분석하는 것만으로도 전문가에 의해 평가될 수 있음.
특정 사용자에 대한 설명을 제공하는 방법도 전문가의 피드백을 쉽게 활용할 수 있음. 의사의 수술 기술 평가를 수행하는 모델의 경우, 이를 사용하는 외과의사는 제공된 설명이 적절했는지 여부에 따라 피드백을 제공할 수 있음.
역전파 기반 접근 방식인 Tsviz는 설명의 명시성(explicitness)을 분석하여 생성된 설명의 품질을 평가함. Explicitness는 hidden representations를 클러스터링하고 이러한 hidden representations가 출력에 미치는 영향을 보여줌으로써 제공됨.
컴퓨터 비전과 달리, 시계열 분야에서는 정성적 평가는 제한적일 수 있음. 시계열의 직관적이지 않은 특성으로 인해 도메인 전문가조차도 생성된 설명의 품질을 정성적으로 평가하기 어려울 수 있음. 따라서, 시계열 분야에 대한 정량적 평가에 우선순위를 두어야 한다는 주장 또한 존재함.
Quantitative evaluations
입력 시계열 중 모델에 가장 기여도가 높은 영역을 제공하는 설명을 평가하는 방법에 관한 연구가 있음. 이 연구에서는 관련 특성이 변경되면 정확한 모델의 성능이 크게 저하될 것이라는 생각으로 데이터에 교란을 수행할 것을 제안하였음.
기여도가 높다고 제안된 특성에 대해(설명 결과), 실제로 그 특성에 교란을 넣었을 때 모델의 성능이 달라지는지 확인한다고 이해하였습니다.
Layer-wise Relevance Propagation(LRP)를 사용한 설명 평가 방법도 존재함. 특정 예측에 중요하다고 식별된 시퀀스를 점진적으로 변경하는 perturbation analysis를 진행함.
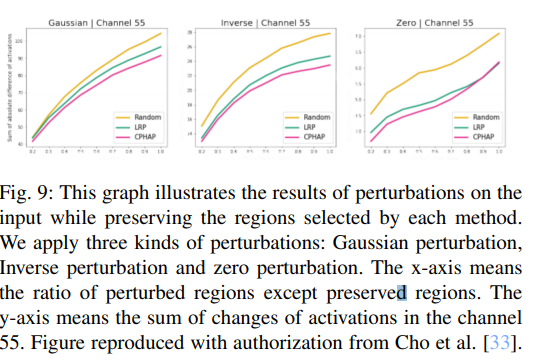
가장 중요도가 높은 필터를 제거하고 예측이 변경되는지 확인함으로써 모델의 faithfulness를 평가하는 방법 또한 존재함.
시계열의 추세나 패턴에 대한 평가가 부족한 perturbation 접근법의 한계를 극복하기 위해 두 가지 새로운 정량적 평가가 제안되었음. 해당 연구에서는 관측치 간의 상호 의존성을 고려하는 평가 방법 Swap Time Points, Mean Time Points가 제안됨. 이 두 가지 접근법은 시계열의 추세 또는 패턴을 고려할 수 있어 perturbation 기반 평가 방법과 상호 보완적임.
설명을 통해 달성하고자 하는 목표에 따라 정성적 평가와 정량적 평가가 어느 정도 적절할 수 있다는 사실을 생각할 수 있음. 사용자나 의사결정권자를 대상으로 하는 설명에는 정성적 평가가 더 적합할 수 있고, 데이터에서 새로운 예측 지식을 발견하려는 설명에는 정량적 평가가 더 적합할 수 있음.
DISCUSSION
본 논문에서 제시된 방법 중 일부는 원래 시계열이 아닌 다른 분야에 적용된 것임. 역전파 기반, perturbation 기반 방법은 컴퓨터 비전 분야를 위해 처음 설계된 후 시계열 분야에 적용된 것임. 시계열 데이터에만 적용되는 CNN을 설명할 수 있는 explainable methods는 없는 것으로 알려져 있음.
제시된 대부분의 방법은 분류(예측)가 수행되는 동안 입력 데이터의 어떤 특정 영역이 모델로부터 집중(attention)을 받는지를 나타냄. 이러한 방법은 모델에 대한 신뢰도를 제공하지 않으며 모델의 취약성을 완화하지도 않지만, 시스템에 대한 설명을 제공하고 신뢰도를 높일 수 있는 한 가지 방법이 될 수 있음. 사용자나 개발자는 모델이 특정 예측을 위해 입력의 중요한 부분에 주의를 기울인다는 것을 알면 시스템을 더 신뢰할 수 있을 것임.
컴퓨터 비전 등 쉽게 이해할 수 있는 이미지 데이터와 달리, 시계열의 직관적이지 않은 측면으로 인해 이러한 방법이 가져다주는 신뢰에 의문이 제기될 수 있음. 또한 시계열의 경우, 결과를 이해하기 위해 전문 지식이 필요할 수 있음.
Explainable methods를 통해 모델에 대한 epistemic confidence를 높일 수 있음. XAI의 목적은 모델에 대한 정보와 이해를 얻고 이를 통해 신뢰를 제공하는 것이지만, XAI 분야는 단순히 신뢰도를 높이는 것 이상의 잠재력을 가지고 있음. 설명 가능한 방법이 제공할 수 있는 인사이트를 사용하여 복잡하고 추상적인 모델의 신뢰성과 견고성을 보장하는 새로운 지표와 훈련 관행을 만들어낼 수 있음.
XAI 방법론이 기술적인 부분에만 초점을 맞추기 때문에 엔드투엔드 XAI 시스템을 구축하는 데는 아직 멀었음. AI 시스템을 신뢰하고 사용하는 데 필요한 사용자 또는 개발자와의 상호 작용을 고려하지 않으며, AI 시스템의 강건함을 입증할 수 있는 객관적인 도구가 부족함. 설명과 피드백을 제공하는 대화형 시스템이 AI 시스템 신뢰 제공에 대한 선도적인 방법이 될 수도 있음.
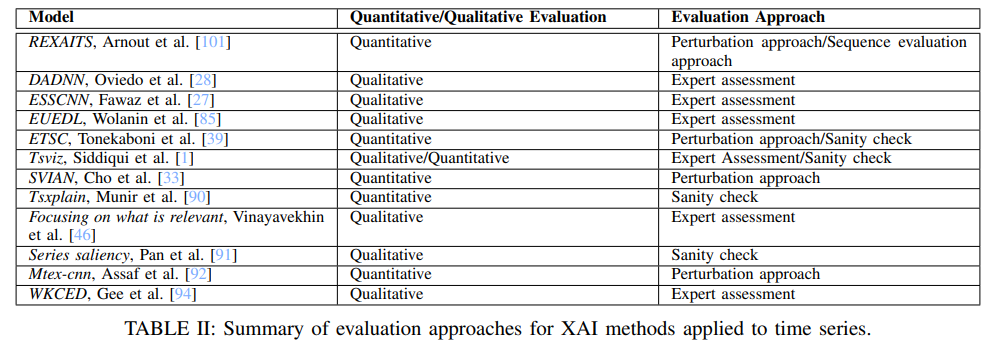
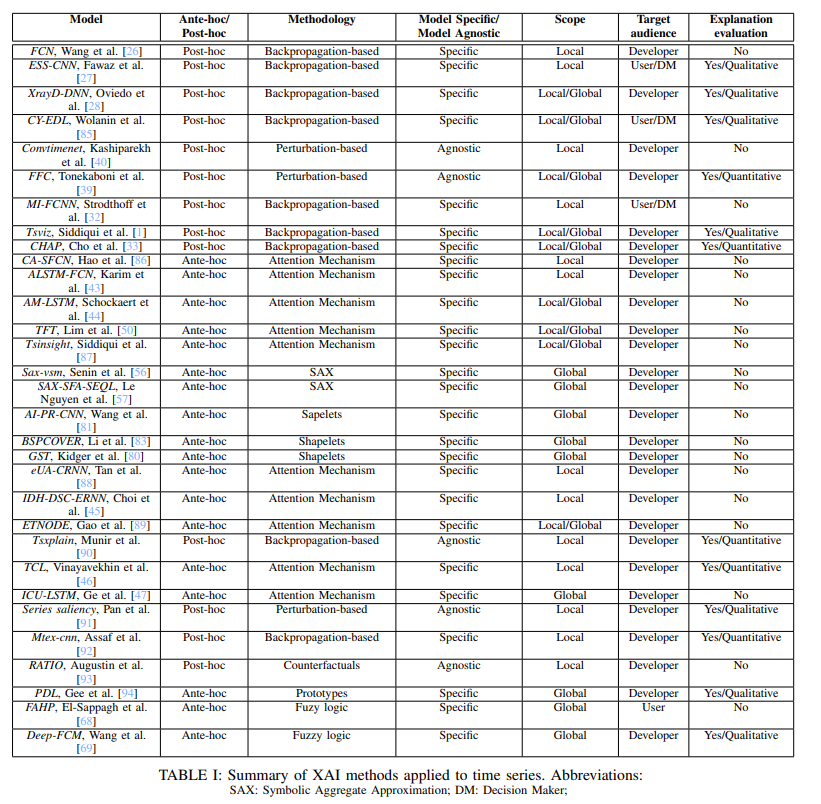
아래는 본 논문에서 소개한 XAI 방법을 정리한 것임.
아래는 본 논문에서 소개한 XAI 평가 방법을 정리한 것임.