
본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Abstract
엔진, 차량, 항공기 등과 같은 기계 장치는 일반적으로 수많은 센서로 기계의 동작과 상태를 파악함. 그러나, 센서가 포착하지 못하는 외부 요인이나 변수로 인해 본질적으로 예측할 수 없는 시계열이 발생하는 경우가 많음.
이러한 시나리오에서, stationarity에 의존하는 수학적 모델에 기반한 표준 접근 방식이나 예측 오류를 활용하는 예측 모델로는 이상 징후를 탐지하기 어려움.
본 논문에서는 이상 탐지를 위한 LSTM 네트워크 기반 Encoder-Decoder 구조(EncDec-AD)를 제안함. 해당 구조는 정상 시계열 동작을 재구성하는 방법을 학습한 후, 재구성 오류를 사용하여 이상을 탐지함.
실험을 통해, EncDec-AD는 강건하며 예측 가능한 시계열, 예측 불가능한 시계열, 주기적 시계열, 비주기적 시계열 및 준주기적 시계열에서 이상 징후를 감지할 수 있음을 확인함. 또한, 짧은 시계열(30개 정도의 길이)뿐만 아니라 긴 시계열(500개 정도의 길이)에서도 이상 징후를 탐지할 수 있음을 확인하였음.
1. Introduction
기계의 센서 데이터는 기계 동작의 변화와 외부 요인으로 인해 변화할 수 있고, 이러한 변화는 캡처하기 매우 어려움. 예를 들어, 땅을 파는 기계의 경우 기계에 가해지는 하중을 알 수 없거나, 매우 자주 혹은 갑작스럽게 변경될 수 있음.
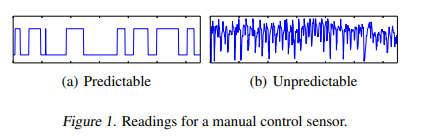
이러한 환경에서는 아주 가까운 미래에 대해서도 시계열을 예측하기가 어려워 EWMA(지수 가중 이동 평균), SVR, LSTM 등 예측 기반 시계열 이상 탐지 모델이 비효율적으로 될 수 있음.
LSTM 네트워크는 감성 분석, 음성 인식 등 많은 시퀀스 학습 작업에 사용된 모델임. 최근 기계 번역과 같은 sequence-to-sequence 학습 작업을 위해 LSTM 인코더-디코더 모델이 제안되었음.
LSTM 기반 인코더는 입력 시퀀스를 고정된 차원의 벡터 표현에 매핑하고, 디코더는 이 벡터 표현을 사용하여 목표 시퀀스를 생성하는 또 다른 LSTM 네트워크임.
본 논문에서는 다중 센서 시계열의 이상 탐지를 위한 LSTM 기반 인코더-디코더 구조(EncDec-AD)를 제안함. LSTM 기반 인코더-디코더는 입력 시계열 자체를 목표 시계열로 삼아 정상 시계열의 인스턴스를 재구성하도록 훈련됨. 그런 다음, 미래의 모든 시간 인스턴스에서 재구성 오류를 사용하여 해당 시점의 이상 가능성을 계산함.
인코더-디코더 구조는 훈련 중에 정상적인 인스턴스만 보고 이를 재구성하는 방법을 학습하였기에, 비정상적인 시퀀스가 주어지면 이를 잘 재구성하지 못할 수 있어 정상 시퀀스에 비해 더 높은 재구성 오류를 가질 수 있음.
EncDec-AD은 훈련에 정상 시퀀스만을 사용함. 이는 비정상적인 데이터를 사용할 수 없거나 희소하여 정상 및 비정상 시퀀스에 대한 분류 모델을 학습하기 어려운 시나리오에서 특히 유용함. 특히, 센서 판독값에 이상이 나타나기 전 유지보수를 받아야 하는 기계의 경우 더욱 유용함.
2. EncDec-AD
를 길이 의 시계열 데이터라고 하면, 다음과 같이 작성할 수 있음.
하나의 는 시간 에서 개의 변수를 가지는 차원 벡터임.
이러한 시계열을 여러 개 사용할 수 있거나 더 큰 시계열에 대해 길이 의 윈도우를 가져와서 얻을 수 있는 시나리오를 고려함.
먼저 정상 시계열을 재구성하기 위해 LSTM Encoder-Decoder 모델을 훈련하고, 재구성 오류를 사용하여 테스트 시계열의 한 지점이 비정상적일 가능성을 계산함. 이상 점수가 높을수록 해당 지점이 이상일 가능성이 높다는 것을 나타냄.
2.1. LSTM Encoder-Decoder as reconstruction model
정상 시계열의 인스턴스를 재구성하기 위해 LSTM 인코더-디코더를 훈련함.
LSTM 인코더는 입력 시계열의 고정 길이 벡터 표현을 학습하고, LSTM 디코더는 이 표현을 사용하여 현재의 hidden state와 이전 시간 단계에서 예측된 값을 사용하여 시계열을 재구성함.
시계열 데이터 와 함께, 는 시간 에서 인코더의 hidden state임. 인코더와 디코더는 역순으로 시계열을 재구성하도록 공동 학습됨.
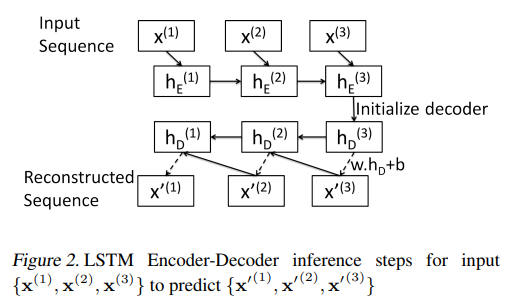
인코더의 최종 hidden state 은 디코더의 최초 입력으로 사용되며, LSTM 디코더 레이어 위에 있는 선형 레이어는 타깃을 예측하는 데 사용됨.
훈련 상태에서, 디코더는 를 입력 받아 를 계산하고 타깃 에 대응하는 를 예측함.
추론 단계에서, 디코더에 예측된 를 입력하여 와 를 계산함. 즉, 디코더의 입력으로 기존 데이터()가 아닌 이전 스텝에서 디코더에서 예측된 데이터()가 사용됨.
모델은 다음의 목적 함수 를 최소화하도록 훈련되며, 은 정상 훈련 시계열 시퀀스임.
2.2. Computing likelihood of anomaly
정상 시계열 데이터를 4개의 집합으로 구분하고, 이상 시계열 데이터를 2개의 집합으로 구분함.
은 LSTM encoder-decoder 재구성 모델을 훈련하는 데 사용됨. 은 훈련 중 조기 종료를 위해 사용됨.
시간 에서의 reconstruction error vector를 라고 하면, 에 속하는 시퀀스의 error vector들은 정규분포의 파라미터 추정에 사용됨.
이후, 추정된 파라미터를 사용하여 anomaly score 를 계산함. 계산된 가 임계값 를 넘어가면, 해당 시퀀스를 이상으로 탐지함.
매개변수 는 검증 시퀀스 에서 score를 최대로 하는 값으로 선택됨. 는 인코더의 LSTM 유닛의 수이며, score는 아래와 같음.
score는 일 때 F1 score와 동일함.
3. Experiments
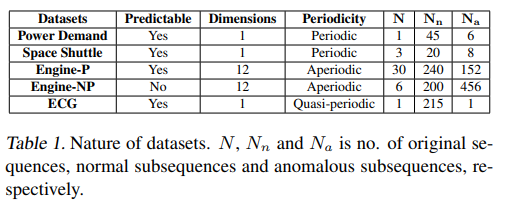
실험을 위해 power demand, space shuttle valve, ECG, engine 데이터셋을 사용함. 엔진 데이터셋에는 두 가지 애플리케이션에 대한 데이터가 포함되었는데, Engine-P는 quasi-predictable 시계열이고, Engine-NP는 예측 불가능한 시계열임.
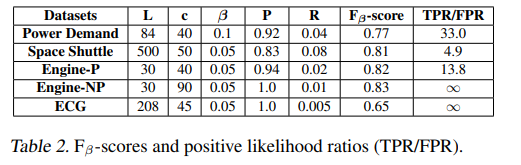
실험에서는 인코더와 디코더에 각각 개의 LSTM 유닛이 있고, hidden layer가 하나인 아키텍처를 사용함. 결과는 아래와 같음.
3.1. Datasets
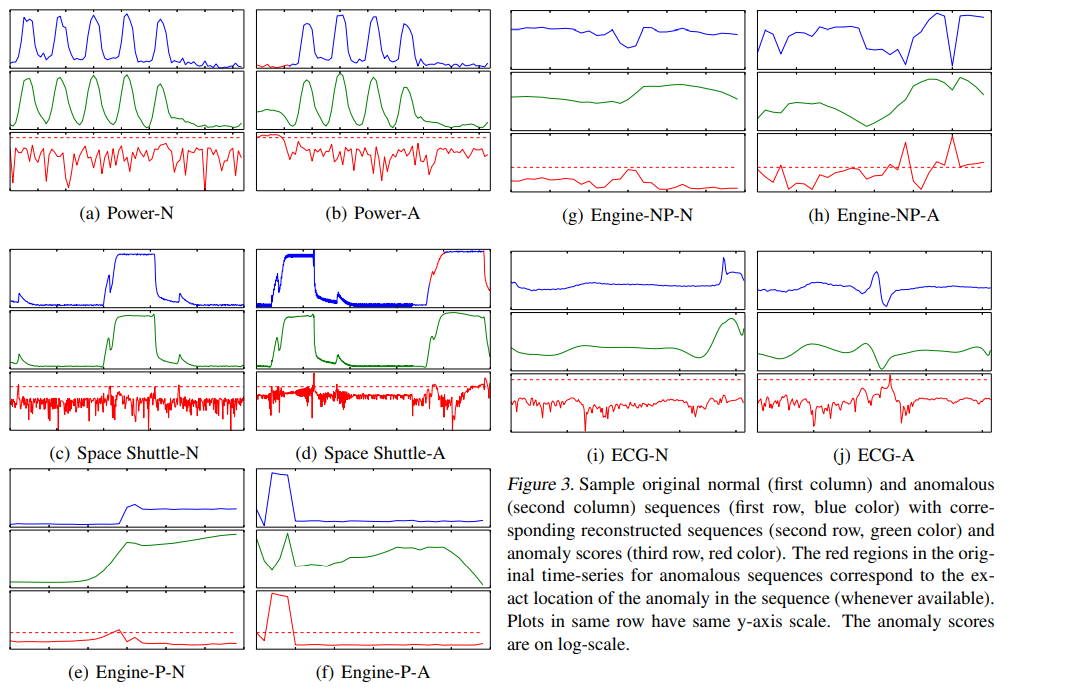
Power demand dataset
Power demand dataset은 35,040개의 샘플이 있는 단변량 시계열 데이터셋임.
전력 수요는 일반적으로 평일에 높고 주말에 낮음. 평일 하루 동안의 수요는 근무 시간에 높고, 그렇지 않으면 낮음. 첫 5일 중 어느 날이라도 전력 수요가 낮은 주(주말 수요와 유사)는 비정상적인 것으로 간주됨.
Space shuttle dataset
Space shuttle dataset은 주기당 1,000개의 포인트와 총 15개의 주기가 있는 주기적 시퀀스 데이터임.
Engine dataset
Engine dataset은 냉각수 온도, 노크, 가속기 등 12개 센서에 대한 판독값이 포함되어 있으며, 엔진의 두 가지 다른 애플리케이션을 고려함.
Engine-P에는 두 가지 상태('high', 'low')의 개별 외부 제어가 있음. 해당 시계열은 제어 변수가 변경되는 시점을 제외하고는 예측할 수 있음.
Engine-NP의 외부 제어는 특정 범위 내에서 어떤 값이라도 취할 수 있고 매우 자주 변경되므로 결과 시계열을 예측할 수 없음. 아래 그림은 Engine-P와 Engine-NP의 샘플 시퀀스임.
주성분 분석(PCA)을 적용하여 다변량 시계열을 단변량으로 축소함. 첫 번째 주성분은 Engine-P의 경우 분산의 72%, Engine-NP의 경우 61%를 설명하였음.
ECG dataset
ECG dataset은 준주기적 시계열 데이터가 포함되어 있으며, 주기 기간은 인스턴스마다 상이함.
실험에서는 심실 전 수축에 해당하는 하나의 이상 징후가 포함된 시계열이 있는 qtdb/sel102 데이터셋의 첫 번째 채널을 사용함.
3.2. Observations
실험에서 관찰한 주요 결과는 다음과 같음.
- 모든 데이터셋에서 positive likelihood ratios (TPR/FPR)이 1.0보다 훨씬 높았음. TPR/FPR이 높다는 것은 EncDec-AD가 정상 지점에 비해 비정상 지점에 대해 훨씬 높은 이상 점수를 부여한다는 것을 의미함.
- 주기적 시계열의 경우, 한 주기의 길이와 동일한 윈도우 길이, 한 주기의 길이보다 큰 윈도우 길이 등 다양한 윈도우 길이를 실험해 보았으며, 준주기적 시계열도 고려하였음. EncDecAD는 이러한 모든 시나리오에서 이상 징후를 감지할 수 있었음.
- 시계열 예측 기반 이상 탐지 모델인 LSTM-AD는 예측 가능한 데이터셋(Space Shuttle, Power and Engine-P)에 대해 더 나은 결과를 제공하였으며, EncDec-AD는 시퀀스를 예측할 수 없는 Engine-NP에서 더 나은 결과를 제공하였음.
4. Related Work
예측 오차 또는 예측 오차의 함수를 이상 징후의 척도로 사용함으로써, 시계열 예측 모델은 이상 징후 탐지에 효과적인 것으로 나타났음.
최근, LSTM-AD에서는 deep LSTM이 예측 모델로 사용되었음. 예측 모델은 정상 시계열을 학습하고 미래 시점을 예측하여 예측 오차를 이상 징후의 척도로 사용함.
EncDec-AD 전체 시퀀스에서 표현(representation)을 학습한 다음 시퀀스를 재구성하는 데 사용하므로 예측 기반 이상 감지 모델과는 차이점이 있음.
이상 탐지를 위한 denoising autoencoders, Deep Belief Nets 등 비시간적(Non-temporal) 재구성 모델들이 제안되었음. 시계열 데이터의 경우, LSTM 기반 인코더-디코더는 이러한 모델의 자연스러운 확장임.
5. Discussion
본 논문에서는 정상 시계열에 대해 학습된 LSTM 인코더-디코더 기반 재구성 모델이 시계열의 이상 징후를 감지하는 접근 방식이 될 수 있음을 확인하였음. 이러한 접근 방식은 예측 가능한 시계열뿐만 아니라 예측 불가능한 시계열에서도 이상 징후를 감지하는 데 효과적이었음.
기존의 많은 이상 탐지 모델은 시계열이 예측 가능해야 했지만, EncDec-AD는 예측할 수 없는 시계열에서도 이상 징후를 탐지하는 것으로 나타났으며, 따라서 기존 모델에 비해 더 강력한 방법이 될 수 있음.
또한, EncDec-AD가 길이가 500에 달하는 시계열에서 이상 징후를 감지할 수 있다는 사실은 LSTM 인코더가 정상 동작에 대해 강건하게 학습하고 있음을 시사함.
