
개요
양자화는 가장 일반적으로 사용되는 모델 압축 방법입니다. 양자화는 매개변수를 나타내는 데 더 적은 비트를 사용함으로써 모델 크기를 줄입니다. 기본적으로 소프트웨어 패키지는 32비트로 부동 소수점 수를 표시하는데, 이를 단정밀도 부동 소수점(FP32)이라고 합니다.
모델의 매개변수가 1억 개이고 각각을 32비트로 저장하면 400MB를 점유합니다. 이때 매개변수를 16비트로 표현하면(반정밀도, FP16) 메모리 공간을 절반으로 줄일 수 있습니다.
부동 소수점을 사용하는 대신 모델을 정수로만 구성할 수도 있습니다. 정수를 나타내는 데는 8비트만 사용합니다(고정 소수점).
이러한 양자화는 메모리 또는 계산 능력이 제한되는 모바일 기기 등 에지 디바이스에서 특히 유용합니다. 이번 포스팅에서는 TensorFlow Lite를 통해 Keras 모델을 양자화하는 방법을 간단하게 알아봅니다.
이 포스팅의 코드는 TensorFlow의 튜토리얼을 참고하였습니다. 더 자세한 내용은 해당 문서를 참고해 주세요.
TensorFlow Lite의 양자화 유형
TensorFlow Lite에서는 다음 유형의 양자화를 사용할 수 있습니다.
| 기술 | 데이터 요구 사항 | 크기 축소 | 정확성 | 지원되는 하드웨어 |
|---|---|---|---|---|
| 훈련 후 float16 양자화 | 데이터 없음 | 최대 75% | 사소한 정확성 손실 | CPU, GPU |
| 훈련 후 동적 범위 양자화 | 데이터 없음 | 최대 75% | 최소 정확성 손실 | CPU, GPU(Android) |
| 훈련 후 정수 양자화 | 레이블이 없는 대표 샘플 | 최대 75% | 적은 정확성 손실 | CPU, GPU(Android), 에지 TPU, Hexagon DSP |
| 양자화 인식 훈련 | 레이블이 지정된 훈련 데이터 | 최대 75% | 최소 정확성 손실 | CPU, GPU(Android), 에지 TPU, Hexagon DSP |
이번 포스팅에서는 양자화 인식 훈련을 적용하지 않은 모델에 훈련 후 float16 양자화, 훈련 후 동적 범위 양자화, 훈련 후 정수 양자화를 적용합니다.
Colab GPU에서 모델을 훈련한 후 동일 코드를 Colab의 CPU와 GPU에서 실행합니다. 모델 성능 및 추론 시간을 중점적으로 확인합니다.
Setting
사전 훈련된 ResNet과 CIFAR-10 데이터셋을 사용합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import time
from pathlib import Path
import keras
import tensorflow as tf
from sklearn.metrics import accuracy_score
# CIFAR-10 dataset
(X_train, y_train), (X_test, y_test) = keras.datasets.cifar10.load_data()tf.data를 사용하여 데이터셋을 정의하고, 데이터 전처리를 위한 preprocess를 적용합니다. 입력 크기를 224 x 224로 조절하고 resnet50.preprocess_input를 적용합니다.
batch_size = 64
train_set = tf.data.Dataset.from_tensor_slices((X_train, y_train))
test_set = tf.data.Dataset.from_tensor_slices((X_test, y_test))
preprocess = keras.Sequential([
keras.layers.Resizing(height=224, width=224, crop_to_aspect_ratio=True),
keras.layers.Lambda(tf.keras.applications.resnet50.preprocess_input)
])
train_set = train_set.map(lambda X, y: (preprocess(X), y)).batch(batch_size).prefetch(1)
test_set = test_set.map(lambda X, y: (preprocess(X), y)).batch(batch_size)Base Model
Train
사전 훈련된 모델을 내려받고 간단히 1 에포크만 훈련합니다.
input_shape=(224, 224, 3)를 지정하지 않아도 훈련 및 추론에 문제는 없지만, 이후 TFLite의 Interpreter에서 오류가 발생합니다. 명시적으로 입력 크기를 설정합니다.
# Transfer Learning
# ResNet50
resnet = keras.applications.ResNet50(weights="imagenet", include_top=False, input_shape=(224, 224, 3))
n_classes = 10
avg = keras.layers.GlobalAveragePooling2D()(resnet.output)
output = keras.layers.Dense(n_classes, activation="softmax")(avg)
model = keras.Model(inputs=resnet.input, outputs=output)
for layer in resnet.layers:
layer.trainable = False
optimizer = tf.keras.optimizers.Adam()
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
history = model.fit(train_set, validation_data=test_set, epochs=1)출력
782/782 [==============================] - 193s 238ms/step - loss: 0.2727 - accuracy: 0.9049 - val_loss: 0.3007 - val_accuracy: 0.8983# model save
model_name = 'Base_Model'
model_path = '/content/drive/MyDrive' / Path(model_name)
model.save(model_path, save_format="tf")Test
훈련된 keras 모델의 성능을 확인합니다. 테스트 데이터를 배치 단위로 처리하지 않고, 하나씩 예측합니다. 이후 TFLite의 모델과 동일하게 실험하기 위함입니다.
전처리 되지 않은 데이터 X_test를 모델에 입력할 수 있도록, 전처리 단계인 preprocess를 model에 추가합니다. 이렇게 하면 모델의 입력 크기와 다른 원본 입력을 별다른 전처리 없이 바로 입력할 수 있습니다.
model_name = 'Base_Model'
model_path = '/content/drive/MyDrive' / Path(model_name)
model = keras.models.load_model(model_path)
# Add preprocess
base_model = keras.Sequential([preprocess, model])실험 결과를 저장할 딕셔너리를 생성합니다. 정확도와 추론 시간을 저장합니다.
Acc_results = {'base_model': [],
'tflite': [],
'dynamic_quant': [],
'float16_quant': [],
'int_quant': []}
Time_results = {'base_model': [],
'tflite': [],
'dynamic_quant': [],
'float16_quant': [],
'int_quant': []}X_test의 500장을 모델에 입력합니다. 앞서 언급했던 것처럼 배치 단위로 처리하지 않고 하나씩 모델에 입력합니다(for x in X_test[:500]). 전체 테스트 데이터를 사용하지 않는 이유는 너무 오래 걸리기 때문입니다.
이후 TFLite 모델 또한 동일하게 한 샘플씩 입력합니다.
500장을 모델에 입력하는 과정을 5번 반복하여 평균 모델 정확도와 평균 추론 시간을 확인합니다. print() 내부의 (GPU)는 해당 코드를 Colab의 GPU에서 실행했다는 의미입니다. 아래에서 CPU 실행 결과도 확인합니다.
n_iter = 5
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in X_test[:500]:
pred = np.argmax(base_model(np.expand_dims(x, axis=0)))
y_pred.append(pred)
Acc_results['base_model'].append(accuracy_score(y_test[:500], y_pred))
end_time = time.time()
Time_results['base_model'].append(end_time - start_time)
print('Base Model Accuracy (GPU): %f' %(np.mean(Acc_results['base_model'])))
print('Base Model Inference Time (GPU): %f' %(np.mean(Time_results['base_model'])))출력
Base Model Accuracy (GPU): 0.898000
Base Model Inference Time (GPU): 52.825546
TFLite
이제 base_model를 TFLite 형태로 변환합니다.
converter = tf.lite.TFLiteConverter.from_keras_model(base_model)
tflite_model = converter.convert()
tflite_models_dir = Path("tflite_models/")
tflite_models_dir.mkdir(exist_ok=True, parents=True)
tflite_model_file = tflite_models_dir/"base_model.tflite"
tflite_model_file.write_bytes(tflite_model)출력
94049004
아래와 같이 출력 결과를 얻을 수 있습니다. 양자화는 진행되지 않습니다.
# one sample test
interpreter_tflite = tf.lite.Interpreter(model_path=str(tflite_model_file))
interpreter_tflite.allocate_tensors()
test_image = np.expand_dims(X_test[0], axis=0)
input_index = interpreter_tflite.get_input_details()[0]["index"]
output_index = interpreter_tflite.get_output_details()[0]["index"]
interpreter_tflite.set_tensor(input_index, test_image)
interpreter_tflite.invoke()
predictions = interpreter_tflite.get_tensor(output_index)
predictions출력
array([[2.6069383e-06, 6.6211354e-04, 1.3438077e-04, 9.9387336e-01,
3.2347896e-07, 5.2271276e-03, 3.4800763e-05, 2.9433845e-06,
8.4103085e-06, 5.3893800e-05]], dtype=float32)동일하게 X_test의 500장을 Interpreter에 입력합니다.
n_iter = 5
input_index = interpreter_tflite.get_input_details()[0]["index"]
output_index = interpreter_tflite.get_output_details()[0]["index"]
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in X_test[:500]:
x = np.expand_dims(x, axis=0)
interpreter_tflite.set_tensor(input_index, x)
interpreter_tflite.invoke()
output = interpreter_tflite.tensor(output_index)
pred = np.argmax(output()[0])
y_pred.append(pred)
Acc_results['tflite'].append(accuracy_score(y_test[:500], y_pred))
end_time = time.time()
Time_results['tflite'].append(end_time - start_time)
print('TFLite Accuracy (GPU): %f' %(np.mean(Acc_results['tflite'])))
print('TFLite Inference Time (GPU): %f' %(np.mean(Time_results['tflite'])))출력
TFLite Accuracy (GPU): 0.898000
TFLite Inference Time (GPU): 81.408882
훈련 후 동적 범위 양자화
동적 범위 양자화는 모델 크기를 4배로 줄입니다. 가중치가 어떻게 변화하는지 등의 자세한 내용은 TensorFlow 문서 등을 참고해 주세요.
TFLite 변환과 비슷하지만, converter.optimizations = [tf.lite.Optimize.DEFAULT]을 전달합니다.
converter = tf.lite.TFLiteConverter.from_keras_model(base_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_dynamic_quant_model = converter.convert()
tflite_model_dynamic_quant_file = tflite_models_dir/"dynamic_quant_model.tflite"
tflite_model_dynamic_quant_file.write_bytes(tflite_dynamic_quant_model)출력
23942680
입력과 출력을 전달하는 방법은 동일합니다.
n_iter = 5
input_index = interpreter_dynamic.get_input_details()[0]["index"]
output_index = interpreter_dynamic.get_output_details()[0]["index"]
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in X_test[:500]:
x = np.expand_dims(x, axis=0)
interpreter_dynamic.set_tensor(input_index, x)
interpreter_dynamic.invoke()
output = interpreter_dynamic.tensor(output_index)
pred = np.argmax(output()[0])
y_pred.append(pred)
Acc_results['dynamic_quant'].append(accuracy_score(y_test[:500], y_pred))
end_time = time.time()
Time_results['dynamic_quant'].append(end_time - start_time)
print('Dynamic Quant Accuracy (GPU): %f' %(np.mean(Acc_results['dynamic_quant'])))
print('Dynamic Quant Inference Time (GPU): %f' %(np.mean(Time_results['dynamic_quant'])))출력
Dynamic Quant Accuracy (GPU): 0.904000
Dynamic Quant Inference Time (GPU): 132.569453
훈련 후 Float16 양자화
Float16 양자화의 경우 모델 크기가 2배 감소합니다.
converter.target_spec.supported_types = [tf.float16]를 추가로 전달합니다.
converter = tf.lite.TFLiteConverter.from_keras_model(base_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_float16_quant_model = converter.convert()
tflite_model_float16_quant_file = tflite_models_dir/"float16_quant_model.tflite"
tflite_model_float16_quant_file.write_bytes(tflite_float16_quant_model)출력
47061036
n_iter = 5
input_index = interpreter_f16.get_input_details()[0]["index"]
output_index = interpreter_f16.get_output_details()[0]["index"]
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in X_test[:500]:
x = np.expand_dims(x, axis=0)
interpreter_f16.set_tensor(input_index, x)
interpreter_f16.invoke()
output = interpreter_f16.tensor(output_index)
pred = np.argmax(output()[0])
y_pred.append(pred)
Acc_results['float16_quant'].append(accuracy_score(y_test[:500], y_pred))
end_time = time.time()
Time_results['float16_quant'].append(end_time - start_time)
print('Float16 Quant Accuracy (GPU): %f' %(np.mean(Acc_results['float16_quant'])))
print('Float16 Quant Inference Time (GPU): %f' %(np.mean(Time_results['float16_quant'])))출력
Float16 Quant Accuracy (GPU): 0.898000
Float16 Quant Inference Time (GPU): 80.526897
훈련 후 정수 양자화
훈련 후 정수 양자화의 경우, 양자화를 위해 레이블이 없는 대표 샘플이 필요합니다.
def representative_data_gen():
for input_value in tf.data.Dataset.from_tensor_slices(X_train).batch(1).take(100):
yield [input_value]다음과 같이 전달하여 모델을 양자화합니다.
converter = tf.lite.TFLiteConverter.from_keras_model(base_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_int_quant_model = converter.convert()이렇게 전달하면 입력과 출력 모두 정수 형태입니다.
interpreter_int = tf.lite.Interpreter(model_content=tflite_int_quant_model)
input_type = interpreter_int.get_input_details()[0]['dtype']
print('input: ', input_type)
output_type = interpreter_int.get_output_details()[0]['dtype']
print('output: ', output_type)출력
input: <class 'numpy.uint8'>
output: <class 'numpy.uint8'>
이후 모델 추론 과정은 동일합니다.
# one sample test
interpreter_int = tf.lite.Interpreter(model_path=str(tflite_model_int_quant_file))
interpreter_int.allocate_tensors()
test_image = np.expand_dims(X_test[0], axis=0)
input_index = interpreter_int.get_input_details()[0]["index"]
output_index = interpreter_int.get_output_details()[0]["index"]
interpreter_int.set_tensor(input_index, test_image)
interpreter_int.invoke()
predictions = interpreter_int.get_tensor(output_index)
predictions출력
array([[ 0, 0, 0, 254, 0, 2, 0, 0, 0, 0]], dtype=uint8)n_iter = 5
input_index = interpreter_int.get_input_details()[0]["index"]
output_index = interpreter_int.get_output_details()[0]["index"]
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in X_test[:500]:
x = np.expand_dims(x, axis=0)
interpreter_int.set_tensor(input_index, x)
interpreter_int.invoke()
output = interpreter_int.tensor(output_index)
pred = np.argmax(output()[0])
y_pred.append(pred)
Acc_results['int_quant'].append(accuracy_score(y_test[:500], y_pred))
end_time = time.time()
Time_results['int_quant'].append(end_time - start_time)
print('Int Quant Accuracy (GPU): %f' %(np.mean(Acc_results['int_quant'])))
print('Int Quant Inference Time (GPU): %f' %(np.mean(Time_results['int_quant'])))출력
Int Quant Accuracy (GPU): 0.894000
Int Quant Inference Time (GPU): 75.647036
Overall
평균 정확도와 추론 시간을 확인하면 다음과 같습니다.
pd.DataFrame(Acc_results).boxplot(figsize=(7, 5))
plt.show()출력
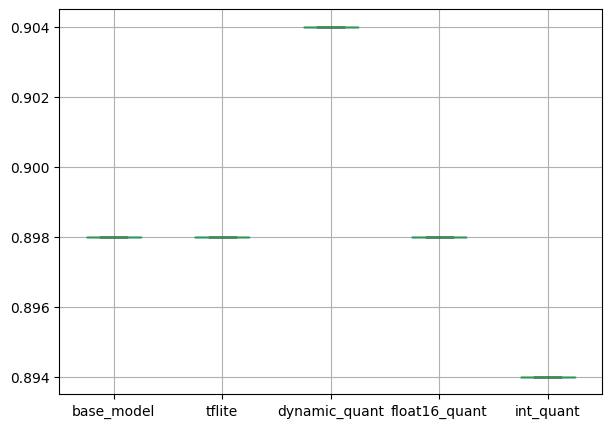
정확도에는 큰 차이가 없습니다. 모델을 경량화 및 양자화했지만, 모델 성능에 큰 영향이 있지 않습니다.
pd.DataFrame(Time_results).boxplot(figsize=(7, 5))
plt.show()출력
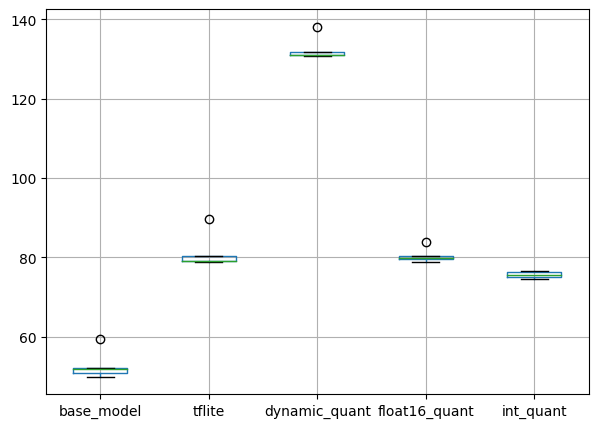
추론 시간의 경우, 기본 keras 모델이 가장 빠릅니다.
CPU
위의 과정을 Colab의 CPU에서 진행한 결과는 다음과 같습니다.
pd.DataFrame(Acc_results).boxplot(figsize=(7, 5))
plt.show()출력
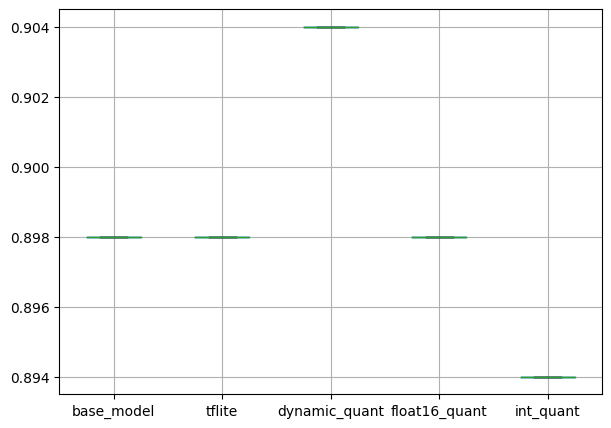
모델 정확도는 마찬가지로 별다른 차이가 없습니다.
pd.DataFrame(Time_results).boxplot(figsize=(7, 5))
plt.show()출력
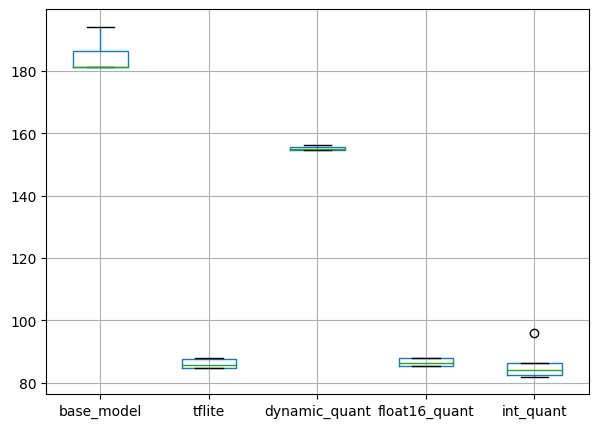
추론 속도의 경우, 경량화 및 양자화한 모델이 훨씬 빠른 것을 확인할 수 있습니다.
모델 크기 비교
저장된 모델의 크기를 확인하면 다음과 같습니다. Keras 모델 SavedModel의 경우 디렉터리로 저장됩니다.
import math
import os
def convert_size(size_bytes):
if size_bytes == 0:
return "0B"
size_name = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
i = int(math.floor(math.log(size_bytes, 1024)))
p = math.pow(1024, i)
s = round(size_bytes / p, 2)
return "%s %s" % (s, size_name[i])
def get_dir_size(path='.'):
total = 0
with os.scandir(path) as it:
for entry in it:
if entry.is_file():
total += entry.stat().st_size
elif entry.is_dir():
total += get_dir_size(entry.path)
return totalbase_model_size = get_dir_size('/content/drive/MyDrive/Base_Model')
tflite_size = os.path.getsize('/content/tflite_models/base_model.tflite')
dynamic_quant_size = os.path.getsize('/content/tflite_models/dynamic_quant_model.tflite')
float16_quant_size = os.path.getsize('/content/tflite_models/float16_quant_model.tflite')
int_quant_size = os.path.getsize('/content/tflite_models/int_quant_model.tflite')
print('Base Model Size:', convert_size(base_model_size), 'bytes')
print('TFLite Size:', convert_size(tflite_size), 'bytes')
print('Dynamic Quant Size:', convert_size(dynamic_quant_size), 'bytes')
print('Float16 Quant Size:', convert_size(float16_quant_size), 'bytes')
print('Int Quant Size:', convert_size(int_quant_size), 'bytes')출력
Base Model Size: 93.43 MB bytes
TFLite Size: 89.69 MB bytes
Dynamic Quant Size: 22.83 MB bytes
Float16 Quant Size: 44.88 MB bytes
Int Quant Size: 23.14 MB bytes
모델 크기가 22.83MB까지 작아집니다.
TFLite 및 양자화에 대한 간단한 사용 방법을 알아보았습니다. 해당 주제에 대해 깊게 공부한 것은 아니므로, 잘못된 내용이 있을 수 있습니다.
양자화 사양 및 지원되는 하드웨어 종류 등 자세한 내용은 공식 문서를 참고해 주세요.
전체 코드는 제 github에서 확인하실 수 있습니다.
감사합니다.
