
개요
지난 포스팅에서는 모델 양자화 기법 중 훈련 후 양자화 기법에 대해 알아보았습니다. 이번 포스팅에서는 TensorFlow Lite가 제공하는 양자화 인식 훈련에 대해 알아봅니다. 양자화 인식 훈련은 모델에 가짜 양자화 연산을 추가하여 훈련하는 동안 양자화 잡음을 무시하도록 학습합니다. 이렇게 하면 최종 가중치는 양자화에 더 안정적입니다.
양자화 인식 훈련을 진행한 모델에 지난 포스팅에서 알아봤던 훈련 후 동적 범위 / float16 / 정수 양자화를 적용해 보겠습니다. Colab의 CPU, GPU에서 모두 실행합니다.
이 포스팅의 코드는 TensorFlow의 튜토리얼을 참고하였습니다. 더 자세한 내용은 해당 문서를 참고해 주세요.
Setting
MNIST 데이터셋과 간단한 CNN 모델을 사용합니다.
Colab의 경우, 아래 코드를 통해 tensorflow-model-optimization를 설치합니다.
!pip install -q tensorflow-model-optimizationimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import time
import math
import os
from pathlib import Path
import keras
import tensorflow as tf
import tensorflow_model_optimization as tfmot
from sklearn.metrics import accuracy_score빠른 실행을 위해 간단한 MNIST 데이터셋을 사용합니다. 이후 훈련 후 정수 양자화를 적용해야 하므로, 모델 입력값이 모두 [0, 255] 사이에 분포하도록 255.0이 아닌 1.0으로 나누어줍니다.
이렇게 하면 train_images와 test_images는 float64 형태입니다.
# MNIST dataset
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images / 1.0
test_images = test_images / 1.0Base Model
Train
간단한 CNN 모델을 사용합니다. TensorFlow의 튜토리얼 코드를 참고하였습니다.
model = keras.Sequential([
keras.layers.InputLayer(input_shape=(28, 28)),
keras.layers.Reshape(target_shape=(28, 28, 1)),
keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation='relu'),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_images,
train_labels,
epochs=1,
validation_split=0.1,
)출력
1688/1688 [==============================] - 14s 7ms/step - loss: 1.0865 - accuracy: 0.9096 - val_loss: 0.1963 - val_accuracy: 0.9548
<keras.src.callbacks.History at 0x7c8808ff8d00>이제 훈련된 모델에 양자화 인식 훈련을 적용합니다. 양자화 인식 모델(q_aware_model)은 새로 컴파일 해야 합니다.
quantize_model = tfmot.quantization.keras.quantize_model
# q_aware stands for for quantization aware.
q_aware_model = quantize_model(model)
# `quantize_model` requires a recompile.
q_aware_model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
q_aware_model.summary()출력
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
quantize_layer (QuantizeLa (None, 28, 28) 3
yer)
quant_reshape (QuantizeWra (None, 28, 28, 1) 1
pperV2)
quant_conv2d (QuantizeWrap (None, 26, 26, 12) 147
perV2)
quant_max_pooling2d (Quant (None, 13, 13, 12) 1
izeWrapperV2)
quant_flatten (QuantizeWra (None, 2028) 1
pperV2)
quant_dense (QuantizeWrapp (None, 10) 20295
erV2)
=================================================================
Total params: 20448 (79.88 KB)
Trainable params: 20410 (79.73 KB)
Non-trainable params: 38 (152.00 Byte)
_________________________________________________________________q_aware_model.summary() 호출 결과, 각 layer 앞에 quant_가 붙었습니다.
이제 이 모델을 추가적으로 훈련합니다. 전이 학습의 fine-tuning과 유사합니다. 훈련 후 양자화와는 다르게, 추가적인 모델 훈련이 필요하므로 하드웨어 리소스의 제한이 있을 수 있습니다.
train_images_subset = train_images[0:1000] # out of 60000
train_labels_subset = train_labels[0:1000]
# fine tuning
q_aware_model.fit(train_images_subset, train_labels_subset,
batch_size=500, epochs=1, validation_split=0.1)출력
2/2 [==============================] - 8s 1s/step - loss: 0.3129 - accuracy: 0.9189 - val_loss: 0.2235 - val_accuracy: 0.9400
<keras.src.callbacks.History at 0x7c8808d5d390>기존 모델과 양자화 인식 모델의 성능을 확인해 봅니다.
_, baseline_model_accuracy = model.evaluate(
test_images, test_labels, verbose=0)
_, q_aware_model_accuracy = q_aware_model.evaluate(
test_images, test_labels, verbose=0)
print('Baseline test accuracy:', baseline_model_accuracy)
print('Quant test accuracy:', q_aware_model_accuracy)출력
Baseline test accuracy: 0.9477999806404114
Quant test accuracy: 0.9322999715805054
그렇게 큰 차이가 나지 않습니다.
Test
지난 포스팅처럼, 테스트 세트의 샘플을 하나씩 모델에 입력하여 그때의 정확도와 추론 시간을 계산합니다.
Normal_Model_Acc_results = {
'base_model': [],
'tflite': [],
'dynamic_quant': [],
'float16_quant': [],
'int_quant': []}
Normal_Model_Time_results = {
'base_model': [],
'tflite': [],
'dynamic_quant': [],
'float16_quant': [],
'int_quant': []}
Q_Aware_Model_Acc_results = {
'base_model': [],
'tflite': [],
'dynamic_quant': [],
'float16_quant': [],
'int_quant': []}
Q_Aware_Model_Time_results = {
'base_model': [],
'tflite': [],
'dynamic_quant': [],
'float16_quant': [],
'int_quant': []}전체 테스트 세트 샘플 추론을 5회 반복하여 평균 정확도와 추론 시간을 측정합니다. (GPU)는 해당 코드가 Colab의 GPU에서 실행되었음을 의미합니다. 이후 CPU 실행 결과도 확인합니다.
n_iter = 5
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in test_images:
pred = np.argmax(model(np.expand_dims(x, axis=0).astype(np.float32)))
y_pred.append(pred)
Normal_Model_Acc_results['base_model'].append(accuracy_score(test_labels, y_pred))
end_time = time.time()
Normal_Model_Time_results['base_model'].append(end_time - start_time)
print('Normal Model Accuracy (GPU): %f' %(np.mean(Normal_Model_Acc_results['base_model'])))
print('Normal Model Inference Time (GPU): %f' %(np.mean(Normal_Model_Time_results['base_model'])))출력
Normal Model Accuracy (GPU): 0.947800
Normal Model Inference Time (GPU): 38.922454
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in test_images:
pred = np.argmax(q_aware_model(np.expand_dims(x, axis=0).astype(np.float32)))
y_pred.append(pred)
Q_Aware_Model_Acc_results['base_model'].append(accuracy_score(test_labels, y_pred))
end_time = time.time()
Q_Aware_Model_Time_results['base_model'].append(end_time - start_time)
print('Q-Aware Model Accuracy (GPU): %f' %(np.mean(Q_Aware_Model_Acc_results['base_model'])))
print('Q-Aware Model Inference Time (GPU): %f' %(np.mean(Q_Aware_Model_Time_results['base_model'])))출력
Q-Aware Model Accuracy (GPU): 0.932300
Q-Aware Model Inference Time (GPU): 71.149294
양자화 적용
일반 모델과 양자화 인식 모델을 TFLite 형태로 변환합니다. 자세한 내용은 이전 포스팅을 참고합니다.
일반 모델
# TFLite
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
tflite_models_dir = Path("tflite_models/")
tflite_models_dir.mkdir(exist_ok=True, parents=True)
tflite_model_file = tflite_models_dir/"base_model.tflite"
tflite_model_file.write_bytes(tflite_model)출력
84820
# TFLite - Dynamic Quant
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_dynamic_quant_model = converter.convert()
tflite_model_dynamic_quant_file = tflite_models_dir/"dynamic_quant_model.tflite"
tflite_model_dynamic_quant_file.write_bytes(tflite_dynamic_quant_model)출력
24064
# TFLite - Float16 Quant
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_float16_quant_model = converter.convert()
tflite_model_float16_quant_file = tflite_models_dir/"float16_quant_model.tflite"
tflite_model_float16_quant_file.write_bytes(tflite_float16_quant_model)출력
44624
# TFLite - Int Quant
def representative_data_gen():
for input_value in tf.data.Dataset.from_tensor_slices(train_images.astype(np.float32)).batch(1).take(100):
yield [input_value]
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_int_quant_model = converter.convert()
tflite_model_int_quant_file = tflite_models_dir/"int_quant_model.tflite"
tflite_model_int_quant_file.write_bytes(tflite_int_quant_model)출력
24608
interpreter_tflite = tf.lite.Interpreter(model_path=str(tflite_model_file))
interpreter_tflite.allocate_tensors()
interpreter_dynamic = tf.lite.Interpreter(model_path=str(tflite_model_dynamic_quant_file))
interpreter_dynamic.allocate_tensors()
interpreter_f16 = tf.lite.Interpreter(model_path=str(tflite_model_float16_quant_file))
interpreter_f16.allocate_tensors()
interpreter_int = tf.lite.Interpreter(model_path=str(tflite_model_int_quant_file))
interpreter_int.allocate_tensors()각 Interpreter의 정확도 및 추론 시간을 확인합니다.
# TFLite
input_index = interpreter_tflite.get_input_details()[0]["index"]
output_index = interpreter_tflite.get_output_details()[0]["index"]
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in test_images:
x = np.expand_dims(x, axis=0).astype(np.float32)
interpreter_tflite.set_tensor(input_index, x)
interpreter_tflite.invoke()
output = interpreter_tflite.tensor(output_index)
pred = np.argmax(output()[0])
y_pred.append(pred)
Normal_Model_Acc_results['tflite'].append(accuracy_score(test_labels, y_pred))
end_time = time.time()
Normal_Model_Time_results['tflite'].append(end_time - start_time)
print('TFLite Accuracy (GPU): %f' %(np.mean(Normal_Model_Acc_results['tflite'])))
print('TFLite Inference Time (GPU): %f' %(np.mean(Normal_Model_Time_results['tflite'])))출력
TFLite Accuracy (GPU): 0.947800
TFLite Inference Time (GPU): 1.351541
# TFLite - Dynamic Quantization
input_index = interpreter_dynamic.get_input_details()[0]["index"]
output_index = interpreter_dynamic.get_output_details()[0]["index"]
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in test_images:
x = np.expand_dims(x, axis=0).astype(np.float32)
interpreter_dynamic.set_tensor(input_index, x)
interpreter_dynamic.invoke()
output = interpreter_dynamic.tensor(output_index)
pred = np.argmax(output()[0])
y_pred.append(pred)
Normal_Model_Acc_results['dynamic_quant'].append(accuracy_score(test_labels, y_pred))
end_time = time.time()
Normal_Model_Time_results['dynamic_quant'].append(end_time - start_time)
print('Dynamic Quant Accuracy (GPU): %f' %(np.mean(Normal_Model_Acc_results['dynamic_quant'])))
print('Dynamic Quant Inference Time (GPU): %f' %(np.mean(Normal_Model_Time_results['dynamic_quant'])))출력
Dynamic Quant Accuracy (GPU): 0.947700
Dynamic Quant Inference Time (GPU): 1.029758
# TFLite - Float16 Quantization
input_index = interpreter_f16.get_input_details()[0]["index"]
output_index = interpreter_f16.get_output_details()[0]["index"]
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in test_images:
x = np.expand_dims(x, axis=0).astype(np.float32)
interpreter_f16.set_tensor(input_index, x)
interpreter_f16.invoke()
output = interpreter_f16.tensor(output_index)
pred = np.argmax(output()[0])
y_pred.append(pred)
Normal_Model_Acc_results['float16_quant'].append(accuracy_score(test_labels, y_pred))
end_time = time.time()
Normal_Model_Time_results['float16_quant'].append(end_time - start_time)
print('Float16 Accuracy (GPU): %f' %(np.mean(Normal_Model_Acc_results['float16_quant'])))
print('Float16 Inference Time (GPU): %f' %(np.mean(Normal_Model_Time_results['float16_quant'])))출력
Float16 Accuracy (GPU): 0.948000
Float16 Inference Time (GPU): 1.086174
# TFLite - Int Quantization
input_index = interpreter_int.get_input_details()[0]["index"]
output_index = interpreter_int.get_output_details()[0]["index"]
for iter in range(n_iter):
start_time = time.time()
y_pred = []
for x in test_images:
x = np.expand_dims(x, axis=0).astype(np.uint8)
interpreter_int.set_tensor(input_index, x)
interpreter_int.invoke()
output = interpreter_int.tensor(output_index)
pred = np.argmax(output()[0])
y_pred.append(pred)
Normal_Model_Acc_results['int_quant'].append(accuracy_score(test_labels, y_pred))
end_time = time.time()
Normal_Model_Time_results['int_quant'].append(end_time - start_time)
print('Int Quant Accuracy (GPU): %f' %(np.mean(Normal_Model_Acc_results['int_quant'])))
print('Int QuantInference Time (GPU): %f' %(np.mean(Normal_Model_Time_results['int_quant'])))출력
Int Quant Accuracy (GPU): 0.947200
Int QuantInference Time (GPU): 0.912520
boxplot으로 확인해보면 다음과 같습니다.
pd.DataFrame(Normal_Model_Acc_results).boxplot(figsize=(7, 5))
plt.show()출력
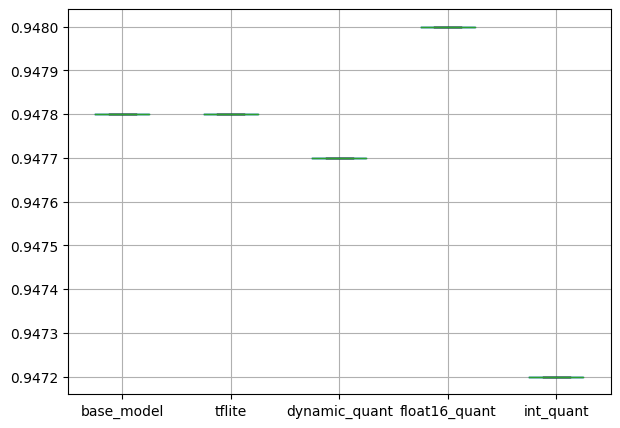
훈련 후 정수 양자화의 성능이 떨어지지만, base_model에 비해 0.0006이 낮아 큰 차이로 보이지는 않습니다.
pd.DataFrame(Normal_Model_Time_results).boxplot(figsize=(7, 5))
plt.show()출력
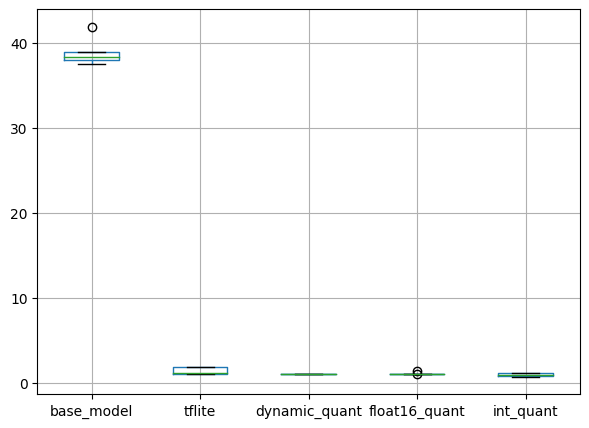
추론 시간의 경우, TFLite 형태로 변환한 모델이 매우 빠릅니다.
양자화 인식 훈련 모델
다음으로, 양자화 인식 모델을 TFLite로 변환한 결과를 확인합니다.
# TFLite
converter = tf.lite.TFLiteConverter.from_keras_model(q_aware_model)
tflite_model = converter.convert()
# Q-Aware Model
tflite_models_dir = Path("tflite_q_aware_models/")
tflite_models_dir.mkdir(exist_ok=True, parents=True)
tflite_model_file = tflite_models_dir/"base_model.tflite"
tflite_model_file.write_bytes(tflite_model)출력
88000
# TFLite - Dynamic Quant
converter = tf.lite.TFLiteConverter.from_keras_model(q_aware_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_dynamic_quant_model = converter.convert()
tflite_model_dynamic_quant_file = tflite_models_dir/"dynamic_quant_model.tflite"
tflite_model_dynamic_quant_file.write_bytes(tflite_dynamic_quant_model)출력
25120
# TFLite - Float16 Quant
converter = tf.lite.TFLiteConverter.from_keras_model(q_aware_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_float16_quant_model = converter.convert()
tflite_model_float16_quant_file = tflite_models_dir/"float16_quant_model.tflite"
tflite_model_float16_quant_file.write_bytes(tflite_float16_quant_model)출력
25120
# TFLite - Int Quant
def representative_data_gen():
for input_value in tf.data.Dataset.from_tensor_slices(train_images.astype(np.float32)).batch(1).take(100):
yield [input_value]
converter = tf.lite.TFLiteConverter.from_keras_model(q_aware_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_int_quant_model = converter.convert()
tflite_model_int_quant_file = tflite_models_dir/"int_quant_model.tflite"
tflite_model_int_quant_file.write_bytes(tflite_int_quant_model)출력
25128
interpreter_tflite = tf.lite.Interpreter(model_path=str(tflite_model_file))
interpreter_tflite.allocate_tensors()
interpreter_dynamic = tf.lite.Interpreter(model_path=str(tflite_model_dynamic_quant_file))
interpreter_dynamic.allocate_tensors()
interpreter_f16 = tf.lite.Interpreter(model_path=str(tflite_model_float16_quant_file))
interpreter_f16.allocate_tensors()
interpreter_int = tf.lite.Interpreter(model_path=str(tflite_model_int_quant_file))
interpreter_int.allocate_tensors()실험 코드는 동일합니다. 결과는 다음과 같습니다.
pd.DataFrame(Q_Aware_Model_Acc_results).boxplot(figsize=(7, 5))
plt.show()출력
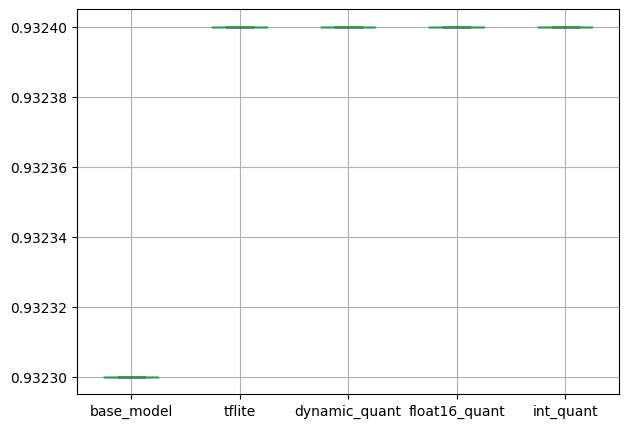
pd.DataFrame(Q_Aware_Model_Time_results).boxplot(figsize=(7, 5))
plt.show()출력
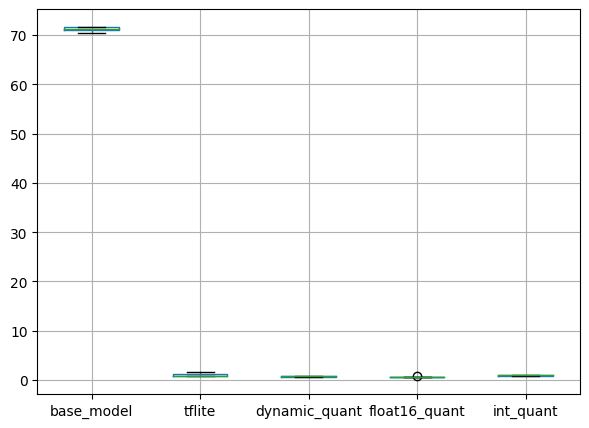
일반 모델과 같이 정확도는 크게 차이나지 않고, 추론 속도는 TFLite 변환 모델이 매우 빠릅니다.
기존 모델에 비해 정확도가 떨어지지만, 기본 모델 훈련과 양자화 인식 훈련 모두 1 에포크만 진행했음을 감안해야 합니다.
CPU
동일한 코드를 Colab의 CPU에서 실행한 결과는 다음과 같습니다.
일반 모델
pd.DataFrame(Normal_Model_Acc_results).boxplot(figsize=(7, 5))
plt.show()출력
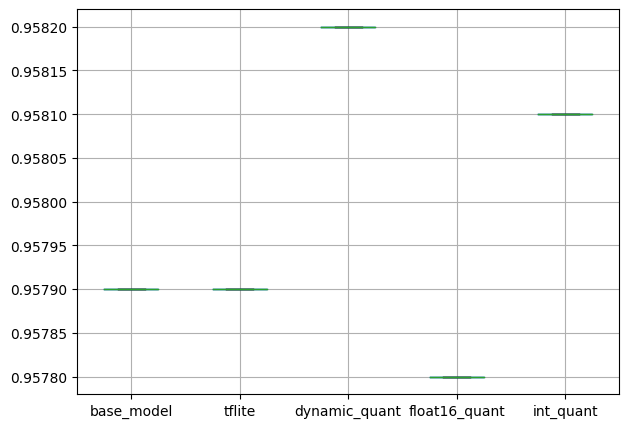
모델 성능의 편차는 마찬가지로 크지 않습니다.
pd.DataFrame(Normal_Model_Time_results).boxplot(figsize=(7, 5))
plt.show()출력
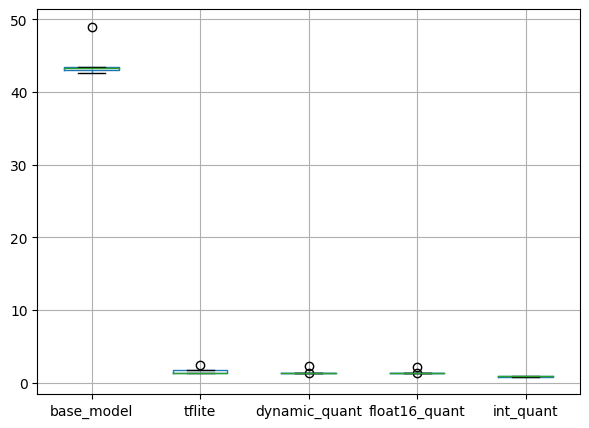
base_model의 추론 시간이 조금 증가하였습니다. 다만, 데이터 및 모델이 그다지 복잡하지 않아 크게 증가하지는 않았습니다.
양자화 인식 훈련 모델
pd.DataFrame(Q_Aware_Model_Acc_results).boxplot(figsize=(7, 5))
plt.show()출력
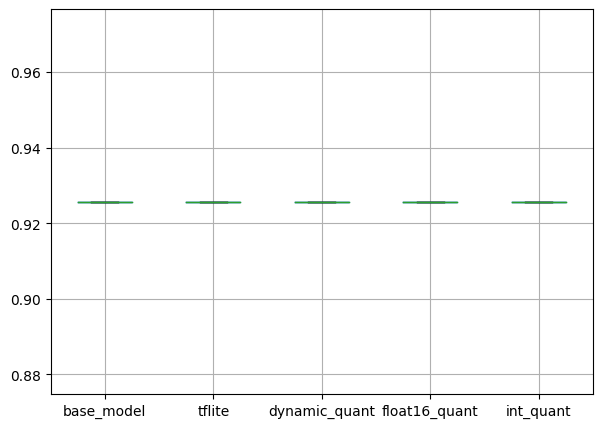
pd.DataFrame(Q_Aware_Model_Time_results).boxplot(figsize=(7, 5))
plt.show()출력
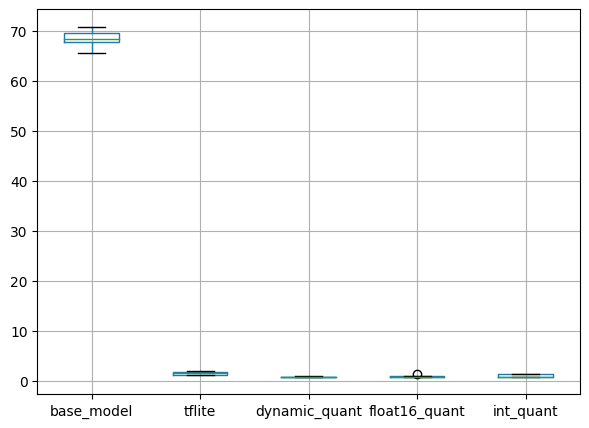
마찬가지로 동일합니다. TFLite 변환 및 양자화에 따른 추론 속도 변화를 확인하시려면 지난 포스팅을 참고하시는 것이 좋습니다.
모델 크기
각 모델의 크기는 다음과 같습니다.
def convert_size(size_bytes):
if size_bytes == 0:
return "0B"
size_name = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
i = int(math.floor(math.log(size_bytes, 1024)))
p = math.pow(1024, i)
s = round(size_bytes / p, 2)
return "%s %s" % (s, size_name[i])tflite_size = os.path.getsize('/content/tflite_models/base_model.tflite')
dynamic_quant_size = os.path.getsize('/content/tflite_models/dynamic_quant_model.tflite')
float16_quant_size = os.path.getsize('/content/tflite_models/float16_quant_model.tflite')
int_quant_size = os.path.getsize('/content/tflite_models/int_quant_model.tflite')
print('Normal Model')
print('TFLite Size:', convert_size(tflite_size), 'bytes')
print('Dynamic Quant Size:', convert_size(dynamic_quant_size), 'bytes')
print('Float16 Quant Size:', convert_size(float16_quant_size), 'bytes')
print('Int Quant Size:', convert_size(int_quant_size), 'bytes')출력
Normal Model
TFLite Size: 82.83 KB bytes
Dynamic Quant Size: 23.5 KB bytes
Float16 Quant Size: 43.58 KB bytes
Int Quant Size: 24.03 KB bytes
tflite_size = os.path.getsize('/content/tflite_q_aware_models/base_model.tflite')
dynamic_quant_size = os.path.getsize('/content/tflite_q_aware_models/dynamic_quant_model.tflite')
float16_quant_size = os.path.getsize('/content/tflite_q_aware_models/float16_quant_model.tflite')
int_quant_size = os.path.getsize('/content/tflite_q_aware_models/int_quant_model.tflite')
print('Q-Aware Model')
print('TFLite Size:', convert_size(tflite_size), 'bytes')
print('Dynamic Quant Size:', convert_size(dynamic_quant_size), 'bytes')
print('Float16 Quant Size:', convert_size(float16_quant_size), 'bytes')
print('Int Quant Size:', convert_size(int_quant_size), 'bytes')출력
Q-Aware Model
TFLite Size: 85.94 KB bytes
Dynamic Quant Size: 24.53 KB bytes
Float16 Quant Size: 24.53 KB bytes
Int Quant Size: 24.54 KB bytes
양자화 인식 모델의 크기가 조금 더 큰 것을 확인할 수 있습니다.
TFLite 및 양자화에 대한 간단한 사용 방법을 알아보았습니다. 해당 주제에 대해 깊게 공부한 것은 아니므로, 잘못된 내용이 있을 수 있습니다.
양자화 사양 및 지원되는 하드웨어 종류 등 자세한 내용은 공식 문서를 참고해 주세요.
전체 코드는 제 github에서 확인하실 수 있습니다.
감사합니다.
