Multi-layer pseudo-supervision for histopathology tissue semantic segmentation using patch-level classification labels
논문 정리

본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Overview
Segmentation 모델의 경우 pixel-level annotation이 필요하지만, WSI 특성 상 pixel-level의 annotation 작업이 매우 어려움. 본 논문에서는 patch-level의 label 정보만 주어졌을 때, semantic segmentation 모델을 훈련할 수 있는 방법을 제안함.
본 논문에서는 아래와 같이 4가지의 범주를 갖는 segmentation task를 다룸.
WSI에서의 Tumor microenvironment(TME) segmentation → tumor epithelial (TE), tumor-associated stroma (TAS), lymphocyte (LYM) and necrosis (NEC)
TE : 상피 종양, TAS : 기질 종양(근육층에서 발생), LYM : 림프구, NEC : 괴사
Method
본 논문에서 제안하는 방법은 아래의 두 과정으로 요약할 수 있음.
- Classification Phase : patch-level의 classifier(ResNet38)를 훈련한 후, 입력 patch 에 대한 Grad-CAM을 pseudo mask로 사용. Classifier의 경우, 4개 범주 중 하나의 범주를 예측하는 것이 아닌 4개의 범주 존재를 모두 예측하는 multi-label classification model을 훈련함.
- Segmentation Phase : 생성된 pseudo mask를 기반으로 segmentation 모델(DeepLab V3+) 훈련
아래의 이미지는 전체 과정을 표현함.
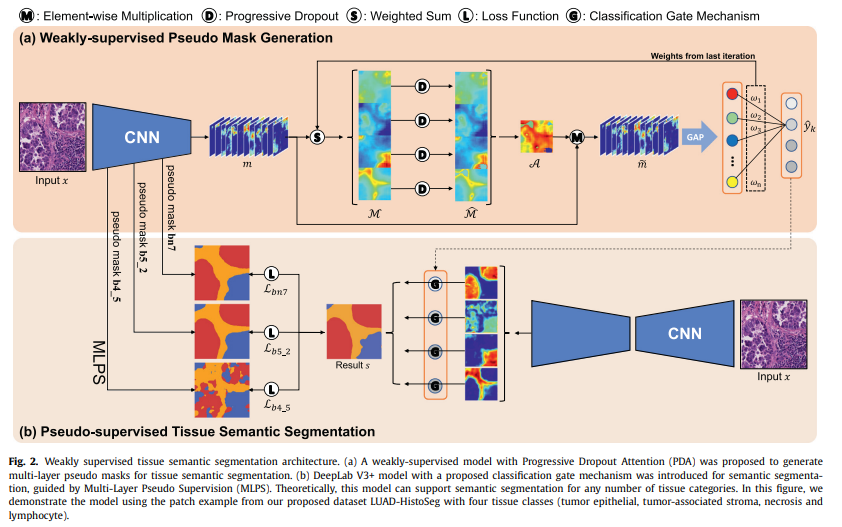
Weakly-supervised Pseudo Mask Generation
Input patch 에 대한 deep feature maps를 이라 정의함. 는 ResNet38을 사용하였음.
Feature map 에 Progressive Dropout Attention(PDA)을 적용함.
Global Average Pooling(GAP) 적용 후 최종 클래스()에 대한 예측 확률 값을 계산함. 기존의 CAM 논문과 유사한 과정임.
Classifier의 훈련이 끝나면, 예측 결과 에 대한 Grad-CAM 적용으로 pseudo mask 를 계산함.
Progressive Dropout Attention(PDA)
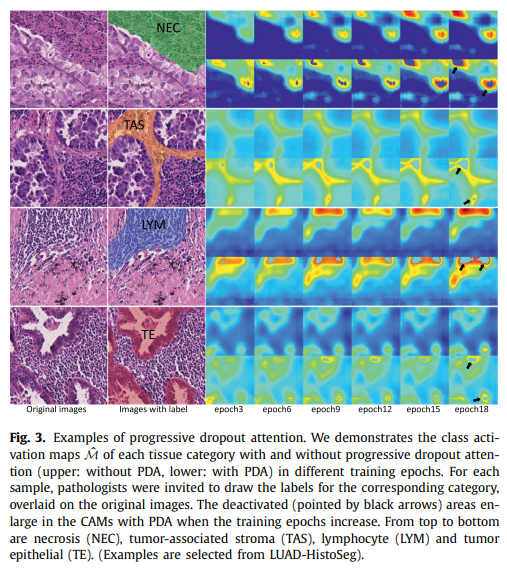
Image classifier의 예측 결과(Grad-CAM 등)를 pseudo mask로 사용할 때, 고려해야 하는 중요한 문제가 있음. 분류기가 학습됨에 따라, 모델은 가장 discriminative한 지역에 집중하는 경향이 있어 segmentation을 위한 mask 생성에 부정적인 영향을 줄 수 있음.

[Ref : Selvaraju, Ramprasaath R., et al. "Grad-cam: Visual explanations from deep networks via gradient-based localization." Proceedings of the IEEE international conference on computer vision. 2017.]
Grad-CAM ‘Dog’의 경우, 모델의 예측 설명이 개의 얼굴 쪽에 집중된 것을 확인할 수 있음. 이러한 Grad-CAM 결과를 기반으로 segmentation mask를 생성한다면, 해당 mask는 개의 영역을 제대로 포함할 수 없음. Segmentation 모델 학습을 위한 mask를 생성하려면 Grad-CAM의 결과가 개의 머리만이 아닌 몸통까지도 집중해야 함.
Dropout Attention
분류기가 가장 discriminative 한 지역에 집중하는 문제를 해결하기 위해, feature map에 dropout attention을 적용함. 해당 연산의 경우 CAM에서 가장 activate 된 region의 값을 0으로 처리함.
마지막 deep feature 과 GAP 이후 연결되는 가중치 를 사용하여, 각 카테고리에 대한 CAM을 계산함. 는 번째 카테고리에 대한 CAM을 의미함.
모든 에 대해, dropout cutoff 를 사용하여 CAM 내부에서 가장 활성화된 지역을 deactivate함.
Cutoff 는 에 따라 다르게 계산됨. 는 dropout coefficient임.
최종적으로 dropout attention map 를 의 평균으로 계산함.
이 dropout attention map 를 deep feature map 에 곱하여 을 계산함. Deactivate 처리된 feature map 에 GAP를 적용한 후, 최종 예측 확률 를 계산함.
Progressive Dropout Attention
Patch classifier가 훈련됨에 따라 discriminative 지역에 집중하는 정도가 증가하므로, 훈련 epoch가 증가함에 따라 dropout coefficient 를 감소시키는 progressive dropout attention을 적용함.
가 감소되면 가 감소되므로, CAM에서 deactivate되는 영역이 증가함. 는 lower bound 이 될 때까지 점진적으로 감소함. 는 훈련 시의 epoch를 의미함.
본 논문에서는 를 사용하였음. 초기의 3 epoch 동안은 값을 1로 고정한 후 이후 점진적으로 감소시킴.
아래의 이미지는 PDA 적용에 따른 activate 영역을 보여줌.
Pseudo-supervised Tissue Semantic Segmentation
Grad-CAM 기반으로 생성된 pseudo mask를 기반으로, semantic segmentation 모델(DeepLab V3+)을 훈련함.
Segmentation 성능을 보다 향상시키기 위해 아래의 두 가지 방법을 추가로 적용함.
Multi-Layer pseudo-supervision
Segmentation 모델을 위한 추가적인 정보 제공을 위해, 분류 작업에 사용했던 CNN feature map을 추가로 활용함.
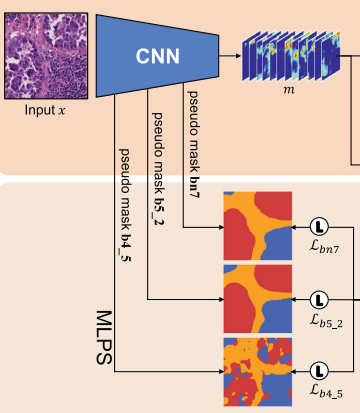
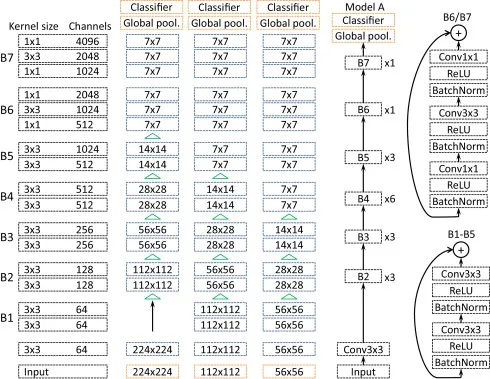
[이미지 출처]
마지막 conv layer()에 의한 pseudo mask 뿐만 아니라, 이전 conv layer의 feature map으로 생성한 pseudo mask 정보를 추가적으로 사용하여 segmentation 모델을 훈련함. Pseudo mask의 경우, bilinear interpolation을 사용하여 입력 크기에 맞춰주었음.
High level feature, Low level feature를 모두 사용하여 segmentation 모델을 훈련한다고 이해
각 pseudo mask에 대한 loss 결과를 조합하여 최종 loss를 계산함.
는 하이퍼파라미터이며, 본 논문에서는 을 사용하였음.
Classification gate mechanism
예측하는 4가지의 클래스 중, 자주 나타나지 않는 클래스(non-predominant categories)는 높은 false positive rate 문제를 가질 수 있음.
Segmentation에서의 false positive error를 감소시키기 위해, patch-level 예측 확률값을 사용하여 out probability map을 조절함.
카테고리 에 대한 segmentation probability map을 , patch 에 대한 예측(classification) 확률 값을 라고 하면, 가 threshold 보다 작을 경우 를 0으로 처리함.
즉, 확실한 출력 예측이 없다면 segmentation 결과를 표시하지 못하도록 처리함. 논문에서는 로 설정하였음.
만약 동일한 픽셀 영역에서 여러 개의 카테고리가 겹친다면, 값이 가장 큰 클래스로 결정함.
아래의 이미지는 전체 segmentation 과정을 나타냄.
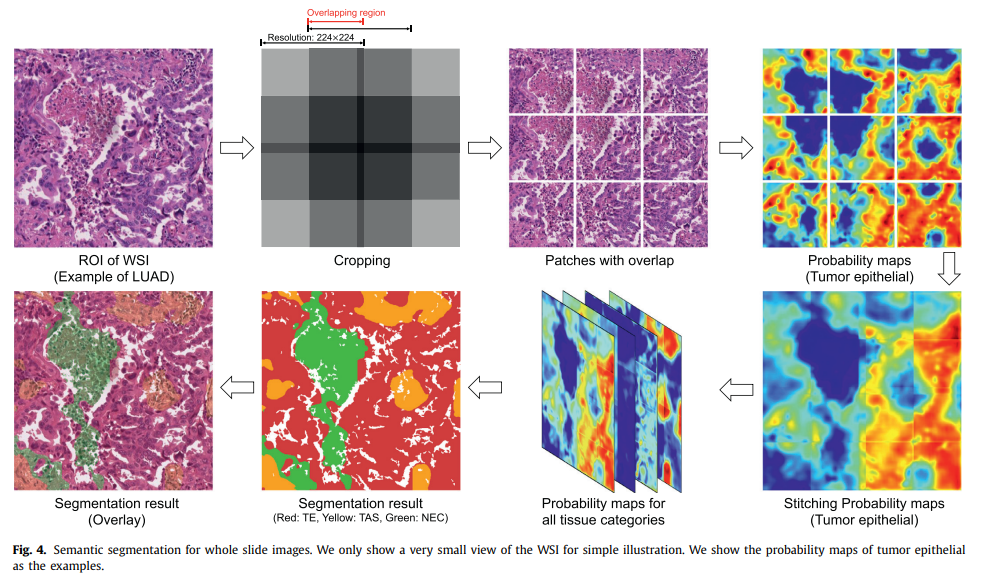
Experiments
본 논문에서 실험을 위해 LUAD-HistoSeg와 BCSS-WSSS 데이터셋을 사용하였음. LUAD-HistoSeg는 본 논문에서 새로 제안하는 데이터셋임.
Comparisons with SOTA
5개의 SOTA CAM-based weakly-supervised semantic segmentation 모델과 성능 비교를 진행하였음.
- HistoSegNet, SC-CAM, Grad-CAM++, CGNet, OAA
성능 측정을 위해 IoU for each category, Mean IoU(MIoU), Frequency weighted IoU(FwIoU), pixel-level accuracy(ACC) 지표를 사용하였음.
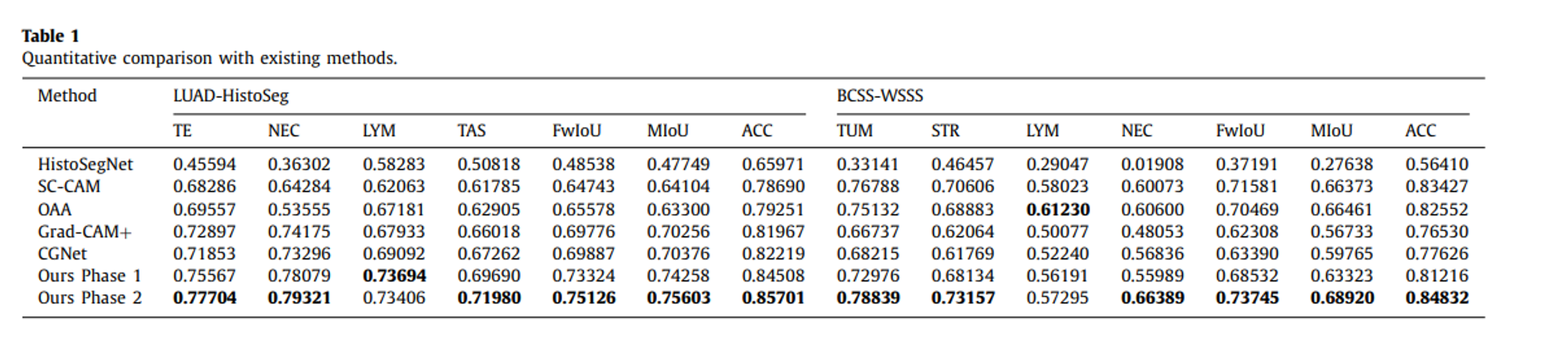
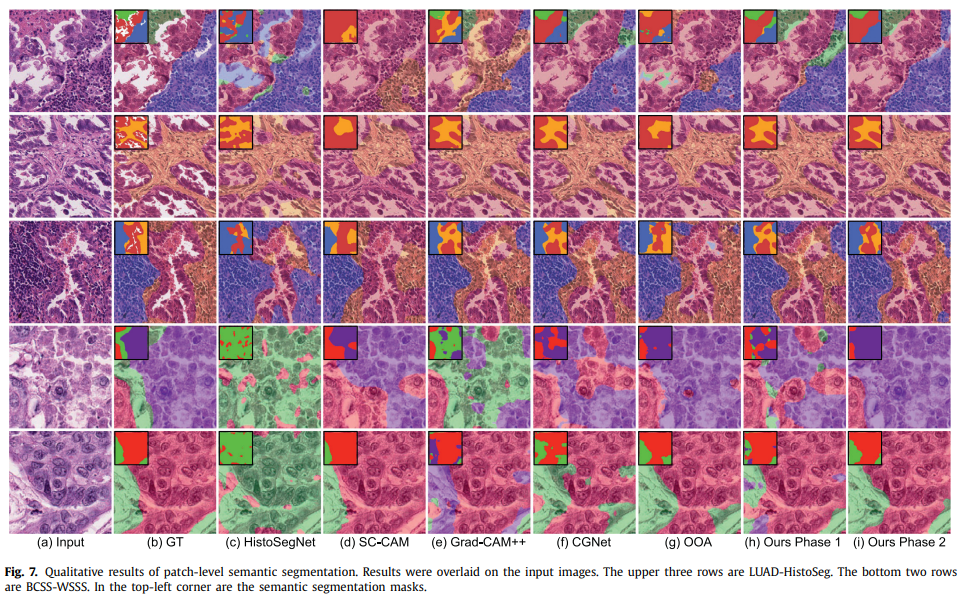
대부분의 경우 기존의 모델보다 더 나은 성능을 확인할 수 있음. 4가지의 클래스 중 LYM은 매우 적게 등장하는(non-predominant) 클래스이므로, 안정적인 성능을 확인하기 어려움. 이에 대한 추가적인 연구가 필요함.
일반적인 이미지의 경우, “자동차는 거의 도로에 존재한다” 등의 규칙이 존재하나, WSI의 경우 그러한 규칙 없이 조직의 분포가 random하고 scatter 한 경우가 많음. 이런 이유 때문에 non-predominant category의 학습이 더더욱 어려움.
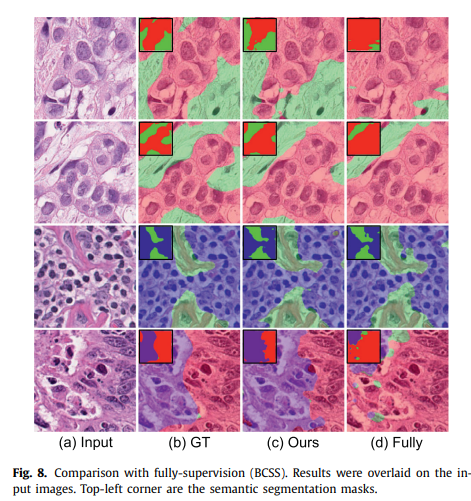
Comparison with Fully-supervised Learning
BCSS-WSSS 데이터셋의 경우 pixel-level의 annotation을 제공하므로, 제안하는 weakly-supervised learning 방법과 fully supervised learning으로 학습된 segmentation 모델 사이의 성능 비교를 수행함.
Weakly-supervised learning임에도 불구하고 fully-supervised learning과의 성능 차이가 2%보다 작았음.
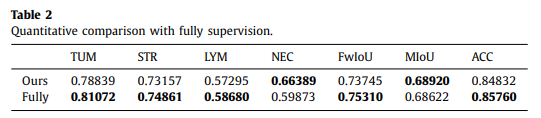
Ablation study 등 추가적인 실험 결과는 원본 논문을 참고.
