
Distributed Learning
분산 학습, Multi-GPU 학습 등은 거대한 데이터셋을 다루는 딥러닝에서 한 번쯤은 들어볼 수밖에 없는 주제입니다. 모델의 크기가 너무 크거나, 데이터의 양이 너무 많아 큰 batch size를 원하는 등 분산 학습을 해야 하는 이유는 다양하게 존재합니다.
이번 포스팅에서는 PyTorch를 활용한 간단한 분산 학습 예제를 다루도록 하겠습니다.
DataParallel vs. DistributedDataParallel
PyTorch 분산 학습, 혹은 multi-gpu 학습 등을 검색하신다면 PyTorch는 크게 두 방법으로 분산 학습을 지원하는 것을 알 수 있습니다. 한 가지 방법은 DataParallel을 사용하는 것이고, 다른 한 방법은 DistributedDataParallel을 사용하는 것입니다.
DataParallel은 사용하기 매우 쉽습니다. 아래와 같이, 사용하고자 하는 모델을 nn.DataParallel로 감싸주기만 하면 됩니다.
# DataParallel 예시
model = nn.DataParallel(model)
# Model Train ... 다만 DataParallel의 동작 특성상, 아래의 이미지처럼 메모리 불균형 문제가 발생할 수도 있습니다.
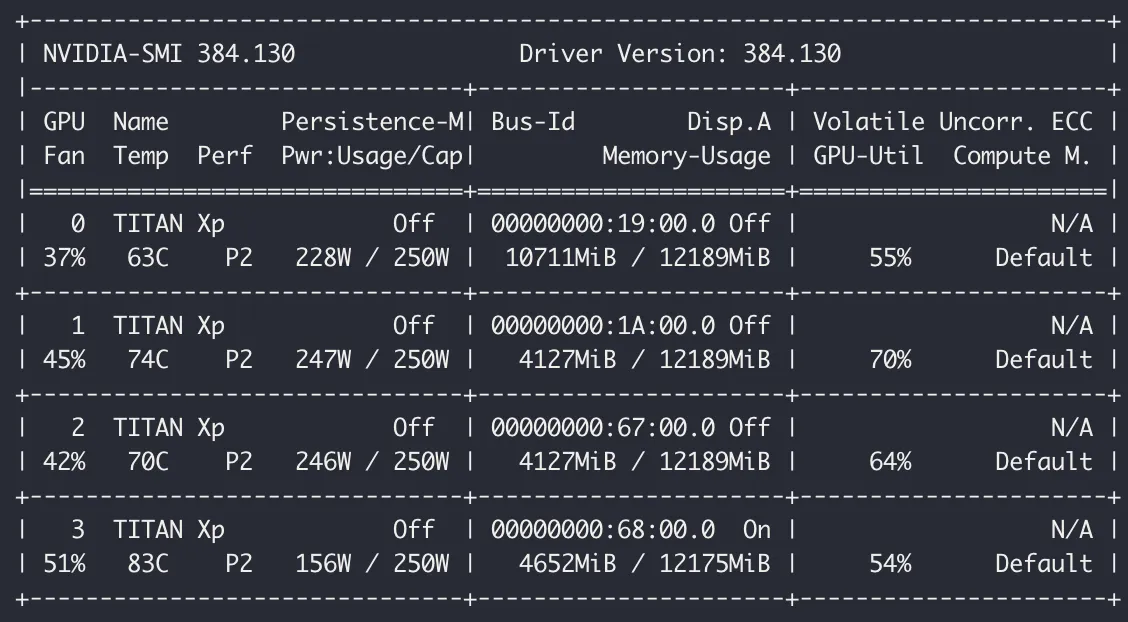
[이미지 출처: PyTorch Multi-GPU 제대로 학습하기]
위와 같이 하나의 GPU만 많이 사용한다면 큰 batch size를 사용할 수 없습니다. 이러한 문제를 해결하기 위해 Custom DataParallel 등을 사용할 수도 있지만, 이번 포스팅에서는 DistributedDataParallel을 사용해 보도록 하겠습니다.
DistributedDataParallel은 DataParallel에 비해 조금 더 어렵습니다. 단순히 모델을 DistributedDataParallel()로 감싸는 걸로 끝나지는 않습니다. 하지만, 메모리 불균형 문제, GIL connection 이슈 등 다양한 부분에서 장점을 가지므로 PyTorch는 DistributedDataParallel 기반의 분산 학습을 권장합니다.
DistributedDataParallel 등 분산 학습에 대한 이론적인 부분을 다루는 훌륭한 포스트가 이미 많이 있으므로, 이번 포스팅에서는 custom model, custom dataset에서 DistributedDataParallel을 사용하는 간단한 예제에 대해서 알아보겠습니다.
시작하기에 앞서, 이번 코드는 CV DOODLE 님의 [pytorch] Multi-GPU Training | 다중 GPU 학습 예시| Distributed Data Parallel (DDP) | Data Parallel (DP) 포스팅을 참고하였음을 알려 드립니다. 또한, 단일 머신(컴퓨터)에 다중 GPU가 있는 경우를 고려합니다.
Code
전체 코드는 제 깃허브에서 확인하실 수 있습니다.
이번 포스팅에서는 ResNet50, CIFAR-10 데이터셋을 사용합니다. 모델과 데이터셋은 code/ 아래 model/과 data/에 정의되어 있습니다.
Model & Dataset
모델의 경우, 아래와 같이 PyTorch 구현체를 그대로 사용합니다. 학습 속도를 빠르게 하기 위하여 backbone은 freezing 하였습니다.
# code/model/resnet50.py
import torch
import torch.nn as nn
from torchvision.models import resnet50, ResNet50_Weights
class ResNet50(nn.Module):
def __init__(self, num_classes=10):
"""
Pytorch ResNet50 implementation.
Using ImageNet weights.
Args:
num_classes (int, optional): number of classes. Defaults to 10(CIFAR-10).
"""
super(ResNet50, self).__init__()
weights = ResNet50_Weights.IMAGENET1K_V2
self.model = resnet50(weights=weights, progress=False)
num_ftrs = self.model.fc.in_features
self.model.fc = nn.Linear(num_ftrs, num_classes)
for _, p in self.model.named_parameters():
p.requires_grad = False
for _, p in self.model.fc.named_parameters():
p.requires_grad = True
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.model(x)데이터셋의 경우, 아래와 같이 PyTorch에서 제공하는 CIFAR-10을 그대로 사용합니다. Download와 Load를 분리하여 구현하였습니다.
# code/data/dataset.py
import torchvision
from torchvision.models import ResNet50_Weights
import torch
from typing import Tuple
def download_CIFAR10(root='cifar10') -> None:
"""
Download CIFAR10 dataset
Location : code/cifar10/
Args:
root (str, optional): path to save. Defaults to 'cifar10'.
"""
torchvision.datasets.CIFAR10(root=root, train=True, download=True)
torchvision.datasets.CIFAR10(root=root, train=False, download=True)
def load_CIFAR10(root='cifar10') -> Tuple[torch.utils.data.Dataset, torch.utils.data.Dataset]:
"""
Load CIFAR10 dataset
Apply ToTensor(), Normalize() transforms.
Args:
root (str, optional): path to load. Defaults to 'cifar10'.
Returns:
Tuple[torch.utils.data.Dataset, torch.utils.data.Dataset]: pytorch dataset
"""
transform = ResNet50_Weights.IMAGENET1K_V2.transforms()
train_set = torchvision.datasets.CIFAR10(root=root, train=True, download=False, transform=transform)
test_set = torchvision.datasets.CIFAR10(root=root, train=False, download=False, transform=transform)
return train_set, test_setload_CIFAR10() 함수는 Dataset 객체를 반환하므로, 이후 DataLoader로 감싸야 합니다. 지금 예시에서는 ResNet50, CIFAR-10을 사용하였지만, 상황에 맞는 모델 및 데이터셋으로 변경할 수 있습니다.
code/utils/trainer.py 아래에는 모델 훈련 및 검증에 사용하는 함수가 정의되어 있습니다. 일반적인 모델 학습 코드와 동일합니다.
multigpu.py
code/multigpu.py를 실행하면 분산 학습을 시작할 수 있습니다. .py 파일을 좀 더 자세히 보겠습니다. 우선 필요한 라이브러리를 import 합니다
# code/multigpu.py
import argparse
import numpy as np
import time
import torch
import torch.distributed as dist
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
from data import dataset
from model import resnet50
from util import seed, trainer
from torchinfo import summaryimport torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel위의 라이브러리가 분산 학습에 필요한 라이브러리입니다.
def get_args_parser():
parser = argparse.ArgumentParser(add_help=False)
parser.add_argument('--batch_size', type=int, default=512)
parser.add_argument('--port', type=int, default=2024)
parser.add_argument('--local_rank', type=int)
return parserargparse를 사용해서 batch size 등을 조절할 수 있습니다. 이번 포스팅에서는 512로 고정하였습니다.
def init_distributed_training(rank, opts):
# 1. setting for distributed training
opts.rank = rank
opts.gpu = opts.rank % torch.cuda.device_count()
local_gpu_id = int(opts.gpu_ids[opts.rank])
torch.cuda.set_device(local_gpu_id)
if opts.rank is not None:
print("Use GPU: {} for training".format(local_gpu_id))
# 2. init_process_group
torch.distributed.init_process_group(backend='nccl',
init_method='tcp://127.0.0.1:' + str(opts.port),
world_size=opts.ngpus_per_node,
rank=opts.rank)
# if put this function, the all processes block at all.
torch.distributed.barrier()
# convert print fn iif rank is zero
setup_for_distributed(opts.rank == 0)
print('opts :', opts)
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = printinit_distributed_training(), setup_for_distributed() 함수를 사용하여 분산 학습에 필요한 내용을 정의합니다. init_distributed_training() 함수 안의 각 부분이 어떻게 동작하는지는 CV DOODLE님의 포스팅을 참고해 주세요.
setup_for_distributed() 함수는 설정한 gpu만 출력이 가능하도록 설정합니다. setup_for_distributed(opts.rank == 0)처럼, rank가 0인 gpu를 전달하여 rank==0인 gpu만 출력이 가능하게 합니다. 출력 가능한 gpu를 설정하는 이유는 무엇일까요?
DistributedDataParallel을 사용하여 분산 학습을 수행하면 하나의 GPU는 하나의 process가 됩니다. 보통 모델을 학습할 때는 손실, 정확도 등과 같은 다양한 지표를 출력하는데, 모든 process가 같은 내용을 중복해서 출력하면 터미널 창이 복잡해질 것입니다. 이러한 부분을 방지하기 위하여 하나의 gpu만 출력이 가능하도록 조절합니다.
main() 함수에서는 모델 정의 및 DataLoader 정의, 모델 학습 및 검증을 수행합니다.
def main(rank, opts):
seed.seed_everything(21)
init_distributed_training(rank, opts)
local_gpu_id = opts.gpu
train_set, val_set = dataset.load_CIFAR10()
### Train / Validation set ###
train_sampler = DistributedSampler(dataset=train_set, shuffle=True)
batch_sampler_train = torch.utils.data.BatchSampler(train_sampler, opts.batch_size, drop_last=True)
train_loader = DataLoader(train_set, batch_sampler=batch_sampler_train, num_workers=opts.num_workers)
val_loader = DataLoader(val_set, batch_size=opts.batch_size, shuffle=False)
### Model ###
model = resnet50.ResNet50().cuda(local_gpu_id)
print()
print('=== MODEL INFO ===')
summary(model)
print()
model = DistributedDataParallel(module=model, device_ids=[local_gpu_id])
### Training config ###
criterion = torch.nn.CrossEntropyLoss().to(local_gpu_id)
optimizer = torch.optim.Adam(model.parameters())
EPOCH = 10
max_loss = np.inf
for epoch in range(EPOCH):
train_sampler.set_epoch(epoch)
train_loss, train_acc = trainer.model_train(
model=model,
data_loader=train_loader,
criterion=criterion,
optimizer=optimizer,
device=local_gpu_id
)
dist.all_reduce(train_loss, op=dist.ReduceOp.SUM)
train_loss = train_loss.item() / dist.get_world_size()
dist.all_reduce(train_acc, op=dist.ReduceOp.SUM)
train_acc = train_acc.item() / dist.get_world_size()
if opts.rank == 0:
val_loss, val_acc = trainer.model_evaluate(
model=model.module,
data_loader=val_loader,
criterion=criterion,
device=torch.device(f"cuda:{local_gpu_id}")
)
if val_loss < max_loss:
print(f'[INFO] val_loss has been improved from {max_loss:.5f} to {val_loss:.5f}. Save model.')
max_loss = val_loss
torch.save(model.state_dict(), 'Best_Model_DDP.pth')
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, accuracy: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')
print('=== DONE === \n') 자세히 보겠습니다.
main() 함수의 첫 부분에서는 seed 고정과 gpu 설정, 데이터셋을 불러와 DataLoader를 정의합니다.
seed.seed_everything(21)
init_distributed_training(rank, opts)
local_gpu_id = opts.gpu
train_set, val_set = dataset.load_CIFAR10()
### Train / Validation set ###
train_sampler = DistributedSampler(dataset=train_set, shuffle=True)
batch_sampler_train = torch.utils.data.BatchSampler(train_sampler, opts.batch_size, drop_last=True)
train_loader = DataLoader(train_set, batch_sampler=batch_sampler_train, num_workers=opts.num_workers)
val_loader = DataLoader(val_set, batch_size=opts.batch_size, shuffle=False)훈련 데이터셋을 여러 개의 GPU로 분할해야 하므로 DistributedSampler, BatchSampler를 사용하여 DataLoader를 정의합니다. 검증(혹은 테스트) 데이터셋의 경우 일반적으로 훈련 데이터셋에 비해 크기가 작습니다. 따라서, 여러 GPU에 분할하지 않고 하나의 GPU에 전달하도록 합니다.
데이터셋을 여러 개의 디바이스로 분할하여 샘플링하는 과정 또한 시간이 필요합니다. 데이터셋이 그리 크지 않다면 하나의 GPU만 사용하여 샘플링하는 시간을 없애는 것이 전체적으로는 더 빠를 수 있습니다.
다음으로는 모델을 정의한 후, 모델을 DistributedDataParallel로 감싸줍니다. summary()는 torchinfo 라이브러리의 함수입니다.
model = resnet50.ResNet50().cuda(local_gpu_id)
print()
print('=== MODEL INFO ===')
summary(model)
print()
model = DistributedDataParallel(module=model, device_ids=[local_gpu_id])다음으로 손실 함수, 옵티마이저 등을 정의한 뒤 설정한 에포크만큼 모델을 훈련합니다. 아래에서는 예시를 위해 10 에포크만 훈련하였습니다.
### Training config ###
criterion = torch.nn.CrossEntropyLoss().to(local_gpu_id)
optimizer = torch.optim.Adam(model.parameters())
EPOCH = 10
max_loss = np.inf
for epoch in range(EPOCH):
train_sampler.set_epoch(epoch)
train_loss, train_acc = trainer.model_train(
model=model,
data_loader=train_loader,
criterion=criterion,
optimizer=optimizer,
device=local_gpu_id
)
dist.all_reduce(train_loss, op=dist.ReduceOp.SUM)
train_loss = train_loss.item() / dist.get_world_size()
dist.all_reduce(train_acc, op=dist.ReduceOp.SUM)
train_acc = train_acc.item() / dist.get_world_size()
if opts.rank == 0:
val_loss, val_acc = trainer.model_evaluate(
model=model.module,
data_loader=val_loader,
criterion=criterion,
device=torch.device(f"cuda:{local_gpu_id}")
)
if val_loss < max_loss:
print(f'[INFO] val_loss has been improved from {max_loss:.5f} to {val_loss:.5f}. Save model.')
max_loss = val_loss
torch.save(model.state_dict(), 'Best_Model_DDP.pth')
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, accuracy: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')
기존의 모델 학습과 달리, train_sampler.set_epoch(epoch)를 전달해 주어야 합니다.
model_train(), model_evaluate() 함수는 내부적으로는 조금 다르지만, 함께 입력받은 data_loader에 대한 loss, accuracy를 반환하는 함수입니다. 이때 반환되는 형태가 다른데, model_evaluate() 함수는 float 형태의 값 두 개가 반환되지만 model_train() 함수는 torch.Tensor 형태의 값 두 개가 반환됩니다.
이는 여러 개의 GPU에서 계산된 훈련 데이터의 loss, accuracy 값을 집계하기 위함입니다. dist.all_reduce(train_loss, op=dist.ReduceOp.SUM)와 같이 dist.all_reduce() 함수를 사용하여 분산된 값을 집계하는데, 집계하는 train_loss 등의 값이 torch.Tensor 타입이어야 하므로 model_train()은 텐서를 반환합니다.
Validation 과정은 하나의 GPU에서만 수행하면 되므로, rank==0인 GPU에서만 해당 동작을 수행하도록 조건문을 추가합니다.
마지막으로, 정의한 모든 함수를 사용할 수 있도록 아래와 같이 작성합니다.
if __name__ == '__main__':
DOWNLOAD_CIFAR10 = True
if DOWNLOAD_CIFAR10:
dataset.download_CIFAR10()
parser = argparse.ArgumentParser('Distributed training test', parents=[get_args_parser()])
opts = parser.parse_args()
# ngpus_per_node = 2
opts.ngpus_per_node = torch.cuda.device_count()
# gpu_ids = 0, 1
opts.gpu_ids = list(range(opts.ngpus_per_node))
opts.num_workers = opts.ngpus_per_node * 4
start_time = time.time()
torch.multiprocessing.spawn(
main,
args=(opts,),
nprocs=opts.ngpus_per_node,
join=True)
end_time = time.time()
print('Elapsed time %s\n'%(end_time - start_time))python multigpu.py를 실행하면 위의 코드가 실행됩니다. CIFAR-10 데이터셋을 다운로드하고, torch.multiprocessing.spawn()를 통해 앞서 정의한 main() 함수가 병렬적으로 수행됩니다.
opts.ngpus_per_node, opts.gpu_ids는 실행하는 환경마다 달라집니다. 제 경우에는, 하나의 머신에 두 대의 TITAN XP가 존재하므로 ngpus_per_node = 2가 됩니다.
GPU Usage
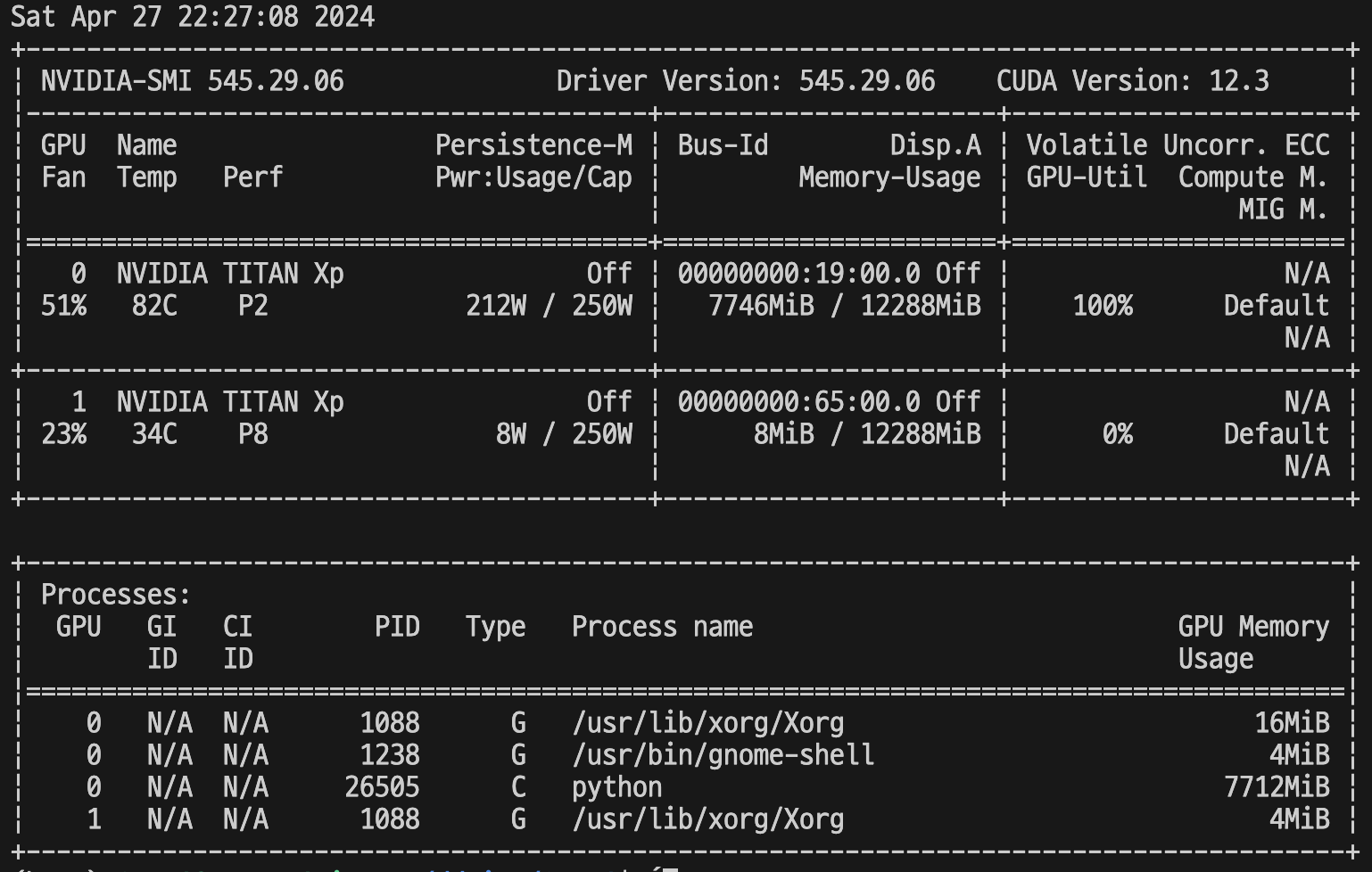
아래는 코드를 실행하였을 때의 GPU 상태입니다.
singlegpu.py
multigpu.py
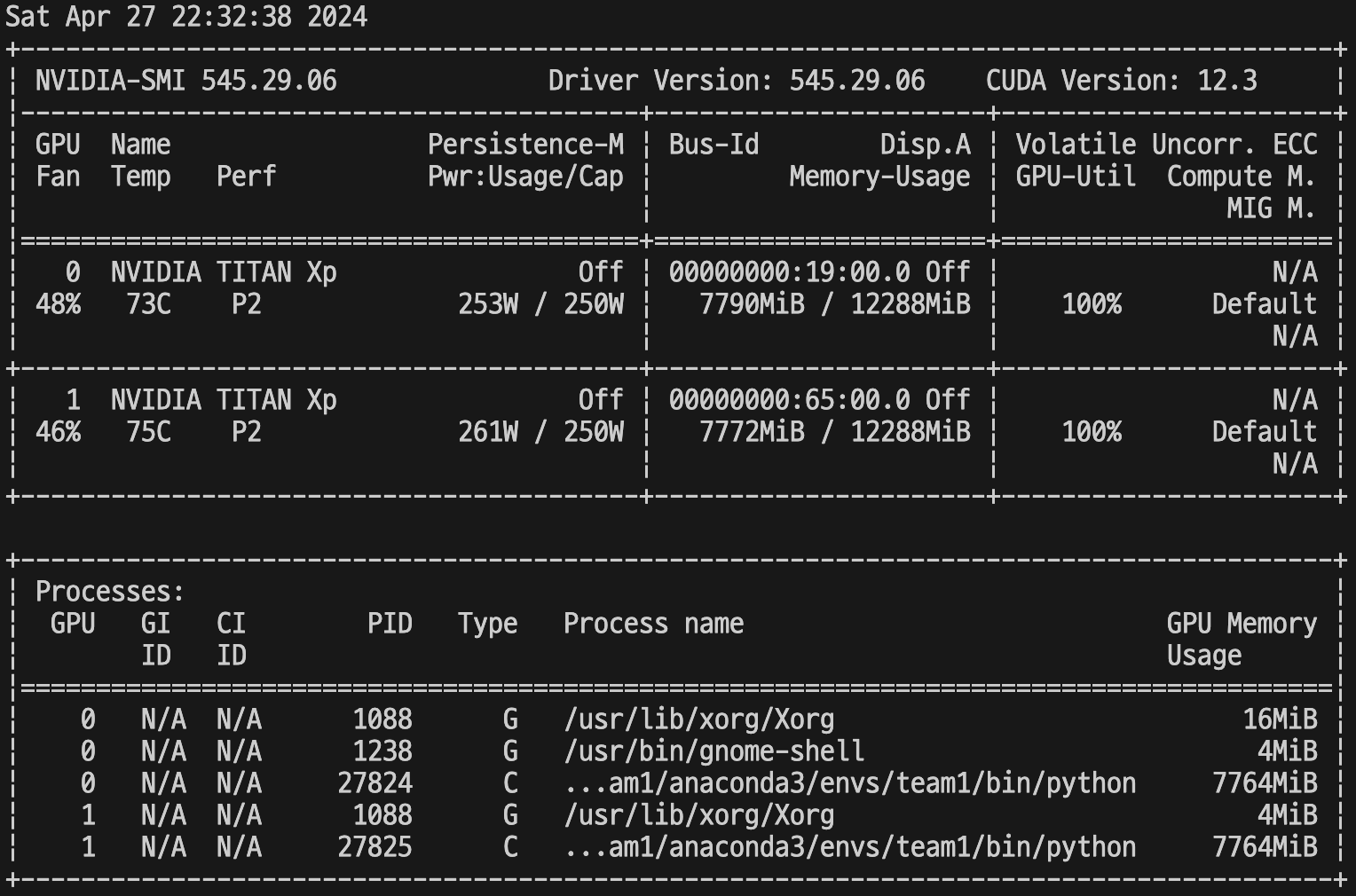
두 개의 GPU가 모두 활성화된 것을 확인할 수 있습니다.
이상으로 PyTorch DistributedDataParallel에 대한 간단한 포스팅을 마치겠습니다. 저 또한 새로 알아가는 분야이므로, 잘못되거나 부족한 내용이 있을 수 있습니다.
전체 코드는 제 깃허브에서 확인하실 수 있습니다.
감사합니다.
