
Weights & Biases (WandB)
WandB는 모델 학습 시 평가 지표, 시스템 사용률, 실험 결과 등을 모니터링 할 수 있도록 도와주는 플랫폼입니다.
.ipynb 파일이나 .py 파일에서도 충분히 모델의 학습 결과 등을 모니터링 할 수 있지만, 여러 개의 모델과 여러 개의 하이퍼파라미터 조합 등을 한눈에 쉽게 확인하려면 WandB와 같은 도구를 사용하는 것이 좋습니다.
이번 포스팅에서는 WandB의 다양한 기능 중, 평가 지표와 샘플 예측 결과를 logging 하는 방법에 대해 알아보겠습니다. 전체 기능에 대해 자세히 설명하는 것은 아니므로, 추가적인 정보는 공식 문서를 참고하시기 바랍니다.
Code
아래의 코드는 로컬 환경의 .ipynb 파일에서 실행되었습니다.
필요한 라이브러리를 불러온 후, 시드를 고정합니다. MNIST 데이터셋에서 간단한 CNN, MLP 모델을 학습할 예정입니다.
import os
import random
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as tr
import torchvision.models as models
from IPython.display import clear_output
def seed_everything(seed = 21):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything()다음으로, WandB에 로그인합니다. 아래의 셀을 실행하면 각 환경에 맞게 로그인할 수 있습니다. 각 계정의 authorize token을 붙여 넣어 로그인합니다.
.ipynb 파일은 token을 입력할 수 있는 칸이 나타나고, .py 파일은 터미널에 복사한 후 엔터를 치면 됩니다. 터미널에 복사할 경우 아무것도 나타나지 않지만, 엔터를 누르면 로그인됩니다.
# Log in W&B account
import wandb
wandb.login()아래의 코드는 데이터셋을 준비하고, 간단한 모델을 정의하는 부분입니다.
# Loading Data - MNIST dataset
def make_loader(batch_size, train=True, shuffle=True):
full_dataset = torchvision.datasets.MNIST(root='./data/MNIST',
train=train,
download=True,
transform=tr.ToTensor())
loader = DataLoader(dataset=full_dataset,
batch_size=batch_size,
shuffle=shuffle,
pin_memory=True)
return loader # Total params: 30,762
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, 3)
self.conv2 = nn.Conv2d(16, 32, 3)
self.fc1 = nn.Linear(32 * 5 * 5, 32)
self.fc2 = nn.Linear(32, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(-1, 32 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x# Total params: 53,018
class MLPNet(nn.Module):
def __init__(self):
super(MLPNet, self).__init__()
self.fc1 = nn.Linear(784, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 16)
self.fc4 = nn.Linear(16, 10)
def forward(self, x):
x = x.float()
x = F.relu(self.fc1(x.view(-1, 784)))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = F.relu(self.fc4(x))
return x아래의 코드는 모델 학습 및 검증에 필요한 함수를 정의합니다.
def model_train(model,
data_loader,
criterion,
optimizer,
device,
scheduler=None,
tqdm_disable=False):
"""
Model train (for multi-class classification)
Args:
model (torch model)
data_loader (torch dataLoader)
criterion (torch loss)
optimizer (torch optimizer)
device (str): 'cpu' / 'cuda' / 'mps'
scheduler (torch scheduler, optional): lr scheduler. Defaults to None.
tqdm_disable (bool, optional): if True, tqdm progress bars will be removed. Defaults to False.
Returns:
loss, accuracy: Avg loss, acc for 1 epoch
"""
model.train()
running_loss = 0
correct = 0
for X, y in tqdm(data_loader, disable=tqdm_disable):
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
output = model(X)
loss = criterion(output, y)
loss.backward()
optimizer.step()
# multi-class classification
_, pred = output.max(dim=1)
correct += pred.eq(y).sum().item()
running_loss += loss.item() * X.size(0)
if scheduler:
scheduler.step()
accuracy = correct / len(data_loader.dataset) # Avg acc
loss = running_loss / len(data_loader.dataset) # Avg loss
return loss, accuracy
def model_evaluate(model,
data_loader,
criterion,
device):
"""
Model validate (for multi-class classification)
Args:
model (torch model)
data_loader (torch dataLoader)
criterion (torch loss)
device (str): 'cpu' / 'cuda' / 'mps'
Returns:
loss, accuracy: Avg loss, acc for 1 epoch
"""
model.eval()
with torch.no_grad():
running_loss = 0
correct = 0
sample_batch = []
sample_label = []
sample_prediction = []
for i, (X, y) in enumerate(data_loader):
X, y = X.to(device), y.to(device)
output = model(X)
# multi-class classification
_, pred = output.max(dim=1)
correct += torch.sum(pred.eq(y)).item()
running_loss += criterion(output, y).item() * X.size(0)
if i == 0:
sample_batch.append(X)
sample_label.append(y)
sample_prediction.append(pred)
accuracy = correct / len(data_loader.dataset) # Avg acc
loss = running_loss / len(data_loader.dataset) # Avg loss
return loss, accuracy, sample_batch[0][:16], sample_label[0][:16], sample_prediction[0][:16]model_evaluate() 함수에서, loss와 accuracy와 함께 16개의 이미지, 레이블, 예측 값을 반환합니다. 일반적인 모델 학습 과정에는 필요하지 않지만, 검증 이미지에 대한 모델 예측 값을 logging 하기 위하여 따로 추출합니다.
첫 번째 배치 중 앞에서 16개의 샘플을 추출하며, 검증 세트에 대한 DataLoader도 shuffle=True를 전달할 것이므로 에포크마다 새로운 이미지가 logging됩니다.
def map_dict_to_str(config):
config_str = ', '.join(f"{key}: {value}" for key, value in config.items() if key not in ['dataset', 'epochs', 'batch_size'])
return config_strmap_dict_to_str() 함수는 딕셔너리 config를 받아 문자열로 바꾸어 주는 함수입니다. config는 아래와 같이 전달됩니다.
config = {'dataset': 'MNIST',
'model': 'CNN',
'epochs': 10,
'batch_size': 64,
'optimizer': 'sgd',
'learning_rate': 1e-2,
'weight_decay': 0}config에서, dataset, epochs, batch_size는 변하지 않습니다. 따라서, 해당 값을 제외한 config 값을 문자열로 만들어 줍니다. 위 config는 아래와 같이 매핑됩니다.
- model: CNN, optimizer: sgd, learning_rate: 0.01, weight_decay: 0
아래의 run() 함수는 config를 인수로 받아, 실제로 모델 학습 및 logging을 수행합니다.
def run(config):
wandb.init(project='YOUR PROJECT NAME', config=config)
wandb.run.name = map_dict_to_str(config)
print('------')
print(map_dict_to_str(config))
print('------\n')
config = wandb.config
device = "cuda" if torch.cuda.is_available() else "cpu"
train_loader = make_loader(batch_size=config.batch_size, train=True)
test_loader = make_loader(batch_size=config.batch_size, train=False)
if config.model == 'CNN':
model = ConvNet().to(device)
if config.model == 'MLP':
model = MLPNet().to(device)
criterion = nn.CrossEntropyLoss()
if config.optimizer == 'sgd':
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate, weight_decay=config.weight_decay)
if config.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate, weight_decay=config.weight_decay)
if config.optimizer == 'adamw':
optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate, weight_decay=config.weight_decay)
wandb.watch(model, criterion, log="all")
max_loss = np.inf
for epoch in range(0, config.epochs):
train_loss, train_acc = model_train(model, train_loader, criterion, optimizer, device, None)
val_loss, val_acc, sample_batch, sample_label, sample_prediction = model_evaluate(model, test_loader, criterion, device)
wandb.log({"Train Loss": train_loss}, step=epoch+1)
wandb.log({"Train Accuracy": train_acc}, step=epoch+1)
wandb.log({"Validation Loss": val_loss}, step=epoch+1)
wandb.log({"Validation Accuracy": val_acc}, step=epoch+1)
wandb.log({"examples": [wandb.Image(image, caption=f"Pred: {pred}, Label: {label}") for image, pred, label in zip(sample_batch, sample_prediction, sample_label)]}, step=epoch+1)
if val_loss < max_loss:
print(f'[INFO] val_loss has been improved from {max_loss:.5f} to {val_loss:.5f}. Save model.')
max_loss = val_loss
torch.save(model.state_dict(), 'Best_Model.pth')
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, acc: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')
if config.model == 'CNN':
model = ConvNet().to(device)
wandb.log({'Total Params': 30762})
if config.model == 'MLP':
model = MLPNet().to(device)
wandb.log({'Total Params': 53018})
model.load_state_dict(torch.load('Best_Model.pth', map_location=device))
model.eval()
val_loss, val_acc, _, _, _ = model_evaluate(model, test_loader, criterion, device)
print('Test Loss: %s'%val_loss)
print('Test Accuracy: %s'%val_acc)
print()
wandb.log({"Best Test Loss": val_loss})
wandb.log({"Best Test Accuracy": val_acc})
return 'Done'조금 더 자세히 보겠습니다.
wandb.init(project='YOUR PROJECT NAME', config=config)
wandb.run.name = map_dict_to_str(config)
print('------')
print(map_dict_to_str(config))
print('------\n')wandb.init()으로 프로젝트를 설정합니다. project='YOUR PROJECT NAME'을 전달하여 프로젝트의 이름을 설정할 수 있습니다. 존재하지 않는 프로젝트라면 새로 생성됩니다. 프로젝트의 각 run 이름은 config와 동일하게 설정합니다.
config 값을 넣어주면 각각의 run에서 아래와 같이 config를 확인할 수 있습니다.
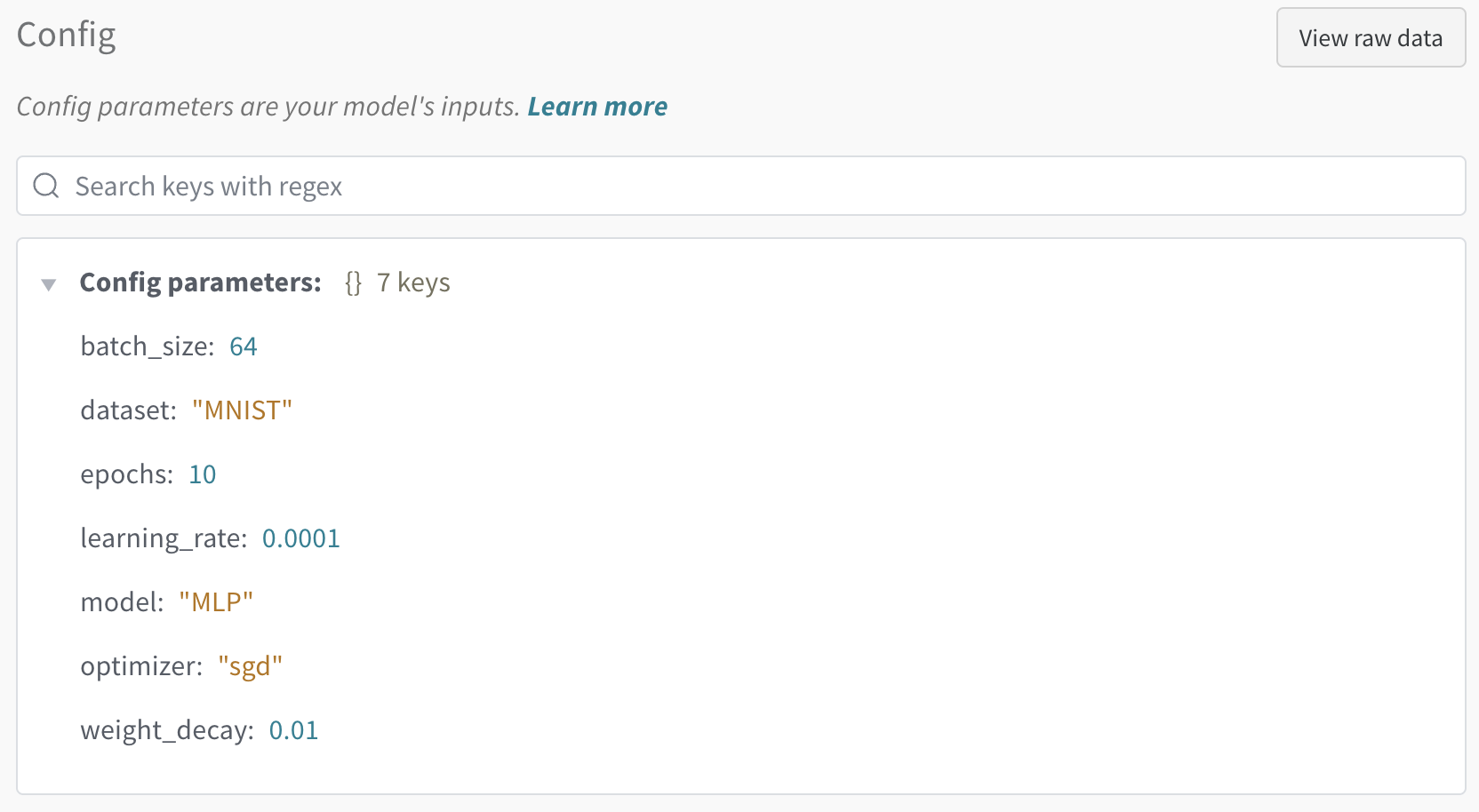
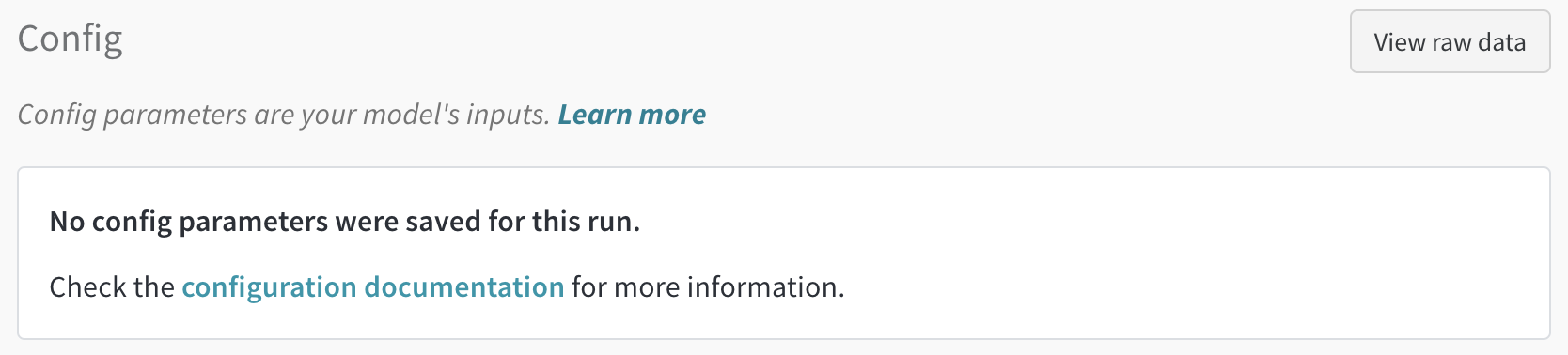
init()에 config를 전달하지 않는다면, 아래와 같이 표시됩니다.
아래의 코드에서는 config에 맞는 모델과 옵티마이저를 정의합니다.
config = wandb.config
device = "cuda" if torch.cuda.is_available() else "cpu"
train_loader = make_loader(batch_size=config.batch_size, train=True)
test_loader = make_loader(batch_size=config.batch_size, train=False)
if config.model == 'CNN':
model = ConvNet().to(device)
if config.model == 'MLP':
model = MLPNet().to(device)
criterion = nn.CrossEntropyLoss()
if config.optimizer == 'sgd':
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate, weight_decay=config.weight_decay)
if config.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate, weight_decay=config.weight_decay)
if config.optimizer == 'adamw':
optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate, weight_decay=config.weight_decay)
wandb.watch(model, criterion, log="all")wandb.watch()에 모델을 전달하여 모델의 gradient와 같은 추가적인 정보를 확인할 수 있습니다.
다음으로 모델 학습을 진행합니다.
max_loss = np.inf
for epoch in range(0, config.epochs):
train_loss, train_acc = model_train(model, train_loader, criterion, optimizer, device, None)
val_loss, val_acc, sample_batch, sample_label, sample_prediction = model_evaluate(model, test_loader, criterion, device)
wandb.log({"Train Loss": train_loss}, step=epoch+1)
wandb.log({"Train Accuracy": train_acc}, step=epoch+1)
wandb.log({"Validation Loss": val_loss}, step=epoch+1)
wandb.log({"Validation Accuracy": val_acc}, step=epoch+1)
wandb.log({"examples": [wandb.Image(image, caption=f"Pred: {pred}, Label: {label}") for image, pred, label in zip(sample_batch, sample_prediction, sample_label)]}, step=epoch+1)
if val_loss < max_loss:
print(f'[INFO] val_loss has been improved from {max_loss:.5f} to {val_loss:.5f}. Save model.')
max_loss = val_loss
torch.save(model.state_dict(), 'Best_Model.pth')
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, acc: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')for문 아래의 코드를 통해 정해진 epoch만큼 모델을 학습합니다.
train_loss, val_acc 등과 같은 지표는 wandb.log()로 logging 할 수 있습니다. wandb.log()에는 딕셔너리를 전달할 수 있으며, 위 코드와 같이 따로따로 loggingg 하거나 하나의 딕셔너리로 묶어 한 번에 logging 할 수도 있습니다.
step=epoch+1을 전달하면 이후 그래프를 확인할 때 그래프의 x축이 epoch와 동일하게 되어(1 ~ config.epochs) 보기 편해집니다.
이미지 및 이미지에 대한 예측 값을 logging 하려면 wandb.log()와 함께 wandb.Image()를 사용합니다.
if config.model == 'CNN':
model = ConvNet().to(device)
wandb.log({'Total Params': 30762})
if config.model == 'MLP':
model = MLPNet().to(device)
wandb.log({'Total Params': 53018})
model.load_state_dict(torch.load('Best_Model.pth', map_location=device))
model.eval()
val_loss, val_acc, _, _, _ = model_evaluate(model, test_loader, criterion, device)
print('Test Loss: %s'%val_loss)
print('Test Accuracy: %s'%val_acc)
print()
wandb.log({"Best Test Loss": val_loss})
wandb.log({"Best Test Accuracy": val_acc})
return 'Done'모델 학습이 완료되면 모델의 전체 파라미터 수를 logging 합니다. 마지막으로, 최적의 모델을 불러온 후 테스트 데이터에서의 손실 및 정확도를 logging 합니다.
실제로는 아래와 같이 여러 개의 list를 전달함으로, 여러 가지 하이퍼파라미터 조합을 모두 실험합니다. clear_output()은 .ipynb 파일에서 결과 출력 값을 지워주는 역할입니다.
model_list = ['CNN', 'MLP']
optimizer_list = ['sgd', 'adam', 'adamw']
learning_rate_list = [1e-2, 1e-3, 1e-4]
weight_decay_list = [0, 1e-2]
for model in model_list:
for optimizer in optimizer_list:
for learning_rate in learning_rate_list:
for weight_decay in weight_decay_list:
config = {'dataset': 'MNIST',
'model': model,
'epochs': 10,
'batch_size': 64,
'optimizer': optimizer,
'learning_rate': learning_rate,
'weight_decay': weight_decay}
run(config)
clear_output(wait=True)Result
다음으로, 실제 logging 결과를 확인해 보겠습니다.
WandB 웹페이지에 로그인한 후, Profile - Projects에서 진행 중인 프로젝트를 확인할 수 있습니다.
각 프로젝트에 들어가면, 아래와 같은 전체 대시보드를 확인할 수 있습니다. 그래프의 x축(step)은 epoch를 의미합니다.
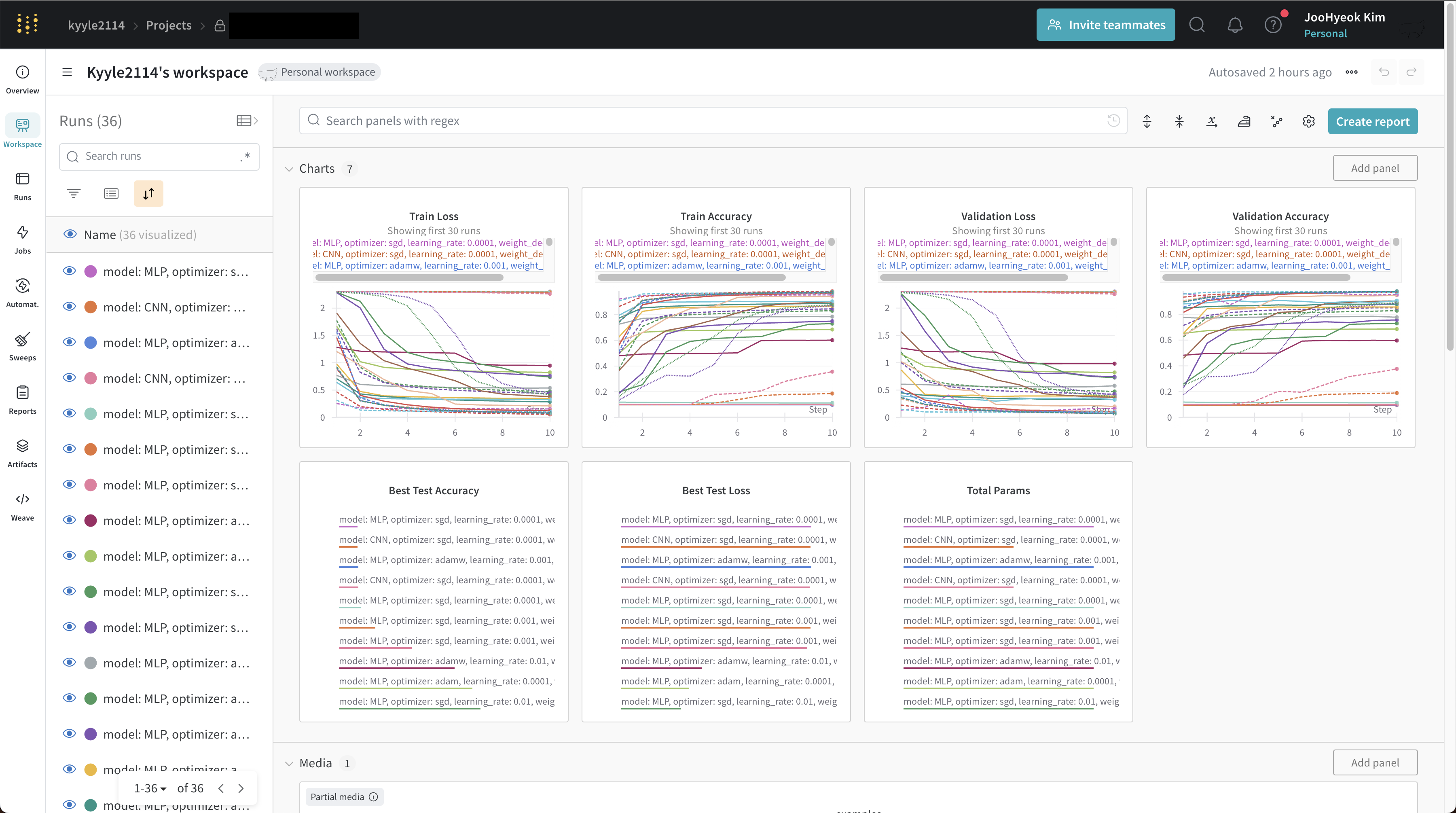
train_loss, val_acc와 같이 훈련 과정에서 logging 했던 지표를 한눈에 확인할 수 있습니다.
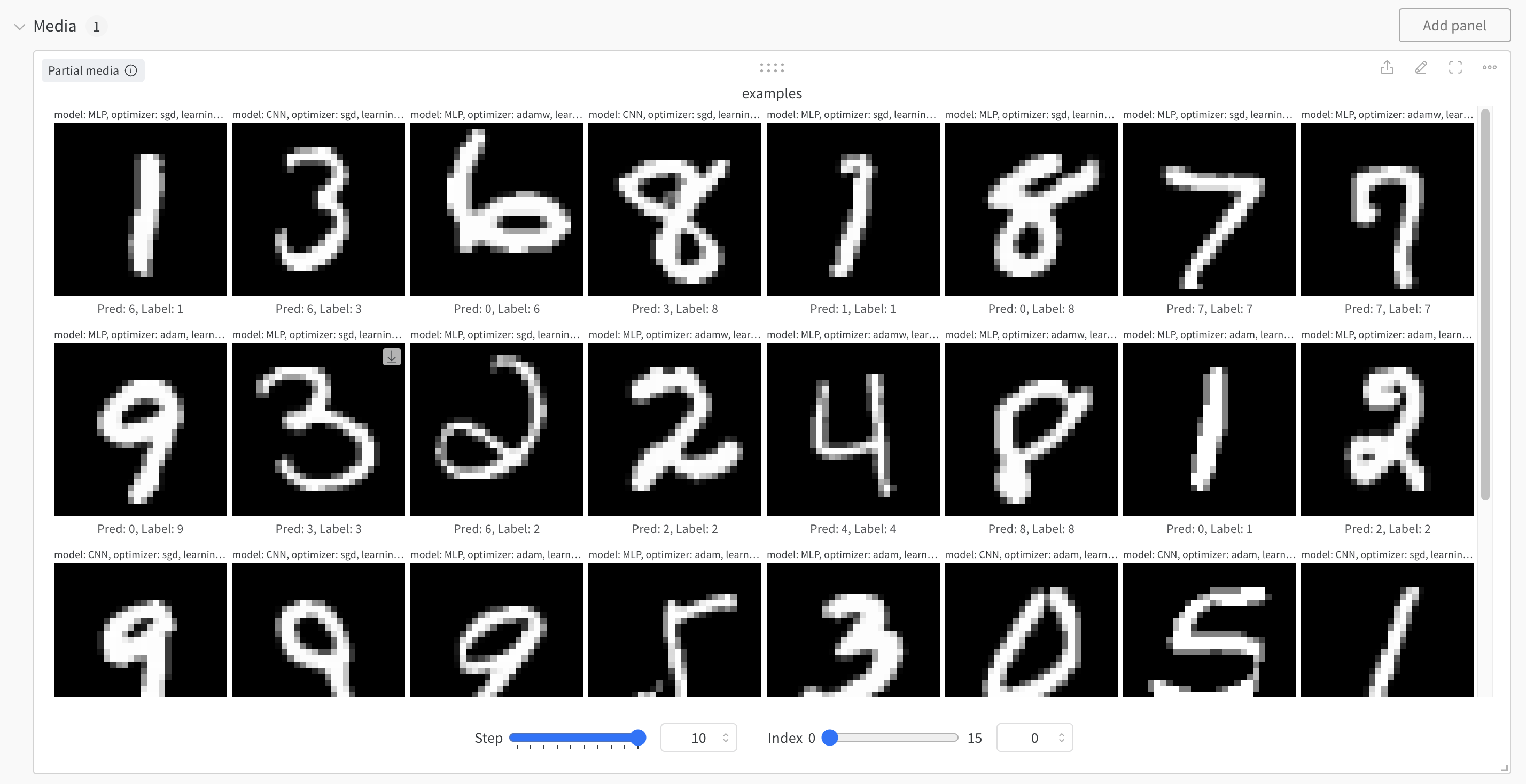
Media 패널에서는 wandb.Image()로 전달한 이미지와 레이블, 모델 예측 결과를 확인할 수 있습니다. Step을 조절하여 각 에포크마다의 결과를 확인할 수 있습니다. 16개의 이미지를 전달하였으므로, Index를 조절하여 각 이미지를 확인할 수 있습니다.
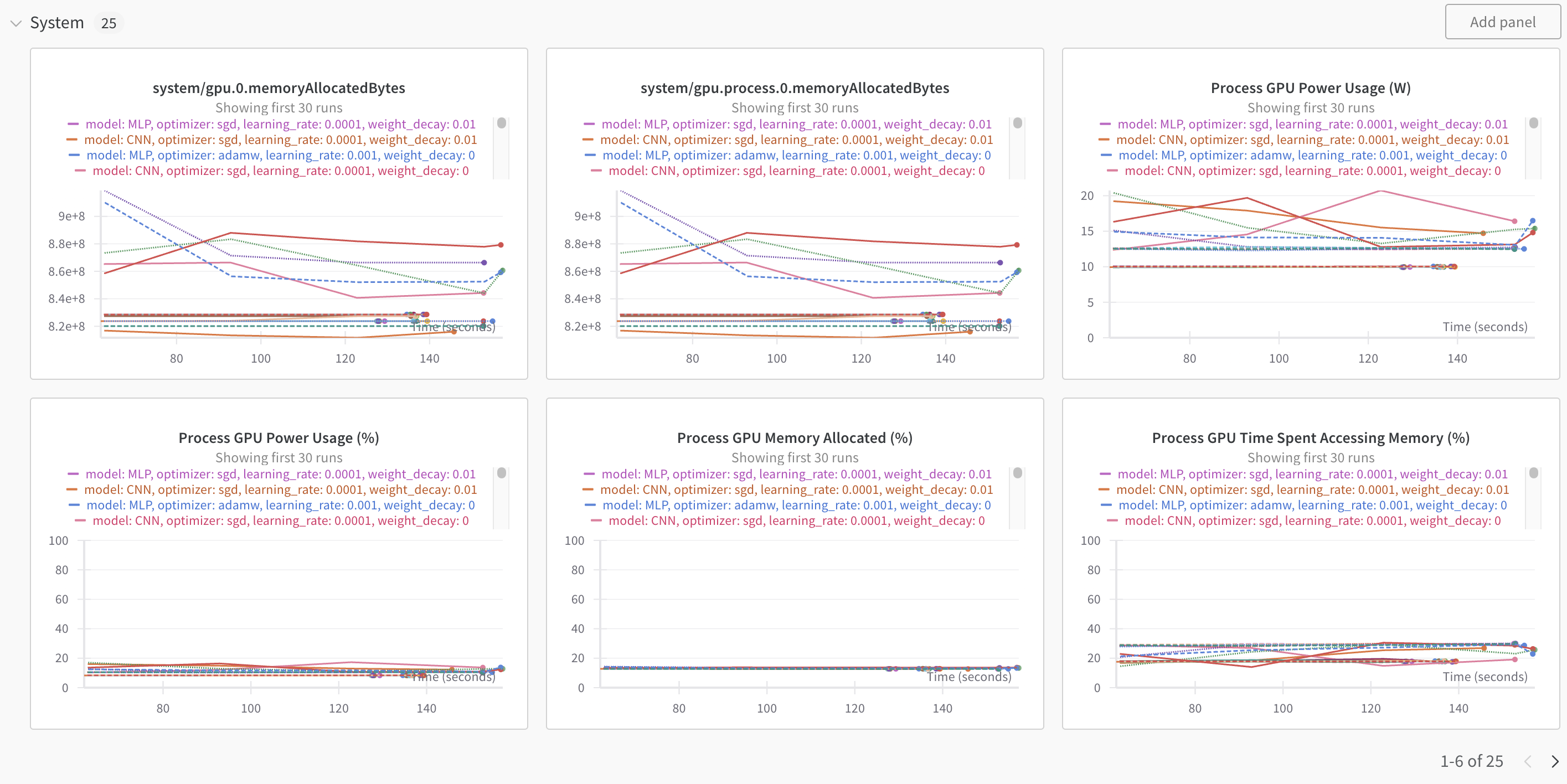
위와 같이, GPU 사용량 등 시스템 관련 값은 자동으로 모니터링 해줍니다.
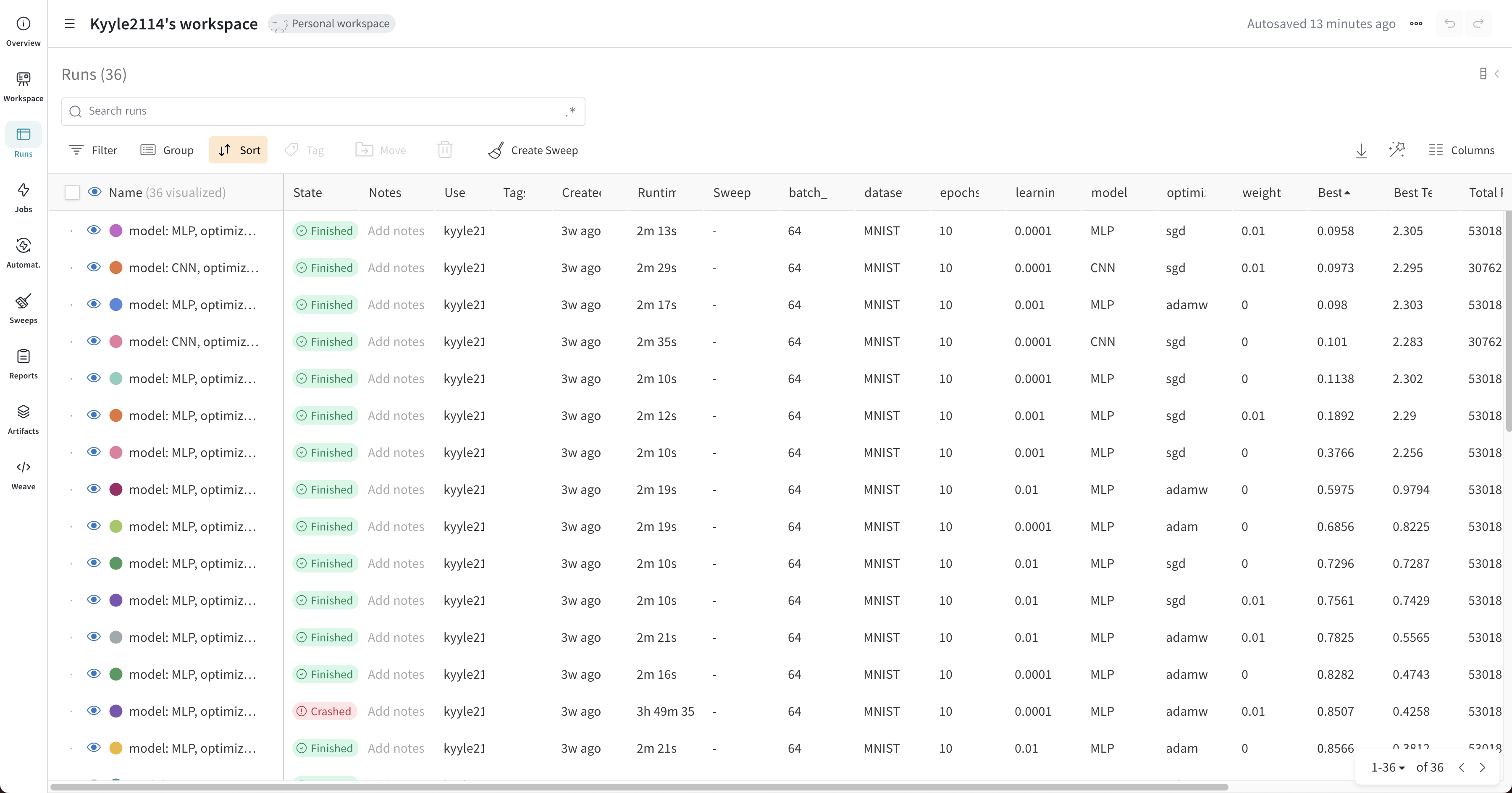
Runs에서 전체 run을 확인할 수 있고, 각 지표(정확도 등)에 따라 run을 정렬할 수도 있습니다.
각 run을 누르면, 해당 run에 대한 자세한 정보를 얻을 수 있습니다.
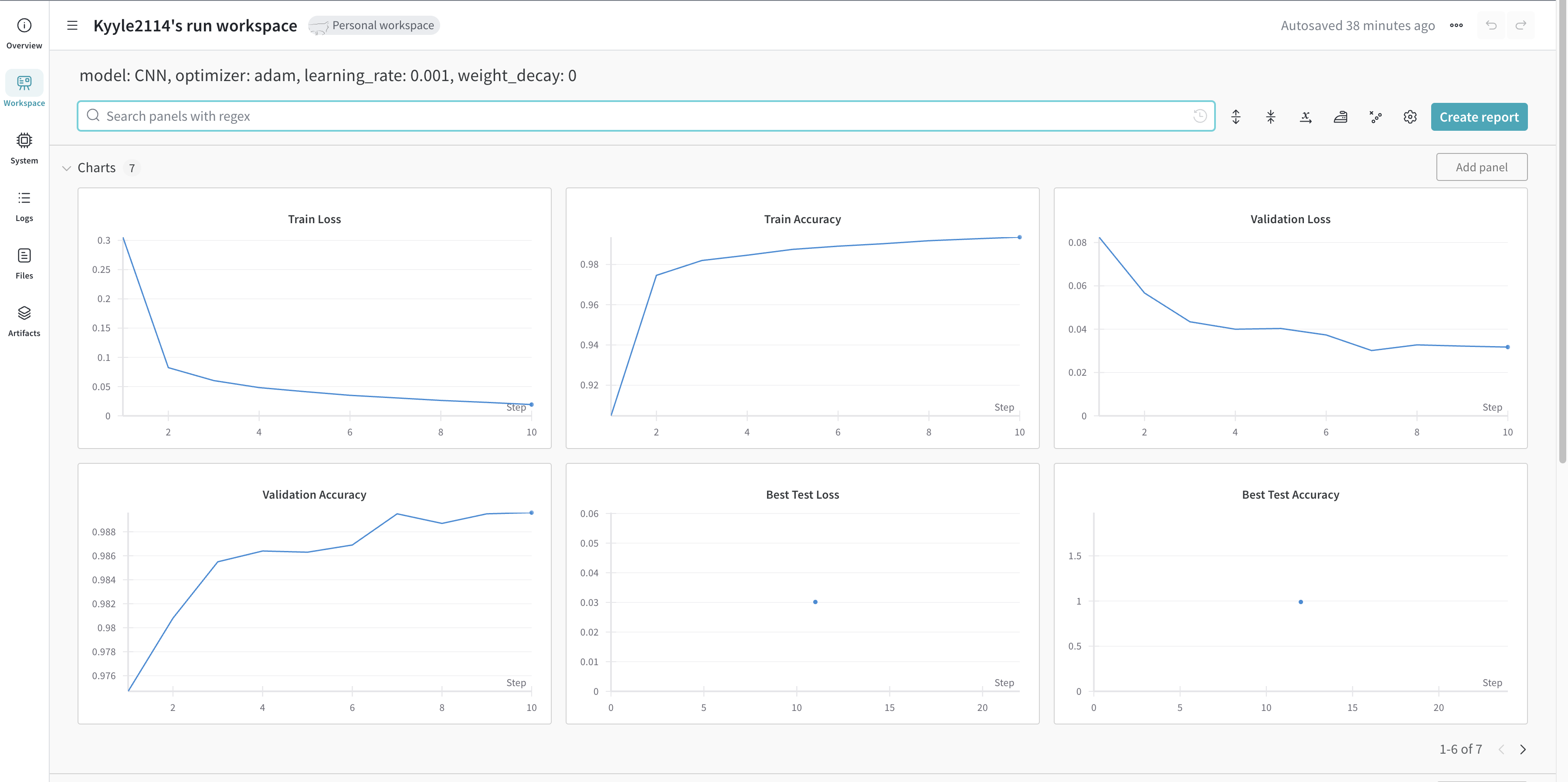
run의 Overview에서 전달한 config 등을 확인할 수 있습니다.
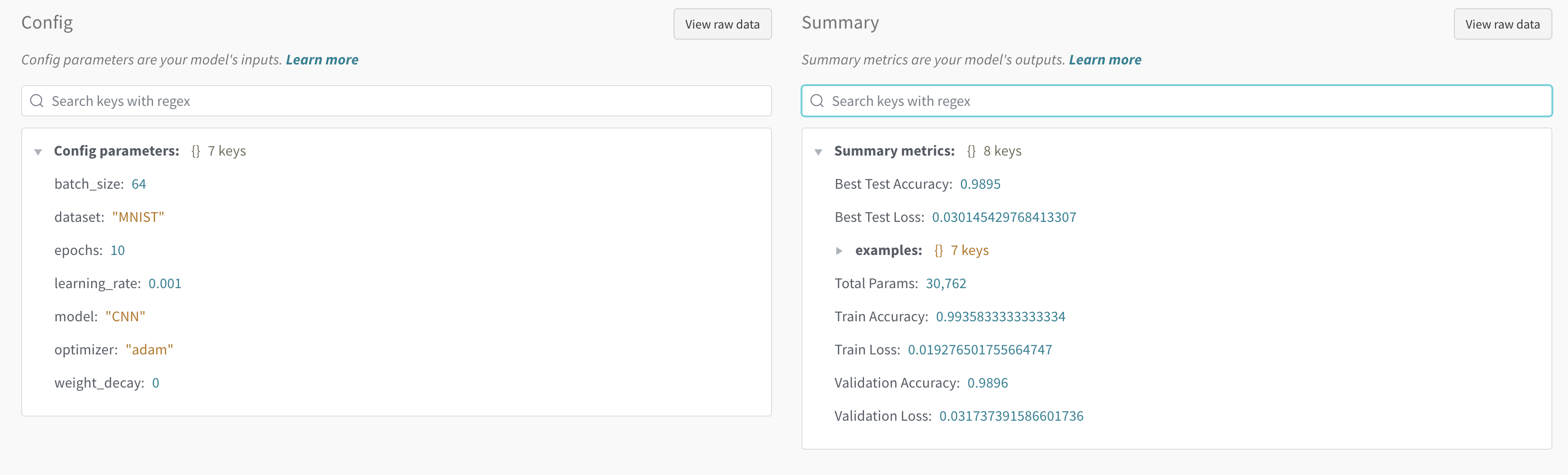
Logs에서 해당 run이 실행될 때 터미널에 출력된 값 또한 확인할 수 있습니다.
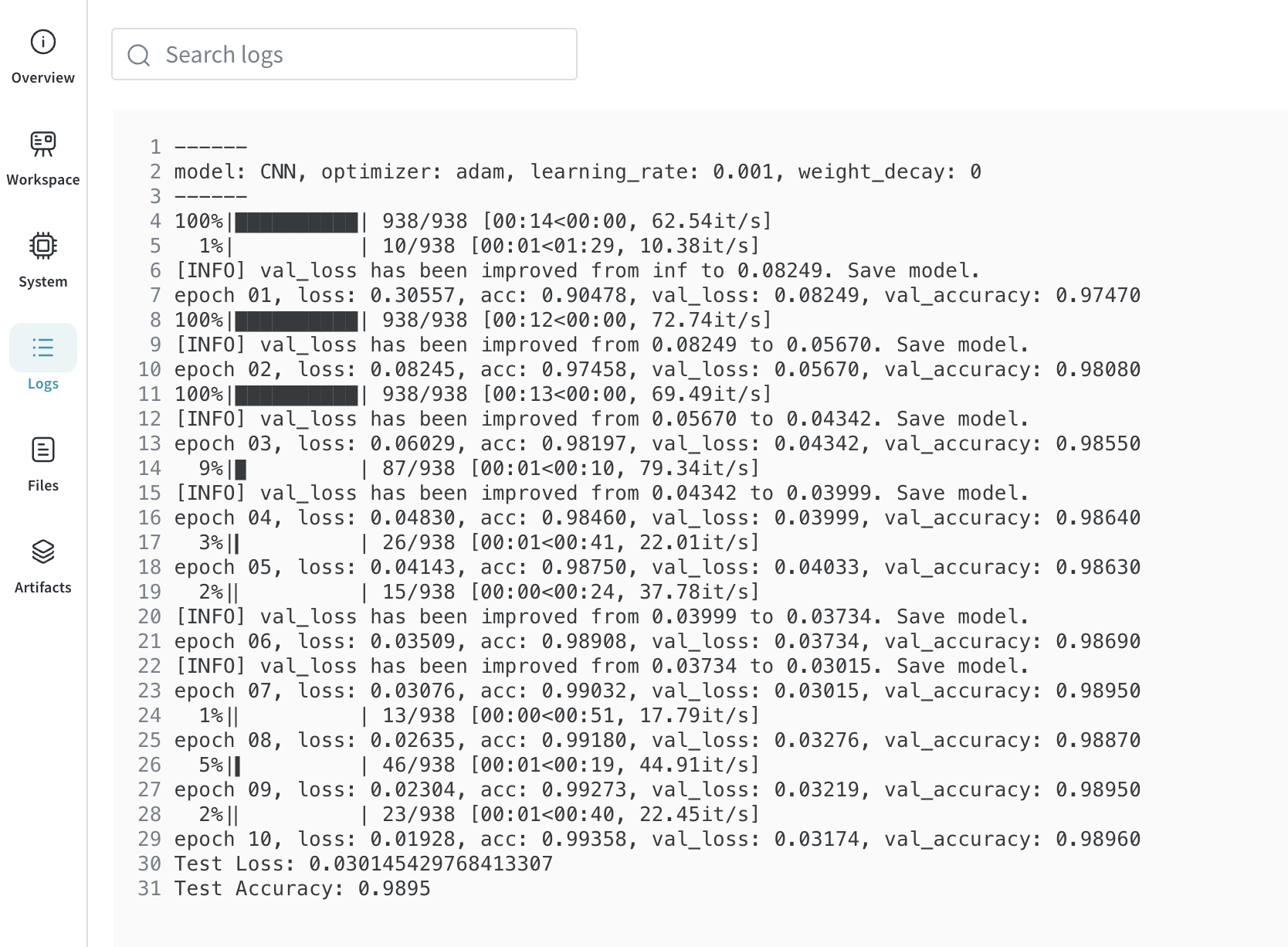
이상으로 WandB에 대한 간단한 포스팅을 마치겠습니다. WandB에 대해 더 자세히 알고 싶으시다면 공식 문서를 참고해 주세요.
전체 코드는 제 깃허브에서 확인하실 수 있습니다.
감사합니다.
