Semi-supervised training of deep convolutional neural networks with heterogeneous data and few local annotations: An experiment on prostate histopathology image classification
논문 정리

본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Overview
CNN은 다양한 컴퓨터 비전 task에서 우수한 성능을 달성하지만, 병리 이미지 분석에 CNN을 적용하기에는 아직까지도 많은 문제점이 있음. 대표적인 문제로는 highly heterogeneous data 문제와 lack of large datasets with local annotations 문제임.
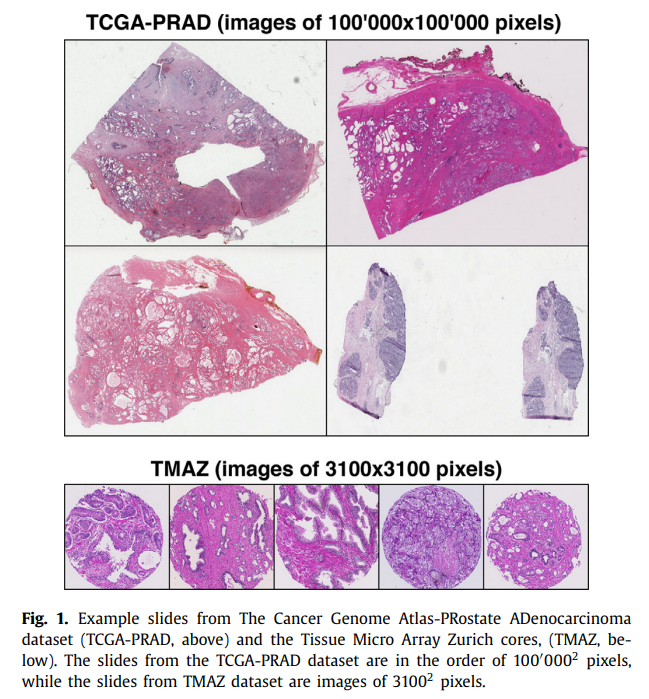
WSI(Whold Slide Image)의 경우 해당 이미지를 얻는 과정(acquisition procedure)이 기관마다 달라 매우 이종적인(heterogeneous) 형태를 가짐. Heterogeneous의 대표적인 예시가 Fig. 1.에 나타남. 하나의 샘플(조직)을 저장할 때, 이미지의 스케일이 3,100x3,100에서 100,000x100,000까지 차이가 나타남.
또한, 각 WSI의 크기가 매우 크기 때문에 local annotation(pixel-level label)을 얻기 매우 어려움. 이러한 문제는 supervised learning 진행을 어렵게 함.
이러한 문제 상황에서, 본 논문은 local annotation이 없는 다양한 데이터 소스를 활용하여 CNN의 성능을 보다 향상시킬 수 있는 방법을 제안함. Teacher / Student training paradigm을 따르며, 실험 결과 inter-dataset heterogeneity 문제와 small number of local annotations 문제에도 보다 높은 성능을 달성하였음.
Teacher / Student model을 사용하지만, Teacher의 출력에 student를 학습시키는 일반적인 지식 증류와는 다릅니다. 이름만 teacher / student로 명명했다고 이해하시면 될 듯합니다.
본 논문에서는 전립선암에 대한 WSI를 다루며, 각 이미지의 Gleason score(patttern)를 분류하는 작업을 수행함. Gleason score 관련 이미지는 아래를 참고.
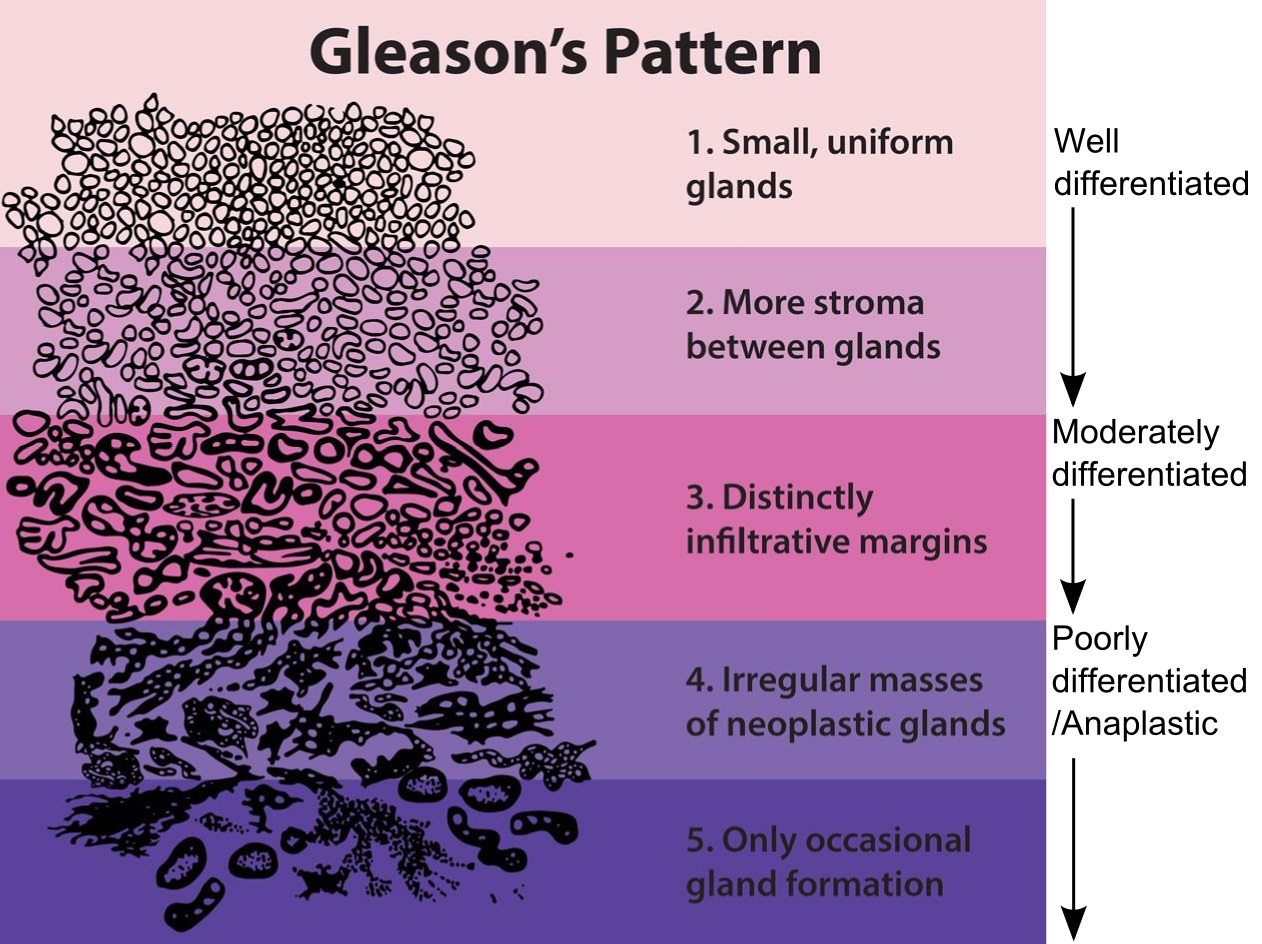
[이미지 출처]
Method
Datasets
본 논문에서는 두 가지의 데이터셋을 활용함. 각 데이터는 Fig. 1.의 TCGA-PRAD 데이터셋과 TMAZ 데이터셋임. 이미지의 사이즈가 매우 다른 highly heterogeneous dataset임.
TMAZ 데이터셋의 각 core는 3,100 x 3,100 픽셀의 크기를 가지며, 40배율로 스캔 되었음. 또한, pixel-wise annotations를 가지고 있음. 4가지의 클래스를 가지며, 각 클래스는 benign, Gleason pattern(GP) 3, GP 4, GP 5임.
TCGA-PRAD 데이터셋의 경우, 40배율로 스캔되었으며 각 이미지는 약 100,000 x 100,000 픽셀의 크기를 가짐. TMAZ 데이터셋과 달리, annotation 없이 병리학자의 reports만 제공됨(GP3, GP4 등). TCGA-PRAD의 경우 benign 클래스를 포함하지 않음.
각 데이터셋에 대한 자세한 정보(훈련/검증 샘플 수 등)는 원본 논문을 참고.
Data Analysis Pipeline
모델 훈련은 앞서 언급한 것과 같이 Teacher / Student training paradigm을 기반으로 함. Teacher model은 high-capacity의 네트워크이며, 이후 student 모델 학습을 위한 pseudo label을 생성함. 본 논문에서는 ResNext 모델을 사용하였음.
아래의 Fig. 2.로 본 논문에서 제안하는 Teacher / Student training paradigm을 요약할 수 있음.
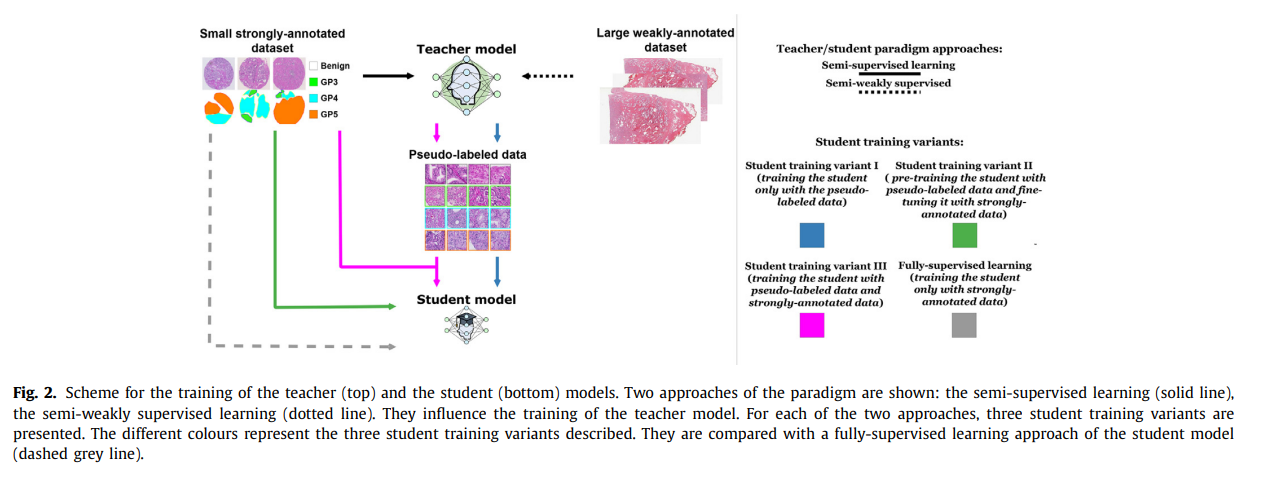
본 논문에서는 Teacher 모델을 학습할 때 두 가지의 방법을 사용하였음. 하나는 semi-supervised learning approach로, teacher 모델은 strongly-annotated data(TMAZ)만을 사용하여 학습됨. 다른 방법은 semi-weakly supervised learning approach로, teacher 모델은 weakly-annotated data(TCGA-PRAD)에서 pre-train 된 후 strongly-annotated data에서 fine-tune 됨.
Student 모델의 경우, teacher 모델에 비해 파라미터 수가 더 적어 훈련 및 추론 시간이 짧은 모델을 사용함. Teacher 모델에 의해 생성된 pseudo-labeled data와 strongly-annotated(pixel-wise label) data를 모두 사용하여 학습을 진행함.
Student 모델 학습의 경우, 3가지의 variant가 존재함.
- Baseline approach : Fully-supervised learning approach로, pseudo label 없이 strongly-annotated data만을 사용함.
- Variant I : Teacher에 의해 생성된 pseudo-labeled data만을 사용하여 학습
- Variant II : Teacher에 의해 생성된 pseudo-labeled data를 사용하여 pre-training, 이후 strongly-annotated data로 fine-tuning
- Variant III : Teacher에 의해 생성된 pseudo-labeled data와 strongly-annotated data로 함께 훈련
Experimental Setup
전체 WSI는 background region을 제외하고 모두 patch(tile)로 분할되어 모델로 입력됨. 40배율 스캔 이미지에서 750x750 사이즈의 patch를 추출하고, CNN 입력 크기에 맞도록 224x224로 다운샘플링 함.
TMAZ 데이터셋의 경우 annotation이 존재하므로 background를 구분할 수 있으며, TCGA-PRAD의 경우 HistoQC tool을 사용하여 tissue mask를 생성한 후, mask를 사용하여 background를 구분하였음. 또한, HistoQC를 사용하여 pen-marking 등 artifacts를 제거하였음.
Patch 추출의 경우, 아래의 과정을 따름.
- TMAZ : 각 core 당 overlapping을 허용하여 30개의 patch를 추출.
- TCGA-PRAD : WSI를 overlapping이 없는 grid cell로 분할한 다음 patch 추출. WSI마다 약 400~12,000개의 patch를 추출하였음.
Weakly-annotated data(TCGA-PRAD)의 경우, 아래의 Fig. 3.와 같이 학습에 사용됨.
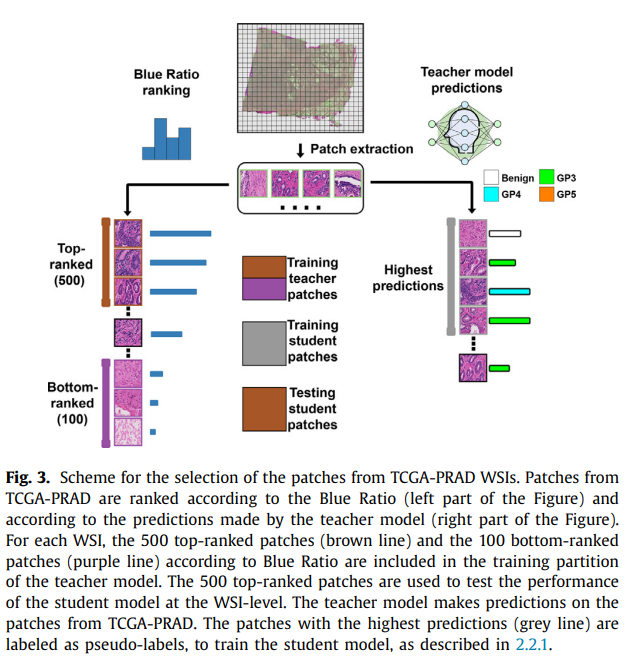
TCGA-PRAD의 첫 번째 set(patches)은 teacher 모델을 학습시킬 때 사용됨. 이는 semi-weakly supervised learning approach의 경우에서 적용됨. 각 patch는 patch-level label이 없으므로 slide image의 label을 그대로 사용함.
Weak label로 인한 noise 문제를 줄이기 위하여, 학습에 모든 patch를 사용하지 않음. Blue-Ratio(BR) technique을 사용하여 지방(fat) 영역 등 nuclei(핵)이 없는 patch를 구분함. 모든 patch들은 BR 점수로 정렬되며, Top-ranked patch와 Bottom-ranked patch를 학습에 사용함. Bottom-ranked patch를 benign class로 사용함.
아래는 Blue-Ratio technique을 제안한 논문의 이미지임.
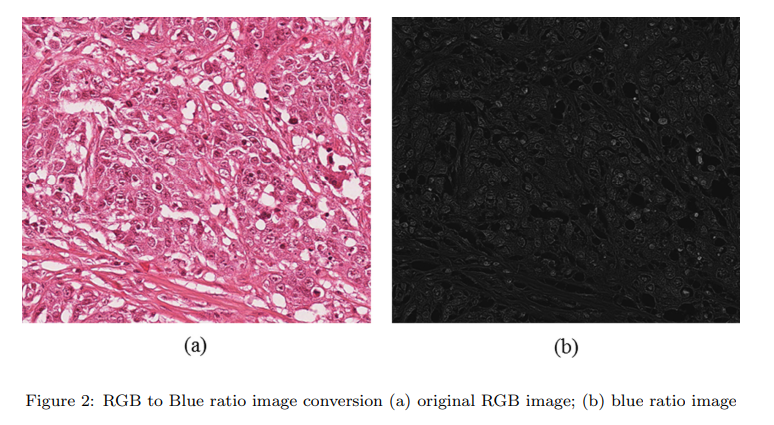
[Paper : Saha, Monjoy, Chandan Chakraborty, and Daniel Racoceanu. "Efficient deep learning model for mitosis detection using breast histopathology images." Computerized Medical Imaging and Graphics 64 (2018): 29-40.]
BR Image : The main goal of the conversion is to find the most prominent and high brightness objects within the image.
두 번째 set은 student 모델 학습에 사용됨. Teacher 모델이 patch에 대한 확률 값을 추정하면, 확률 값이 높은 top K개의 patch를 추출하여 pseudo-labeled data로 사용함.
Data Analysis Implementation
Teacher 모델은 Resnext50_32x4d 모델을 사용하였으며, YFCC100M dataset(Instagram images and hashtags)에서 pre-trained 하였음. Student 모델은 DenseNet121을 사용하였고, 해당 모델은 ImageNet에서 pre-trained된 가중치를 사용하였음.
모델 학습 시 Class-wise data augmentation(CWDA)을 적용하였음. 이미지마다 rotation, flipping, color augmentation이 적용되며, 클래스 불균형 문제를 완화하도록 class augmenting을 적용함.
모델의 성능을 평가하기 위하여 Quadratic weighted Cohen Kappa score()를 사용함. Optimal Kappa는 1이며, random distribution의 경우 0의 값을 가짐. 자세한 것은 아래의 블로그 포스팅을 참고.
https://blog.naver.com/PostView.nhn?blogId=y4769&logNo=220680837692
이 외의 자세한 학습 구현 내용은 본 논문을 참고.
Results
아래의 Fig. 4.와 Fig. 5.를 통해 실험 결과를 확인할 수 있음.

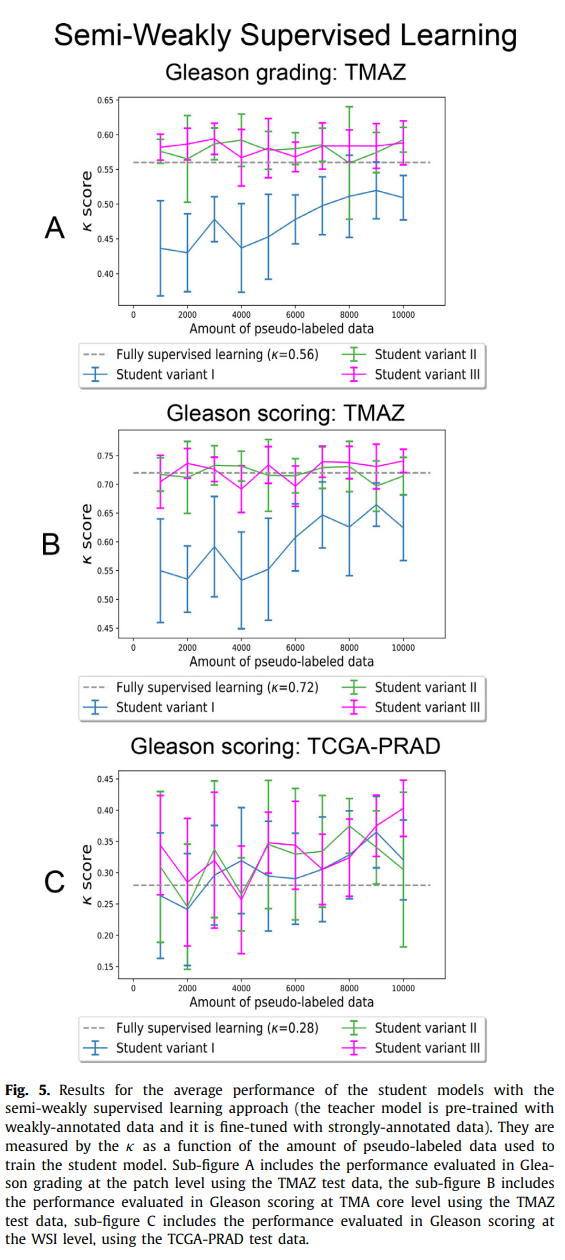
실험 결과, 제안된 방법을 통해 학습된 student 모델이 baseline approach에 비해 유의미한 성능 향상이 있음을 확인하였음.
Pseudo-labeled data의 양이 증가할수록 모델의 성능이 단조 증가하지 않음. 이는 어쩔 수 없이 pseudo label에 나타나는 noise의 영향으로 보임.
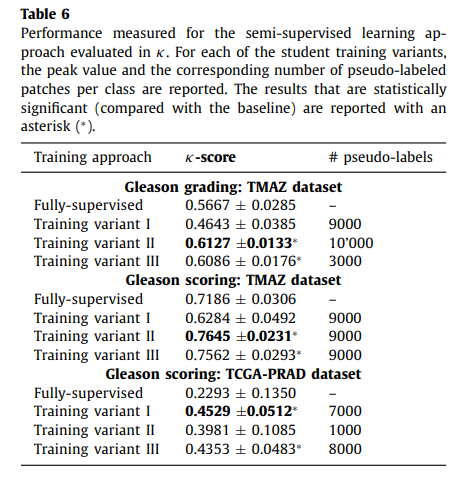
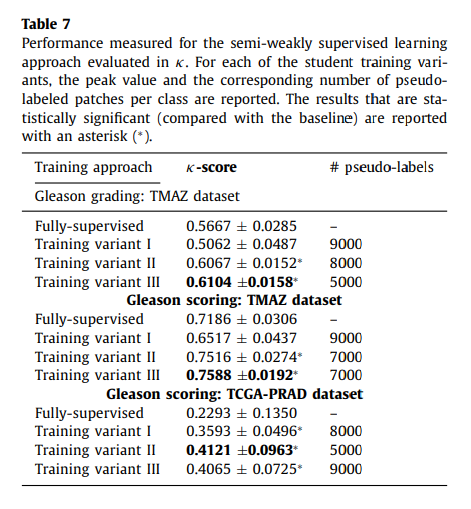
두 개의 Classification task(Grading, Scoring)에서, Semi-supervised learning approah(for teacher model) 기반의 방법이 모두 가장 좋은 성능을 보여주었음.
Semi-supervised approach가 semi-weakly supervised approach에 비해 조금 더 나은 성능을 보여주었는데, 이는 생성되는 pseudo label에 의한 것으로 보임.
Semi-supervised approach의 경우, weakly-annotated 데이터를 학습에 사용하지 않으므로 less noisy 한 pseudo label을 생성함. 결과적으로, 생성되는 pseudo label에 noise가 적은 semi-supervised approach가 더 좋은 성능을 보였을 것이라 추측할 수 있음. Weakly-annotated data를 사용하여도 noise가 적은 pseudo label을 생성할 수 있는 방법을 추가로 연구해야 함.
TMAZ patch에서 fully-supervised learning으로 학습된 모델은 동일한 데이터셋에서는 충분히 좋은 성능을 얻음. 하지만, 해당 모델을 TCGA-PRAD 데이터셋에서 평가하면 그 성능이 좋지 않음을 확인할 수 있음. 이는 하나의 데이터셋에서만 훈련된 모델은 안정적인 일반화 성능을 얻을 수 없음을 의미함.
본 논문에서 제안하는 pseudo labeling과 teacher/student approach를 사용하면 highly heterogeneous data 문제와 lack of large datasets with local annotations 문제를 완화할 수 있을 것임.
