Python3.12 - subinterpreter와 GIL

본 글은 GIL, Thread와 Process의 차이, IPC, interpreter에 대해 사전 설명을 하지 않습니다. subinterpreter와 interpreter라는 용어가 혼재되어 있습니다. 본 글에서는 글을 같은 의미로 이해하여도 괜찮습니다.
Python3.12가 업데이트되었습니다. new features가 여러 개 공개되었는데 개인적으로 가장 흥미로운 부분은 “Support for isolated subinterpreters with separate Global Interpreter Locks (PEP 684)” 이었습니다. 이를 살펴보면서 subinterpreter에 대해 간략하게 공부한 내용을 정리 해보고자 합니다.
subinterpreters
subinterpreter는 하나의 파이썬 프로세스에서 main interpreter와 독립적인 실행 환경을 가지고 병렬적으로 실행할 수 있는 인터프리터를 의미합니다. (Python 1.5 이후로, 여러 인터프리터를 가질 수 있는 C-API가 있습니다.) 그런데 무엇이 독립적일까요? 스레드도 독립적인 stack 영역이 있는데 이와 유사한 것일까요? 아니면 프로세스처럼 메모리 영역과 네임 스페이스 등이 독립적인 것일까요? 이해도를 높이기 위해 아래 사진을 봅시다.
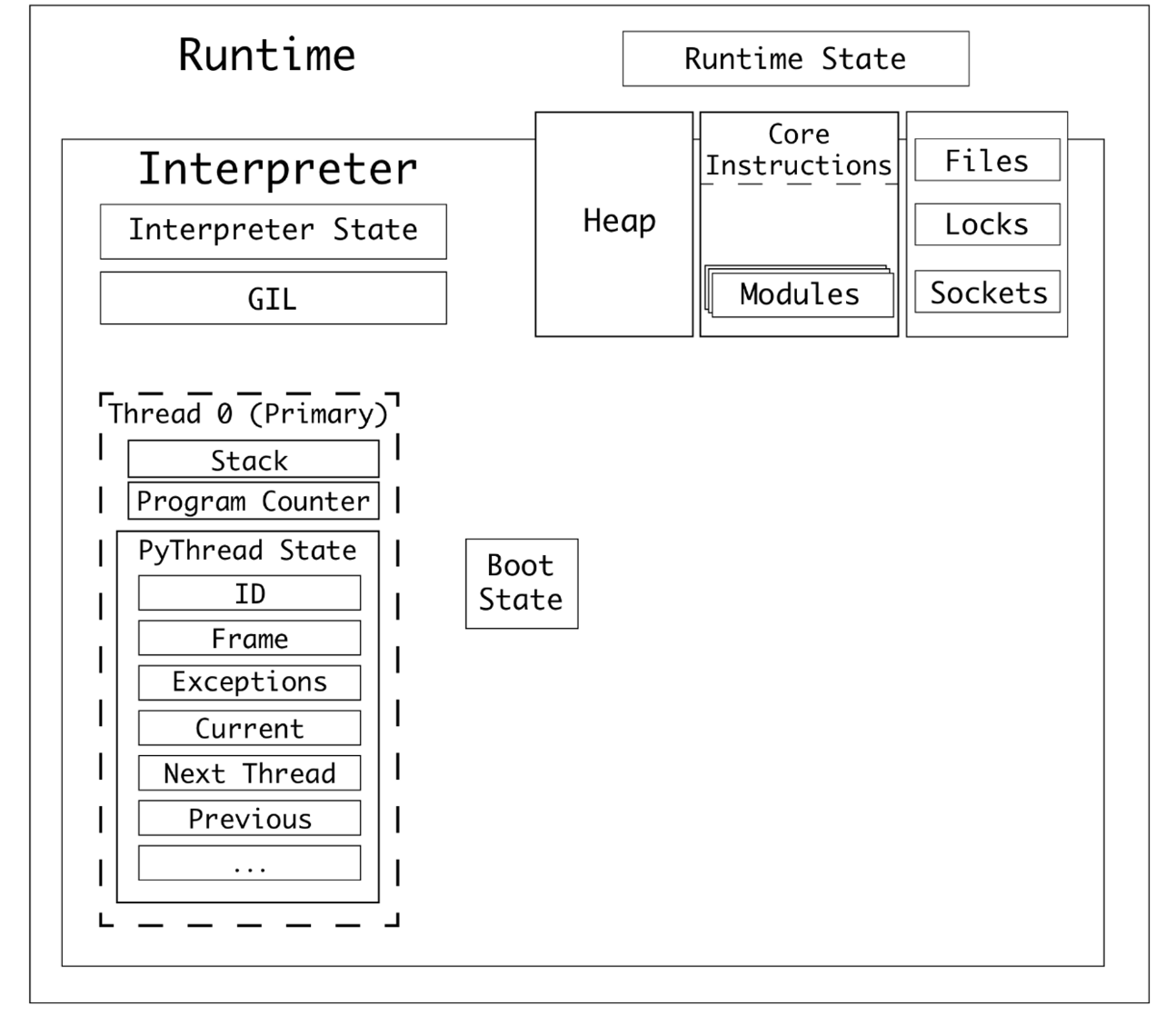
파이썬에는 모든 인터프리터가 공유하는 Runtime State(global state of Cpython 정도로 이해하면 편합니다.)이 있습니다. 그리고 Interpreter마다 interpreter state가 있고, Thread마다 각자의 stack 영역이 있죠. subinterpreter의 경우 독립적인 공간을 가진 스레드 집합체라고 이해하시면 됩니다. interpreter에서 thread를 생성하면 다른 interpreter에서는 보이지 않습니다. 또한 global scope name table, import 한 module 등은 독립적입니다. 하지만 OS가 프로세스에 할당한 것(메모리, 파일 핸들러 등)은 독립적이지 않습니다. Thread가 같은 global scope name table을 가지고 heap 영역을 공유하고, Process는 서로 다른 memory sapce를 가진다는 것과 다르죠.
subinterprter의 메모리가 독립적이지 않다는 의미는 OS에 할당받은 같은 memory space를 interpreter끼리 공유하여 사용한다는 의미이고, heap 영역이나 stack 영역은 서로 독립적입니다.
thread, process와 비교했을 때 어떠한 장점이 있을까요?
untrusted code를 실행해야 하는 상황을 생각해 봅시다. 현재 interprter와 격리된 레벨에서 실행하므로 thread보다 상대적으로 보안 측면에서 더 뛰어나겠죠. global scope name table을 다르게 하고 싶거나 다른 모듈을 사용하고 싶을 때도, thread가 아닌 subinterprter가 적절하겠죠. 또한 같은 프로세스 내에서 실행되기 때문에 multi-processing보다 communication 비용이 더 적지 않을까요? (물론 interpreter 간의 data sharing은 직접적으로는 불가능하며 OS.pipe()를 사용해야 합니다. 당연히 직렬화와 역 직렬화 비용이 들어갑니다. 추가로 multi-processing 때 고려 해야할 문제도 고민 해야하고요.)
multi-threading, multi-processing의 장점만 모아둔 것 아니야?
우리는 앞서 Runtime State를 전체 interprter가 공유한다고 배웠습니다. GIL도 여기에 포함됩니다. 즉 true parallelism을 달성할 수 없었죠. subinterpreter 생성이 process를 하나 더 실행하는 것보다 빠르기는 하지만 thread를 생성하는 것보다는 당연히 느립니다. 이점이 많이 상쇄되기도 하고 python의 stdlib내에 포함되어 있지도 않아서 사용이 번거롭습니다.
3.12의 변화 - A Per-Interpreter GIL
PEP 684에서 자세히 보실 수 있습니다. 3.12에서는 Runtime State에서 GIL을 interpreter state로 옮겼습니다. 정말 간단해 보이지만 이 과정은 7년 이상이 소요 되었습니다. GIL은 여러 thread가 동시에 Runtime State에 접근하는 것을 방지해 race condition을 방지하고 있었기 때문입니다. 이를 위해 많은 변경 사항이 있었습니다. "obmalloc" 을 runtime state에서 interpreter state로 변경한 것도 하나의 예시입니다. 더 자세한 이야기는 여기를 통해 확인해 보세요! 와 그러면 이제 Cpython에서도 true parallelism을 기대해 봐도 좋을까요? 필자가 3.12 버전을 통해 여러 방면으로 실험해 보려 했으나 실험 코드 작성이 쉽지도 않고 누군가 저보다 훨씬 잘 정리를 해놓았기에 링크를 남깁니다. 성능 비교도 보기 좋게 해두었습니다.
subinterpreter의 stdlib 편입, GIL 제거
PEP 554, PEP 734는 현재 프로세스에서 interpreter를 생성하고, 분석하고, 실행시키는 새로운 모듈인 interpreters를 표준 라이브러리에 포함하는 것을 제안합니다. 아직 accept 된 것은 아니라 어떻게 될지는 모르지만 잘 만들어져서 편하게 사용했으면 좋겠네요 :) 이외에도 GIL을 Optional로 변경하려는 PEP 703 논의도 있습니다. 3.13에서 반영이 될 예정이라고 합니다.
출처 및 후기
GIL과 관련하여 큼직한 변화들이 나오고 있어 흥미로웠습니다. 현재 회사에서 Python을 사용 중이기에 계속 변화를 따라가고자 합니다. 설계에 대한 공부가 많이 필요함을 느끼기도 했습니다. 현재 글과 큰 관련은 없지만
하이퍼 컨넥트의 파이썬 성능 최적화 글을 읽으며 Python의 multi-processing에 대해 상당히 많이 배웠습니다.
