The State of AI & Art 2022

AI도 예술이 될 수 있는가?

2022년의 The State of AI를 사진 1장으로 말하라면, 이 사진이 아닐까 싶다. 그리고 The State of Art 2022를 말하라고 해도, 나는 저 사진을 말할 것이다.
기사(영어 기사, 한국어 기사)로 많이 소개되어서 아는 분들도 있겠지만, AI로 만든 이미지가 미술대회에서 1위를 수상하게 되면서 논란이 생겼었다. AI가 그린 그림을 창작물이라고 말할 수 있는가?라는 의문은 200년 전 "사진은 예술인가?"라는 질문의 반복이라는 생각을 들게 하면서도, AI까지도 예술이라고 한다면 대체 예술이 있나라는 의문도 들게 한다. 이 모든 일이 2022년 단 1년 동안 진행되었다. 미래에 2022년이 엄청난 특이점이었음을 반복해서 이야기하게 되지 않을까 싶다.
The State of AI 2022
2022년의 AI를 말하자면, text-to-image라고 말할 수 있을 것이다. 그리고 더 많은 사람들이 더 많은 프로젝트들이 나오면서, The State of AI를 넘어 The State of Art를 말할 수 있는 해가 되었다. 그래서 이 글의 제목이 탄생했다. 그리고 이제 왜 2022년이 AI와 Art가 함께 만난 큰 특이점이 생긴 해가 되었는지에 대한 이야기를 하려고 한다.
2021 - 서막
 Prompt: "Inside a room alien spaceship with large window that provide a scenic view of a huge planet can be seen in the background, Highly detailed labeled, poster, aesthetic, haeccety, trending on artstation, trending on cgsociety"
Prompt: "Inside a room alien spaceship with large window that provide a scenic view of a huge planet can be seen in the background, Highly detailed labeled, poster, aesthetic, haeccety, trending on artstation, trending on cgsociety"
모든 것의 시작은 OpenAI에서 발표한 이 녀석이라고 말할 수 있다. 그러니 이 이야기를 안 하고 시작할 수 없다, 아보카도 의자에 대한 이야기를.
DALL-E (Jan, 2021)

OpenAI가 2020년에 GPT-3라는 엄청난 걸 발표하였고 2020년은 그대로 NLP의 해가 되었다. 그리고 다들 NLP, 그러니까 Text에 빠져 있을 때 갑자기 2021년은 이제 새로운 해다!(해로운 새다!)라고 말하는 것처럼 1월에 DALL-E라는 text-to-image AI 모델을 발표했다.
이미지를 설명하는 Text Prompt(input)을 입력하면 그에 맞는 Image를 생성해주는 AI 모델이다. 기존에 이미지를 관련 AI의 경우, 기존에 있던 사진의 Style을 바꿔준다던가, 혹은 어설픈 결과를 내서 티가 많이 나는 AI가 많았다. 그러나 DALL-E는 위에 사진에서 보는 것처럼 아보카도 의자라는 현실에는 없는 의자를 만들어 달라고 해도 현실에 있는 것 같은 의자를 만들어 줬다. 좀 더 솔직히 말하자면, 내 그림 실력은 아득히 뛰어넘었다. (물론 이건 내 그림 실력이 C 언어 같은 면도 크긴 하나)
아무튼!

그러나 OpenAI에서 논문과 함께 DALL-E를 만들었다고 공개를 하긴 했지만, 모두가 쓸 수 있게 열어주지는 않았다. 초대받은 일부의 사람들만 써볼 수 있었기에 대부분의 사람들에게는 그림의 떡 일 수밖에 없었다.
 Prompt: "a high quality picture of a korean rice cake which is in picture frame"
Prompt: "a high quality picture of a korean rice cake which is in picture frame"
직접 만들어 보면 어떨까?
DALL-E를 만드는 방법은 복잡하지 않다. 딱 3가지만 하면 된다.
- CLIP(Contrastive Language-Image Pre-training)이라고 하는 AI Model을 만든다.
(이미지를 넣으면, 그 이미지에 대한 설명을 해주는 AI Model이다)
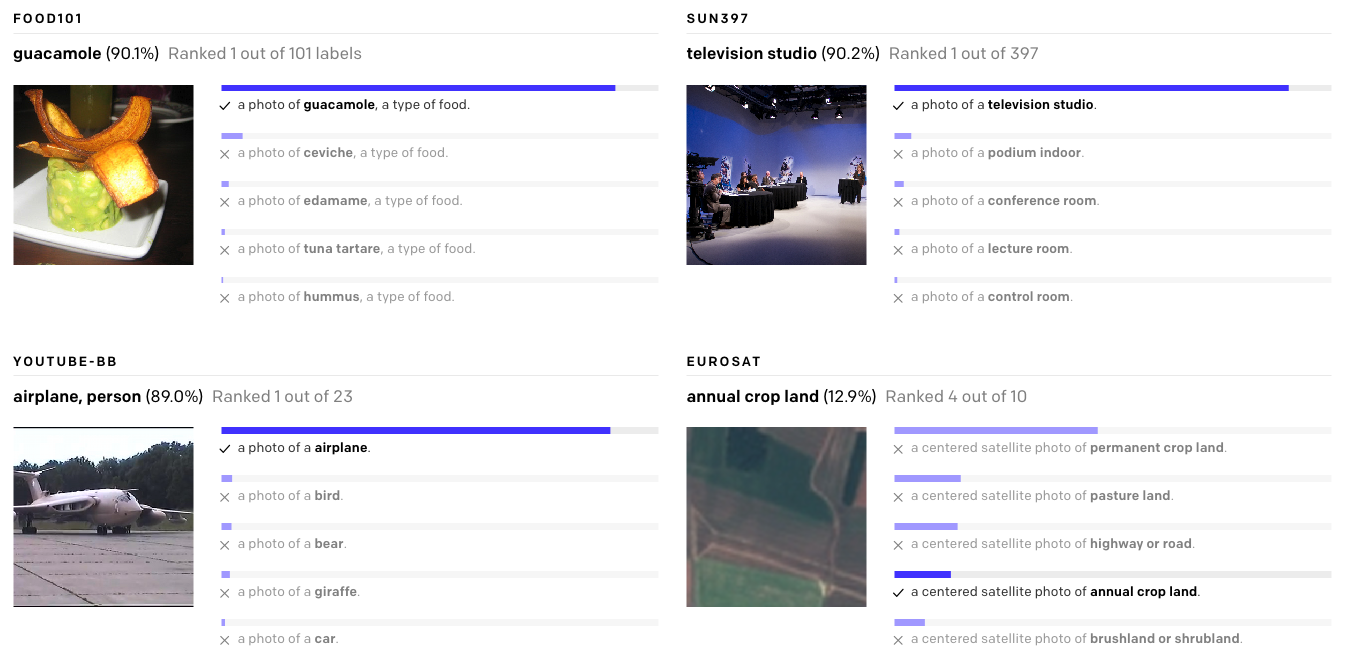
- Diffusion Model을 만든다.
(노이즈가 있는 이미지에서 실제 이미지를 만들어 주는 AI Model이다)

- CLIP과 Diffusion을 잘 합친 후에, 거기에 값 비싼 GPU들을 쏟아 넣는다.
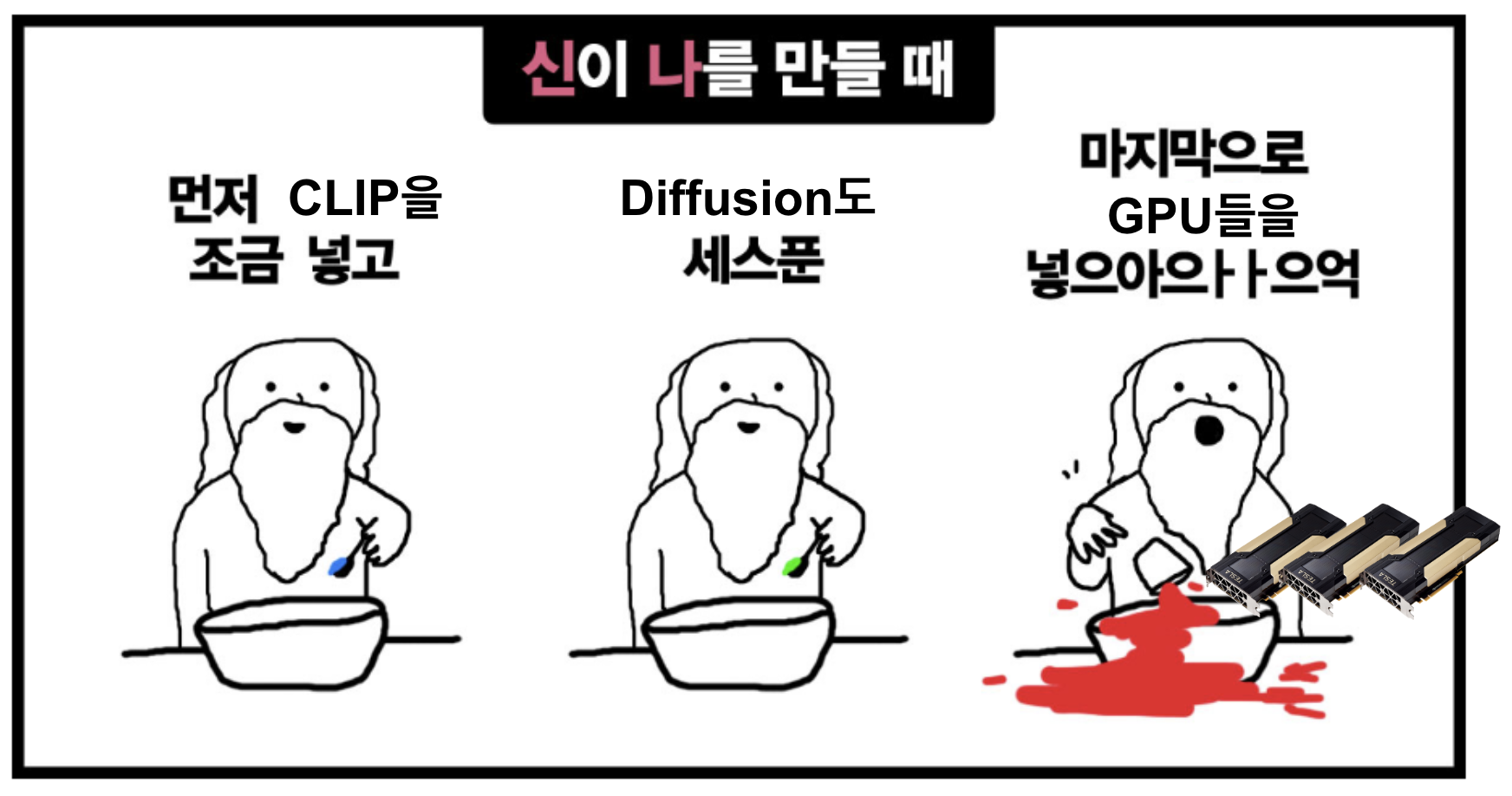
이러면 된다, 참 쉽죠 ^^
 Prompt: "Bob ross painting a picture of bob ross"
Prompt: "Bob ross painting a picture of bob ross"
쓰고 싶지만 써볼 수 없는 상황이었다. 자꾸 생각나지만 어쩔 수 없었다. 그냥 과몰입하지 마는 수 밖에는
Disco Diffusion (Oct, 2021)
 Prompt: "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.", "yellow color scheme"
Prompt: "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.", "yellow color scheme"
빨리 가려면 혼자 가고, 멀리 가려면 함께 가라. - 아프리카 속담
작년 10월에 Disco Diffusion이라는 오픈소스 기반의 text-to-image AI Model이 출시되었다. 아마도 대부분 그때는 이름조차 못 들어보셨을 것이다. 저도 그랬었고.
오픈소스로 만들어지고 단 하나의 Jupyter Notebook 파일로 실행하고 이용해 볼 수 있던 Disco Diffusion은 파일 하나라는 편의성과 Google Colab에서 쉽게 실행해 볼 수 있다는 큰 장점이 있었다. 전자는 커뮤니티 기반으로 빠른 버전업을 가능하게 했고(v1 -> v5까지 불과 5개월), 후자는 더 많은 사람들이 AI를 써보게 만들었다.
그리고 올해 2월 정도가 되자, 개발자가 아닌 사람들이 후자의 상당 부분을 차지하게 된다. 우리가 Artist라고 부르는 분들이.
 View from the Window at Le Gras, 1826
View from the Window at Le Gras, 1826
 Derrière la gare Saint-Lazare, Henri Cartier-Bresson, Paris, 1932
Derrière la gare Saint-Lazare, Henri Cartier-Bresson, Paris, 1932
개발자들이 만든 text-to-image의 결과물이 첫 번째 사진이 기술적 Demo를 보여주기 위한 것들이라면, 예술가들은 AI를 이용해 두번째 사진과 같은 예술적인 결과물들을 만들어내기 시작했다. Instagram에서 #discodiffusion으로 검색해보면, 아래와 같이 멋진 결과물들을 찾아볼 수 있다.

우리가 아는 고흐, 고갱이 파리 카페에 모여 미술에 대해 논하던 것처럼, 21세기의 예술가들도 같이 모여서 다양한 결과물과 더 좋은 결과물을 위한 Case Study를 진행하고 있었다.
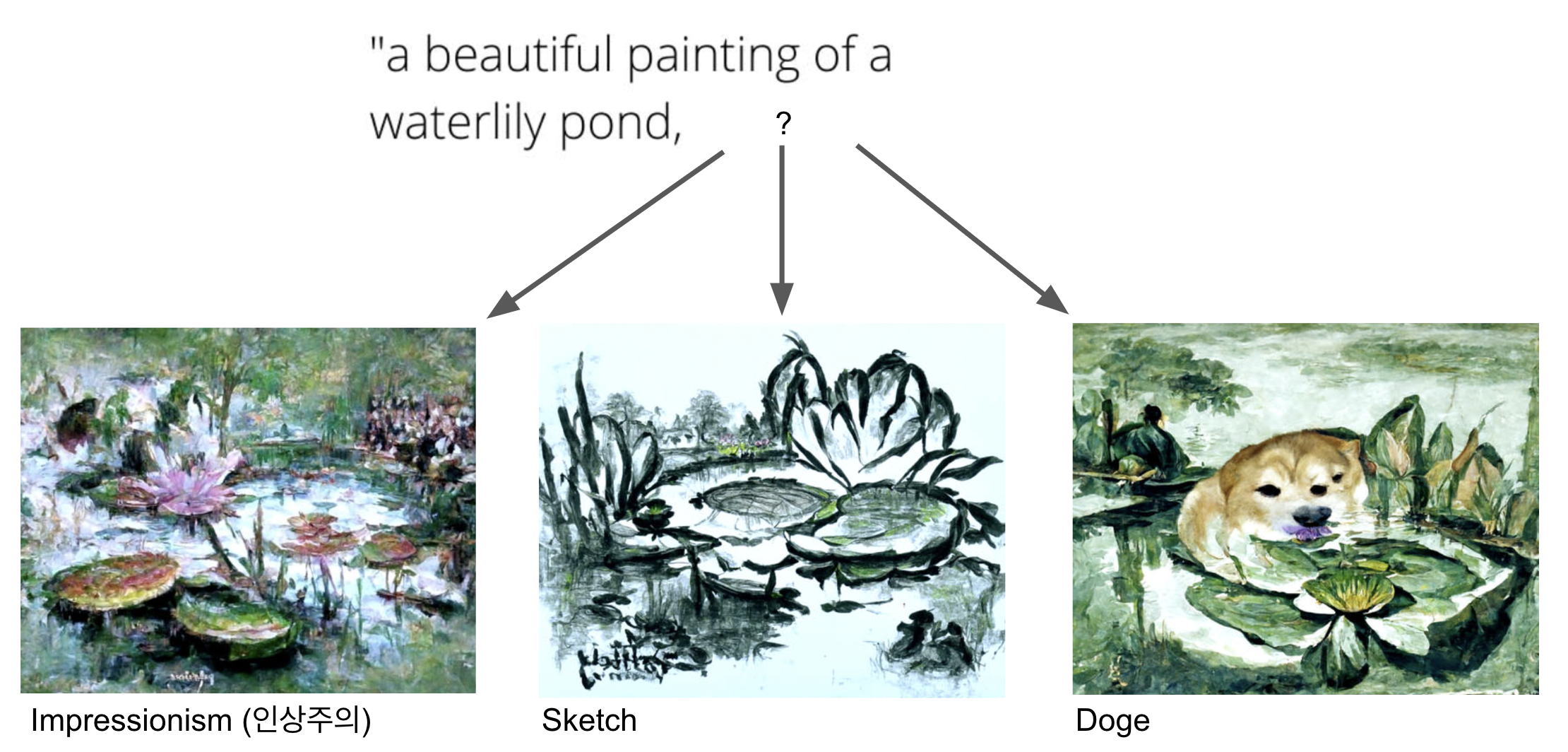 같은 Prompt에 마지막에 style 부분에 해당되는 단어에 따라 결과물이 달라진다
같은 Prompt에 마지막에 style 부분에 해당되는 단어에 따라 결과물이 달라진다
--
2022년 초에 벌어진 이러한 변화는 향후 몇 년 뒤를 상상하게 만들었다. AI 분야에 예술가들이 참여하게 된다면, 어떤 일이 일어날까? 얼마나 멋진 일이 일어날까? 그리고 그렇게 되면 예술은 어떻게 될까? 그리고 그것에 영향을 받는 다음 세대 AI는?
그렇게 몇 년 뒤를 상상하고 있었는데...
2022 - AI x Art
MidJourney (Mar, 2022)
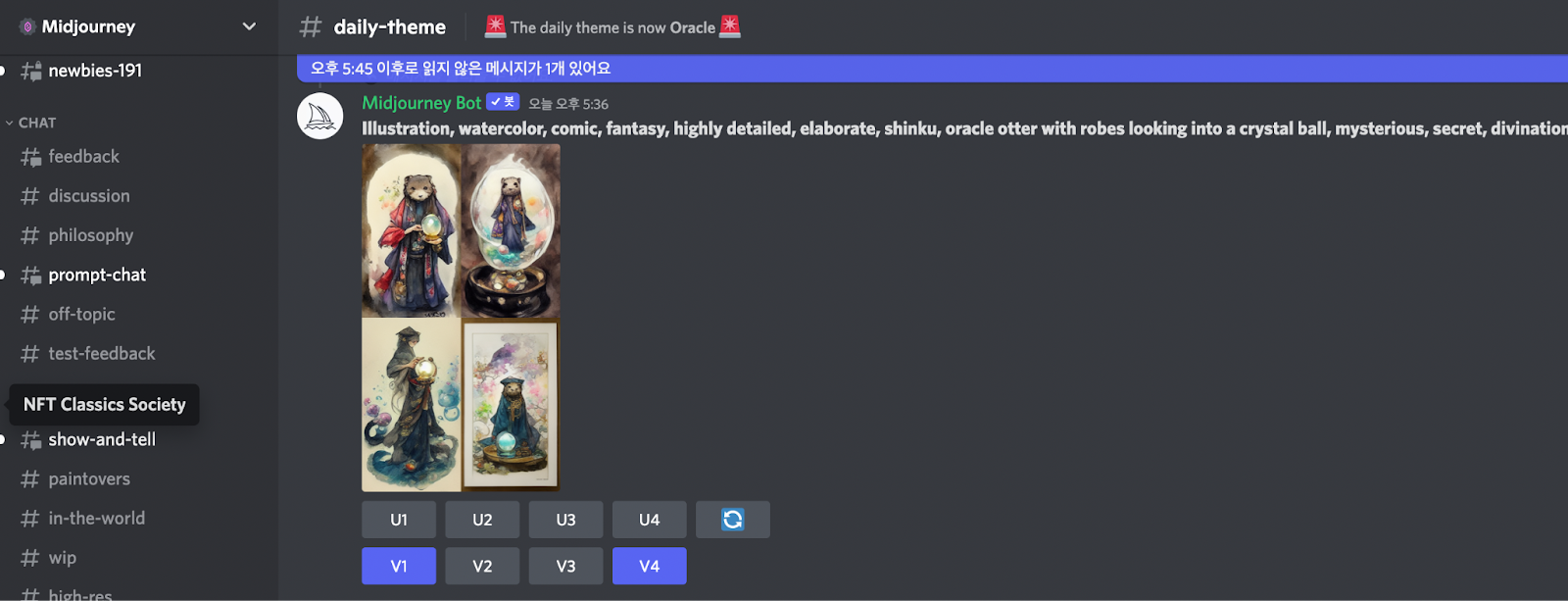
Disco Diffusion은 AI Model을 직접 만드는 것보다는 훨씬 쉬웠지만, 그렇다고 어느 정도는 코드를 보거나, 주변이 도와줄 수 있는 사람만 쓸 수 있는 형태였다. 사실 가장 간단하고 쉬운 형태는 input으로 prompt text만 받고, output으로 image만 보여주고 저장할 수 있게만 해주는 것이었다. 그리고 이걸 MidJourney라는 곳에서 처음으로 해냈다. Web도, App도 아닌 Discord Bot이라는 새로운 형태로.
 키보드만 칠 줄 알면, 야 너두 할수있어
키보드만 칠 줄 알면, 야 너두 할수있어
다음과 같이 Discord 상에서 /imagine prompt: "a photo of drawing Robot" 이라고 명령어만 치면, 아래 사진과 같은 결과물을 얻을 수 있다.

편의성도 편의성이지만, 같은 prompt text를 넣었을 때 나오는 결과물이 기존에 있던 Disco Diffusion에 비해 훨씬 좋았다.
 disco diffusion에 "a photo of drawing Robot"을 넣었을 때 나오는 결과물
disco diffusion에 "a photo of drawing Robot"을 넣었을 때 나오는 결과물
이렇게 편하니, 개발자가 아닌 일반인들도 쉽게 와서 쓸 수 있었고 불과 출시 6개월 만에 200만 명이 넘는 사용자를 모았다. 그리고 이것도 현재 진행 중이어서, 지금 들어가 보면 몇십만, 혹은 100만이 더 늘었을 수도 있다.
200만 명이 얼마나 대단한 숫자냐면, 출시한 지 20년이 지난 AWS의 MAU(월간사용자)가 100만 명이다. AWS에도 SageMaker와 같은 다양한 AI 서비스들이 있을텐데, 그걸 쓰는 사람들을 다 합쳐도 10만 명은 넘으려나? 그런데 MidJourney는 불과 6개월 만에 그것보다 훨씬 많은 AI 사용자들을 모았다. 시리나, 파파고처럼 간접적으로 쓰는 유저가 아닌 직접적으로 "나는 AI로 그림을 만들 거야"라고 말하는 사용자들을 말이다.

DALL-E 2 (Apr, 2022)
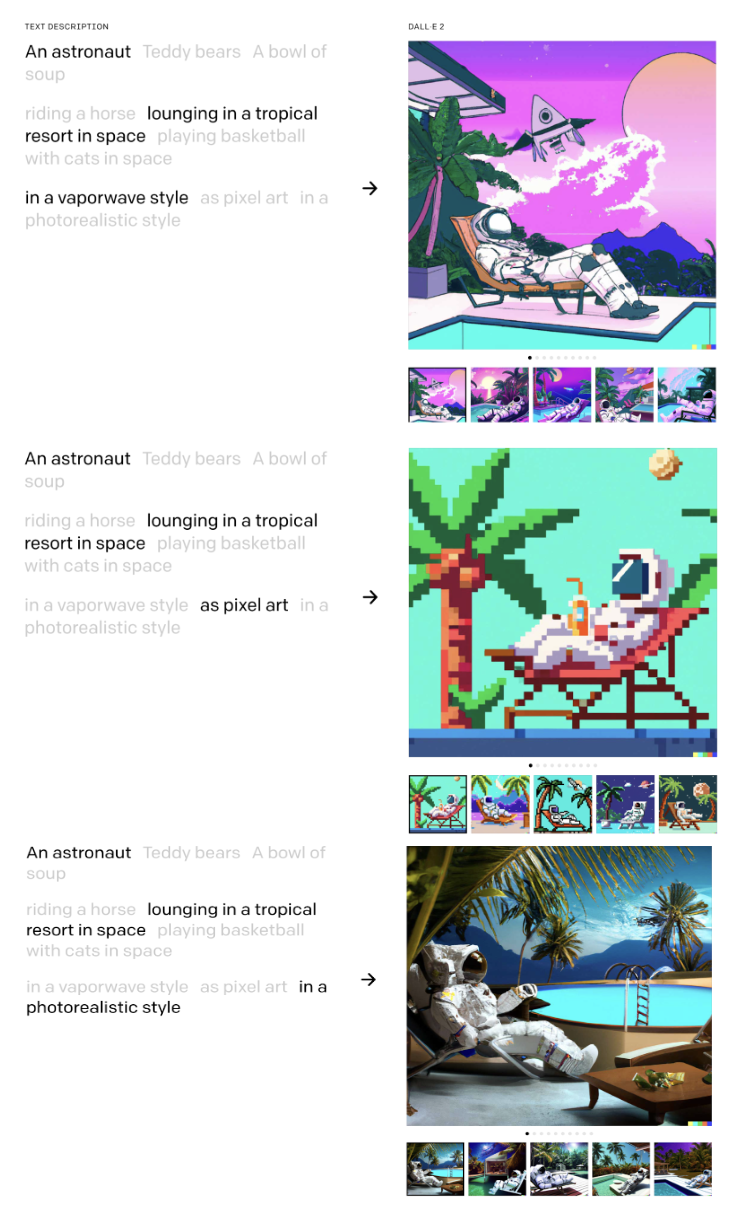
OpenAI에서도 작년에 발표한 DALL-E를 개선한 DALL-E 2를 4월에 공개했다. 영화와 다르게 기술은 보통 1보다 2가 거의 항상 좋듯이 DALL-E 2도 1에 비해 성능이 좋아졌다.
 같은 Prompt를 넣으면 더 좋은 결과물에 4배 좋은 해상도의 이미지를 얻을 수 있다
같은 Prompt를 넣으면 더 좋은 결과물에 4배 좋은 해상도의 이미지를 얻을 수 있다
또한 다음 같은 게 가능해졌다. 원본이 될 Image를 업로드하고 일정 부분만 prompt를 작성하여 AI로 채워 넣을 수 있게 되었다.
 3번 영역에 강아지를 그려달라고 했을 때의 결과물
3번 영역에 강아지를 그려달라고 했을 때의 결과물
개인적으로 생각하는 가장 큰 변화이자, 실감할 수 있는 변화는 DALL-E 2로 만든 결과물을 상업적으로 쓸 수 있게 되었다는 점이다. 그 전에는 라이센스 정책이 상업적으로 쓸 수 없다고 되어 있었다. 특히 NFT는 절대 안 된다고 명시까지 했었는데, 유료화 가격 정책(실행 한 번당 100원 정도)과 함께 상업적으로 쓸 수 있도록 라이센스가 바뀌어서 이제 마음 놓고 AI로 만든 이미지를 쓸 수 있게 되었다.
실제로 이렇게 바뀐 라이센스 덕분에 기존에 스톡포토 사이트에서 사서 쓰던 이미지들을 AI로 직접 만들어서 쓴 사례도 있고, 이걸 이용해서 동화책의 삽화나 앨범 커버 등을 만드는 사례도 있는 것으로 알고 있다.
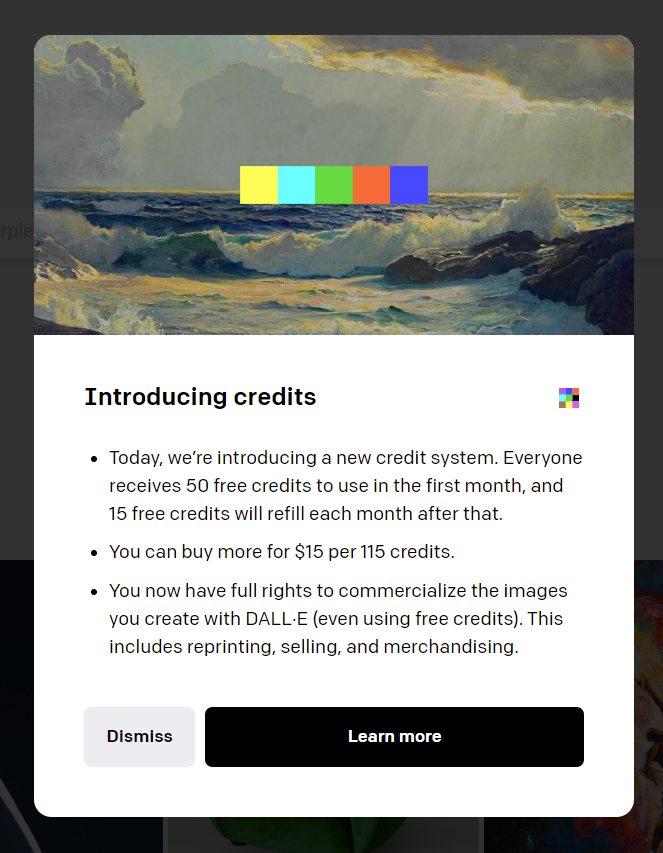 무료 credit도 50을 주지만, 테스트 좀 하다 보면 금방 쓰긴한다ㅠ
무료 credit도 50을 주지만, 테스트 좀 하다 보면 금방 쓰긴한다ㅠ
Stable Diffusion (Aug, 2022)

8월에 갑자기 두둥! 등장한 Stable Diffusion은 stability.ai라는 스타트업에서 공개한 AI 모델이다. 기존에 나왔던 것들을 장점들을 모두 흡수한 것 같은 모습을 하고 있다. 일단 Disco Diffusion에서 핵심이었던 Jupyter Notebook 제공과 오픈소스라는 것을 그대로 흡수하였다. Jupyter Notebook 파일은 기본이고 Google Colab, HuggingFace Space도 제공되어 바로 실행까지 해볼 수 있었고, 코드도 오픈소스로 공개되었다. 또한 DALL-E 2처럼 돈을 내면 그냥 Web에서 Cloud Service처럼 이용해 볼 수 있게도 제공해 주고 있다.
Stable Diffusion은 2022년 8월 22일에 출시되었다. 그리고 일주일 뒤, 세상은 그 전과 완전히 달라졌다.
Stable Diffusion 출시 후, 일주일 동안 벌어진 일
8월 23일 (출시 2일 차)
- Image-to-Image 기능이 오픈소스로 추가됨 (이미지를 입력으로 넣으면 새로운 이미지를 생성해주는 기능)
- Stable Diffusion용 Discord Bot 출시
- 윈도우용 GUI 버전 출시
8월 24일 (출시 3일 차)
- Animation 생성 기능 개발됨
- Figma Plug-in 기능 개발됨 <- 이건 꼭 한번 봐보세요!
8월 25일 (출시 4일 차)
- Inpainting 기능 (특정 부분만 지우고 해당 부분만 AI로 채우는 기능) 개발됨
- WebUI 출시
......
오픈소스라는 장점이 만나 대폭발 하게 된다. 다양한 개발들이 일주일 만에 기능을 추가하고, 다른 툴에 Plug-in 형태로 기능들을 붙이기 시작했다. 다시 말하지만 단 일주일 만에.
그리고 이런 성공 덕분에 stability.ai는 1조원 가치로 투자 라운딩을 도는 중이라고 한다.
 Prompt: "Caspar David Friedrich, a cat above the Sea of Fog"
Prompt: "Caspar David Friedrich, a cat above the Sea of Fog"
Stable Diffusion 직접 써보기
회사 동료분이 Stable Diffusion을 쓸 수 있는 Discord Bot을 만들어서, 무료로 제공 중에 있다. 이 링크를 통해 Discord에 들어오면, 바로 써보실 수 있다. 아직 다른 곳처럼 Credit이나 생성 숫자에 대한 제한도 없다. (유명해지면 생길지도)
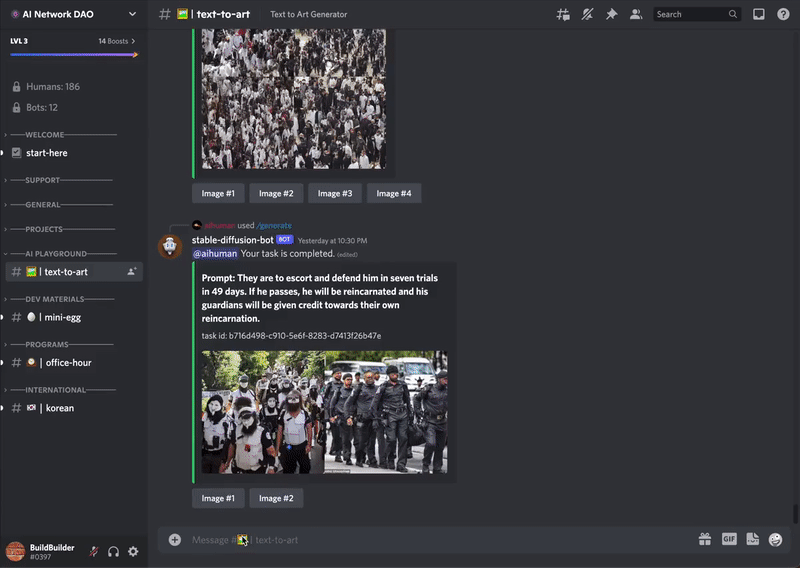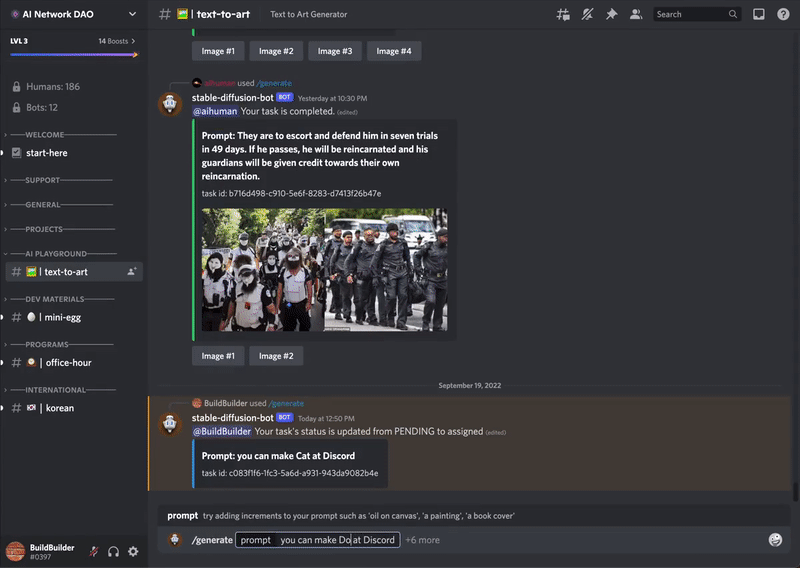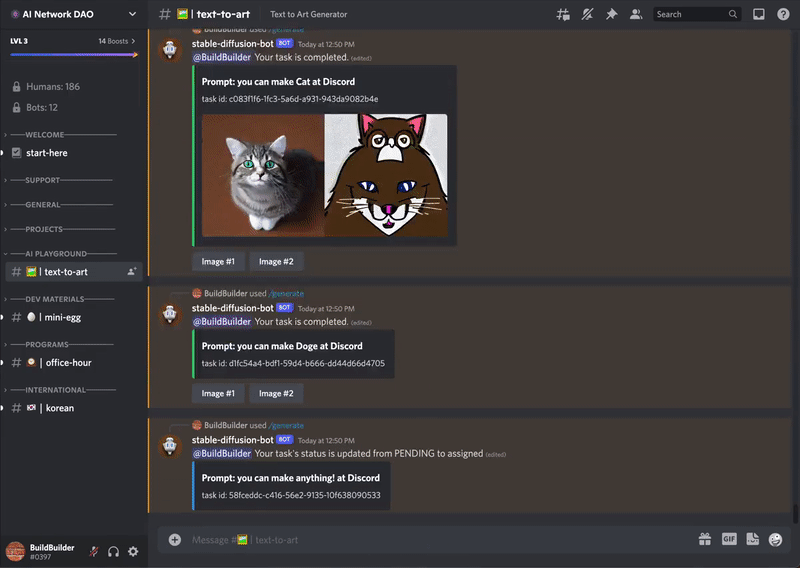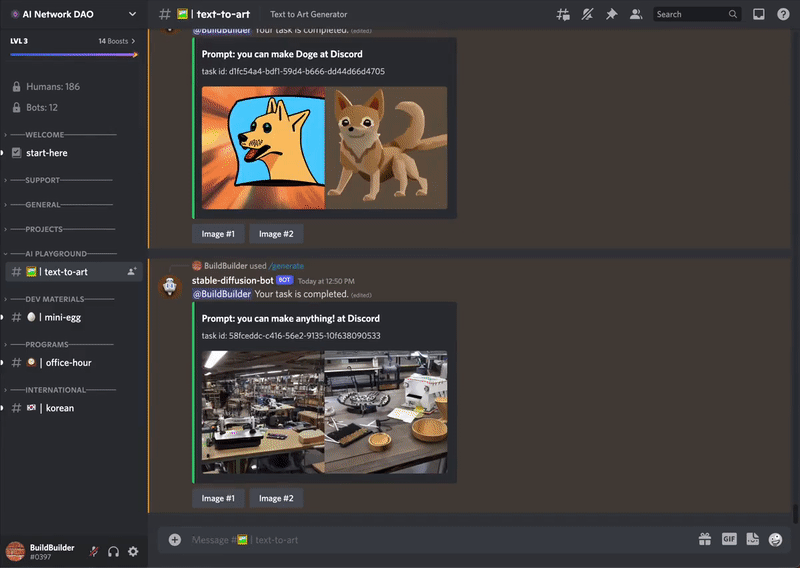 들어오셔서
들어오셔서 /generate prompt:"cute cat" 이렇게만 넣으면 끝이다.
 Prompt: "a panting of the castle in the pyrenees by René Magritte"
Prompt: "a panting of the castle in the pyrenees by René Magritte"
잠깐! 다음으로 넘어가기 전에
다음 내용을 읽으시기 전에, 위에서 소개드린 Stable Diffsuion Bot도 좋고, MidJourney도 좋고, DALL-E 2도 좋으니, text-to-image AI를 써보시고 와서 아래 글을 읽기를 추천드린다. 영화를 봐야 영화에 대해 논할 수 있는 것처럼, 한번 써보고 오시면 제가 뒤에 하는 이야기가 더 많이 공감되실 것이다.
AI가 예술이라면, 우리의 할 일은 무엇일까?
파도가 바다의 일이라면 너를 생각하는 것은 나의 일이었다 - 김연수
그림 그리기가, 사진 만들기가, 2D 그래픽을 만들기가, AI의 일이 되고 있다. 그리고 불과 1년 사이에 일어난 일들을 보면, 내년, 내후년, 그리고 10년 뒤를 생각해보면 어떻게 될지 쉽게 상상을 할 수 있을 것이다.
 이 고양이는 진짜일까? 가짜일까?
이 고양이는 진짜일까? 가짜일까?
써보신 분은 알겠지만, 원하는 이미지를 생성해 내는 Prompt를 만들기란 생각보다 쉽지 않다. 그래서 지금 우리가 해야 할 일은 AI가 원하는 결과물이 나오는 Prompt를 찾는 일이 되었다.
인터넷과 검색엔진이 있기 전/후를 비교해 보면 어떤 느낌인지 이해하기 좀 더 쉬울 것이다. 어떤 정보를 찾으려면 무조건 도서관에 가서 관련된 책을 뒤져봐야만 했다. 그러다 인터넷과 검색엔진이 나온 후, 정보를 찾는 건 그 정보를 보여주는 키워드를 찾는 일이 되었다. 이제 AI를 쓰는 일도 비슷해졌다. 원하는 결과를 만들어주는 Prompt를 찾아야, AI에게 원하는 일을 시킬 수 있는 세상이 되었다.
 Prompt: "a painting of an library, only a lone man reading. by edward hopper"
Prompt: "a painting of an library, only a lone man reading. by edward hopper"
promptbase
이러한 흐름에 따라, 원하는 결과가 나오는 Prompt를 파는 사이트가 등장하였다. RPG Game에서 아이템으로 쓸만한 이미지를 만드는 Prompt, 포켓몬처럼 생기면서 Pixel Art 같은 스타일의 이미지를 만들어주는 Prompt 등 유명 맛집의 레시피를 파는 것처럼, 해당 이미지를 만들 수 있는 Prompt 2~3달러에 팔고 있다.
원하는 이미지를 저기서 찾을 수 있다면, 돈을 내고 사는 것도 좋을 것이다. 실제로 원하는 결과를 만들어주는 Prompt를 찾는데 짧으면 몇십 분, 길면 며칠도 걸리는 일이니, 2~3달러라면 비싸지 않다고 볼 수 있을 것이다.

lexica
또 하나는 Stable Diffusion을 위한 검색엔진인 lexica이다. 사용자들 stable diffusion에 입력으로 넣은 prompt와 output 이미지를 검색해 볼 수 있다. 그리고 해당 이미지를 클릭하면, 그 이미지를 만들 때 쓰인 prompt, width, height, seed 정보들을 확인해 볼 수 있다. 해당 정보를 통해, 그것과 비슷한 이미지를 만들려면 어떻게 keyword들이 들어가야 하는지를 확인해 볼 수 있다.
지금은 사이트가 업데이트되면서 표시를 안 해서 안 보이지만, 3주 전에 표시된 걸로는 1,000만 개의 사진이 등록되어 있다고 한다. 아마도 지금은 그것보다 더 많을 것이다.
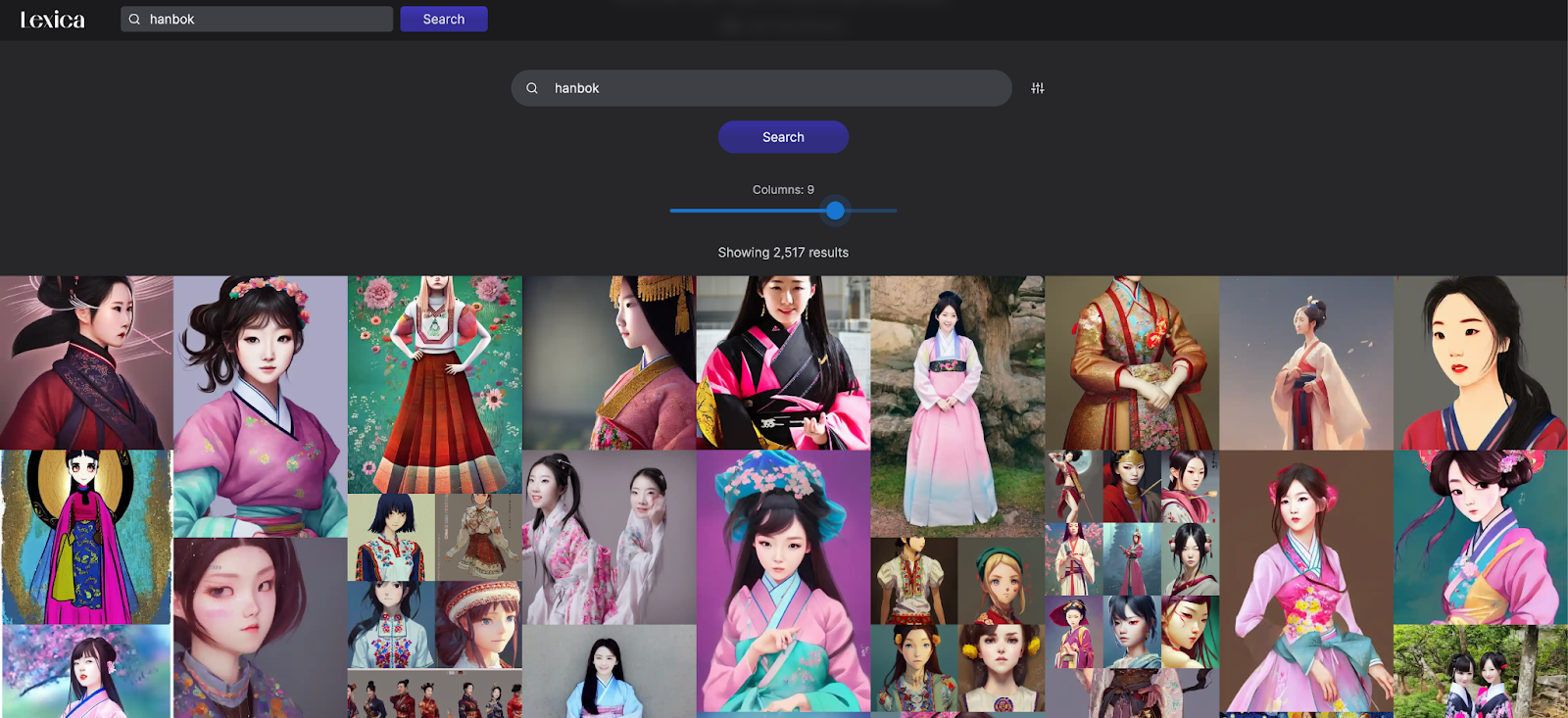 참고로 이 글에서 올린 사진들 중 "Prompt: ~~~"라는 설명을 달아놓은 것들 대부분은 이 사이트에서 적절한 prompt를 찾고 그걸 수정해서 만들었다.
참고로 이 글에서 올린 사진들 중 "Prompt: ~~~"라는 설명을 달아놓은 것들 대부분은 이 사이트에서 적절한 prompt를 찾고 그걸 수정해서 만들었다.
21세기 AI를 위한 2가지 제언
유발 하라리처럼 <21세기를 위한 21가지 제언>을 할 수 있으려면 좋으려 만, 그 정도까지는 몰라서 못하겠고 근 1년을 되돌아보면서 2가지 정도는 말할 수 있을 것 같다.
첫 번째, AI 프로젝트들이 Open Source로 풀리는 것만으로는 부족하다. 많은 AI 프로젝트들이 논문과 함께 Github에 Code를 같이 공개하지만, 그걸로는 충분하지 않을 걸 다시금 확인했다. 사진기의 발명과 사진 예술의 탄생 사이에는 대략 100년 정도의 갭이 있다. 기술의 발명과 개발은 어떤 변화의 시작점일 뿐이다. 실제로 그 변화가 더 많은 사람에게 가기 위해선 기술을 넘어 다른 것이 필요하다. 그리고 "그 다른 것"은 대부분 혼자 가는 방법이 아닌, 함께 멀리 가는 방법에 대한 것이었다. 혼자 빨리 가면 나만 빨라지지만, 함께 멀리 가면 세상이 이전과 달라진다.
두 번째, 이 글에서 소개한 text-to-image AI도 그렇고, GPT-3와 같은 초거대 언어 모델도 그렇고, AI를 쓰는 일이 Prompt를 잘 찾고 만드는 일이 되고 있다. 그렇다면 사람이 만든 컨텐츠가 아닌 AI가 만들어낸 컨텐츠를 찾을 수 있고(1), 재현하는 방법을 찾을 수 있고(2), 이어서 바로 써볼 수 있는(3) 플랫폼이 중요해질 것이다. 그제야 AI가 오로시 도구처럼 느껴질 것이다.
 Prompt: "The role of an artist is to think about the future"
Prompt: "The role of an artist is to think about the future"
예술가의 역할은 미래를 사유하는 것이다 - 백남준
결국, 미래에는 개발자와 예술가가 함께 만나 새로운 미래를 만들어가는 미래가 되지 않을까? 그리고 그 미래가 우리의 생각보다 훨씬 더 가까이 있다.
2023년 6월 업데이트
Stability AI 관련해서 아래와 같은 논란이 있습니다.
https://news.hada.io/topic?id=9347

6개의 댓글


clip은 "이미지를 넣으면, 그 이미지에 대한 설명을 해주는 모델"이 아니고 "이미지와 해당 이미지에 대한 설명 텍스트를 같은 공간에 위치하도록 학습하는 representation learning 모델"입니다. 이미지에 대한 설명을 해주는 일은 CLIP을 활용하는 수많은 방법 중 하나일 뿐입니다.
Diffusion model은 "노이즈가 있는 이미지에서 실제 이미지를 만들어 주는 모델"이 아니고 "원본 이미지에 연속적인 노이즈를 넣고 원본 이미지로 복원하는 법을 배우는 모델"입니다.
많은 분들이 보는 글 같은데 가장 중요한 clip과 diffusion model에 대해 간단하게 요약한 정도가 아니라 약간 틀리게 설명하신 것 같아서 조심스레 글 남겨 봅니다.

감사합니다- 프롬프트를 사고 파는 사이트가 있는 줄은 처음 알았네요.
중간에 promptbase 링크 터졌어요