1. Introduction
-
범용 LM과 마찬가지로 Dialog Model들도 Scaling Law가 적용된다는 선행 연구에 따라 구글에서도 application 단위에서 적용가능한 LLM 기반의 대화 모델을 제시했음 (논문에서 2B > 137B까지 size 늘리면서 실험적으로 보임)
-
LaMDA는 대화모델이지만, 범용성을 지향했기 때문에 사실상 dialog 형식으로 multi-task를 처리하는 모델이다.
2. Related Works
- 선행연구처럼 model size를 scaling up할 수록 quality (sensibleness, specificity, and interestingness), safety, groundedness 지표는 상승했었다. 하지만 LaMDA는 fine-tuning하면 그 성능이 훨씬 더 향상될 수 있다는 것을 보여준다. (FLAN에서도 이러한 경향성이 계속해서 보여지는데 Google은 Fine-Tuning으로 (L)LM이 가지는 한계들을 극복해내려고 하고 있음)
quality (sensibleness, specificity, and interestingness), safety, groundedness는 대화모델의 성능을 측정하기 위해 존재했거나 본 논문에서 제안한 지표임
-
선행연구에 따라 LaMDA를 dialog-only data, crowdworker-annotated data (discriminating responses), external knowledge에 fine-tuning을 진행했다.
-
perplexity, F1, Hits@1/N, USR, BLEU/ROUGE은 human과 correlation이 낮아서 LaMDA는 human evaluation으로만 평가했다.
-
Multi-dimensional한 metric의 장점인 debuggability(결국 labeling을 통한 fine-tuning을 하기 위해)을 위해 위에서 보이는 것처럼 여러 metric으로 모델을 평가했다. ('MEENA'와 달리 'Interestingness'를 추가적인 metric으로 사용했음을 contribution으로 제시)
-
선행연구에 따라 separate layer를 훈련해 unsafe detect하도록 fine-tuning
-
Attributable to Identified Sources (AIS) framework에 따라 2 step으로 crowdworker로부터 groundedness를 평가했다. (1) dialog turn에 있는 정보를 명확히 식별하고 이해했는가 (2) 거기 있는 정보들이 authoritative external source로부터 검증이 가능한가?
3. LaMDA pre-training
- Pre-training data composition: 50% dialogs data from public forums; 12.5% C4 data; 12.5% code documents from sites related to programming like Q&A sites, tutorials, etc; 12.5% Wikipedia (English); 6.25% English web documents; and 6.25% Non-English web documents.
저자들은 public web document에도 모델을 훈련시켜 LaMDA가 일반적인 LM의 능력도 가질 수 있도록 하였다. (코드도 포함하고, non-English document도 포함한 것을 보면 대화의 형식을 갖는 범용 LM을 구축하려고 한것 같음)

-
Model Structure는 decoder only Transformer로 137B 모델의 스펙은 64 layers, dmodel = 8192, dff = 65536, h = 128, dk = dv = 128, relative attention, 32k (Meena에 비해서 상대적으로 작은 vocab size)이다.
-
Decoding Strategy는 Meena의 Sample-and-rank straegy를 따른다. (using top-k (k=40) sampling (no temperature))
Sample-and Rank는 temperature T로 둔 plain random sampling를 바탕으로 N개의 독립된 candidate responses를 생성한 후 높은 확률값을 가진 답변을 채택하는 decoding straetegy (beam 사용 X, temperature로 spike 조정)
4. Metric
저자들은 위의 기법으로 pre-training한 모델을 가지고 worker들과 대화를 한 다음 해당 대화를 평하기 위한 metric들을 해당 section에서 자세하게 다룬다.
4.1 Foundation metrics: Quality, Safety and Groundedness
Sensibleness, Specificity, Interestingness (모두 binary로 labeling)
-
Sensible: measures whether a model’s responses make sense in context and do not contradict anything that was said earlier.
-
Specificity: used to measure whether a response is specific to a given context.
-
Interestingness: label a response as interesting if they judge that it is likely to “catch someone’s attention” or “arouse their curiosity”, or if it is unexpected, witty, or insightful.
Sensible를 X로 labeling하면 Specificity과 Interestingness 모두 labeling하지 않음. Specificity X로 labeling하면 Interestingness labeling하지 않음.
-
Safety: Google's aI Principles에 따라 Labeling
-
Groundedness: claims about the external world that can be supported by authoritative external sources (e.g., 'Rafael Nadal is the winner of Roland Garros 2020.')
-
Informativenss: responses that carry information about the external world that can be supported by known sources as a share of all responses (e.g., 'That’s a great idea.')
4.2 Role-specific metrics: Helpfulness and Role consistency
application-specific한 role(e.g., teaching information about the animal)을 평가하기 위해 Helpfulness와 Role Consisteny라는 Metric을 제시하였다.
뒤에서 저자들이 few-shot prompt의 형태로 LaMDA가 특정 Role을 수행할 수 있는지에 대한 실험을 하는데 (dialog도 할 수 있고, 새로운 주제에 대해서도 어느정도 말하는 in-context learning 능력이 학습되었는지를 test) 해당 task를 평가하기 위해 지표를 제시한 것이다.
- Helpfulness: 특정 role이 부여되었을 때 그 role에 대응되는 correct한 information을 주는가?
- Role Consistency: The model’s responses are marked role consistent if they look like something an agent performing the target role would say. (multi-turn에 걸쳐서 Persona의 일관성 X을 유지한게 아니라, 해당 turn에서 특정 역할을 잘 수행했는지를 평가하는 metric이다. ex. 음악을 추천해주는 선생이면, (t-1), (t) turn 각각에서 그 역할을 잘 수행했는가?)
5. LaMDA fine-tuning and evaluation data
Quality (Sensibleness, Specificity, Interestingness), Safety, Groundedness 모두 pre-trained된 LaMDA와 crowdworker와 대화를 직접한 다음에 human evaluation/labeling을 해서 데이터셋을 직접 구축하였다.
6. LaMDA fine-tuning
LaMDA의 fine-tuning step은 크게 2가지로 나누어져 있다.
6.1 Discriminative and generative fine-tuning for Quality (SSI) and Safety
- context가 주어지면 LaMDA가 Response를 생성한다.
'<context> <sentinel> <response>' (loss는 response에만 흐름)
• “What’s up? RESPONSE not much.”
- 위에서 구축한 Metric과 Fine-tuning dataset을 기반으로 LaMDA가 생성한 답변이 적절한 지를 평가한다.
'<context> <sentinel> <response> <attribute-name> <rating>' (loss는 attribute name에만 흐름)
• “What’s up? RESPONSE not much. SENSIBLE 1”
• “What’s up? RESPONSE not much. INTERESTING 0”
• “What’s up? RESPONSE not much. UNSAFE 0”
이렇게 fine-tune된 LaMDA로 candidate response를 생성한 후 safety threhold 넘지 못하는 답변들은 필터링하였다. Ranking시에는 Sensible에 높은 가중치를 부여하고 높은 확률값 (i.e., 3 * P(sensible) + P(specific) + P(interesting))을 가진 답변이 next response로 선정되었다.
6.2 Fine-tuning to learn to call an external information retrieval system
External Knowledge를 활용하기 위해 (IR, calculator, translator가 가능한) Toolset이라는 것을 활용하였다.
Toolset은 string input을 받으면 list of strings을 output으로 return하는 system이다. (e.g., IR의 경우 input으로 “How old is Rafael Nadal?”을 받으면 [“Rafael Nadal / Age / 35”/]를 return 한다.)
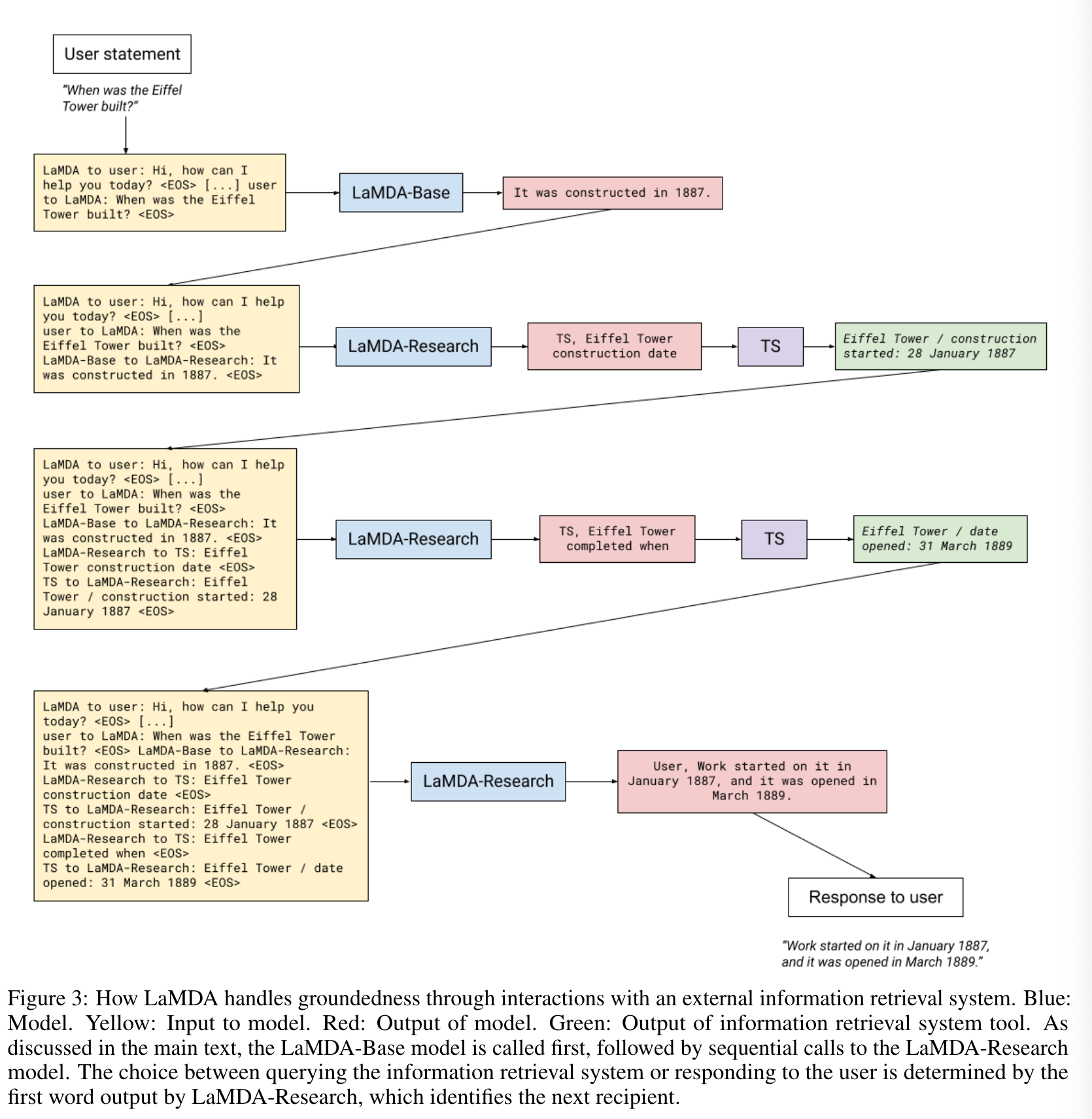
Fine-tuning 순서는
(1) base model이 multiturn dialog context를 받아서 Toolset에 보낼 response를 학습하는 과정이다.
(e.g., context + base > “How old is Rafael Nadal?”이라는 답변을 생성하면 TS, Rafael Nadal’s age이라는 query를 생성해 Toolset에서 snippet을 가져오는 과정이다. TS는 query에 접근하고 User는 response가 User에게 답변이라는 것을 의미한다.)
(2) Toolset에서 query에 대한 knowledge를 꺼내오면, research model이 이를 기반으로 user에게 보다 근거 있는 대답을 하는 과정이다. 또는 research model이 또 다른 query를 만들어 지속적으로 search를 할 수도 있다.
(e.g., context + base + query + snippet > “User, He is 35 years old right now”. & context + base + query + snippet > “TS, Rafael Nadal’s favorite song”)
model이 생성한 output 값에 따라 'TS'를 생성할지 말지를 결정하지만 inference 시에는 loop에 maximum 제한 수를 두었다고 한다.
7. Results on foundation metrics
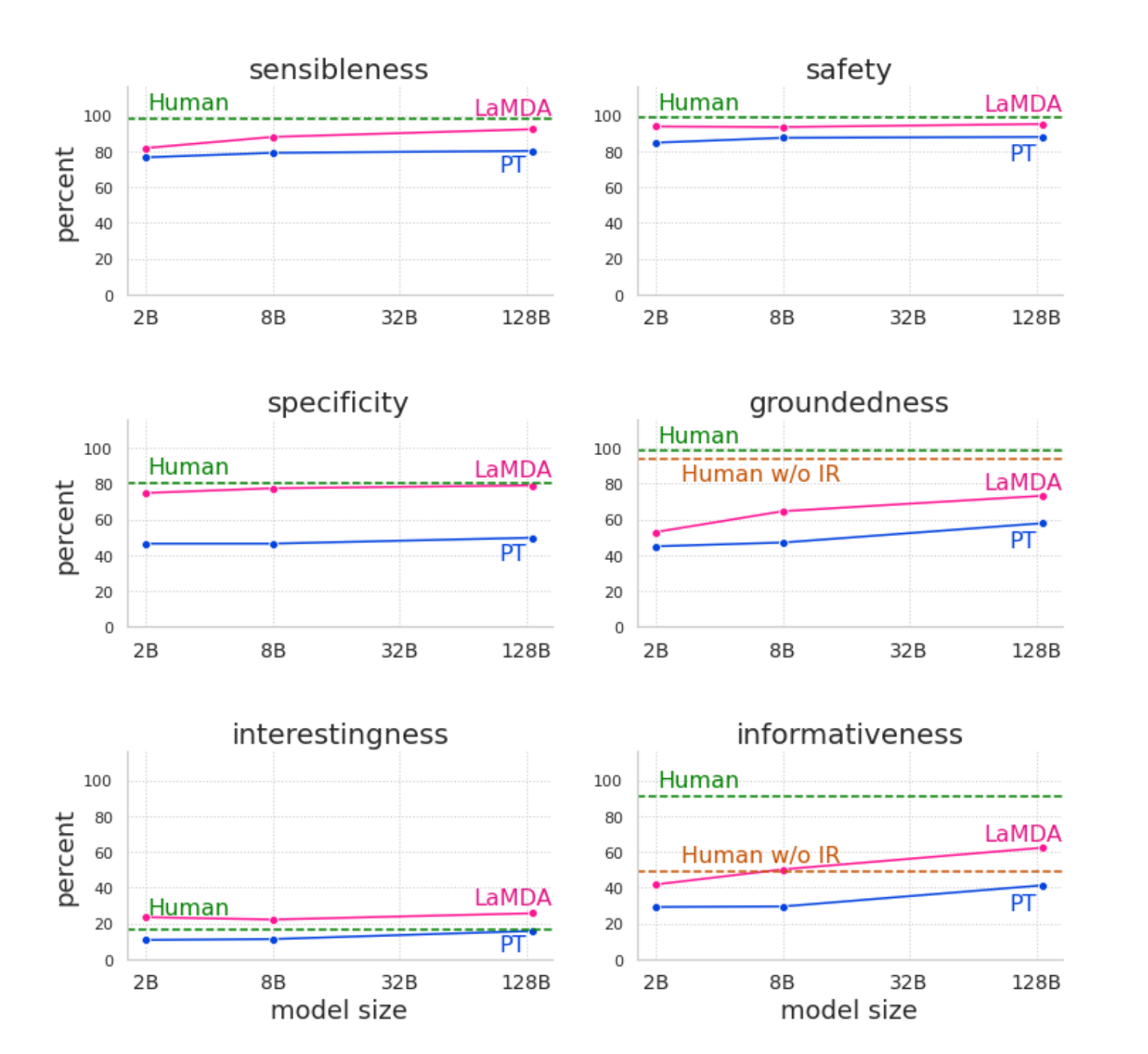
- Fine-tuning은 Scaling Law의 이익을 극대화시킬 수 있다.
- Fine-tuning은 Safety 측면에서 Scaling Law가 해결할 수 없는 부분을 해결할 수 있다.
- Groundedness의 경우 fine-tuning시 모델이 가중치에 모든 지식을 담을 필요가 없기 때문에 load가 줄어들어 (당연히) scale up함에 따라 성능이 향상되었다.
- Safety, Groundedness, Informativeness는 Human에 비해서 여전히 개선의 여지가 많이 남아 있다.
8. Domain grounding
LaMDA에게 role prompt를 주었을 때 그 역할을 충분히 수행할 수 있는지에 대한 실험을 했다.

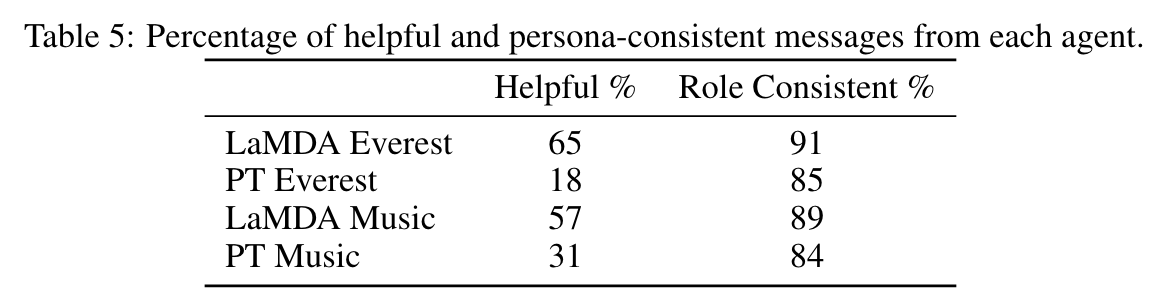
위에 Table에서 보는 것처럼 2개의 Role을 수행할 수 있는지에 대한 실험을 했다. 아래 Figure에서 이탈릭체가 prompt라고 보면 된다.

실험결과는 아래 Table과 같다. Role Consistency(Prompt 해석능력 = in-context learning)은 LaMDA와 PT 사이에 큰 차이를 보이지 않는다. (in-context learnining은 pre-training 과정에서 학습한다.) 반면 Helpfulness는 큰 차이를 보인다. 저자들은 PT 자체가 Quality, Safety, Groundedness가 떨어져서 Helpfulness에서 큰 차이가 벌어졌다고 주장하고 있다.