A Survey for In-context Learning
1. Introduction
적은 sample안에 있는 context를 파악해 문제를 해결하는 in-context learning은 LLM이 보이는 강력한 능력 중 하나이다.

Incontext learning은 기존에 X,Y pair로 된 dataset을 finetuning하는 방식과는 다른 방식으로 inference를 진행한다. 우선, X,Y를 ‘template’을 통해 자연어의 형태로 모델에 입력될 수 있도록 변경해 준다. 다음, inference 하기 위한 X(i.e., new query) (figure에서의 good meal!)를 위한 몇가지 예시들을 모델 앞에 붙혀주는데 이를 demonstration들이라고 한다. LLM은 demonstration들을 활용해 new query에 대한 inference를 진행하며, 이러한 학습 방법은 gradient descent를 통해 model parameter를 update할 필요가 없다.
저자들은 ICL은 크게 3가지 장점을 갖는다고 주장하다.
- 자연어로 작성된 demonstration이 인간과 LLM이 소통할 수 있는interface 역할을 한다.
- 유추를 통해 새로운 정보를 해석/추론하는 인간의 능력을 모방한다. (딥러닝을 포함한 대부분의 성공적인 기술은 생물을 모방)
- Training-free learning framework이다. (이건 관점에 따라 다른 것 같다)
ICL이 갖는 장점은 분명하고 GPT3에서 좋은 성능을 보여주는 것은 분명했지만
- Pretraining 단계에서 adaption을 통해 개선의 여지가 더 많이 남아 있고 On the Relation between Sensitivity and Accuracy in In-context Learning Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
- Prompt Template, In-context example selection, example order에 민감가며 (분산이 큼)
- ICL이 동작하는 것이 직관적으로는 이해가 가능하나 아직까지 명확하게 근거를 밝혀내지는 못하고 있다. Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers Transformers learn in-context by gradient descent
2. Overview
ICL 능력은 크게 2가지에 의해 영향을 받는다.
- LLM이 ICL 능력 자체를 학습하는 training (pretraining)
- 특정 task에서 어떤 demonstrastion을 활용해 inference를 할 것인가?
3. Definition and Formulation
저자들은 GPT3의 저자들을 따라 ICL을 다음과 같이 정의한다.
'In-context learning is a paradigm that allows language models to learn tasks given only a few examples in the form of demonstration.’

수식으로 정의하면 위와 같은데, 저자들은 기존의 (fine-tuning과 같은 방법으로) inference하고자 하는 candidate likelihood 는 demonstation(=C)와 X, y{j}가 같이 (1)과 같은 scoring function으로 표현될 수 있다고 주장하며, 이때 scoring funciton f는 query 와 demonstration이 주어졌을때 current answer $y{j}$의 정답 가능성(how possible)을 측정하는 함수로 뒤에 더 자세하게 다룰 예정이라고 한다.
ICL과 다른 유사한 개념들 간의 차이점은 다음과 같다.
(1) Prompt Learning : Prompt learning은 desired output를 위해 어떻게 prompt를 설계할 것인가에 초점을 맞추고 있다. ICL의 demonstration 설계가 prompt tuning의 일부로 볼 수 있다.
(2) Few-shot learning : Few-shot은 제한된 sample들로 parameter update를 하지만 ICL은 그렇지 update하지 않는다.
4. Model Warmup
LLM의 ICL성능을 높히고 pretraining과 ICL inference 사이의 discrepancy를 줄이기 위해 미세한 continual training을 하는 것(parameter update & adding module)을 본 survey에서 ‘model warmup’이라고 정의한다. warmup은 ‘특정 task를 위해’ model parameter를 하는 것이 아니기 때문에 fine-tuning과는 구별된다.
##### 4.1. Supervised In-context Training
크게 2가지 방법이 있음
→ MetaICL (w/ demenstration)
pretraining 목적함수가 ICL에 최적화 된 것이 아니기 때문에 task에 맞는 demonstration example들을 구축해 ICL에 최적화된 continual training을 하는 것
→ Instruction tuning
‘task instructions’을 통해 continual training하는 것 (ex. LaMDA-PT and FLAN)
(각 task마다 demonstration을 설계해야하는 MetaICL과 달리 task explanation만 잘 설계해주면 됨)
##### 4.2. Self-supervised In-context Training
→ original raw text를 input-output pair를 가진 4가지 형태의 objectives로 변경해 continual learning을 진행 (Improving In-Context Few-Shot Learning via Self-Supervised Training)
##### Supervised In-context Training & Self-supervised In-context Training 둘다 데이터 양이 일정 수준 넘어가면 성능향상이 정체된다고 한다.
5. Prompt Designing
demonstration = prompt를 어떻게 설계하고, 구성 및 배열은 어떻게 할 것인가?
##### 5.1. Demonstration Organization
→ 어떻게 demonstration을 selection할 것인가에 대해서는 크게 unsupervised와 supervised가 있다. unsupervised에는 pre-defined metric(L2, Cosine) 기반해서 유사한 example을 가져오는 방법론이나 LLM을 직접 활용해 demonstration을 생성하는 방법이 있다 Kim et al. (2022a). Supervised 방법론으로는 처음에 BM25 같은 unsupervised retriever로 유사한 candidate들을 가져 온 후 scoring LM을 통해 candidate에 대해서 positive, negative labeling을 하게 한 후 supervised retriever을 학습하는 방식을 제안한 논문이 있다. (+ 강화학습을 사용했다는 논문도..)
→ demonstration order에 따라 model의 ICL performance가 민감하게 반응하는데, Liu et al. (2022)는 query에 유사한 example들이 query와 가까운 내림차순 방식을 활용한다. 그들은 ‘entropy metric’이 ICL performance와 양의 상관관계가 있음을 보이며 ‘entropy metric’을 best ordering을 선택하는데 사용함
##### 5.2. Demonstration Formatting
-
복잡한 추론능력을 요구하는 task일수록 (math, commonsense reasoning), chain-of-thought와 같은 x와 y사이의 intermediate 단계를 추가하는 것이 필요하다.
-
좋은 demonstration을 설계하는 것만큼 정확하게 task를 설명하는 Instruction을 설계하는 것은 Inference 성능을 향상시키는데 도움이 된다. 하지만 demonstration과 달리 instruction은 training data에서 얻을 수 없기 때문에, LLM을 활용한 방식 (p(instruction|demonstration) & automatic instruction generation and selection & bootstrap off its own generations)이 많이 연구되고 있다.
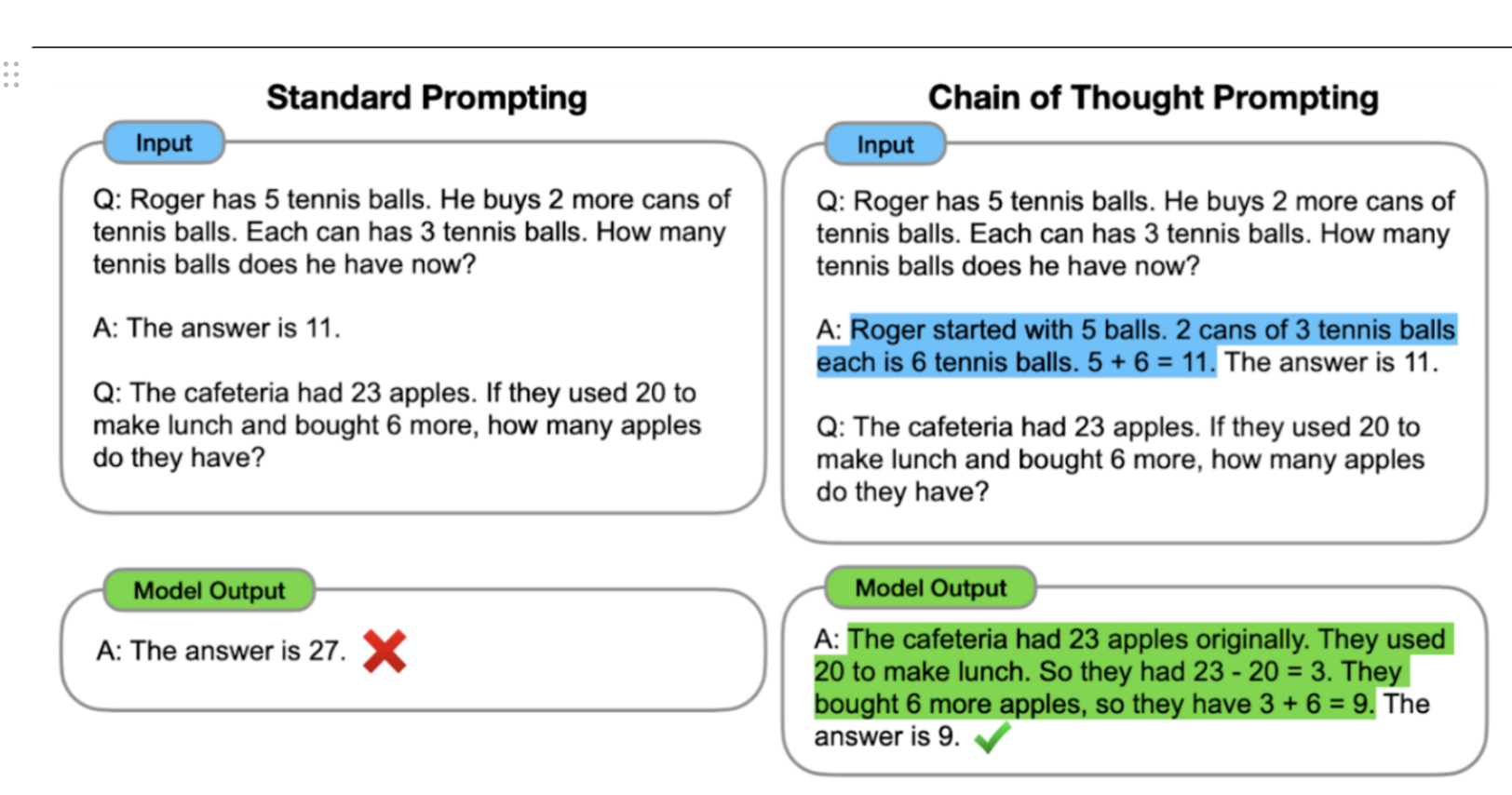
- arithmetic reasoning과 symbolic reasoning을 해결하기 위해 도입된 CoT에 따라 Input-Output Pair를 여러 stage로 나누어 추론하는게 가능해짐에 따라 각 reasoning step에 따라 다른 prompt를 주어서 ICL을 하는 연구들도 진행되고 있다고 한다.
6. Scoring Function
- LM prediction을 specific answer의 likelihood로 변환하는 작업
- Direct : highgest probability selected as the final answer
→ 제한적인 template design (answer가 항상 left) - PPL : ppl of whole input sequence
(C: demonstration, x: query, y: label) → extra computation - Channel : p(query|demonstration,label)
7. Analysis
- ICL 성능에 영향을 미치는 요인들에는 무엇이 있는가?
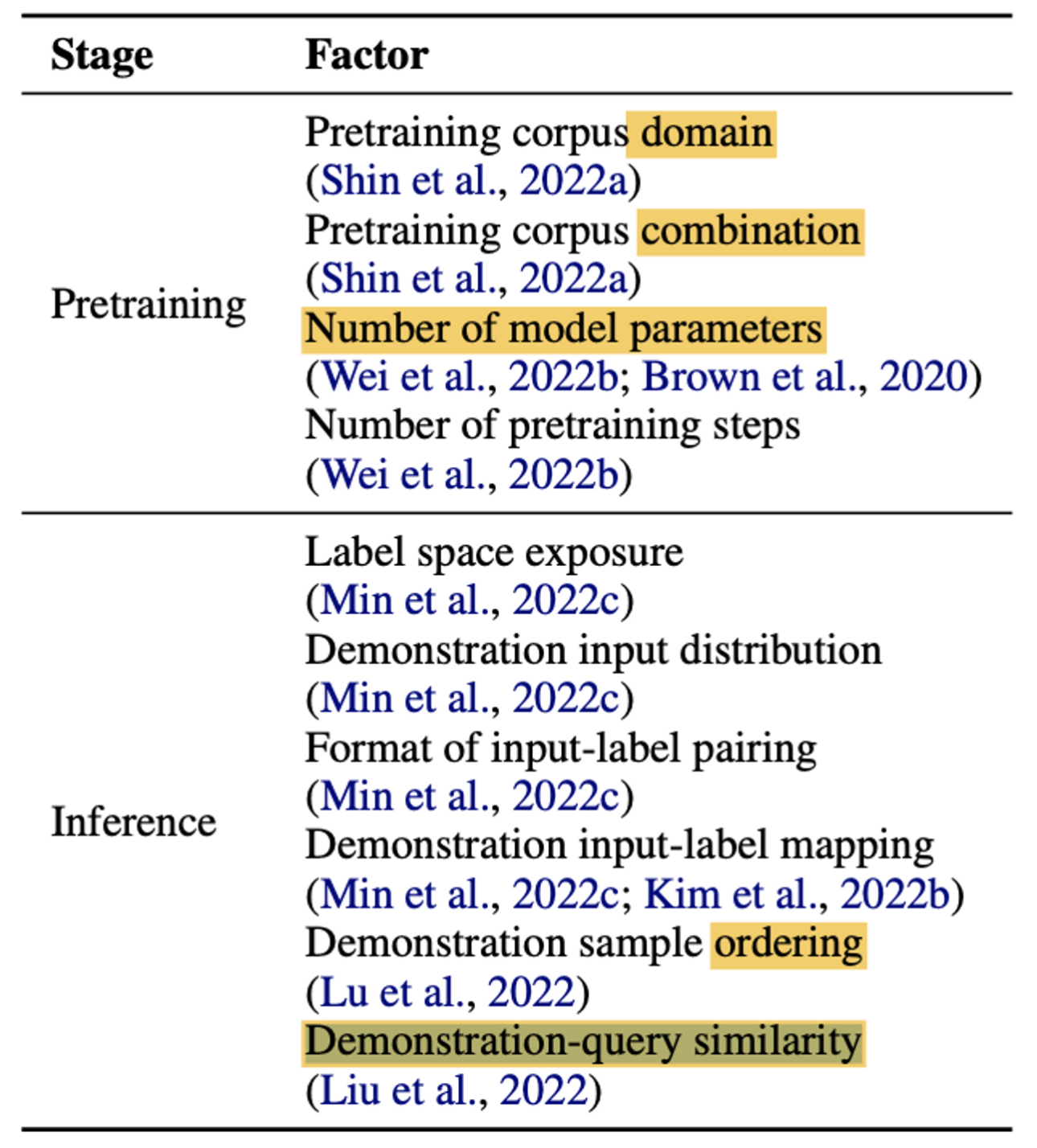
-
Pretraining
Corpus domain source가 size보다 성능에 중요한 영향을 미친다.
규모의 법칙 (pretraining step & model size) -
Inference
demonstration samples (input-label pairing format, label space, input distribution, input-label mapping)
demonstration sample order
demonstration-query similarity -
How ICL Works?
Distribution of Training Data, Learning Mechanism, Functional Modules (e.g., Transformer내 특정 head)를 분석해 왜 ICL이 동작하는지 연구하는 논문들이 그동안 발표되었다. 하지만 위의 연구들은 simple task와 small model에 국한되어있다는 한계가 있다고 한다. 또한, 저자들은 Meta Optimization 관점에서 ICL을 보는 것이 합리적이라고 이야기 하고 있음. (ICL의 key는 LM이 demonstration을 얼마나 잘 활용하는가에 있으니깐)**
8. Evaluation and Resources
-
Traditional Tasks
: 전통적인 fine-tuning setting에 ICL을 적용하려면 각 task마다 n개 (32 samples)를 sampling하는 few shot setting을 구축해야 한다. GPT-3의 경우 범용성은 좋으나 세부 task별로 대부분 fine-tuning SOTA를 이기지는 못함 -
New Challenging Tasks
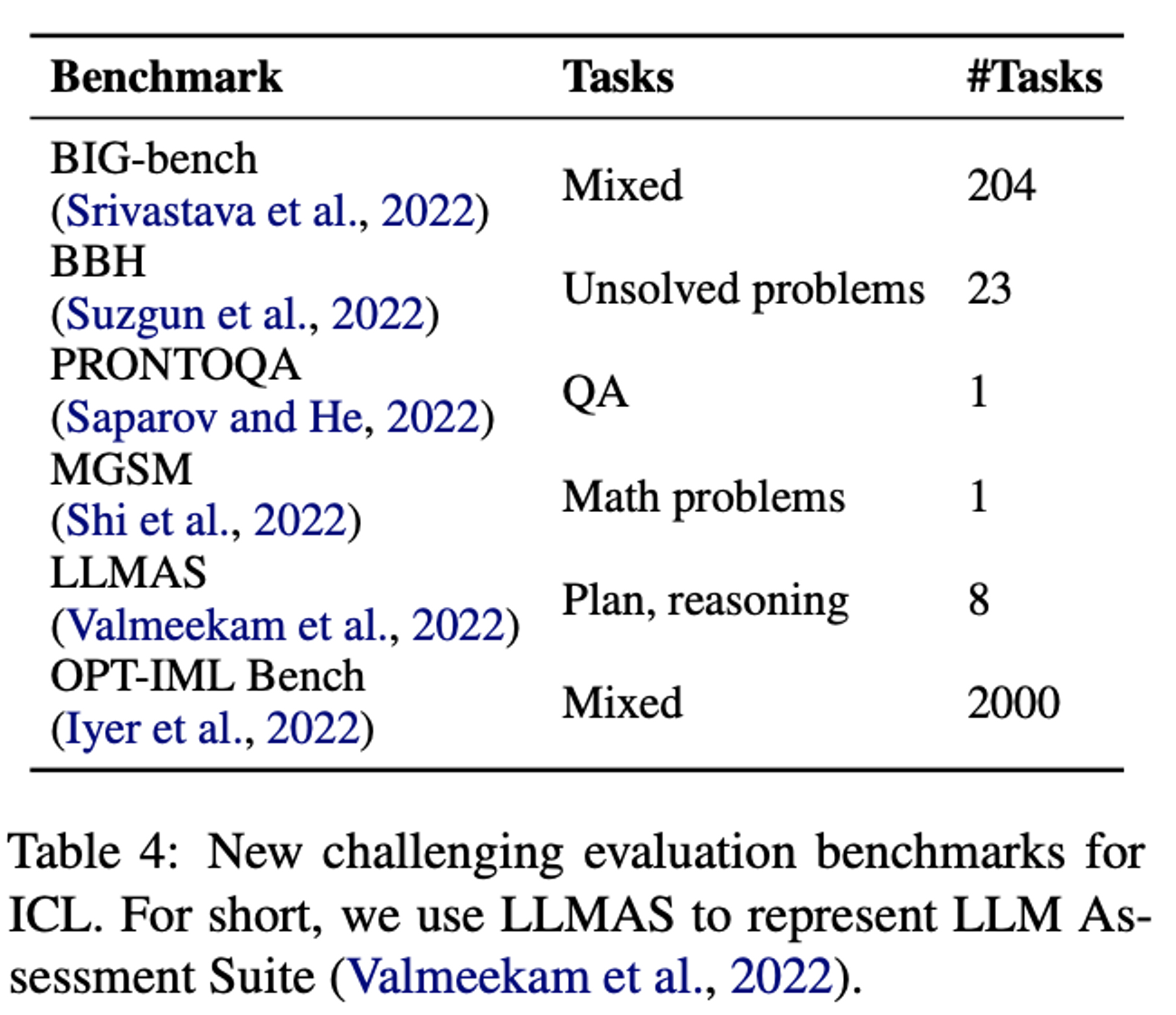
LLM의 다양한 역량을 측정하기 위해 BIG-Bench, Big-Bench의 어려운 버전인 Big-Bench Hard가 구축되었다. 또한 모델 사이즈가 커질 수록 성능이 떨어지는 task도 찾고 있는 중이라고 한다. 최근에는 ICL의 reasoning 능력을 특정하기 위한 데이터셋 (MGSM, LLMAS)도 구축되고 있다.
여전히 ICL 성능을 정확히 측정하기 위한 metric이 무엇인지에 대한 합의가 이루어지는 않은듯하다.
9. Application
demonstration이 명시적으로 추론에 대한 근거를 제시하기 때문에 ICL은 복잡한 추론과 복잡한 문제를 generalization하는 영역에서 좋은 성능을 보인다고 알려져 있다. 저자들이 제시하는 ICL의 application 방향은 크게 2가지이다.
- Model Editing
scale and a mixture of all types of demonstration examples strengthen the knowledge editing success rate of ICL. (demonstration을 활용해 LLM 안에 있는 knowledge를 수정할 수 있다)
- Data Annotation
GPT-3 사용해서 50%-96% 비용 절감이 있었다는 논문이 존재..
10. Challenges and Future Directions
-
New Pretraining Strategies (bridge the gap between pretraining objectives and ICL)
-
Distill the ICL Ability to Smaller Models

The Telltims Canada survey allows Tim Hortons to collect feedback from many customers, including those who are satisfied and those who are not happy with service. This feedback can be used to identify areas where Tim Hortons can make improvements.
The Tell Tims survey helps Tim Hortons restaurants improve customer satisfaction by identifying areas for improvement and making changes that benefit their customers.
Visit https://telltims-canada.com/ to complete the Telltims Canada survey by sharing our honest feedback and win $1 Hot Chocolate, French Vanilla, or Iced Coffee.