Reveiw] Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation - incomplete
cv_paper_reviews
목록 보기
19/22
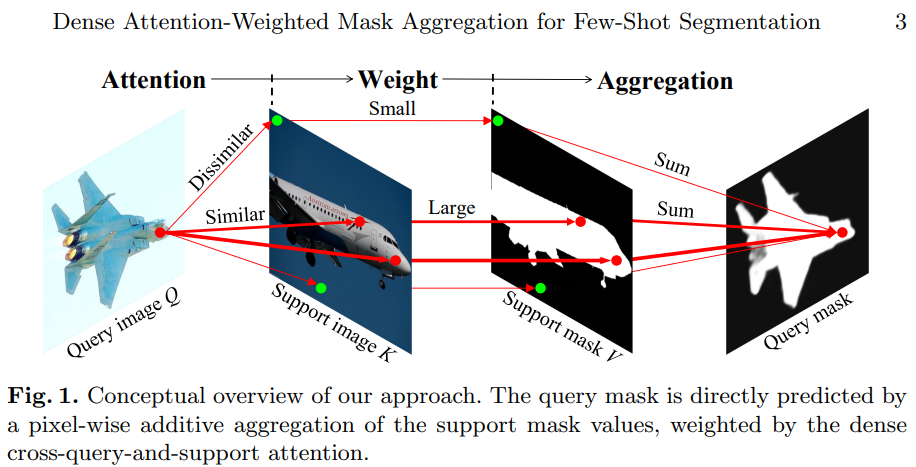
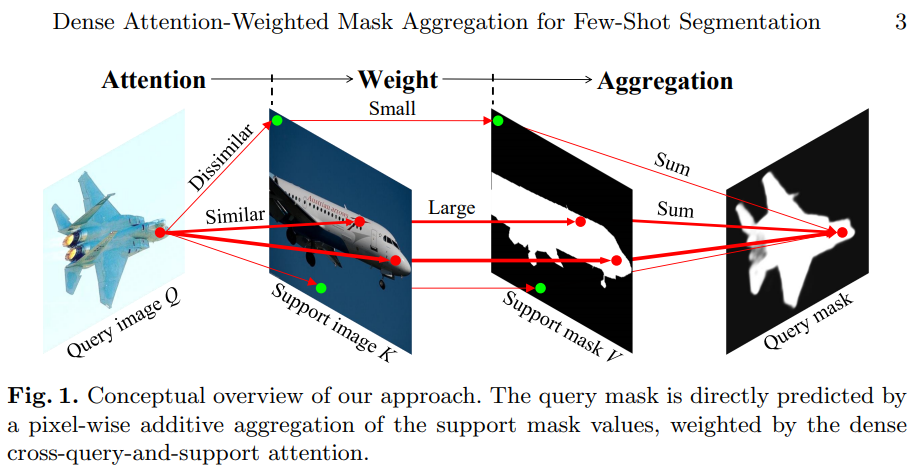
1. Motivation
- This paper proposed the model that expolits all available foreground and background features in the support images for dense pixel-wise classification.
2. Method
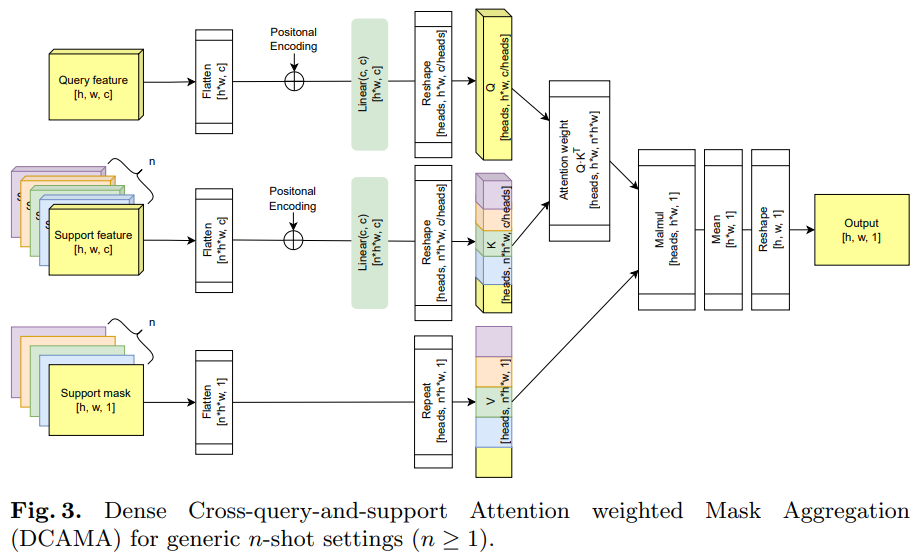
- Overall structure
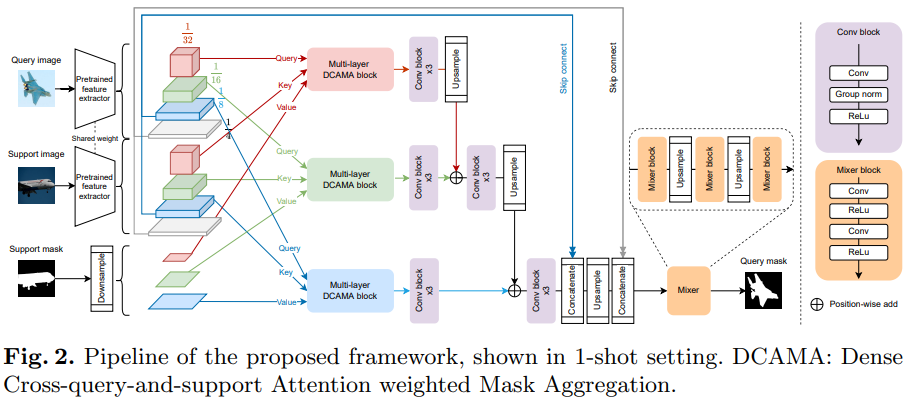
2.1. Feature extraction and mask preparation
- First feature vector of query image and support image is extracted from backbone model. The feature extractor outputs multi-scale, multi-layer feature map like Fig 2. Meanwhile, support masks of multi-layer are generated via bilinear interpolation.
2.2. Multi-scale multi-layer cross attention weighted mask aggregation
- Attention is the main concept of vision transformer and the paper use equation (1) to adopt to compute attention across the query and support features.
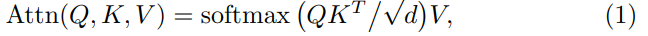
- The dimension of feauture map is h x w x c and mask is h x w x 1
- The proposed model flatten the feature vector and interpolated masks to treat each pixel as a token. Then, generate Q and K matrices. After that, dot-product attention can be computed for each head. Lastly the paper average the outputs of the multiple heads for each token and reshaped them.
3. Result
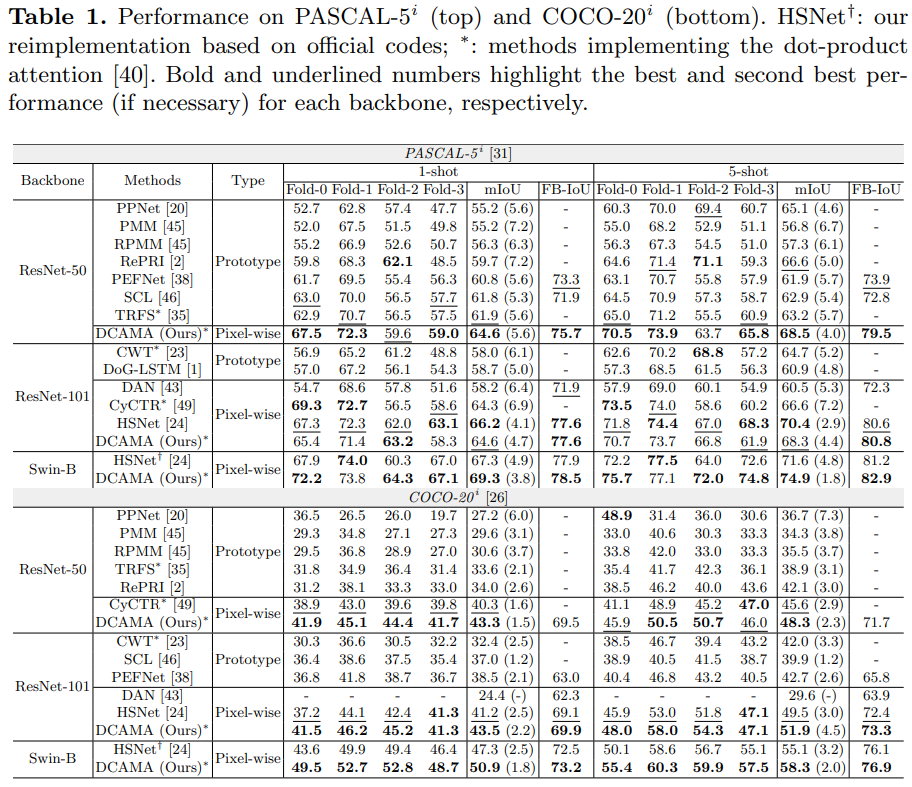
- Efficiency


호수공원