1. Motivation
- Architecture of CNN has out-standing performance in computer vision applications. However, capturing long term arange interactions for convolutions is challenging because of poor scaling properties.
- The problem of long range interaction has been tackled with using of attention and most of works using attention had used global attention layers as an add-on to existing CNN.
- Therefore, this paper proposed the local self-attention layer that can be used for both small and large inputs.
2. Method
2.1. Base model of CNN
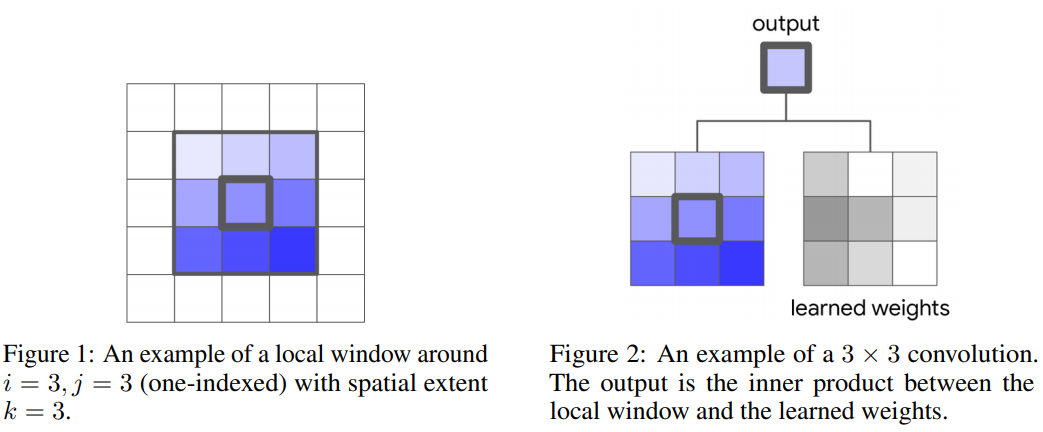
2.2. Self-Attention
- Self-attention is defined as attention applied to a single context which query, key and value are extracted from the same image.
- Single-head attnetion is computed as equation(2). With the equation, the model extracts local attention.(k is spatial extent) Global attention can be used after spatial downsampling has been applied because of computational cost issue.
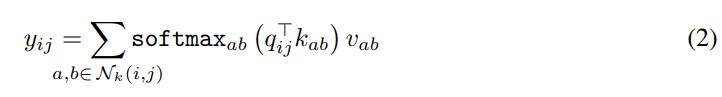
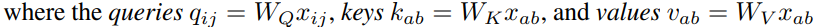
- In practice, multiple attention heads are used to learn multiple dinstinct representations of the input. Feature of input are divided into N groups in depthwise and the dimension of each weight is d_out/N * d_in/N. Finally the model output representation in d_out after concatenating.
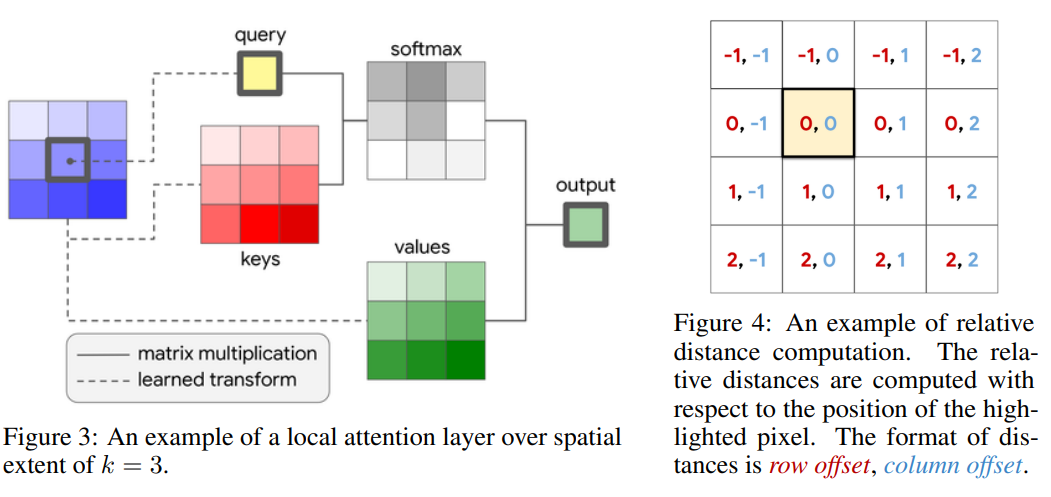
2.3. Fully Attentional Vision Models
- The main purpose of this work is creating a fully attentional vision model. Therefore, it takes an existing convolutional architecture and replaces every convolutional layer with attention layer.
- In this paper, it references resnet
- For the initial layers of CNN refered as stem, attnetion layer is applied without positional information.
3. Result
-
In imagenet classification
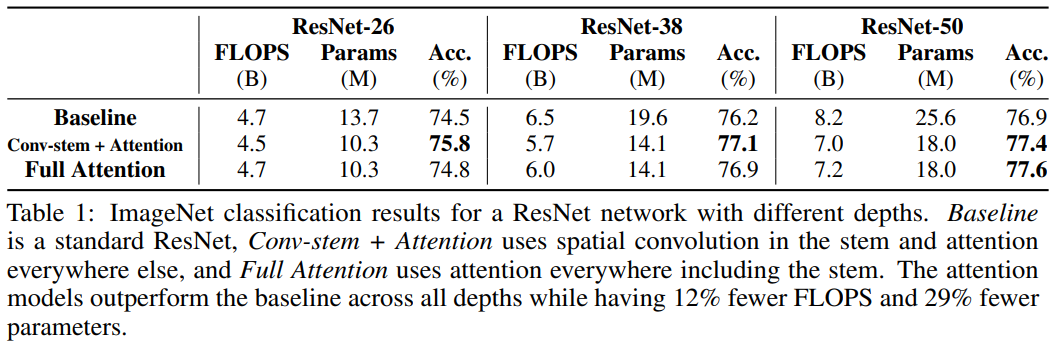
-
Coco dataset obeject detection
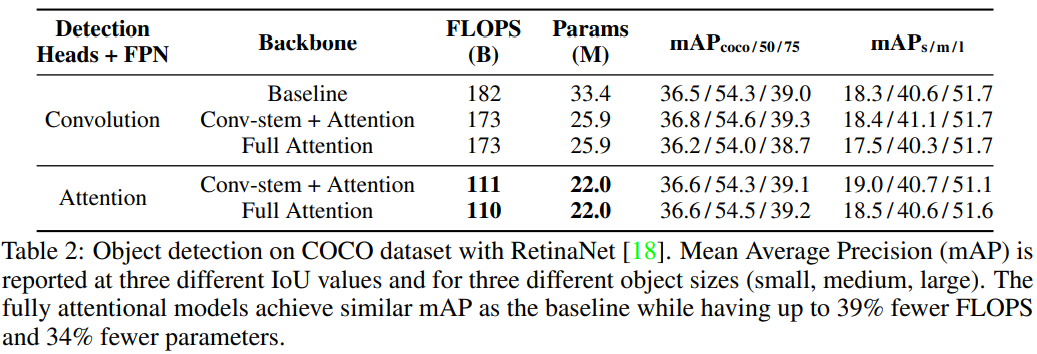
-
Affect of relative position information
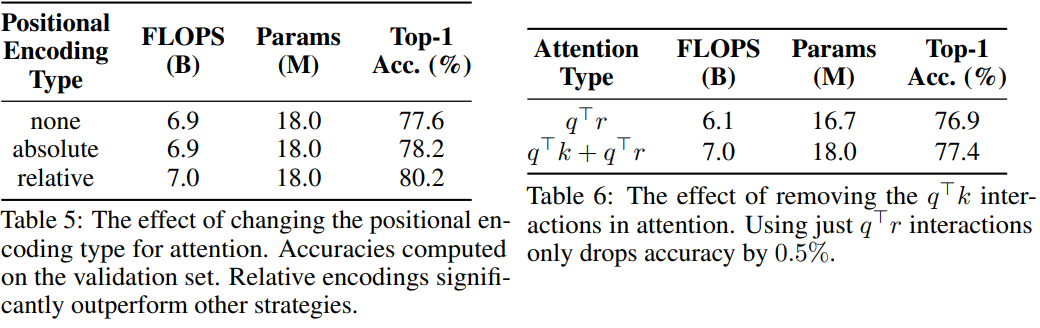
-
Spatial extent
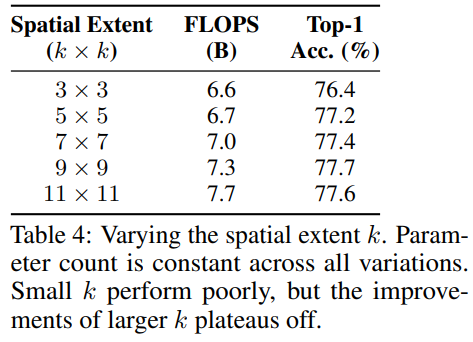

호수공원