Review] Self-supervised Vision Transformers for Land-cover Segmentation and Classification
cv_paper_reviews
목록 보기
22/22
1. Motivation
- In this paper, it proposed the method to combine vision transformer architecture and self-supervied learning
2. Method
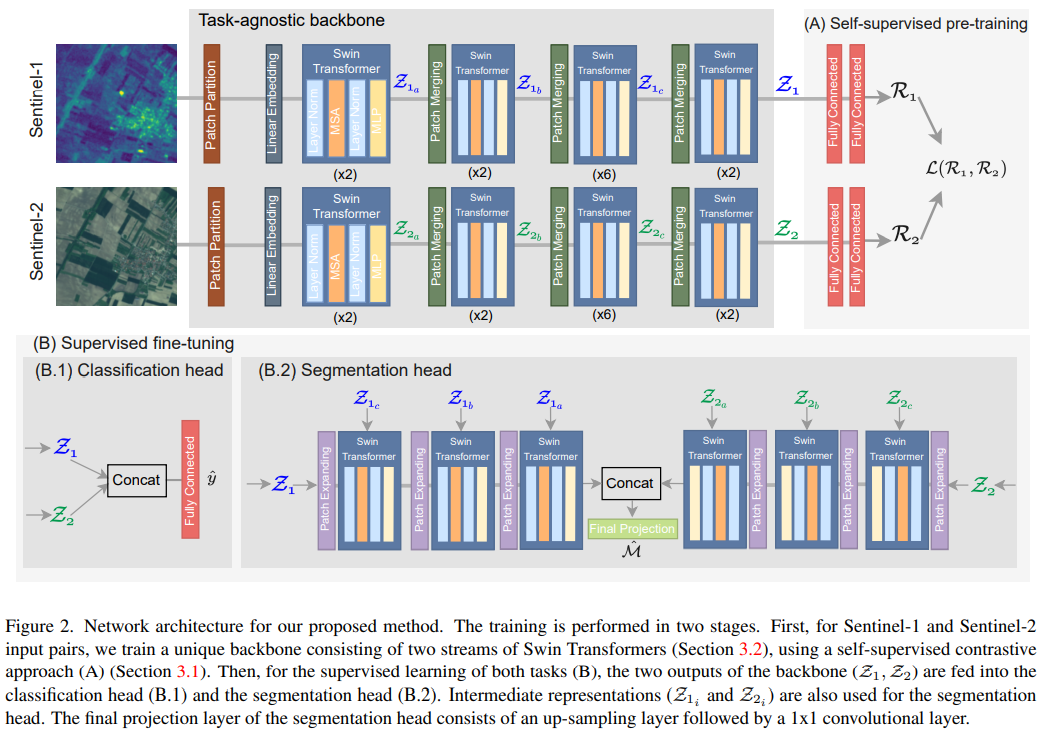
- Overall structure
2.1. Self-supervised learning
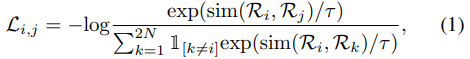
2.2. SwinUNet
- This work proposed two separate SwinUNet streams for contrastive learning process as Fig 2.
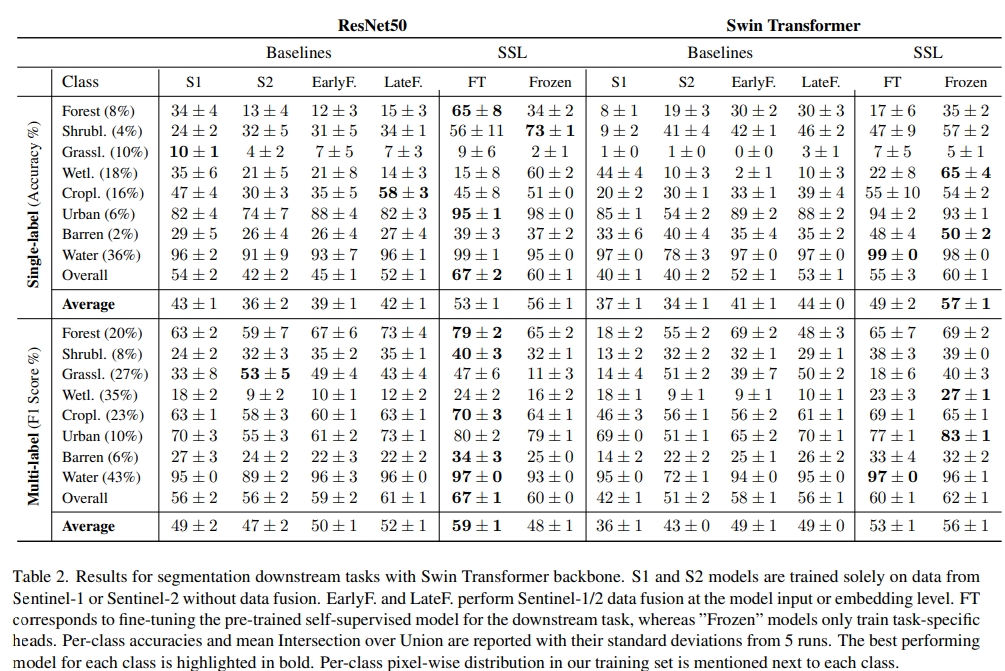
3. Result
Reference

호수공원