Review] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
cv_paper_reviews
목록 보기
21/22
1. Motivation
- The transformer structure shows that adaptation of attention module can outperform traditional CNN-based model.
- However the transformer has a problem that it is computational complexity is quadratic to image size. Therefore, in this paper, it proposed swin-transformer which is linear to image size.
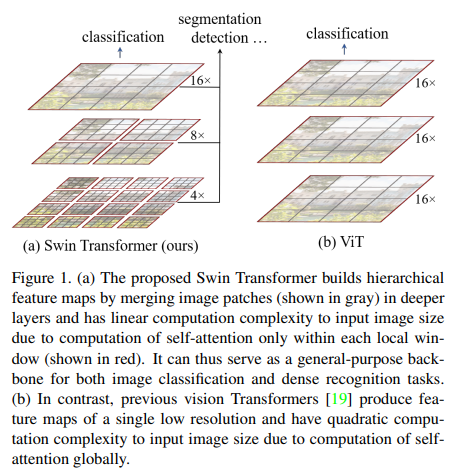
2. Method
2.1. Shifted Window based Self-Attention
-
Computational complexity of transformer is caused from global attention
-
Self-attention in non-overlapped windows
- For efficiency, the paper proposed the method to calculate local attention in non-overlapped windows with MxM patches. It can decrease the computational overhead as shown in equation (2)
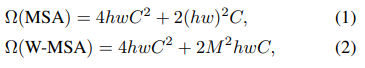
- For efficiency, the paper proposed the method to calculate local attention in non-overlapped windows with MxM patches. It can decrease the computational overhead as shown in equation (2)
-
Shifted window partitioning in successive blocks
- Just seperating the image to MxM patch might decrease connections across windows. To deal with the issue, shifted window partitioning approach is proposed.
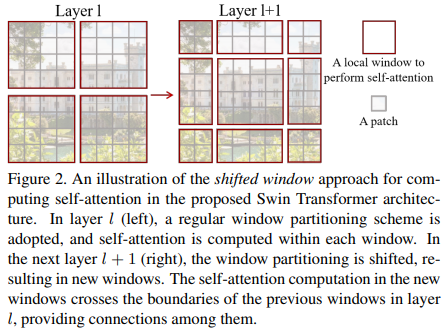
- Just seperating the image to MxM patch might decrease connections across windows. To deal with the issue, shifted window partitioning approach is proposed.
-
Efficient batch computation for shifted configuration
- The cyclic shift makes computional cost same as regular window partition(3x3 -> 2x2)

- The cyclic shift makes computional cost same as regular window partition(3x3 -> 2x2)
3. Result
-
Image classification in ImageNet
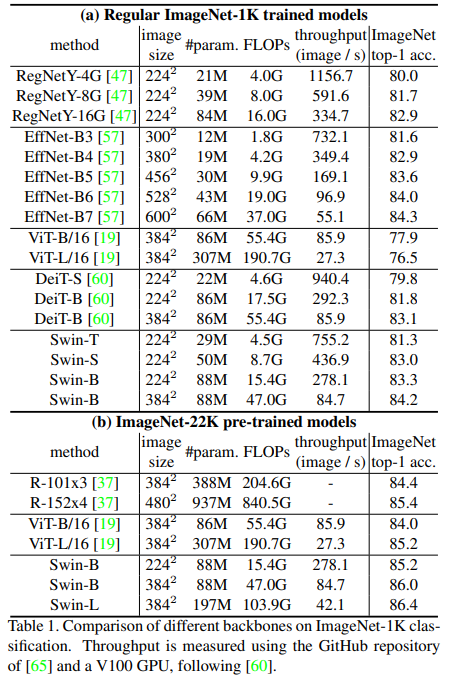
-
Object detection in COCO
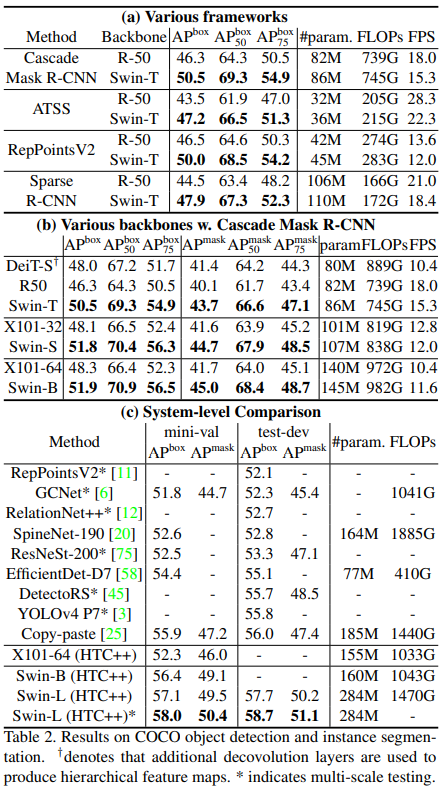
-
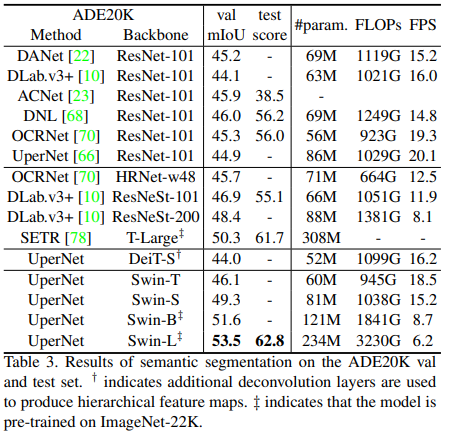
Semantic Segmentation on ADE20K
Reference
https://arxiv.org/abs/2103.14030v2

호수공원