Introduction
IVIF에서 사용하는 prevalent tool은 3가지 정도입니다.
GAN
FusionGAN에서 Generator는 fused image를 생성하고, discriminator는 fused image에다 visible image의 정보를 더 넣도록 합니다.
왜냐하면, visble/infrared에서 rich texture를 가지고 있는 것은 visible image이기 때문입니다.
이에 더 발전하여, conditional GAN이 나오면서 detail information과 target boundary의 sharpening을 향상시켜 GAN-based image fusion이 각광 받고 있다고 합니다.
Multi-Scale transformation
filter or optimization method를 이용하여 image를 spatial domain에서 background(Low-frequency)와 detail content(High-frequency)로 transform시켜 최종 fusion image를 만드는 것입니다.
detail content의 feature는 pre-trained network를 사용하여 feature를 extraction합니다.
일반적으로 VGG19의 모델을 사용하며 detail content는 fusion과정에서 infrared의 thremal objects와 visible objects는 서로 distinct하기 때문에 매우 중요한 과정이여서, VGG19와 같은 DL-based를 사용합니다.
최종 fusion image는 detail/background의 fusion feature map을 merge하여 reconstruction하게 됩니다.
AE(Auto-Encoder)
Encoder에서 feature map을 만들고, Decoder에서 feature map을 다시 upsampling하여 최종 image를 만드는 method입니다. 이는 segmentation 등 다양한 활용분야가 있으며, DIDFuse도 이와같은 mechanism을 보여줍니다.
하지만 저자는 Limitation을 이와같이 설명합니다.
DL-based가 input image의 feature 혹은 fusion strategy에서만 사용된다고 합니다. 이는 High/Low frequency로 decomposition을 하는데 DL을 사용하지 않았다는 것이 주요 Limitation으로 생각하였으며, Mulil-Scale과 AE를 서로 결합하여 DIDFuse Network가 만들어졌다고 합니다
Two-folds
First Deep Learning Image Decomposition Model
DIDFuse는 IVIF task에서 first deep learning image decomposition model입니다.
AE를 사용하여 fusion과 decomposition을 하게 되는데, 정확하게는 fusion은 를 사용합니다.
AE에서 Encoder는 각 source image를 decomposition을 하는 것과 feature를 extraction하는 것이며, Decoder는 이러한 feature를 reconstruction하는 것이 주요 목적입니다.
Dataset
Vis/Ir task에서 dataset이 매우 부족하였는데, 이를 TNO를 포함하여 FLIR, NTR도 같이 이용하였고, 3가지 dataset에서 모두 좋은 성능을 보여주었습니다.
Related Work
DIDFuse는 U-Net과 매우 관련이 높은 network입니다.
U-Net은 Contracting/Expanding Path, 2가지의 path가 존재하는데 일반적인 AE와 비교하여 Contracting과 Expanding을 서로 연결하는 skip connection이 존재합니다.
이는 Contracting path의 중간 layer에서 얻은 feature map을 Expanding Path에 연결하여 channel-wise로 concat하게 되는데 더 빠른 수렴 속도와 thick feature map을 생성하여 더 높은 성능을 보여주었다고 합니다.
또한, 일반적은 AE는 encoder의 마지막 feature map만을 사용했는데 이는 초기/중간 layer의 feature map을 활용하지 못한다는게 limitation으로 뽑힙니다. (추상화 단계가 낮아짐)
Network Architecture
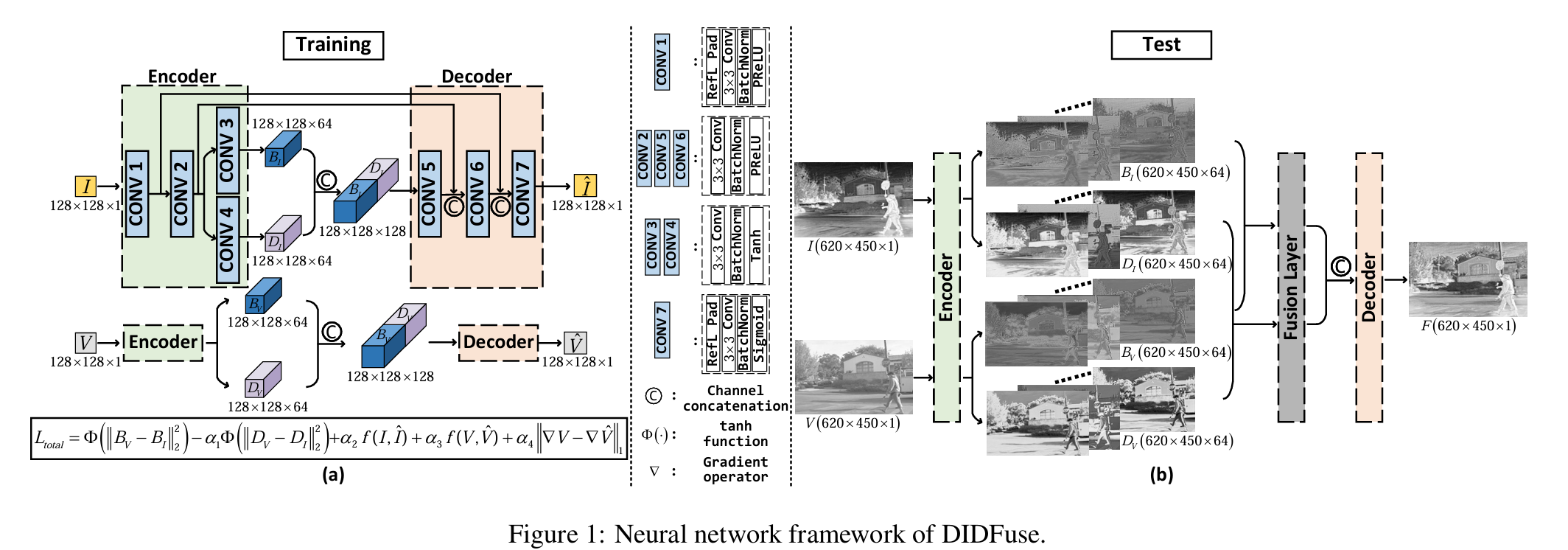
Figure 1. (a)
input으로는 Vis/Ir image가 들어가게 되고, network의 구조는 서로 똑같지만 서로 다른 network (2개)에 들어가게 된다.
부터 까지는 Figure 1 (a)와 (b) 사이에 있으니 참고 바랍니다.
여기서 중요한 것은 Encoder의 output이 가 나오게 되는데, 는 Low-frequency feature map, 는 High-frequency feature map을 의미하게 됩니다.
단순히 filter를 적용해서 Low/High로 나눠지는 것이 아니고 loss function에서 이를 면밀히 정의하고 있기 때문에 가능한 것이다.
이를 Decoder의 input으로 넣기 위해서 를 channel-wise로 concat을 해주게 됩니다. 앞에서, Encoder의 각각 의 output이 Decoder의 의 output인 feature map에다가 channel-wise concat을 해주게 됩니다.
이는, 더 나은 성능과 수렴 속도를 보장하게 되는데 다양한 Encoder에서의 각 conv layer의 feature map을 활용하였기 때문이라고 볼 수 있습니다. (U-Net과 장점이 같음)
따라서, Decoder의 output은 로 input image 각각의 feature map이 생성이 되었습니다.
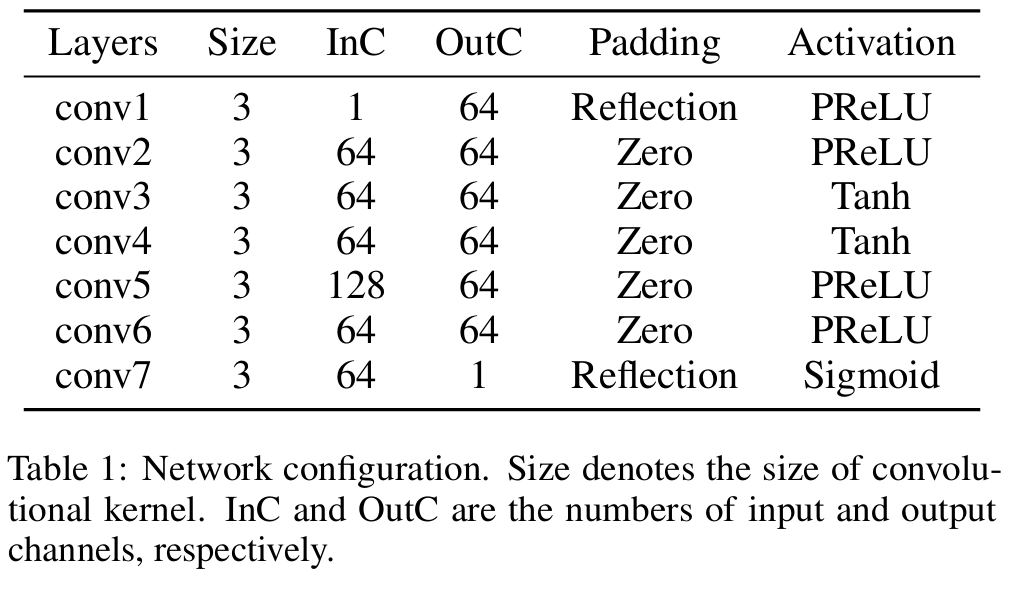
첫번째와 마지막 conv는 fused image의 artifact of edge를 방지하기 위해 reflection padding을 사용하고, conv3와 conv4는 tanh를 썼는데 이는 output의 대칭성을 유지하는 함수로, image의 detail과 background를 표현하는데 유리하고, conv7의 sigmoid는 original image를 reconstruction하는데 매우 유용하다고 합니다.
Loss Function
Loss Function은 다음과 같습니다.
background feature map은 source image에서 common feature map입니다.
반면에, detail feature map은 distinct characteristic을 가지고 있습니다.


위의 visible, infrared image는 서로 다른 modality에 있어 중복된 정보가 없는 것이 아닙니다.
특히, background(Low-frequency)는 common feature로 구성이 될 수 밖에 없는데 detail content는 확실히 distinct characteristic인 사람이 보입니다.
따라서 우리는 detail feature map은 매우 중요도가 높지만 background는 상대적으로 detail보다 낮은 값으로 구성이 되어야할 것 입니다.
에서 는 Base Part로 Low-frequency를 의미하는데 는 minimize이 되어야하며, 는 Detail Content로 High-frequency로 는 maximize되어야합니다.
따라서, detail content에 음수를 넣게 되면 해당 수식은 maximize해지게 될 것입니다.
(는 tanh입니다.)
이며 각 Ir, Visible의 pixel intensity를 유지하기 위함입니다. (SSIM은 Luminance, Contrast, Structure로 되어있습니다.)
있으며 는 값을 정규화해준 값으로 생각합니다.
gardient sparsity penalty는 기울기 희소성을 유도하는 regularization term으로, 이는 급격한 변화(pixel간에)는 edge에서만 발생해야하기 때문에 gradient sparsity를 유도함으로써, 급격한 변화가 없는 부분은 보존하고 edge만 detect하게끔 합니다.
이를 통해서, 자연스럽고 부드러운 이미지를 복원할 수 있게 도와줍니다.
이는 visible image는 texure에 대한 정보가 많기 때문에 reconstruction of visible images에 texture를 유지하는 것에 힘써야합니다.
따라서, gradient sparsity penalty는 로 texture(edge, 질감 등등)를 보존합니다.
Figure 1. (b)
이는 fusion strategy까지 이용해서 fusion output을 만드는 과정입니다.
다양한 strategy가 있지만 L1 norm을 사용했다고 하며, 여기서 다르게 추가한 것은 softmax의 분모와 분자에 box blur(mean filter)를 취해주었습니다.
가 box blur를 의미합니다.
따라서 가 되므로, 최종 fusion output은 가 됩니다.
는 element-wise multiplication, 는 element-wise addtion입니다.
