CNN-based image fusion에서 last layer만을 사용해서 feature들을 사용하는 fusion method는 middle layer들에서 획득한 feature들을 사용하지 못한다는 것을 Limitation이라고 정의했다.
따라서, DenseFuse는 위의 Limitation의 문제를 해결했으며 deep learning architecture는 encoding, decoding network로 구성되어 있다.
Encoding에서는 각 image의 feature들을 뽑아내며, Dense block으로 이루어져 있으며 Decoding은 fused image를 생성한다.
Network
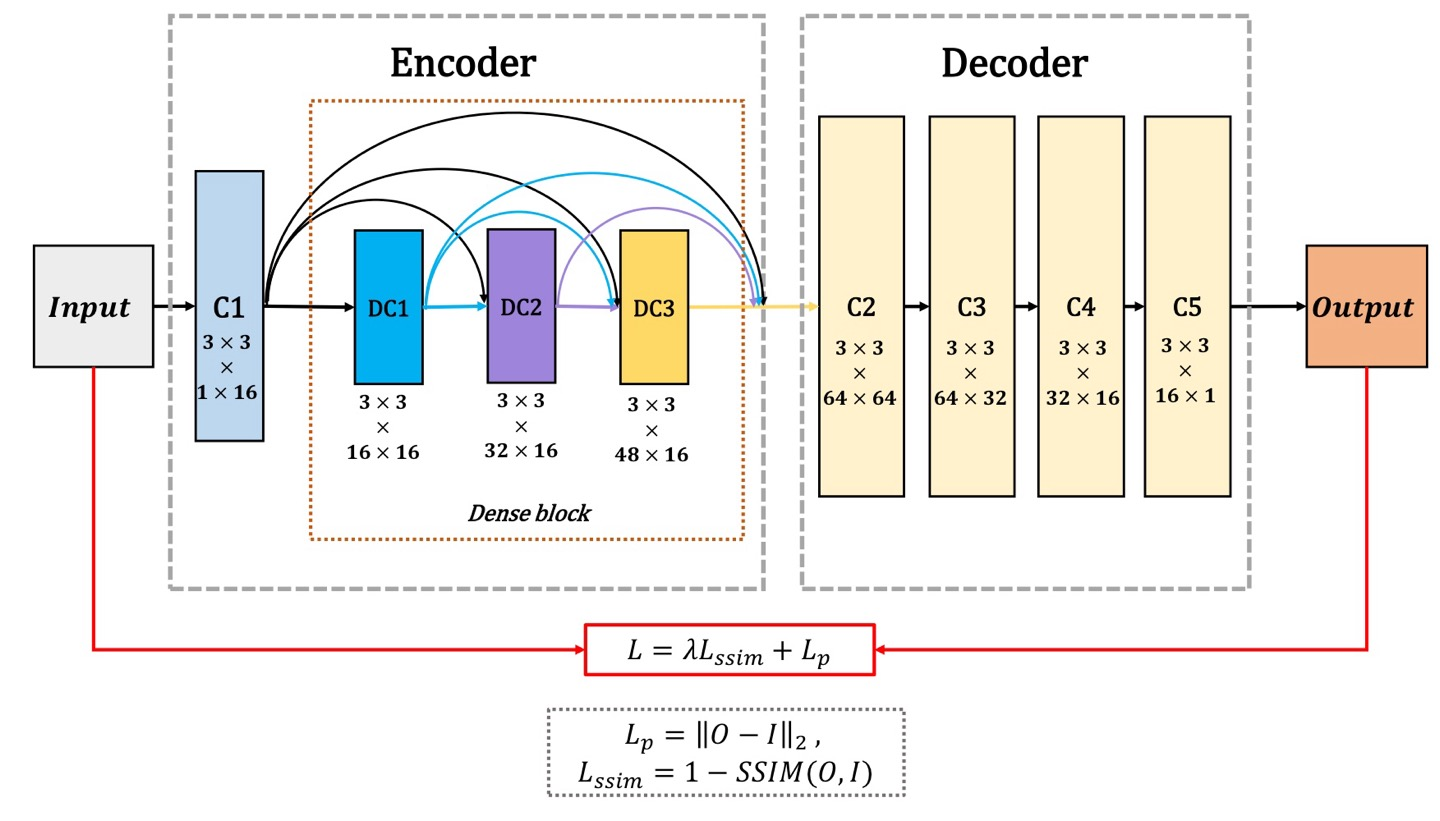
input은 논문에서 로 서로 다른 modality의 image를 말하며, input channel은 1개(gray scale) or 3개(RGB)든 똑같은 fusion strategy를 가지기 때문에 상관없다.
전체 구성은 Encoder, Fusion Layer, Decoder로 구성되어 있다.
Encoder
Encoder의 구성은 크게 C1과 Dense block으로 구성되어있으며 CNN을 사용하기 때문에 image의 feature들을 extraction하는 역할이다.
따라서, C1은 의 kernel size를 가지고 있으며 output channel은 16개가 된다.
Dense block은 의 kernel을 사용하지만 각 output을 다음 layer의 output에다가 concatenate하는 구성이며, 각 output은 16개의 channel number를 보여준다.
이러한 stack은 다음과 같은 장점이 있다고 한다.
-
Can preserve as much information as possible
-
Improve flow of information and gradients through network, which makes network be trained easily
-
The Dense connections have a regularizing effect, which reduces overfitting on tasks
Dense block은 last layer만을 사용하지 않고 middle layer도 같이 사용하기 때문에 useful information을 얻을 수 있다.
또한, 중요한 것은 kernel은 만을 이용했으며 각 output은 16개의 channel number만을 사용했다는 것이다.
padding은 zero padding이 아닌, reflection padding을 이용했다고 한다.
reflection padding은 zero padding과 비교해서 edge부분에서 비정상적인 값이 발생할 수 있지만, reflection은 자연스러운 연속성을 유지할 수 있습니다. 이로 인해 더 나은 성능을 낼 수 있는 경우가 많습니다.
예를들어, 가 input이고 이를 reflection pad를 2로 설정하게 되면, 가 된다.
이는, input image가 3행3열부터 6행6열까지이며 나머지는 padding이 된 것인데, 3행1열부터 3행2열의 값을 보면, 3행3열을 기준으로 3행4열, 3행5열의 값이 reflection되었다는 것을 알 수 있다.
Loss Function
Loss Function은 이다.
는 pixel loss로써 로 L2-Norm(Euclidean distance)을 사용하였으며 O는 prediction output image, I는 input image를 의미하며, 만약 infrared/visible image가 input으로 들어가게 되면 이 되겠다.
에서 에 대해서 먼저 알아보자.
SSIM
SSIM은 Structural Similarity Index Measure로 2개의 image의 유사도를 luminance, contrast, structure 3가지 요소를 이용하여 비교하는 방법이다.
output은 input값에 따라 0~1 or -1~1의 값이 나오는데 1에 가까울수록 2개의 image가 유사하다는 것을 의미한다.
Luminance
빛의 양이라고 하며, image의 pixel value를 사용한다.
-
: pixel value
-
: 전체 pixel 개수
-
: image의 평균 luminance
따라서, 2개의 image가 라고 할 때 luminance를 비교하기 위한 식은 다음과 같으며, C1은 epsilion이다.
Contrast
image내에서 빛의 밝기가 바뀌는 정도로 pixel간의 값이 얼마나 차이가 나는지 정량화 할 수 있으므로 표준편차를 이용한다.
-
: image pixel간의 표준편차
-
: image pixel의 평균
N-1로 나눠준 이유는 모집단의 표준편차를 추종하기 위한 값이므로 표본 표준편차의 값이기 때문이다. 이는 표본 표준편차가 모표준편차를 정확히 추종하기 못하기 때문으로, 표본 크기 N이 충분히 크지 않을 경우 표본 분산이 모분산보다 작기 때문에 N-1의 값으로 설정하면 표본 분산이 약간 커져 유용하게 사용이 가능하다.
따라서, 2개의 image가 라고 할 때 constrat를 비교하기 위한 식은 다음과 같으며, C2은 epsilion이다.
Structure
pixel value의 구조적인 차이점을 나타내고 성분 확인 시 edge를 나타냅니다.
이다.
은 값을 사용하는데, 이를 loss function에 반영해야하므로 이 되겠다.
해당 논문에서는 로 사용했다고 한다.
다시, 원점으로 돌아와 에서 λ는 와 가 3배 정도 차이가 나기 때문에 각 중요도를 맞추기 위한 hyperparameter 값이다.
Fusion Layer
논문에서 이 전까지 사용해왔던 Addition fusion strategy와 새롭게 제안한 method()를 설명한다.
Addition fusion strategy
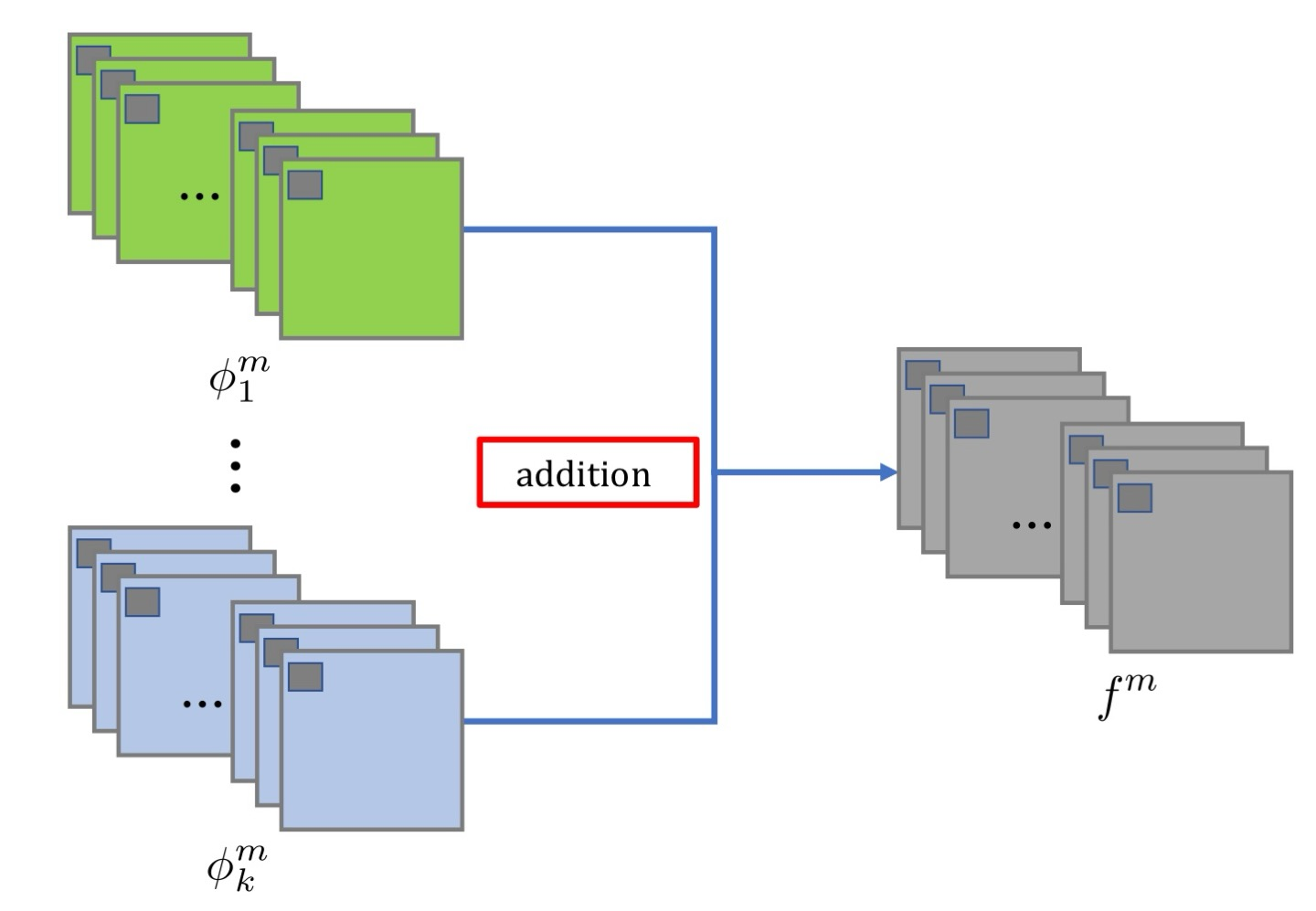
Encoder에는 visible, infrared image가 각각 들어가게 된다. 따라서, fusion strategy에 들어가게 되는 channel number는 각각 64가 되겠다.
로 fused feature map들이 구성된다.
-
m: feature map이며 channel number가 각각 64이니, 이다.
-
: fused feature maps이며, Decoder의 input
-
: i번째 Encoder의 output
가 나오게되면, 이는 Decoder의 input이 된다.
Addtion fusion strategy는 salient feature를 selection하기에는 rough fusion strategy이기 때문에, 우리는 좀 더 정교한 과 soft-max operation을 사용한다.
해당 글은 이전 포스트인 Infrared and Visible Image Fusion using a Deep Learning Framework에 있으니 참조바란다.
Training Phase
CNN은 Encoder와 Decoder에서만 쓰이기 때문에 2가지만 train시키면 된다.
Encoder와 Decoder의 weight가 fix된다면, fusion strategy를 사용하여 fusion output을 얻었다고 한다.
visible,infrared의 dataset이 부족하기 때문에, 약 MS-COCO dataset 80,000장으로 train시켰으며 256으로 resize 및 gray scale로 변환해주었다고 한다.
또한, 값이 증가함에따라 더 빠르게 수렴했다는 것이 key point이다.
구현
