Abstract

Classification, Object Detection과 관련된 새로운 모델로 Inception CNN Architecture을 제안한다고 한다.
VGG16에서 Convolution layer가 많을수록 모델의 performance가 좋아진다는 것을 알았다. 하지만 depth가 깊어질수록 연산이 많아지기 때문에 문제가 있었다.
하지만, Inception에서는 Computing Resource 즉, 연산을 그대로 유지하고 depth와 width를 키웠다고 한다.
이를 "GoogLeNet"이라고 불리우기도 한다.
Related Work

ImageNet과 같은 매우 많은 dataset에서는 overfitting을 방지하기 위해 dropout을 쓰면서 layer를 깊이 쌓던가, layer의 size를 키우는 방법을 선택한다고 한다.
CIRAF와 MNIST에 비해 layer를 깊이 쌓던가 키우는 이유는, parameter의 숫자가 늘어나게 되면서 non-linearlity가 늘어나 더욱 복잡한 이미지의 패턴을 학습하는 것에 알맞기 때문이다.
하지만, 위와 같이 overfitting의 가능성이 있을 수 있어 dropout과 같은 방법을 사용하는 것이다.
또한, MaxPooling이 spaitial information을 없애는 우려에도 불구하고 다른 domain에서도 성공적으로 쓰이면서 performance가 향상되었다고 한다.
MaxPooling 자체가 weighted sum된 값을 이용하여 해당하는 kernel size에 있는 element마다 제일 큰 값을 추출하기 때문에 해당 이미지의 중요도가 높은(weighted sum의 값이 높은) 값만을 추출하기 때문에 spatial information은 없애지만, 정확도가 올라가게 되는 것 같다.
즉, 사람이 있지만 사람의 제일 특징적인 부분을 model이 골라 학습한다고 생각하면 된다.

Network의 representational power를 올리기 위해서 Network-in-Network를 사용했다고 한다.
조금 더 구체적이게, 1x1 convolution layer를 사용했다고 하는데 이는 Computational Bottleneck을 방지하기 위해 dimension reduction의 역할을 하며, depth의 증가와 layer의 size를 증가시키는데 도움이 되었다고 한다. (1x1 conv layer + ReLU는 1개의 set이다.)
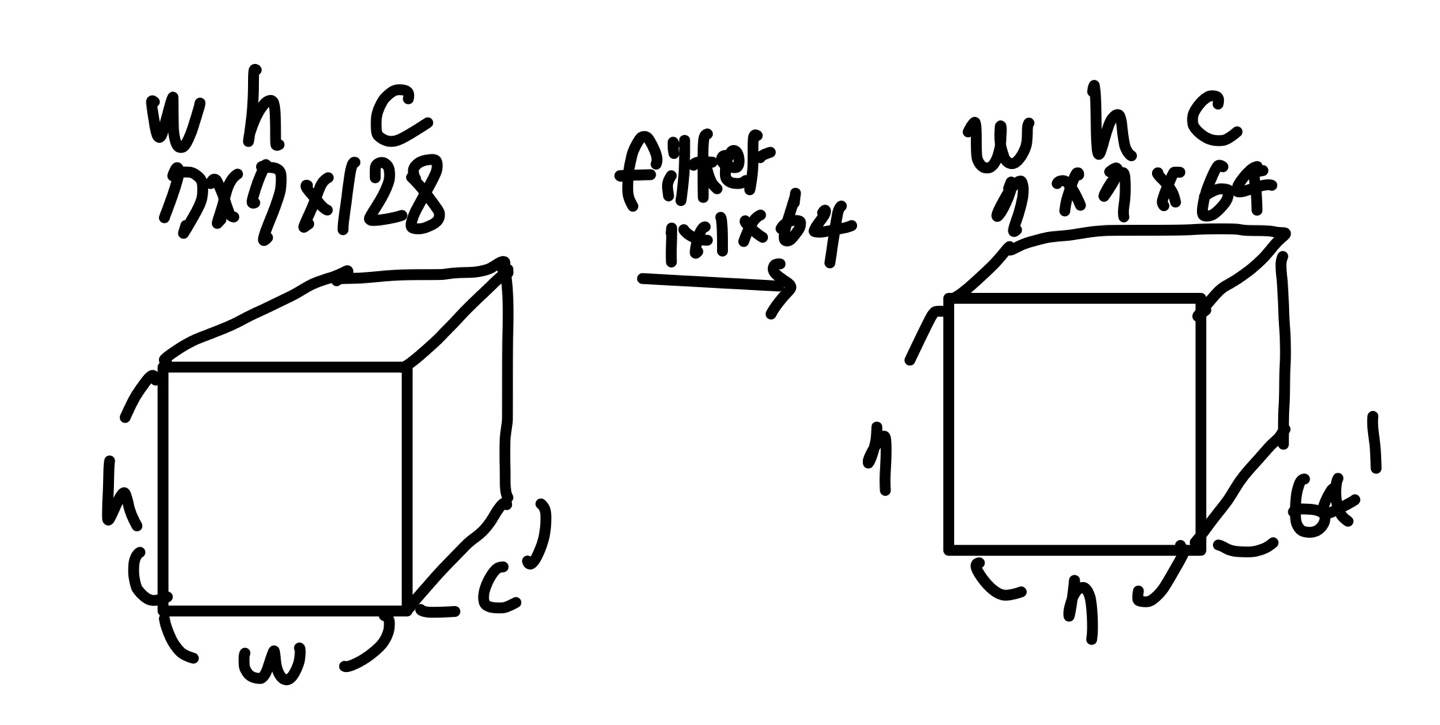
input img의 크기가 (7x7x128)이라고 해보면 우리가 filter의 kernel size는 1x1 그리고 channel수는 64로 지정해보면(channel수는 사용자가 정할 수 있다.), filter의 channel수의 개수가 output의 channel수가 되니, (7x7x64)가 된다.
이때 input의 channel 수는 128이였던 반면, output은 64로 오히려 parameter의 숫자가 줄어든 것을 볼 수 있다.
물론 parameter의 숫자가 줄어듬으로써 모델의 performance의 영향이 있지만, layer를 깊게 쌓을 수 있으므로 해당 영향을 어느정도 커버해주는 느낌이다.
Motivation and High Level Considerations

당연히, 모델의 성능을 안전하게 끌어올릴 수 있는 가장 안전한 방법은 labeled data가 많은 것이 가장 좋다.
하지만, 유의미한 데이터를 끌어모으고 전처리 과정에서 매우 많은 시간을 쓸 뿐만 아니라 위 Figure 1과 매우 비슷한 데이터도 범주를 잘 나눠야하기 때문에 고급 인력이 필요하다고 말한다.
또한, 모델의 성능은 layer가 깊을수록 성능이 좋아지지만 앞서 말씀드린 것과 같이 overfitting이 되기 쉬워 이는 위험한 방법일 수 도 있다.
해당 논문에서는 layer를 아무리 키워봤자 weight의 값이 0으로 수렴하기 때문에, weight가 updated가 되지 않는다고 한다. (backpropagation 과정에서 layer가 너무 깊기 때문에 vanishing gradient가 생기게 된다.)
그래서 이는 memory 측면에서는 매우 낭비라는 것이다.
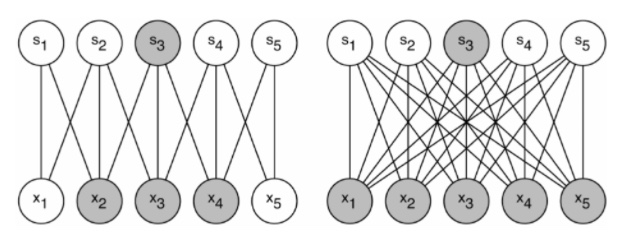
[왼쪽 그림] 과거 dataset의 분배 확률은 sparse하게하고 더 큰 심층 신경망으로 표현이 가능하다면 입력에서 출력까지의 layer간의 노드들은 매우 연관이 가까운 것만 연결하도록 하게 했다고 한다.
[오른쪽 그림] 하지만 현재(2014년 기준)에는, 병렬 network에 최적화 하기 위해서 full connection으로 다시 바뀌었다고 한다. 이는 CPU연산에서 GPU연산으로 모델을 학습시키면서 복잡한 연산에 최적화된 GPU로 변환하게끔 모델을 변환시킨 것이다.
따라서, 더 많은 filter의 수, batch size는 dense연산을 가능하게끔 하도록 한다.
Architectural Details
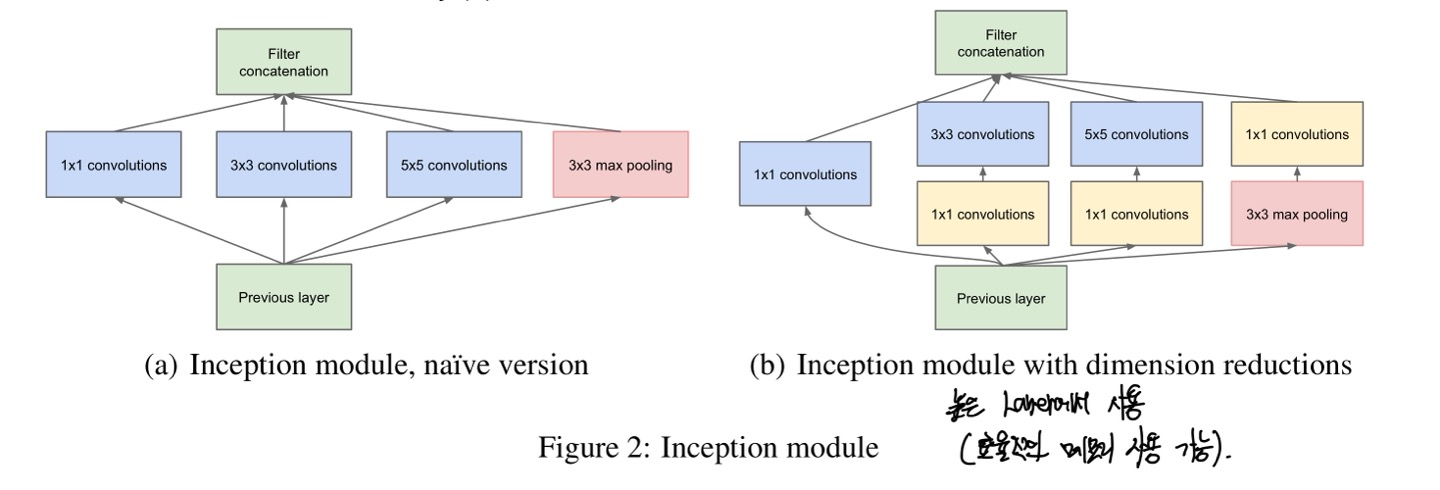
Inception에서의 main idea는 CNN에서 각 요소를 최적의 local sparse structure로 근사화하고, 이를 dense component로 바꾸는 방법을 찾는다.
이를 논문에서 조금 어렵게 말해서 조금 쉽게 말하면, 이미지에서 중요한 부분을 뽑아두고 해당하는 부분을 그냥 Dense하게 모아둬 학습하는 것을 의미한다.
(sparse matrix를 서로 묶어 dense한 submatrix를 만드는 방향성)
백광록에서 사진을 퍼왔습니다 !
input layer와 가까운 낮은 layer에서는 특정 부분에 correlated unit이 모여있다. (관련있는 부분이 모여있다는 뜻)
이는 단일지역에 집중되어 있어서 1x1 conv로 처리가 가능하지만, 맨 오른쪽과 같이 특정 부분에는 좀 더 넓은 영역의 conv filter가 있어야한다.
즉, Inception module에는 1x1, 3x3, 5x5 conv를 연산 처리하여, correlated unit을 다양하게 연산처리하여 반영한다.
Figure2에서 (b)를 보면 1x1 conv를 추가하여 input과 가까이 있는 layer와 output을 제외한 layer에서 이를 쓰게 되며 효율적인 메모리를 사용하게끔 할 수 있는 layer가 되었다.
GoogLeNet Network
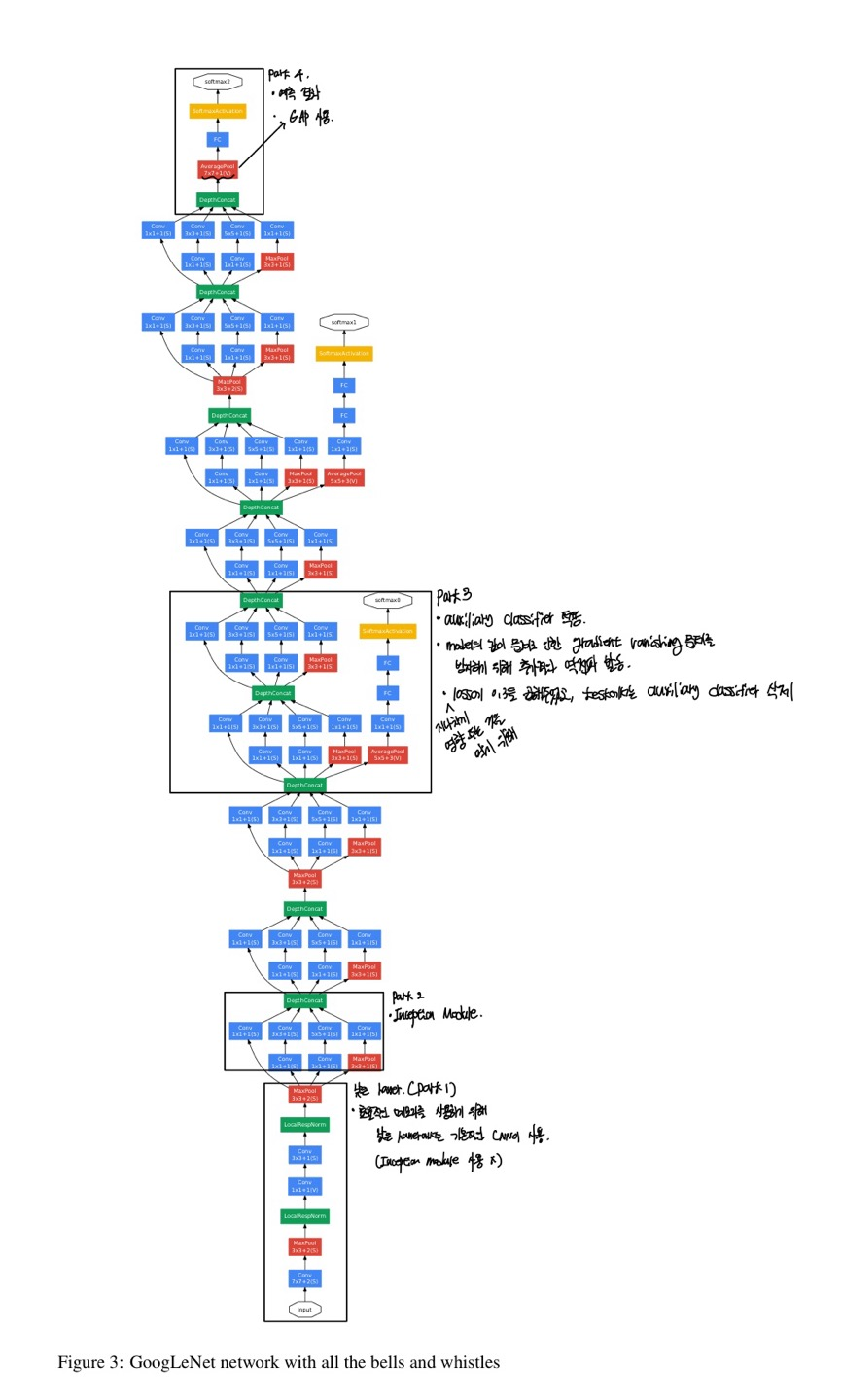
part1에서는 효율적인 메모리를 사용하기 위해 기본적인 CNN을 사용하였으며
part2와 part3에서는 inception module을 사용하며, 다른점이 있다면 part3에서는 auxiliary classifier를 적용하며 model의 깊이 문제로 인한 vanishing gradient 문제를 방지하기 위해 추가적인 backpropagation을 발동하여 해당 문제를 방지한다.
지나치게 영향 주는 것을 막기 위해 loss에 0.3을 곱해주었으며, test에서는 auxiliary classifier를 삭제하였다고 한다.
part4에서는 예측 결과를 도출해내는 곳이며, AveragePooling을 통해 vector를 만들어 Fully Connected layer에 들어가 image classifier를 수행하여 마지막, softmax를 통해 가장 높은 확률을 가지는 label이 input img의 label로 지정해주게 된다.
학습 시에는, 0.9 momentum & SGD를 이용하였으며 8epochs마다 4%씩 learing rate를 감소시켰다고 한다.
구현
PASS
