동국대학교 AI융합학부 전공 수업인 "개별연구(CSC 딥러닝 기반 Computational Camera 기술 연구)"에서 읽고 연구할 논문입니다.
해당 논문은 논문 링크에서 읽으실 수 있으며 github에 코드가 있습니다. (연구실 : Lab)
모델의 성능 개선을 통한 논문 작성을 목표로 하기 때문에 논문 해석, 단어가 무엇을 의미하는지 등 자세하게 다룹니다.

Image fusion이란, 상호 보완적인 정보를 가진 다양한 modality들의 image를 서로 fusion하여 더 많은 정보를 포함한 이미지를 생성하는 것을 목표로 합니다.
(여기서 modality란, RGB, IR 등의 image들을 이야기합니다.)
learning-based의 방식으로 performance가 증가하기는 했지만, Convolution의 depth를 깊게 쌓음으로써(large receptive field 때문에 -> 이는 1개의 pixel당 더 많은 정보를 함양하기 위함) image의 detail, context value를 잃어버린다고 합니다.
따라서 이 논문에서, CMTFusion(cross-model transformer-based fusion)을 통해 source images들 간의 global interaction을 capture합니다.
global interaction이란, data의 모든 요소들이 서로 어떻게 연결되어 있는지를 분석하고, 이를 종합적으로 이해하는 것을 의미하는데 image같은 경우 source image 내의 관계를 고려하는 것을 말합니다.
Image fusion의 pipeline은 다음과 같습니다.
1. RGB, IR image 각각, 서로 다른 kernel size를 가진 filter를 이용하여 feature map을 구성합니다.
2. CMTs를 이용하여 spatial/channel domain에서 redundancy들을 제거합니다. 이는 global interaction을 capture하기 위해 사용합니다.
3. gated bottleneck을 사용합니다. 이는 source image들끼리 더 나은 상호보완적 information을 얻기 위해 source images끼리 interaction합니다.(cross-domain interactions)
4. 마지막으로, fusion image는 fusion block을 통한 refined된 feature map을 통해서 source image간 spatial/channel의 필요한 information만을 뽑아 만들어집니다.
결과적으로, 최신 RGB/IR Image fusion 모델과 비교해 더 우수한 performance를 보였을 뿐만 아니라, computer vision에서도 뛰어난 performance를 입증했습니다.
Introduction

Image fusion은 remote sensing, medical diagnosis, security 등 다양한 산업 분야에서 쓰인다고 합니다.(여기서 말하는 Image fusion은 RGB/IR에 국한되지 않습니다.)
Remote sensing이란,
지구 표면, 대기, 해양 등의 환경을 직접 접촉하지 않고 멀리 떨어진 곳에서 위성, 항공기 등의 장비를 통해 데이터를 수집하는 기술을 말합니다.
Visible image란 RGB image(가시광 이미지)를 이야기하는데 texture details를 매우 잘 capture하는 것이 장점입니다. 하지만 날씨에 따라 image의 변화가 심하다는 것이 단점입니다.
반면에, infrared image는 사물에서 thermal radiation(열 복사) 방출을 capture하기 때문에 날씨에 따른 영향이 매우 적습니다. 하지만 texture detail의 information은 부족합니다.
따라서, RGB/IR Image의 단점들은 서로의 장점을 통해 보완할 수 있습니다.
초기, RGB/IR Image fusion은 multi-scale transform, low-rank representation, sparse representation 등 과 같은 수학적 이론을 기반으로 한 이론들이 나왔다고 합니다.
해당 이론들은 manually designed된 features들로 사용자가 직접 정의하는 듯 하다. 따라서 capability, characterization의 표현 능력은 당연히 limited되어있을 수 밖에 없다. 따라서 deep learning-based approach(CNN)로 발전되고 있다.
논문에서 "limit"라고 표현한 이유는 RGB/IR Image fusion은 서로 다른 information을 제공함으로써 이들의 서로 상호보완적인 information을 효과적으로 fusion하려면 복잡한 pattern을 이해하는 것이 매우 어려워 이를 "limit"라고 표현한 것 같다.
하지만, Convolution layer가 쌓임으로써 high-level information의 정보만 extracted될 뿐, low-level의 대한 정보는 잃게 된다.
High-Level-features
이미지에서 더 추상적이고 의미있는 정보로써, 이미지의 전체적인 맥락이나 객체 간의 관계 등 고차원적 정보를 말합니다. 이는 conv의 depth가 깊으면 깊을수록 해당 features에 대한 정보를 더 많이 가집니다.
Low-Level-features
이미지에서 얻을 수 있는 기본적인 정보로 세부적인 pixel단위의 특성을 이야기합니다.
이는 초기 conv layer에서 extracted됩니다.

전통적인 deep learning-based fusion algorithm들은 고정된 kernel size만을 이용하였기 때문에 local information만을 얻을 수 있었다고 한다. 따라서 source image간의 global interaction을 capture하는 것은 한계가 있을 수 밖에 없다.
(kernel size가 클수록 pixel간의 context를 extract할 수 있지만, convolution연산 시 kernel size가 크면 연산량이 기하급수적으로 올라간다. 최대 )
따라서 transformer는 NLP에서 long-term dependency를 해결하여 context를 이해하는 것에 특화되었으며 이를 Image fusion에서도 이용한다.
Vision에서는 long-range dependency로 서로 멀리 떨어져 있는 pixel에서도 context를 파악할 수 있도록 한다.
Long-term dependency
data나 information의 여러 element간의 관계가 시간적으로 멀리 떨어져 있거나, 서로 먼 위치에 있을 때도 효과적으로 이해하고 modeling하는 능력을 의미한다.
이를 "Self-Attention"을 통해 해당 문제점을 해결한다.
참조: Attention-is-all-you-need
하지만, image fusion에서 transformer는 매우 훌륭한 performance를 보여주었지만 self-attention의 연산량도 매우 많다고 합니다.
따라서 high-resolution image를 processing하기에는 부적합하다고 합니다.
Abstract에서 말한 pipeline보다 더 자세하게 설명해보겠습니다.
이 논문에서는 source image들 간의 서로 상호보완적인 information을 통해서 image를 fusion하는 것이 목표입니다.(global interaction을 통해서요.)
처음에는 infrared, visible images들의 다양한 feature들을 뽑기 위해 multi-scale의 filter를 이용합니다. coarse-to-fine manner라고 되어있는데 이는 scale이 커졌다가 갈수록 작아지는 것을 의미합니다.(kernel size!!)
다음, source image들 간의 서로 상호보완적인 information을 추출하기 위해서 spatial/channel domain의 redundancy를 제거하고 CMT는 spatial/channel 각각의 transformer로, 독립적으로 구성되어있습니다.
CMT는 global interaction과 context들을 capture함과 동시에 spatial/channel domain의 redundancy를 제거한다고 보시면 됩니다.
gated bottleneck을 통해서 source image들 간의 상호보완적 information을 교환합니다.(이를 cross-domain interaction이라고 표현했습니다.)
이후, fusion block은 refined된 feature들로 fusion image의 결과를 생성합니다.
Related Work

영상처리와 컴퓨터 비전에서 딥러닝의 발전과 동시에, image fusion은 매우 발전하고 있다고 합니다.
image fusion은 CNN, GAN based로 2가지의 카테고리로 나뉜다고 한다.
CNN
infrared/visible image들의 상호 보완적인 정보를 뽑기 위해서 single network를 사용한다고 하는데, 이는 서로 다른 modality에 동일한 block을 사용하기 때문에 source images의 상호 보완적인 정보를 추출하는 것이 매우 어려워 fusion의 결과물이 좋지 않다고 한다.
그래서, infrared/visible features를 독립적으로 추출되어진다면 각 이미지의 intrinsic features를 보존하는데 더 좋다고 합니다.
intrinsic feature란, 각 image에서 추출한 feature를 의미합니다.
GAN
convolution layer가 쌓일수록 이미지에서 detail한 feature를 뽑지 못하여 fusion 결과물은 unbalanced 이미지를 생성할 수 있다고 한다.
그래서 GAN을 기반으로 한 image fusion 알고리즘이 나오게 되었는데 이는 single discriminator를 사용하여 fusion 결과물과 source images들 간의 차이점을 구별하여 fusion 결과물을 생성한다고 한다. 이는 single discriminator를 사용하기 때문에 source image에서 bias가 생길 가능성이 높으므로 dual-discrimators를 사용하는 것이 high-contrast, texture를 잘 표현한다고 한다.(이는 bias가 감소) 즉, bias가 없어지는 역할을 해준다.
하지만 이는 long-range dependency를 해결하지 못하고 있는 상황이라고 한다.

transformer가 나오고 나서, 이는 pixel간의 global interaction을 추출하는 것이 매우 특출나 컴퓨터 비전에서도 잘 사용한다고 한다.
CNN과 transformer를 같이 사용하여 local/global information을 잘 추출할 수 있어 source image들간의 상호 보완적인 information을 보존하는 능력이 더 좋아졌다고 한다.
transformer에서 사용하는 self-attention은 image resolution(해상도)에 따라 연산량이 크게 증가한다. 하지만, CMTFusion은 source images간의 local/global interaction을 추출하는 연산량은 매우 효율적이라고 한다.
Proposed CMTFusion Algorithm
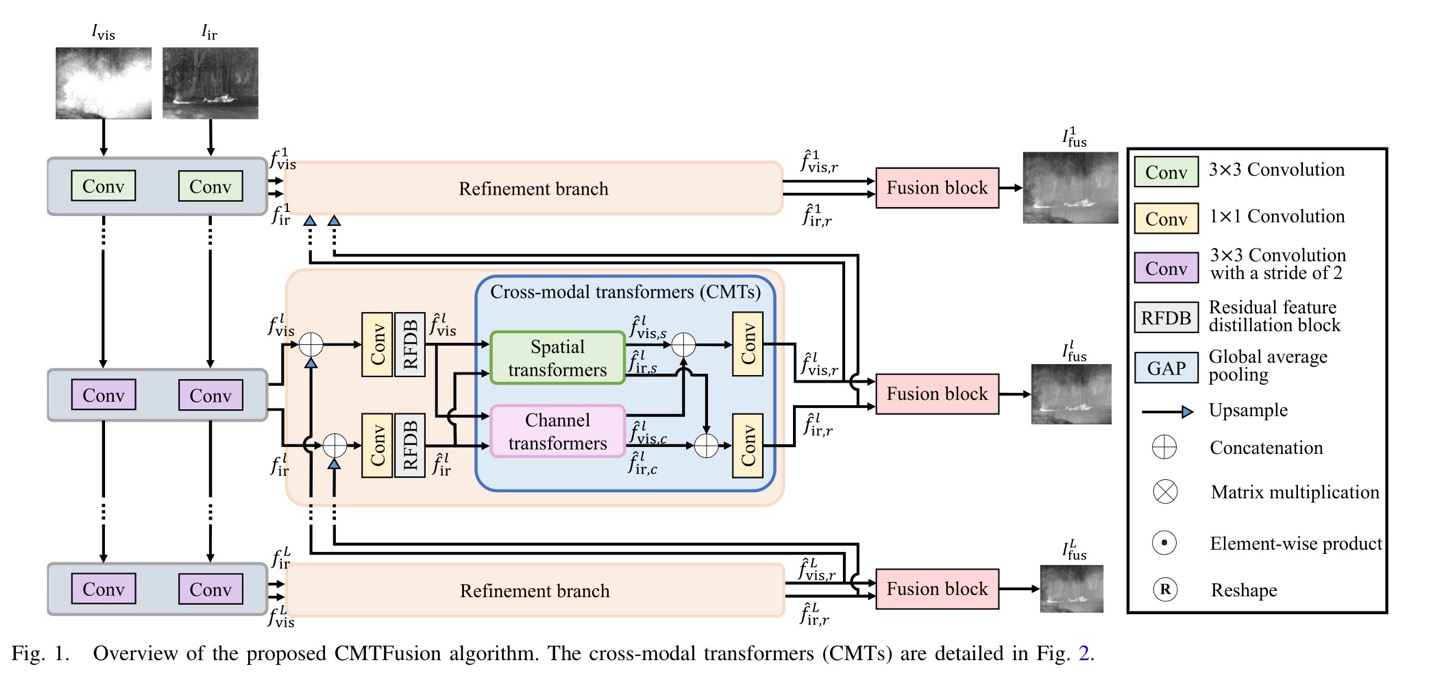
Overall Architecture
위의 Fig.1dms CMTFusion의 overview로, infrared/visible image들을 fusion하는데 coarse-to-fine manner로 fusion한다고 한다.
coarse-to-fine manner란, Image fusion하는 과정이 여러 단계로 이루어져 있는데 간단한 처리로 시작하여 이후, 더 자세한 정보와 세부사항을 반영하여 fusion의 품질을 개선하는 것.
infrared/visible 1개의 쌍인 는 conv layer를 통해 독립적으로 연산이 수행되며, 이때 kernel size는 3x3 or 3x3 with stride 2가 있다. (독립적으로 수행되며 가 각 source image의 output이다.)
Level 에서 source images 각각의 feature map은 source images의 global information을 추출하기 위해 refinement branch로 들어가게 된다.
refinement branch에서 enhanced featuers가 포함된 previous level과 현재 level에서의 feature map과 concatenate해준다. 이후 RFDB(Residual Feature Distillation Block)에 넣어주어 더 discriminative한 feature map을 얻을 수 있다.
RFDB에서 나온 feature map은 redundant한 information이 존재하니 CMTs가 이를 spatial, channel domain에서 irrelevance feature map을 estimated하여, 삭제한다. (이는 source images들 간 더 상호보완적인 값을 얻게 됌)
irrelevance feature map은 각 pixel location마다 얼마나 다른지 수치화시킨 값이고 이 값은 network가 source images들간의 상호 보완적인 information에 focus하게끔 한다.
마지막으로 fusion block을 통해 각 level에서 fused image 를 얻게 된다.
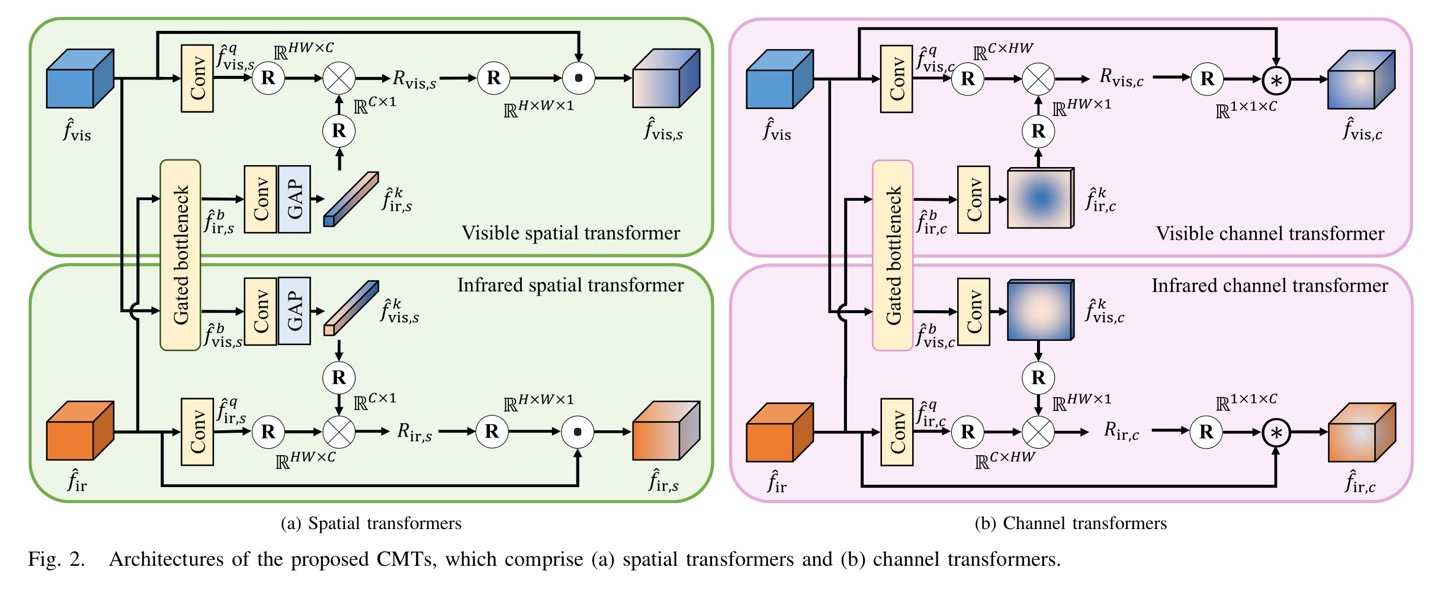
Spatial Transformers
spatial transformer는 말 그대로 spatial domain에서 source images들간의 상호보완적인 information을 추출하는데, 이는 visible/infrared feature map의 irrelevance(irrelevance feature map)를 통해 향상 시킨다고 한다.
spatial transformer가 입력값으로 받는 것은 RFDB의 output이고, 이를 논문에서 로 표현한다.
spatial transformer의 output은 로 표현(이는 refined된 feature map)
이때, infrared/visible transformer구조가 다르지 않고 똑같으므로 1개만 설명해보면 query를 생성하기 위해 1x1 conv를 이용하여 를 생성한다.
infrared/visible feature map은 서로 다른 modality이지만 redundant information이 포함되어 있으니 gated bottleneck을 구성하여 redundant information을 서로 공유한다.
key는 other modality의 feature map을 이용하며(만약 visible이면 infrared feature map을 이용), 마찬가지로 1x1 conv를 이용하고 1-dimension을 가질 수 있게 global average pooling을 사용한다.
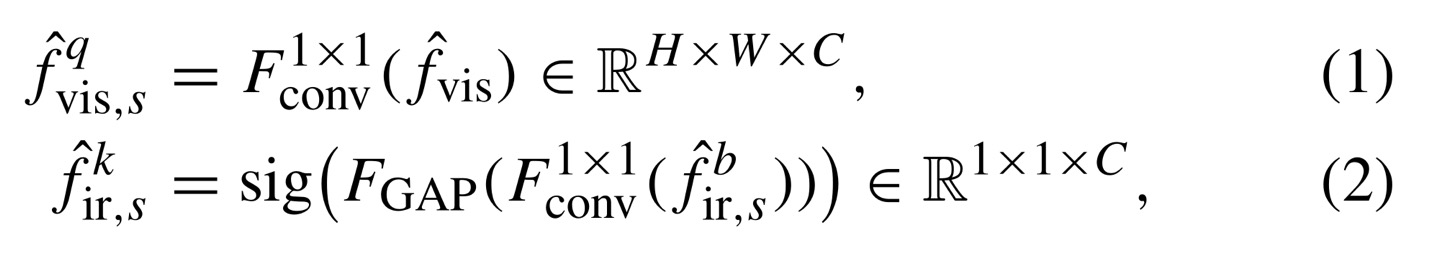
query와 key를 구하는 수식은 위와 같으며, multiplication 연산을 위해 dimension은 각각 X, X이 된다.(query, key를 구하는 것이 transformer를 이용)
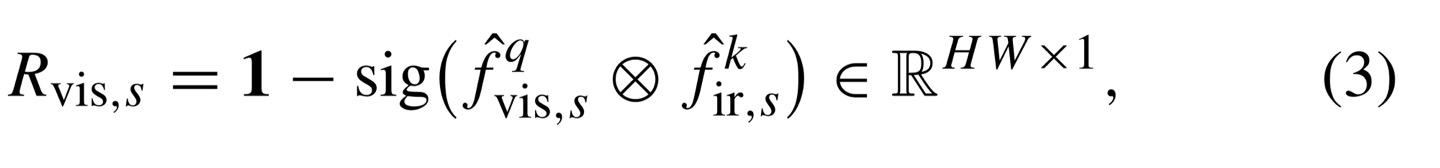
이후, irrelevance map을 만들기 위해 query, key의 multiplication한 값에 sigmoid function에 넣어준 다음, 1을 빼주게 된다.
1을 빼주지 않으면 relevance map이 된다.(이는 refinement branch와 어긋남)
irrelevance feature map을 얻었으니 input(output of RFDB)와 dot product를 해주게 되면 input값은 other modality의 redundant information을 제거하게 된다. (각 channel마다 계산해주게 되는 것을 잊지말기)
Channel Transformers
infrared/visible간의 상호보완적 information은 spatial information과 global context가 있다. spatial information은 spatial transformer를 이용하여 추출하였으니 global context는 channel information으로 추출한다.
spatial domain에서는 scene information(이미지 전체에 대한->channel을 포함)이 부족하다. 따라서 channel domain에서 irrelevance maps를 추출하는데 매커니즘은 spatial transformer와 비슷하다.
마찬가지로, query와 other modality의 key를 구하고, irrelevance map을 구하면 된다.
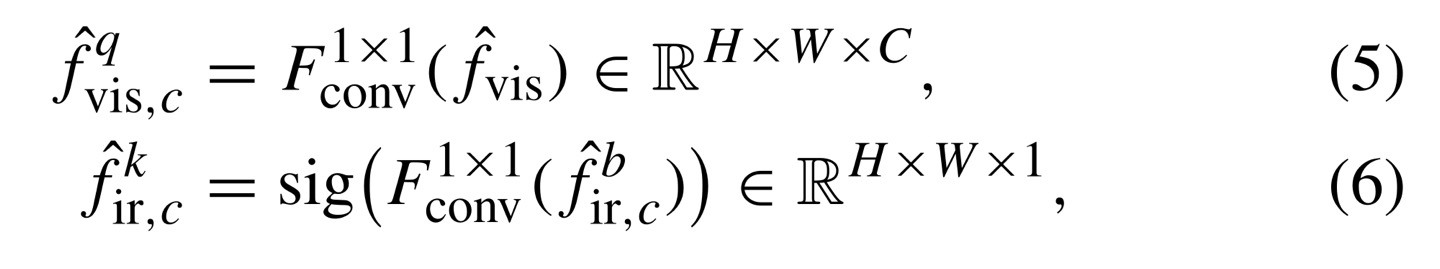
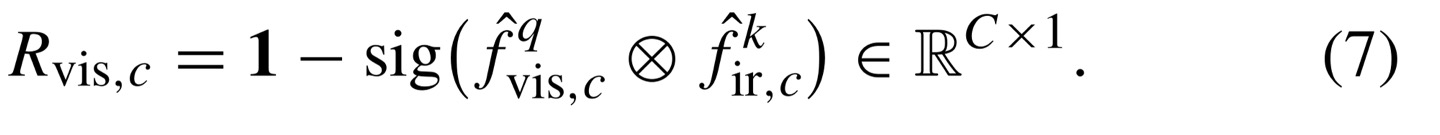
이후, RFDB의 output이자 channel transformer의 input인 와 를 channel-wise multiplication을 해준다. 각 의 channel마다 의 element값을 곱해주면 된다.
Gated Bottleneck
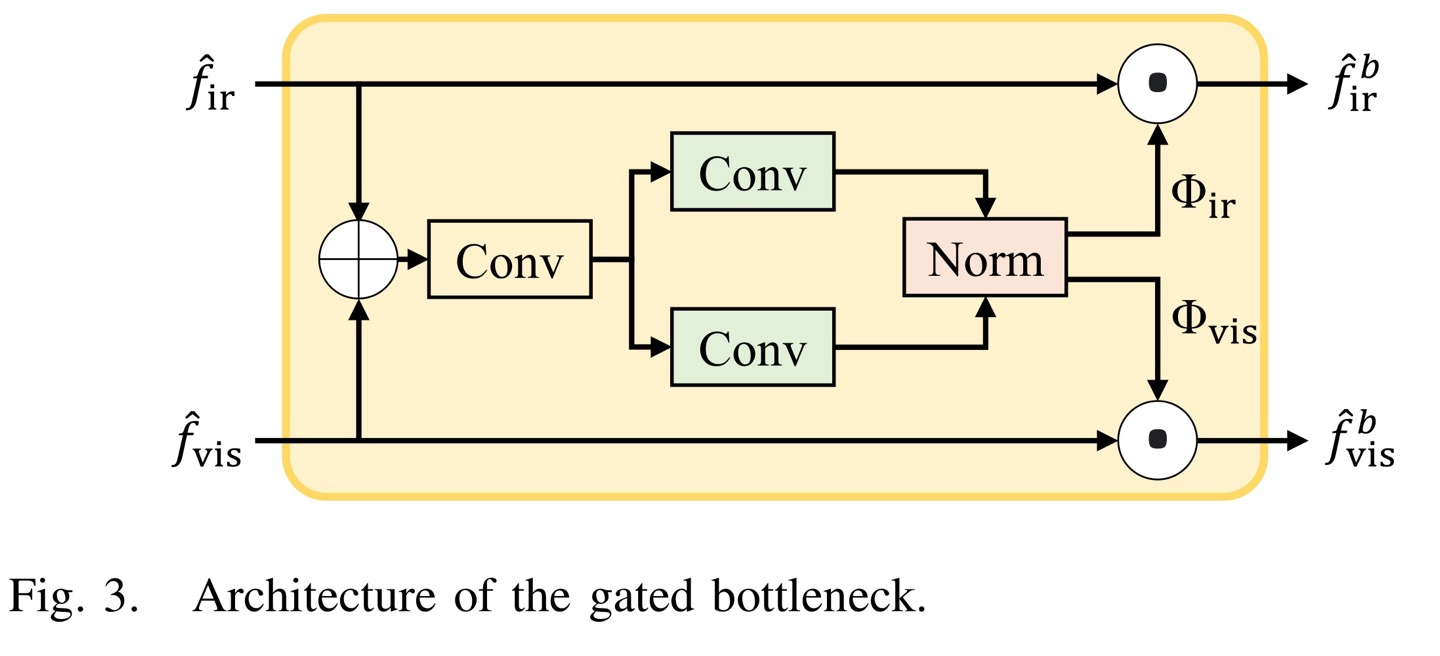
이 전에는 spatial domain에서만 global interaction을 했으니 1개의 feature map만 input값으로 사용했다고 한다. 그렇지만 source images끼리는 서로 다른 modality여도 redundant information이 존재한다고 앞에서 언급했다.
따라서 independent한 transformers들은 상호보완적인 information을 얻기란 힘들 것이다. (왜냐면 중복된 값이 있기 때문에, 불필요함 -> 이는 capability가 제한되어있기 때문)
그래서 spatial/channel transformer에서 redundant information을 구하기 위해 gated bottleneck을 사용한다고 한다.(key값을 구하기 전에 사용)
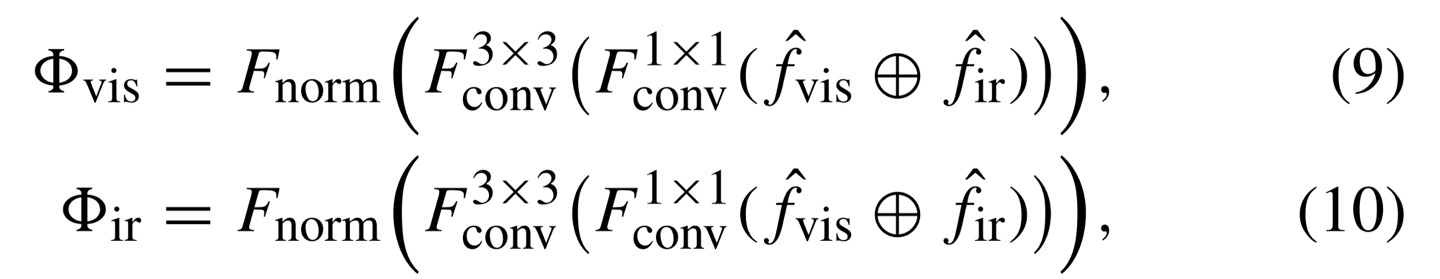
gated bottlneck은 source images마다 weights map을 만들어주는데, 이는 spatial/channel transformer의 input의 dimension과 같다. (즉, HxWxC면, 똑같이 weights map도 HxWxC)
따라서, visible weights map을 구하는 수식을 보면 와을 channel-dimension으로 concatenate한 다음, 1x1 convolution operation을 하게 된다. 이후 3x3 conv를 적용하고 을 해주는데 이는 noramlization function인데 feature map에서 같은 위치에 element값을 sum이 1로 되도록 해준다.
즉, A와 B를 feature map이라고 하고, 를 pixel location이라고 할 때 아래 수식으로 나타낼 수 있다.
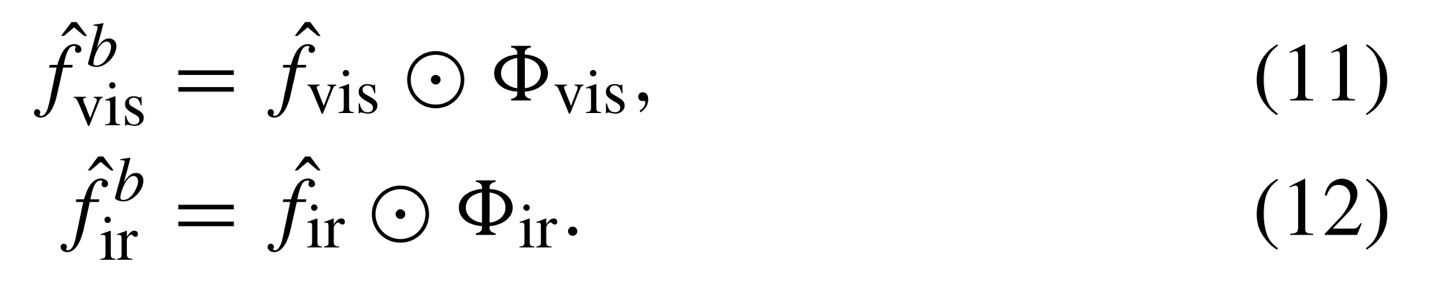
이후, redundant information을 제거하기 위해 input값에 weights map을 dot product해주면 된다.(dimension이 같으므로 dot product가능, 브로캐스팅 x)
Feature Refinement
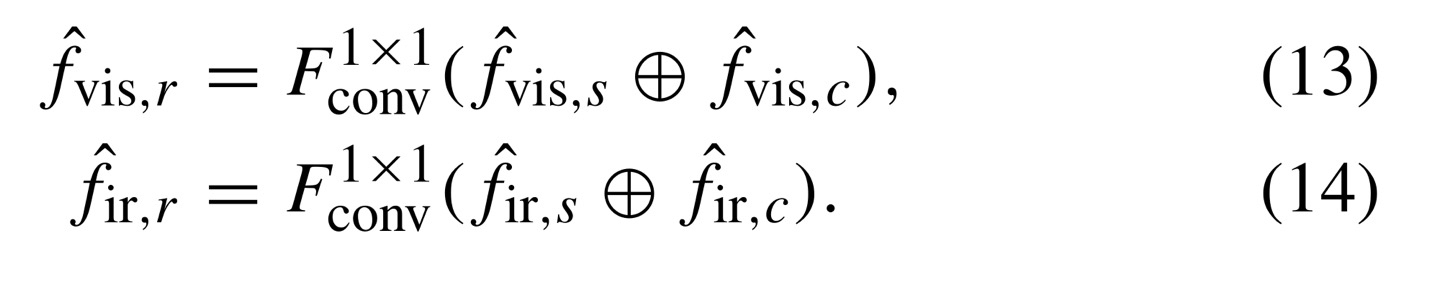
spatial/channel transformer의 output은 visible/infrared image끼리 독립적으로 추출된 값이다. 즉, visible에서는 와, infrared에서는 와이 output이다.
서로 다른 domain에서 추출된 값이니, 서로의 정보를 보완하기 위해 channel-dimension으로 concat하여 서로의 정보를 보완한 다음, 1x1 conv operation을 적용시켜주면 spatial/channel의 중요성을 반영하도록 돕게 된다.
Fusion Block
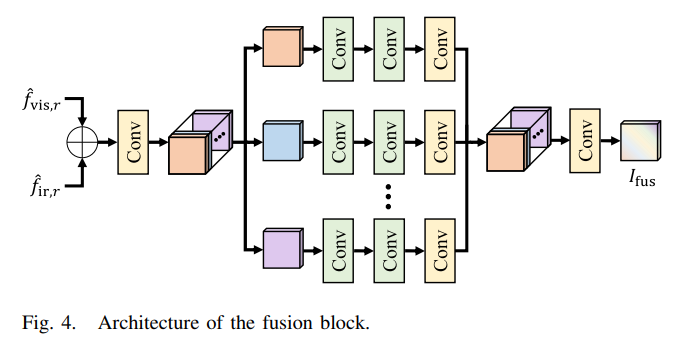
이제, 각 level마다 로 fusion된 image가 생성이 된다.
convolution, residual block과 같은 모든 block이 이러한 features를 fusion하는데 method가 될 수 있지만 straighforward한 fusion방식은 spatial, channel간의 interaction을 포착하는 것은 실패할 가능성이 높아 좋지 않은 fusion image가 생성이 될 것 이다.
그렇기 때문에 Fig.4.에 나와 있는 SFC(self-fusion convolution block)를 통해
각 level마다 fusion image를 생성한다고 한다.
SFC는 매우 적은 parameter의 개수로 high-level information을 다시 재구성할 수 있도록 하는 방법이라고 한다.
Loss Function
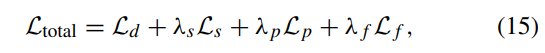
CMTFusion은 end-to-end로 train하며 data loss , spatial loss , perceptual loss , frequency loss 로 구성 된다.
각 loss값을 조절하기 위해 는 hyperparameter의 값으로 4개의 loss를 control한다.
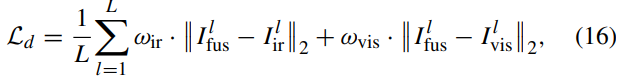
위의 수식은 MSE로 fused image , source images 를 의미한다. L은 pyramid level을 의미한다.
