Abstract
SPP-net의 핵심은 SPP(Spatial Pyramid Pooling)라고 한다. SPP는 다양한 img의 size를 input data로 넣을 수 있으며, SPP를 사용하기 전 다양한 img를 일정한 size로 fix하면 object detection의 accuracy가 떨어지기 쉽다고 한다.
SPP를 통해서 input img의 size에 관계없이 일정한 크기의 output을 반환하게 되는데, output이 size가 같아야하는 이유는 Fully connected layer이기 때문이라고 한다.
R-CNN에서는 2,000개의 후보영역을 Convolution연산을 했어야하는 반면, SPP를 적용하게 되면 한번의 Convolution연산을 할 수 있다는 장점이 있다고 한다.
Introduction
논문에서는 CNN을 사용하려면 고정된 size의 img를 필요로 한다고 했는데, 이때는 FC layer가 있기 때문에 이러한 말을 한 것 같다.
img를 고정된 size로 바꿀 수 있는 방법은 Crop과 Warping이 있다.

보시는거와 같이 Crop은 이미지의 특정한 영역을 window size로 잘라서 낸 img를 말하고, Warping은 가로/세로 비율이 달라져서 img가 찌그러져 보이게 되는데 비율이 달라지면 object detection의 성능이 떨어질 수 있다고 한다.
왜냐하면 실제의 object와 warping한 img의 가로,세로의 크기와는 다르기 때문이다. 이 때문에 예측한 Boundary-Box의 성능도 별로 좋지 않게 된다고 한다.
SPP는 위의 Crop과 Warping에 대한 문제를 해결해준다.
즉, CNN이 고정된 크기의 input img를 받아야 한다는 조건을 해결해주고 SPP가 Convolution연산이 끝나고 난 뒤의 output size를 고정시켜주는 역할을 하니, input image를 굳이 crop과 warping을 할 필요가 없는 것이다.

즉, 위의 이미지는 R-CNN과 SPP-net의 구조의 차이점을 말한 것인데 R-CNN은 warping을 진행하는 반면 SPP-net은 warping을 진행하지 않는다. 이러한 SPP방식은 굉장히 효율적이며 R-CNN대비 속도가 매우 빠르다는 장점이 있다.
SPP(Spatial Pyramid Pooling)
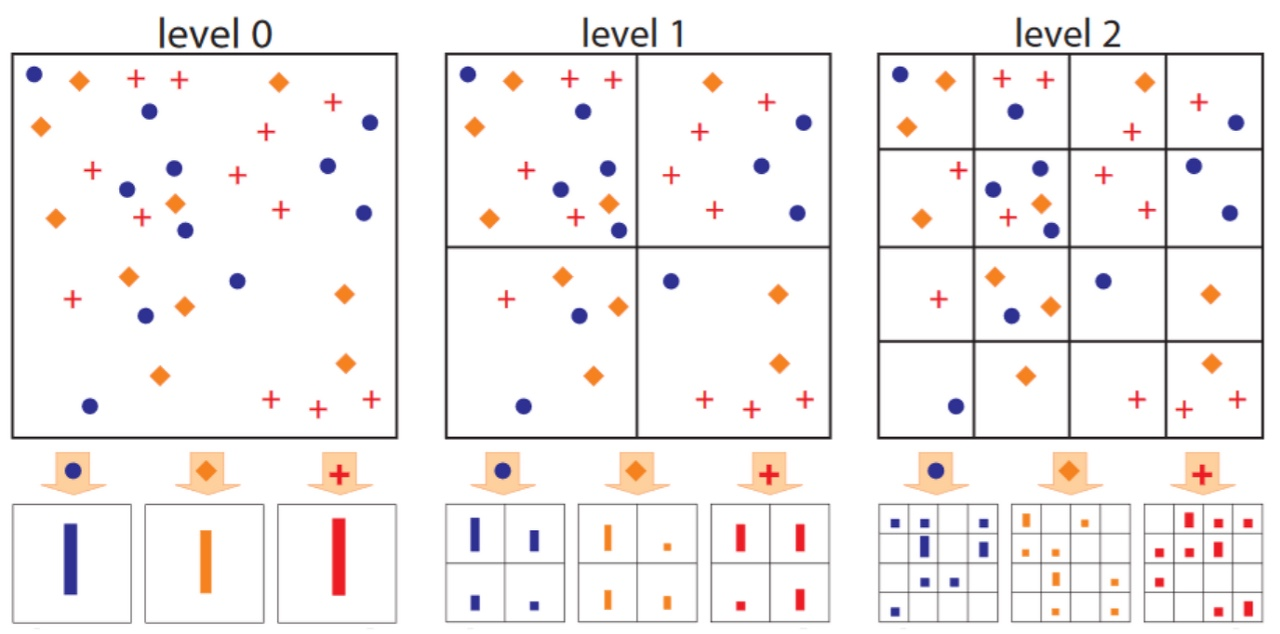
위는 SPP를 어떻게 사용하는지 도식화 해놓은 것으로, img를 여러 영역으로 나누고 난 뒤에, 각 영역별로 feature를 파악하는 방식이다.
계속 이야기하지만, SPP는 input img의 크기에 관계없이 고정된 size의 output을 출력하며, 다양한 level의 grid를 사용하는 multi-level spatial bins를 사용한다.
그니까, level0은 bins가 1개, level1은 bins가 4개, level2는 bins가 9개이다.(bins는 격자를 이야기함)
또한 SPP는 다양한 scale의 feature를 추출할 수 있게 되며, 앞서 말한 3가지의 장점으로 object detection의 성능이 올라간다고 한다.
SPP를 통해서 overfitting을 방지할 수 있게 되는데, 이는 feature map을 서로 다른 부분으로 나누어서 feature를 추출하기 때문에 특정 부분에 지나치게 의존하지 않고 parameter를 공유할 수 있기 때문이다.
또한 R-CNN에 비해 속도가 100배가 빠르다고 하며, 1개의 img를 처리하는데 0.5초가 걸린다고 하여 실시간 처리가 가능하다고 봐도 되는 수준이다.
Convolutional Layers and Feature Maps

(a)의 img들을 Conv연산을 통해서 feature map을 뽑은건데, 이때의 feature map은 5번째 Conv layer라고 한다.
filter들은 각각 다른 feature를 추출하기 때문에 (b)에서의 feature maps를 보게 되면 각각의 response강도가 다른 것을 볼 수 있다. filter #175는 자동차 창문쪽의 response강도가 높으며 filter #55는 자동차의 바퀴(원)의 response가 높다고 볼 수 있다.
이러한 CNN의 모델을 통해서 (c)에 object detection을 하게 되면 자동차의 창문(혹은 비슷한 모양), 자동차의 바퀴(혹은 비슷한 모양)들의 detect가 된 것을 볼 수 있다.(사실 detect가 된 것은 아니고 가장 강한 영역에 Boundary-box를 표시한 것이다.)
The Spatial Pyramid Pooling Layer
이제 SPP가 어떻게 진행되는지 알아봤으니, 구체적으로 더 살펴봐야겠다.
SPP를 통해서 고정된 input img의 size를 받지 않아도 되기는 하지만, output img의 size도 마찬가지로 동일하지 않은 feature map이 나올 것이다.(왜냐하면 input img의 size가 같지 않기 때문이다.)
SPP방식은 위에서 본 것처럼 local spatial bins(부분 공간 격자)를 통해서 Spatial information을 추출하게 되고, local spatial bins는 inpt img크기에 비례해서 커지게 된다.
bins의 개수만을 정하면 되는 것이고 이 bins의 크기는 input image에 맞춰 grid를 형성해줘야 된다는 것이다.(img가 크면 local spatial bins의 크기도 커지기 때문에 개수가 일정하게 된다.)
정리하자면, Convolution연산을 하고 난 뒤의 output img는 input img와 size가 비례하며 SPP는 local spatial bins 개수는 input img 크기에 따라 변하지 않게 된다. 따라서, SPP의 output은 input size의 관계없이 일정하다.
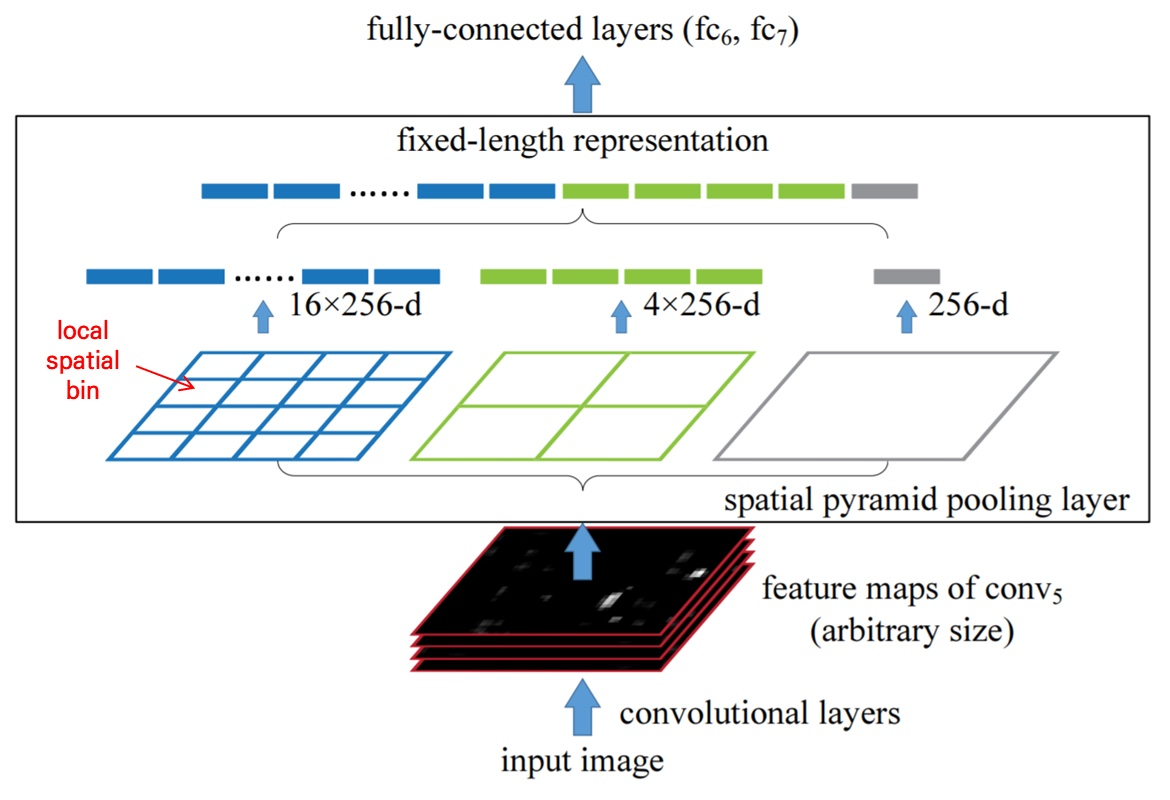
위는 Conv연산과 FC layer사이에 SPP가 있는 예시이며, 각각의 level에서는 16, 4, 1개의 bins가 있다는 것을 알 수 있다.
각 Spatial bin마다 response를 pooling하게 되는데, 이는 Max Pooling을 통해서 가장 중요한 정보를 추출한다고 한다.(Pooling을 적용한다는 말이 Max Pooling)
SPP의 결과 값은 k x M의 크기를 가지는 vector(1차원)이 되는데, M은 Spatial bins의 개수이며 K는 마지막 Conv layer의 filter 개수이다.
위의 구조를 계산하게 되면 K = 256, M = (16 + 4 + 1) = 21이 된다. 그러면 vector는 1 x 5376(K x M)의 값이 나오고 FC layer의 input Node의 개수는 5376개수로 고정된 값을 받게 되는 것이다.
bins는 level별로 설정할 수 있으며 hyperparameter로, 사용자가 지정할 수 있다.
읽어주셔서 감사합니다
