Abstract
CNN을 사용하기 전, 오랫동안 Vision분야에서는 SIFT와 HOG기반으로 발전하였지만, PASCAAL VOC 데이터셋에서 object detection에서의 성능은 크게 높아지지 않았다고 한다. 단지 기존 모델을 약간 바꾸거나 결합해서 미미한 성능 향상을 보였다고 한다.
R-CNN은 Region prposal과 CNN을 사용하여 mAP(mean Average Precision을 30%이상 올렸다고 한다.
여기서 말하는 mAP에 대해서 알아보자 mAP에 대한 자세한 설명 더 자세히 알아보고 싶은 분은 링크를 들어가길 바란다.
AP는 img내에서 1개의 object에 대한 성능 지표이고, mAP는 img내의 모든 object에 대한 성능 지표이다. 여기서 말하는 object란 class를 의미한다.
object detection 알고리즘의 성능을 결정하는 평가지표가 mAP이며 구하는 방식은, 각 class당 AP를 구한 다음, class의 개수로 나누어주면 된다.
R-CNN에서 말하는 핵심은 2가지라고 한다.
-
Boundary-box를 위한 Region proposal에 CNN을 적용했다고 한다.
-
Pre-training과 fine-tuning을 적용해서 train data가 적은 상황에서 성능을 올렸다고 한다.
첫번째에서 말한 알고리즘으로 Region proposal + CNN의 결합으로 R-CNN이라고 한다.
Introduction
PASCAL VOC datset
PASCAL VOC dataset은 object detection이나 segmentation 성능 평가를 위해서 주로 사용하는 데이터이며 20개의 class가 있다고 한다.
이 dataset은 Annotation정보가 담겨있으며, object label, Boundary-box의 meta 정보가 포함되어 있다.
2-stage의 hierarchical model이다.
R-CNN은 2-stage의 모델이며, 첫번째 단계에서는 img내에서 object classifier를 하고 두번째 단계에서는 Boundary-box를 추정하는데 이는 regression을 이용한다.
classification과 regression이 같이 있는 모델로 생각하면 된다. 뒤에서 다시 자세히 다루겠지만, regression은 실제 Boundary-box에 더 정확하게 matching이 되기 위해서 Region proposal한 Box에서의 regression을 진행한다고 보면 된다.
R-CNN에서 해결해야하는 문제는 다음과 같다.
-
CNN으로 Object Localization하는 문제
-
Annotation된 data가 부족한 상태에서 model 학습해야하는 문제
이 문제에 대해 상세히 알아보자.
Object Localization
Localization이란, object의 위치를 찾는 것이라고 생각하면 된다.
이 localization을 해결하기 위한 방법을 3가지로 접근하였다고 한다.
첫번째 방법은 Localization을 regression문제라고 놓고 문제를 해결하려 했으니, 실효성이 떨어진다고 한다.
두번째 방법은 R-CNN이 나오기 전 Sliding Window 방식으로 해결하려 했으나, Computation 비용이 높으며, 다양한 크기와 비율의 객체에 대응하기 어려워 정확한 localization이 어렵다고 한다.
세번째 방법은 Region Proposal인데, R-CNN에서 제안하는 새로운 접근 방식이다.
Region Proposal의 procedure은 다음과 같다.
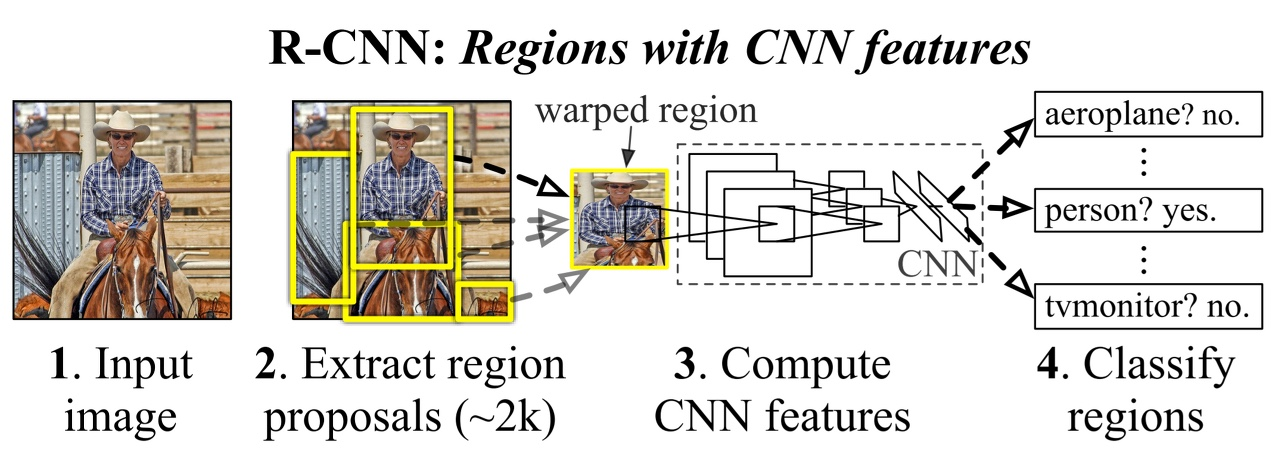
- Input Image
- 2000개의 후보 영역을 제안한다.
- 후보 영역의 size를 고정된 size로 만든다. 이는, AlexNet의 FC layer로 인해서 그렇다.
왜냐면, FC layer로 갈 때 고정된 Node의 개수만을 받기 때문이다. - CNN을 이용하여(AlexNet Model) Region Proposal 후보에서 feature를 연산한다.
- FC Layer의 마지막 output node(4096개)를 feature라고 간주하고 SVM을 통해서 Classification 작업을 수행한다.
그리고 앞선, Annotation된 data가 부족한 상태에서 model 학습해야하는 문제는 ImageNet으로 AlexNet을 pre-training하고, 적은 수의 PASCAL 데이터로 원하는 domain에 맞게 fine-tuning을 하였다고 한다.
이를 통해 mAP를 8% 향상을 이끌었다고 한다.
Object Detection with R-CNN
앞에서 이야기 했던 내용을 더 자세히 다루는 part이다.
Region Proposals
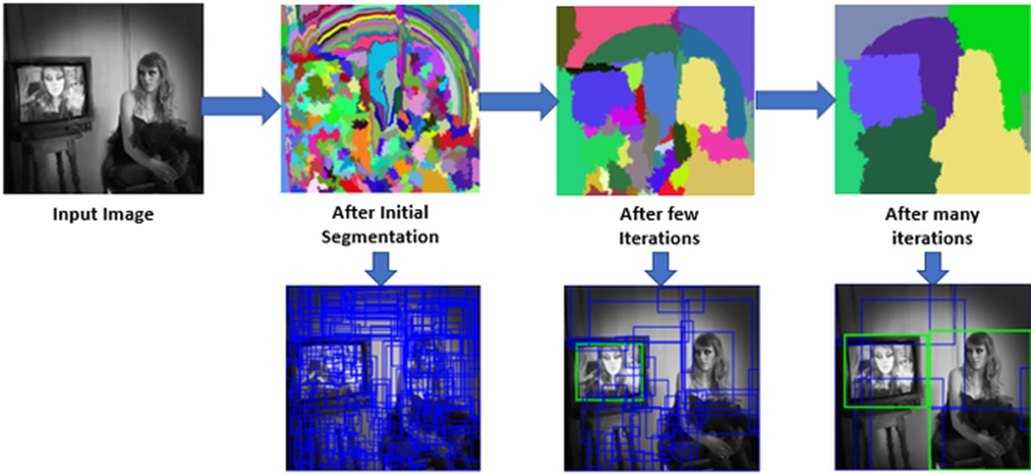
Selective Search을 통하여 Region Proposal 기법을 사용하는데 이는 segmentation기법을 활용한다.
이에 대한 내용도 Selective Search에 자세히 적어놓았다.
Feature Extractor
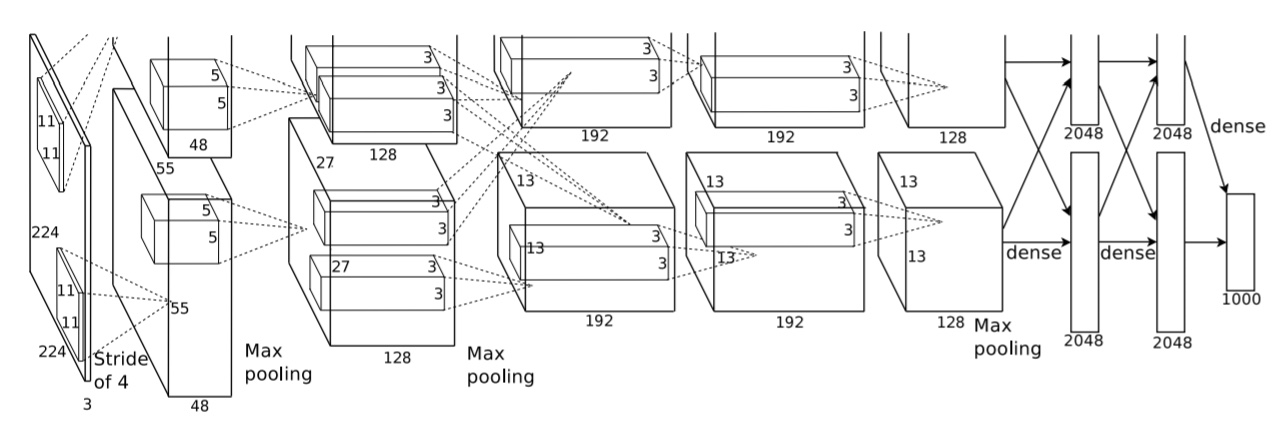
후보로 선정된 영역에는 CNN연산을 통해 4096개의 feature들을 추출하게 되는데, 이는 AlexNet의 모델을 사용하게 된다. 위의 img는 AlexNet의 모델의 architecture이다.
AlexNet은 1000개의 class를 classification하게 되는데 우리는 feature를 4096개를 추출한다고 했으니 output layer를 없앤 model이 되겠다.
위에서 224 x 224의 img를 받는다고 했는데, 이는 논문에서의 오류로 227 x 227로 img를 고정시켰다고 한다. 이렇게 img를 고정시키는 것에 대한 용어를 Warping 이라고 한다.
개인적인 생각으로 PASCAL dataset은 img의 크기가 random이기는 하지만, object에 대한 영역을 후보로 추출하니 227 x 227로 추출할 때 이미지를 확대하는 것으로 볼 수 있을 것 같다. 물론 아닌 경우도 있을 것 이다.
하지만, warping을 하기전에 후보 영역 주변 배경을 16pixel만큼 주변 배경을 포함했다고 한다.
위 내용을 정리하자면, selective search를 하고 난 뒤의 후보 영역의 주변을 16pixel만큼 포함하고 warping을 했다는 이야기이다.
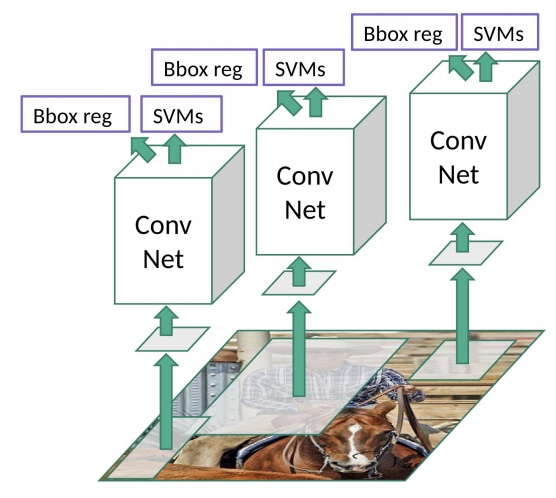
R-CNN의 대략적인 구조는 위와 같다고 한다.. SVM으로 classification하고, 그 후보 영역 즉, Boundary-Box를 더 정확히 예측하기 위해서 Boundary-box를 regression하는 것이다. 이를 2-stage,,
Test-time detection
Test 단계에서도 train과 마찬가지로 수행하는데, SVM으로 각 class별 score를 계산하고 score에 따라 NMS를 수행하는데 이도 마찬가지로 각 class별로 수행한다.
NMS(Non Max Suppresion)
NMS란, object detection의 알고리즘은 object가 있을만한 Boundary-box를 수행하는 경향이 가아핟고 하며 이 때문에 여러 개의 Boundary-box가 있다고 한다.
그렇기 때문에, 가장 적합한 Boundary-box가 필요한데 이를 NMS를 사용한다.
NMS의 Procedure은 다음과 같다.
- Boundary-box에서 특정 threshold 이하 Boundary-box는 제거한다.
- 가장 높은 score(IOU 값)을 가진 순(내림차순)으로 sorting한다.
- 높은 score(IOU 값)을 가진 Boundary-box와 그 이하의 score를 가지는 Boundary-box를 모두 조사하여 IOU가 특정 threshold값 이상인 Boundary-box는 모두 제거한다.
만약, threshold값을 너무 작게 설정하게 된다면, 다른 object를 detection한 Boundary-box를 제거할 수 도 있기 때문에, 최적의 threshold값을 최적화 시켜야 한다.
threshold값은 0.5로 설정하였고 0.5이상은 positive, 0.5미만은 negative으로 배경이라고 인식한다고 한다.
Training
AlexNet이 ImageNet으로만 train하였기 때문에 Img classication 수준의 pre-train을 하였고 object detection에 맞게 fine-tuning을 진행하였는데, 이는 PASCAL dataset에서 warping한 후보 영역 img만을 활용하여 CNN parameter를 갱신하였다고 한다.
그러면 ImageNet을 사용하였으니, 1000개의 output에서 N + 1의 output을 구성하였는데 N은 PASCAL dataset에서의 class의 수, 나머지 1은 배경이라고 한다.
PASCAL dataset의 class는 20으로, N이 20이 되겠다.
Bounding-box Regression
Bounding-box Regression은 localization error를 줄이는 방법으로 Bounding-box 위치 선정을 교정하고 모델의 성능을 높이기 위한 과정이다.
수학적 수식으로 설명해보겠다.
우리의 목표는 predicted-box(후보 영역)가 input으로 들어왔을때 이를 이동시켜 G로 잘 예측하는 것이다. 그러니까 P에서 G로 transform하는 것이다.
는 들을 G와 유사하게 이동시켜 주는 함수들인 d를 학습시켜야 하는데 로 보며 W(weight)를 학습시킨다고 보면 된다. 는 CNN layer에서 5layer에서 구한 feature vector로 보면 된다.(필자는 θ_5(p)를 1개로 봤음)
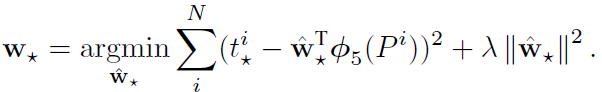
위는 Loss function에 대한 식이며, t는 label이고 L2 LOSS를 사용했다는 것을 알 수 있다.
따라서 위의 Loss에 대한 식을 통해 update된 weight를 학습시키게 된다.
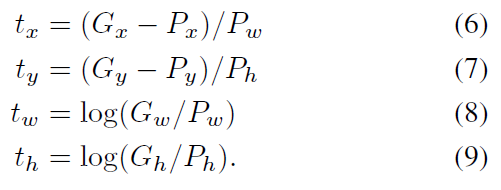
t에 대한 식은 위와 같다.
위의 가중치를 update했다면 P에서 새로운 P인 을 구하였을텐데, 이는 다음과 같다.
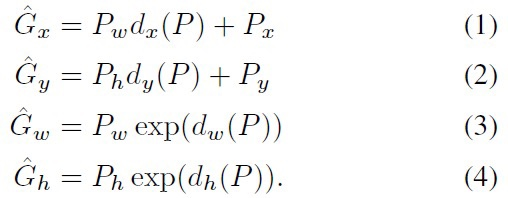
읽어주셔서 감사합니다.
할게 너무 많아서,, 이번에는 코드 구현을 하지 않았습니다~~!!!!!!!
