Deep Learning 개요
- 딥러닝은 머신러닝의 한 기법으로 학습 과정 동안 인공 신경망으로서 예시 데이터(Input)에서 얻은 일반적인 규칙을 독립적으로 구축(훈련)합니다.
- 딥러닝은 학습 데이터를 통해 훈련을 하게 되고 학습된 데이터에 따라 다른 제공된 데이터를 추론 하게 됩니다.
퍼셉트론(Perceptron)
- 퍼셉트론은 실제 뇌를 구성하는 신경 세포 뉴런을 착안하여 만든 모델입니다.
- 최초의 ANN(Artificial Neural Network)입니다.
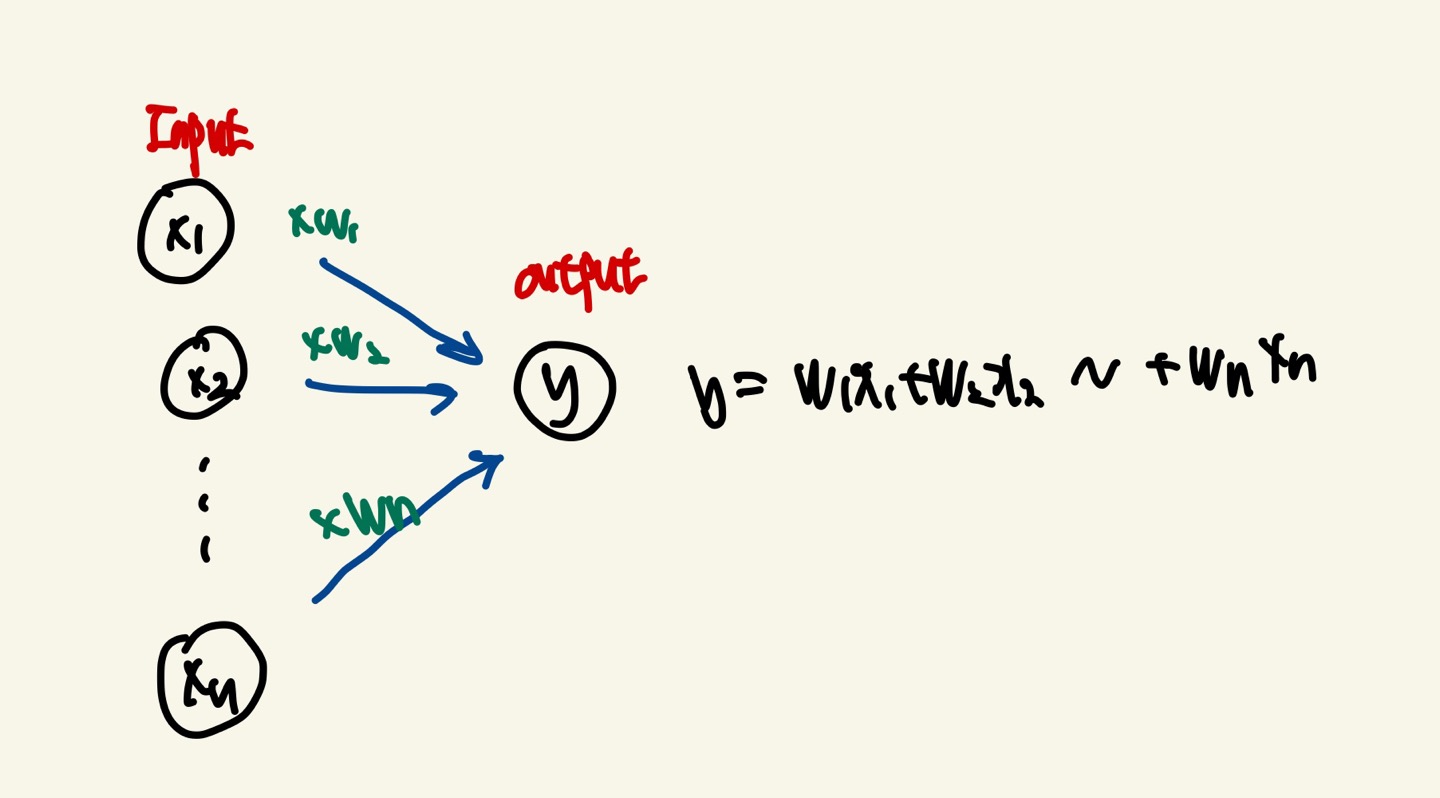
- 여러개의 입력신호를 받아서 1개의 출력신호를 출력합니다.
- 가장 단순한 ANN이면서 Hidden Layer가 없이 Single Layer로 구성되어 있습니다. 입력 피처들과 가중치,Activaion,출력 값으로 구성되어 있습니다.
weighted Sum : 입력feature들의 개별 값과 이 개별 feature에 얼마만큼의 가중치를 주어야 하는가를 결정하는 가중치 값을 각각 곱하고 최종으로 더해서 나온 값 입니다.
x: Input(입력신호) : X1~Xn 값
y : output(출력값) : 0 or 1만을 출력합니다. 0은 False, 1은 True
w : weight(가중치) : 각각의 입력신호들이 전체에서 가지는 중요성을 높이기 위해서 일정한 수치를 곱한 값입니다.
퍼셉트론의 동작원리는 y = W1X1+W2X2 + ~ + Wn*Xn가 우리가 설정한 임계값(θ)을 넘으면 출력값이 1(True) 넘지 못하면 0(False)를 출력하게 됩니다.
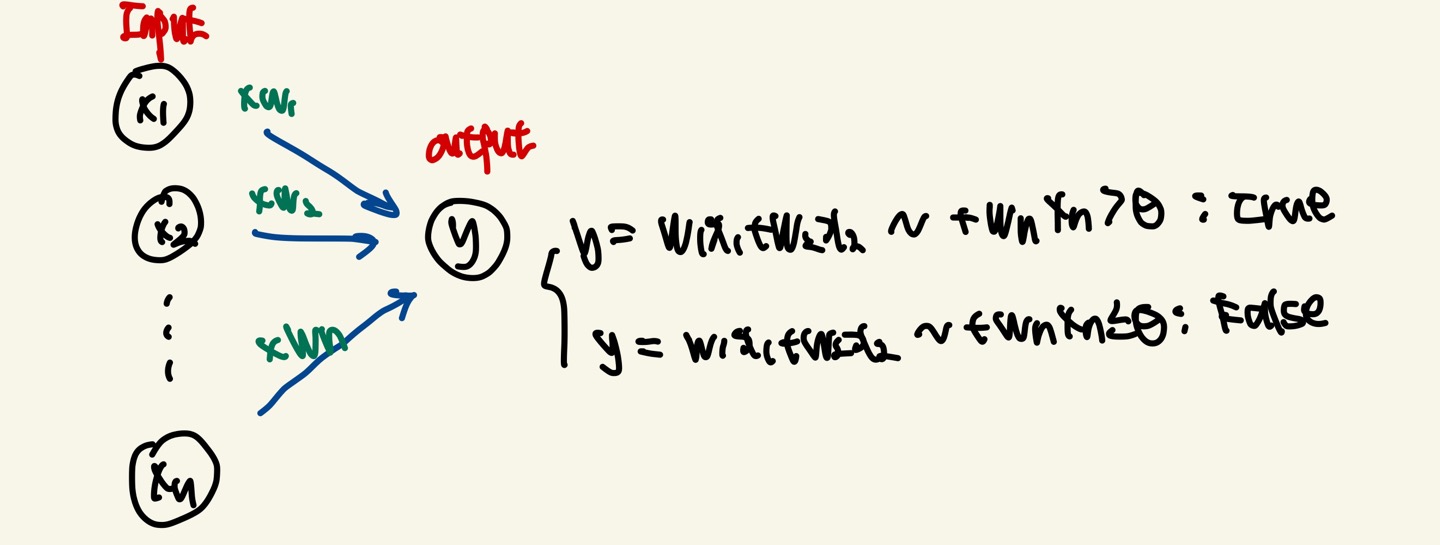
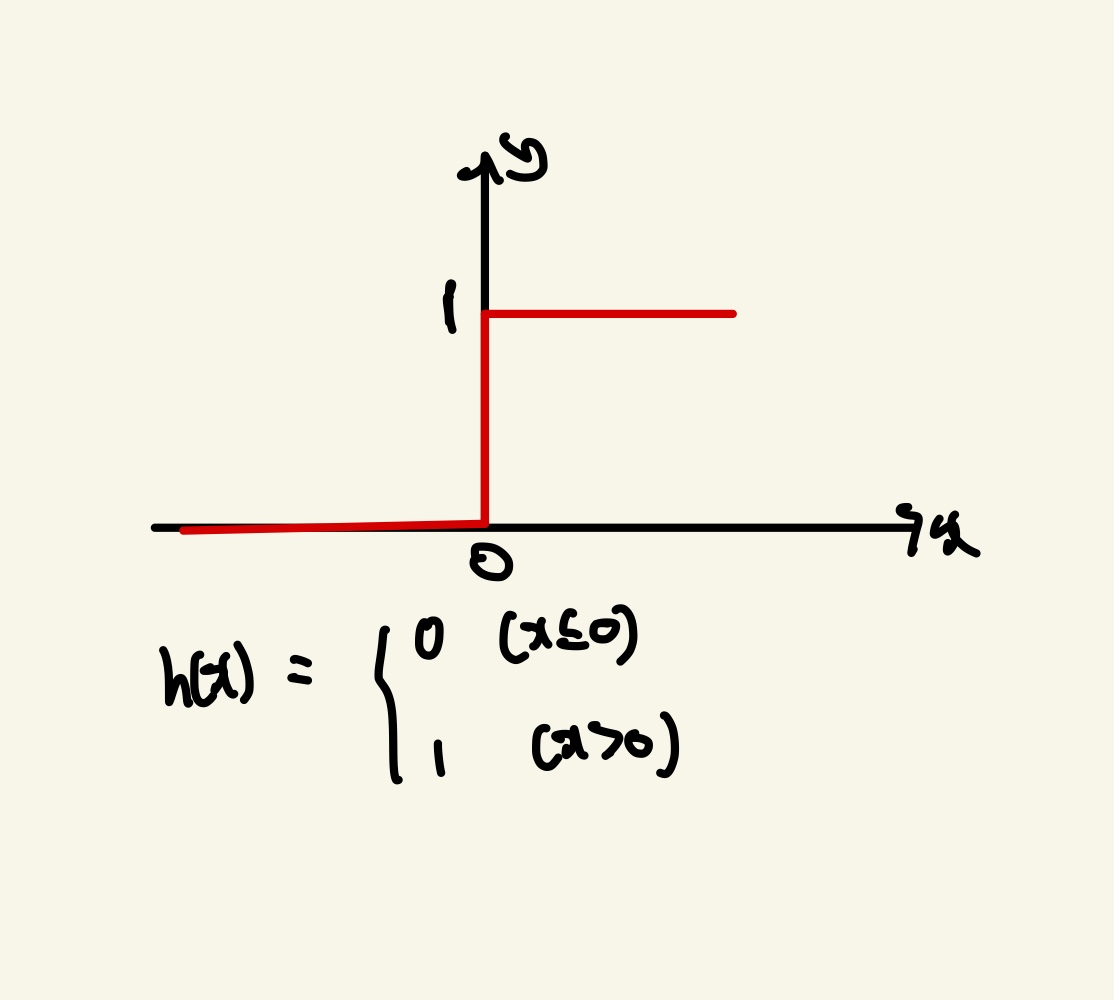
덧붙여서 말하면 Perceptron의 Activation Function은 Step Function을 사용합니다.
Step Function은 계단함수로 다음과 같은 그래프를 가집니다.
계단함수는 입력값(X)가 0보다 크다면 1(True)값을 출력하고 작다면 0(False)값을 출력합니다.
Activaion Function은 다음 포스팅때 더욱 자세히 말씀드리겠습니다.
퍼셉트론 동작원리의 그림을 보면 y의 값이 임계값(θ)에 관한 식이 있다.
여기서 θ를 -b로 치환하고 y에 대한 식으로 넘겨주면 다음과 같은 식이 나옵니다.
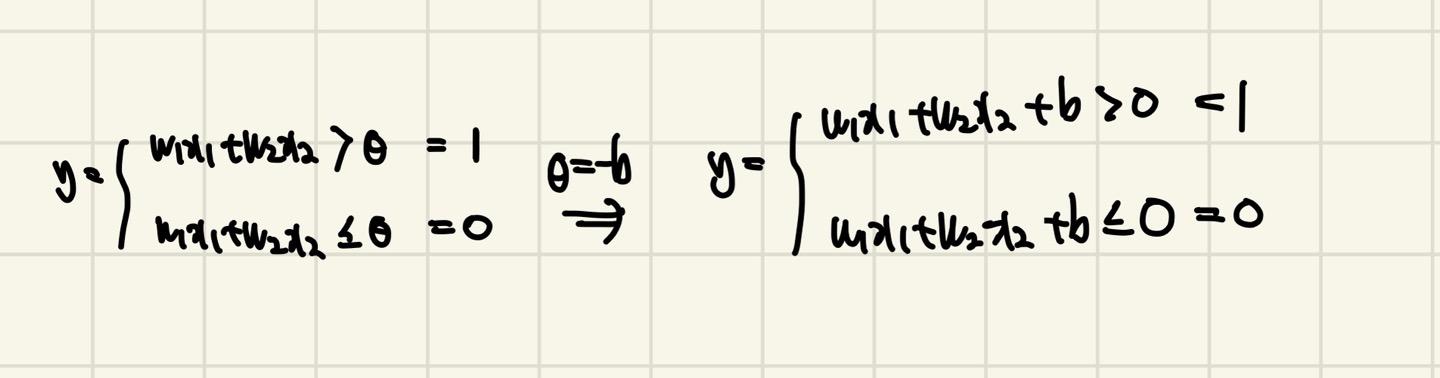
이때 b를 우리는 편향(Bias)라고 부르기 시작하고 b는 결국 임계값(θ)입니다.
b : bias(편향) : 뉴런이 얼마나 쉽게 활성화 되느냐를 제어하는 역할을 하게 됩니다.
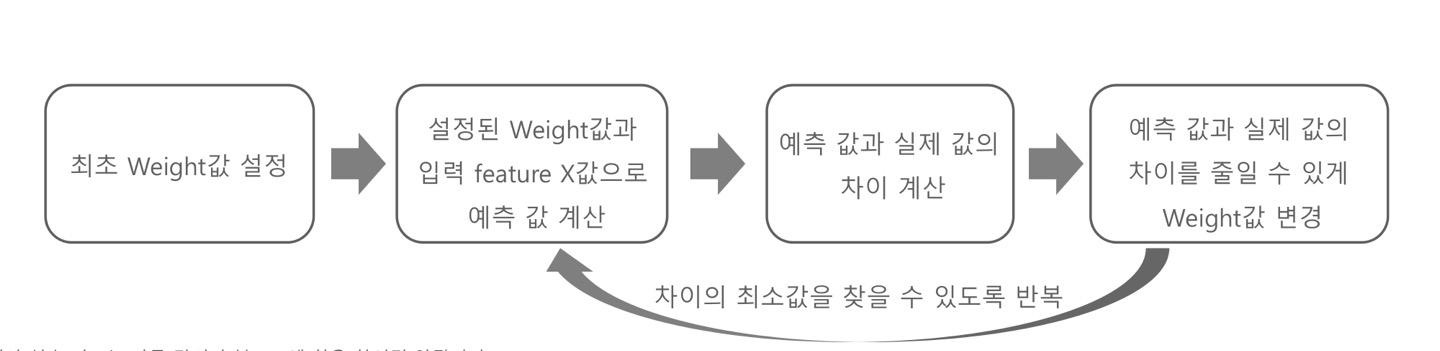
퍼셉트론(Perceptron)의 학습
퍼셉트론의 학습의 출력값은 실제값이 아닌 예측값을 도출합니다.
신경망은 예측값과 실제값의 차이를 줄이는것을 목표로 합니다. 차이를 줄이기 위해서는 최적의 weight를 찾아야합니다.
X(Input feature)들은 우리가 입력한 Constant Value이고 W(weight)는 Parameter이기 때문에 W를 학습하게 됩니다.
W는 예측값과 오차값을 줄이는 방향으로 W가 학습하게 됩니다. 이러한 방법은 Gradient Descnet가 있습니다.
Gradient Descent는 다음 포스팅때 더욱 자세히 말씀드리겠습니다