
Intro
레거시(Legacy)를 무시하지 말자.
요즘엔 Spring Framework의 확장 버전인 Spring Boot가 대중적으로 많이 쓰인다. 나 또한 이전까지 보다 빠르게 애플리케이션을 개발할 수 있고, 각종 설정들을 자동화할 수 있는 Spring Boot를 사용하고 있었고, Spring Boot로만 개발해야 한다는 생각이 있었다. 그런데 이는 크나큰 오산이었다.
교육과정을 통해 Spring Framework의 전반적인 생태계를 배우고 알게되면서 Spring Legacy에 대해선 기피하고 무시하며, Spring Boot만을 고집했던 내가 부끄러워졌다.
Spring Boot의 설정 자동화라는 이점이 설정을 고쳐 사용해야 하는 시스템의 경우라면 오히려 독이 될수도 있다. Spring Legacy를 통해 원하는 설정들을 커스텀하여 사용하는게 더 나을 수도 있다.
Legacy와 Boot 중에서 무엇이 좋고 무엇을 사용해야 좋다 라는 기준을 통해 개발환경을 결정하는 것이 아니라, Legacy와 Boot 중에서 내가 개발해야할 애플리케이션이나 프로그램의 구조, 즉 아키텍쳐 설계를 이용하려면 어떤 것이 더 나은지를 고민하고 결정했어야 했다.
앞으로 스프링 프레임워크를 배우며 다루는 교육기간 동안 Spring Boot를 당연히 더 많이 쓰겠지만, Spring Legacy의 구조에 대해서도 이해하고, Legacy System과 연동하는 과정은 어떻게 이루어지는지 숙지할 것이다.
Day - 45
Factory Method Pattern(팩토리 메소드 패턴)에 관하여
이전 회고록에서 템플릿 메소드 패턴을 알아보았다. 템플릿 메소드 패턴과 함께 거론되는 팩토리 메소드 패턴에 대해서도 배웠지만, 복습 차원에서 다시 한번 정리하며 기록하려 한다.
팩토리 메소드 패턴(Factory Method Pattern)이란?
하위클래스에서 객체의 생성여부를 결정하게 하는 것인데, 구체적으로는 객체를 생성하는 과정을 별도의 클래스로 분리해 캡슐화시키는 것이다.
- Factory를 문자 그대로 직역하면 무언가(객체)를 생산 해낸다는 뜻으로 통용된다.
팩토리 메소드 패턴을 쓰는 이유는?
팩토리 메소드 패턴의 큰 강점은 바로 상위클래스에서 하위클래스를 생성하는 것을 숨길 수 있으며, 하위클래스에서 어떤 객체를 생성할 지를 결정짓게 할 수도 있다. 이로 인해 객체를 생성하는 코드의 중복을 제거할 수 있으며, 객체를 생성하는 로직과 객체를 사용하는 로직간의 결합도와 의존성을 낮출 수 있다.
사용자의 상,하,좌,우의 움직임을 입력받는 예제
말로 하는 것보다, 코드로 이해하는 것이 더 이해하기 쉬울 것 같다. 사용자가 Move라는 객체를 통해 상,하,좌,우로 움직일 때 팩토리 메소드 패턴을 적용시켜보려 한다.
작성한 코드들을 살펴보자.
Move.java
public interface Move {
public void move();
}Up.java
public class Up implements Move{
@Override
public void move() {
System.out.println("move() method - Up");
}
}Down.java
public class Down implements Move{
@Override
public void move() {
System.out.println("move() method - Down");
}
}Left.java
public class Left implements Move{
@Override
public void move() {
System.out.println("move() method - Left");
}
}Right.java
public class Right implements Move{
@Override
public void move() {
System.out.println("move() method - Right");
}
}Move라는 인터페이스를 생성하고 move라는 추상 메서드를 선언하였다. 이를 Up, Down, Left, Right 클래스에서 구현하도록 작성하였다.
여기까지만 보면 팩토리 메소드 패턴과 별 관련이 없어보인다. 다시 한번 말하지만 팩토리 메소드 패턴은 하위클래스에서 객체의 생성방법을 결정하게 하는 것이다. Factory 클래스를 하나 만들어서 객체의 결정권을 적용한다.
public class MoveFactory {
public Move getMove(String command) {
if (command.equals("UP")) {
return new Up();
} else if (command.equals("DOWN")) {
return new Down();
} else if (command.equals("LEFT")) {
return new Left();
} else if (command.equals("RIGHT")) {
return new Right();
}
return null;
}
}MoveFactory 클래스는 팩토리 클래스로써 핵심 기능을 담당한다. getMove라는 팩토리 메소드를 두고 주어지는 command마다 Up, Down, Left, Right 객체들을 생성하여 반환하도록 하였다.
public class MoveMain {
public static void main(String[] args) {
MoveFactory moveFactory = new MoveFactory();
// Up Method
Move cmdUp = moveFactory.getMove("UP");
cmdUp.move();
// Down Method
Move cmdDown = moveFactory.getMove("DOWN");
cmdDown.move();
// Left Method
Move cmdLeft = moveFactory.getMove("LEFT");
cmdLeft.move();
// Right Method
Move cmdRight = moveFactory.getMove("RIGHT");
cmdRight.move();
}
}이제 위에서 만든 MoveFactory 클래스에서 객체를 생성 후 반환하는지 main 메서드에서 확인해보자.
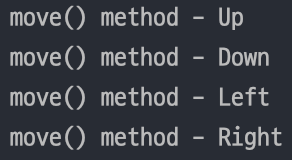
위와 같이 Up, Down, Left, Right 객체들의 생성을 온전히 팩토리 클래스(MoveFactory)가 담당하게 됨을 확인할 수 있다.
또한, 이로 인해 클라이언트 코드(main method)를 변경할 필요없이, 팩토리 클래스(MoveFactory)만 관리하면 되기에 객체 생성에 대한 확장을 구성하는데 좀 더 수월해졌다고 생각이 들었다.
Spring Bean이란?
스프링 빈(Bean)이라고 하면, 스프링 IoC 컨테이너(Spring IoC Container, Spring Container)가 관리하는 자바 객체를 말한다.
Spring IoC Container란?
스프링 컨테이너는 스프링의 빈(Bean)을 생성하고 관리하는 곳이다. 인스턴스를 생성하고 소멸하기까지의 전반적인 인스턴스의 생명주기 관리를 대신 해준다. 객체들을 관리하는 주체가 프레임워크(Container)가 되기 때문에 개발자는 비즈니스 로직에 집중할 수 있게 된다.
프레임워크 없이 Java로 개발할 때는 객체를 생성하고, 생성한 객체를 초기화하고, 메소드를 호출하거나 소멸하는 등의 객체를 제어하는 작업들을 개발자가 직접 관리하였다.
하지만 Spring같은 프레임워크를 사용한다면 이야기가 달라진다. 그것은 바로 객체의 생명 주기와 관련된 작업들을 프레임워크에 위임할 수 있다는 것이다.
이와 같이 객체의 제어권을 개발자가 아닌 프레임워크 같은 다른 주체에게 위임하는 원칙을 IoC(Inversion Of Control), 직역하여 제어의 역전이라고 한다. IoC에 대해서는 다른 챕터나 목차에서 다뤄보려 하니 여기서는 간단하게 무엇인지 정도만 알고 넘어가자.
내가 사용해왔던 Java Programming 에서는 클래스를 생성하고 new를 통해 객체의 인스턴스를 직접 만들어 사용했었다. 하지만 Spring에서는 직접 new를 통해 생성된 객체를 사용하는 것이 아니라, Spring Container에 의하여 관리되는 객체를 사용하는 것이다. 그래서 Spring Container에서 관리하는 자바 객체를 스프링의 빈(Bean)으로 등록하여 사용할 수 있는 것이다.
그렇다면 스프링 빈은 어떻게 등록할까?
앞에서 스프링 빈이 무엇이고 왜 사용하는지 간단하게 알아봤으니 이제 어떻게 사용하는 것인지 알아보자.
컴포넌트 스캔(Component-scan)으로 빈 등록하기
컴포넌트 스캔은 @Component 어노테이션을 클래스나 인터페이스의 위에 명시한다면 스프링이 자동으로 해당 객체의 빈을 스프링 컨테이너에 등록해준다.
왜 클래스나 인터페이스에만
@Component어노테이션을 붙일 수 있을까?
@Component어노테이션의 내부를 살펴보니 아래와 같이 Element.Type이 설정되어 있었다. 그래서 클래스와 인터페이스에서만 사용할 수 있음을 알 수 있었다.
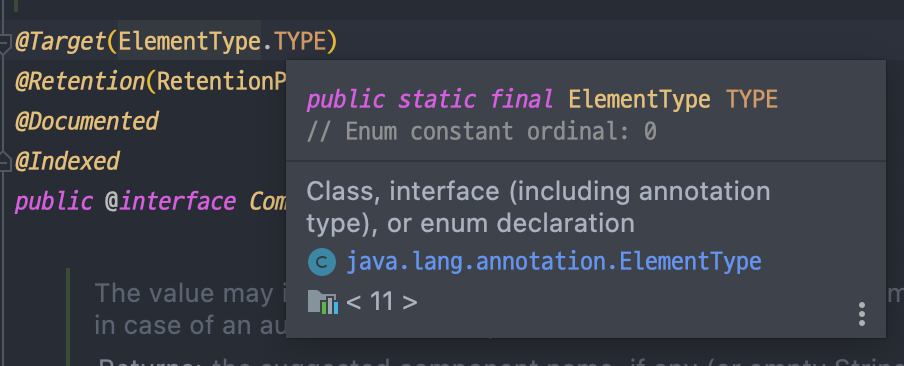
또한 @Controller, @Repository, @Service, @Configuration 같은 어노테이션들은 @Component 어노테이션을 상속받고 있기에 컴포넌트 스캔이 되어 동일하게 빈을 등록할 수가 있다.
Configutation을 통해 빈 등록하기
Java 코드를 통해서도 빈을 등록할 수 있다. 바로 @Configuration 어노테이션을 사용하여 직접 @Bean 어노테이션 붙여 빈을 등록해주는 것이다.
@Configuration
public class AppConfig {
@Bean
public MemberController memberController() {
return new MemberController;
}
}위와 같이 @Bean 어노테이션을 명시하면 @Component 어노테이션을 붙이지 않아도 스프링에서 자동으로 MemberController의 빈을 등록해준다.

자세히 살펴보면 해당 방법도 컴포넌트 스캔으로 빈을 등록하는 원리와 비슷하다. 일단 @Configuration 어노테이션의 경우 내부 코드를 보면 @Component 어노테이션을 사용하기 때문에 결국 컴포넌트 스캔의 범위가 된다. 그래서 @Configuration 어노테이션을 통해 안에서 직접 정의한 빈들이 스프링 컨테이너에 등록된다.
스프링 빈의 범위(스코프, Scope)는?
스프링 빈 스코프란 빈이 존재하는 범위를 뜻하는데, 스프링은 기본적으로 모든 빈을 싱글톤(Singleton)으로 생성하고 관리하게 된다. 싱글톤 빈은 스프링 컨테이너에 한 번 등록되면 이 컨테이너가 종료될 때까지 소멸되지 않는다.
그렇게 객체를 통해 생성된 인스턴스는 Single Beans Cache에 저장된다. 이후 해당 빈에 접근해야할 경우 미리 캐시된 객체를 반환해준다. 결국 인스턴스는 최초 하나만 생성되기 때문에 이후에도 해당 인스턴스를 사용할 때 같은, 즉 동일한 인스턴스를 참조하게 된다.
스프링 빈에 대한 내용을 간단하게 정리한다면 서버 애플리케이션을 실행했을 때, JVM 안에서 스프링이 각각의 빈마다 객체를 하나씩 생성해준다. 그래서 스프링을 통해서 빈을 주입 받으면 언제나 주입받은 빈은 동일한 객체라는 생각을 항상 유의하여 개발에 임해야 한다는 생각을 하게 되었다.
Day - 46
컴포넌트 스캔(Component-scan)
컴포넌트 스캔(Component-scan)은 스프링이 스프링 빈(Spring Bean)으로 등록할 클래스들을 스캔하여, 빈으로 등록해주는 과정이다. 클래스들이 스프링 빈으로 등록되려면 등록할 준비가 되어야 한다. 어떤 준비가 되어야 할까?
컴포넌트 스캔 과정에서는 @Component 어노테이션이 작성된 클래스들은 전부 컴포넌트 스캔의 대상이 되는데, 개발자가 직접 @Controller, @Service, @Component, @Repository, @Configuration와 같은 어노테이션을 해당 클래스에 작성하여 준비를 해야한다.
컴포넌트 스캔은 @Component 어노테이션을 빈 등록 대상으로 바라보는데, @Controller 나 @Service는 어떻게 빈 등록 대상이 되는 걸까? 바로 @Controller나 @Service 어노테이션은 @Component 어노테이션을 포함하고 있기 때문이다.
@ComponentScan 어노테이션을 이용한 컴포넌트 스캔
컴포넌트 스캔을 사용하기 위해서는 설정 정보 클래스에 @ComponentScan 어노테이션을 붙여줘야 한다. 이 때, 컴포넌트 스캔의 범위는 설정정보에 작성한 클래스의 패키지의 하위 패키지를 포함한 자신의 모든 패키지가 된다.
그런데 모든 자바 클래스들을 모두 컴포넌트 스캔하게 된다면 시간이 오래 걸릴 수 있다. 그래서 아래와 같이 설정한 위치부터 컴포넌트 스캔을 하도록 설정할 수 있다.
@ComponentScan( basePackages = "com.kakao.lango")그리고 Spring Boot에서는 main 메소드를 가지고 있는 클래스에 @SpringBootApplication 어노테이션을 명시하게 된다.
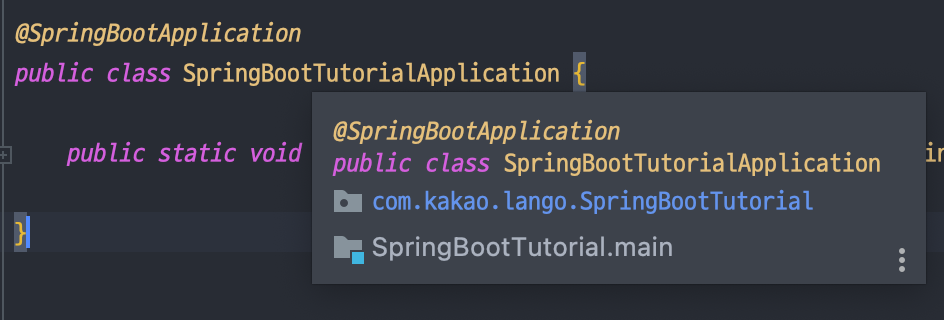
@SpringBootApplication 어노테이션의 내부를 들여다보면 @ComponentScan 어노테이션을 확장하여 사용하고 있음을 알 수 있었다.

xml 파일이나 Java 파일에서 컴포넌트 스캔 사용하기
다음으로 XML 파일이나 Java 파일 안에서 컴포너트 스캔을 설정하여 사용하는 방법에 대해서 알아보자.
1. xml 파일에 설정하는 방법
먼저 xml 파일에서 컴포넌트 스캔을 설정하는 과정에 대해서 알아보자.
<context:component-scan base-package="com.kakao.lango"/>
<context:component-scan base-package="com.kakao.lango, com.kakao.jooney"/>
다음과 같이 xml 파일에 설정하고 기본 패키지명을 작성하면 해당 기본 패키지를 기준으로 클래스들을 스캔하여 빈으로 등록한다. 이 때, 기본 패키지를 작성할 때는 여러개의 패키지를 작성할 수도 있다.
위처럼 설정을 작성한다면 기본 패키지 하위에 존재하는 @Controller, @Service, @Repository, @Component 과 같은 어노테이션이 붙은 클래스들을 모두 빈으로 등록시킨다.
2. 자바 파일안에서 설정하는 방법
다음으로 Java 파일로 만들어 컴포넌트 스캔을 진행해보자.
@Configuration
@ComponentScan(basePackages = "com.kakao.lango")
public class AppConfig {
...
}다음과 같이 @Configuration 어노테이션을 붙인 클래스는 앞에서 설정했던 xml 파일과 동일한 설정 파일로 사용할 수 있게 된다. 그렇게 해당 클래스를 설정파일로 설정한 후, @ComponentScan 어노테이션을을 붙여 기본 패키지를 설정해주면 된다.
만약 컴포넌트 스캔을 사용하지 않는다면, 빈으로 등록하여 사용할 클래스들을 개발자가 직접 xml 파일에 등록해야 하는 번거로움이 클 것이라는 생각이 들었다.
Day - 47
SimpleJdbcInsert를 사용하며 발생한 이슈
Spring Legacy Project를 통해서 트랜잭션 공부를 위해 DB에 CRUD 작업을 수행하던 중 SimpleJdbcInsert 클래스와 관련된 이슈가 발생하였다.
goods라는 객체를 모델삼아 데이터베이스에 삽입하는 작업을 하고 있었는데 내가 만든 goods 테이블이 아닌 엉뚱한 goods 테이블에 삽입을 하며 예외를 발생시켰다.
Error Console Log
PreparedStatementCallback; bad SQL grammar [INSERT INTO goods (id, itemid, itemname, price, description, pictureurl, updatedate, createdAt, updatedAt, deletedAt) VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?)]; nested exception is java.sql.SQLSyntaxErrorException: (conn=89) Unknown column 'id' in 'field list'에러 로그를 살펴보았더니 이상했다. 나는 lango Database에 goods 테이블을 만들어 작업 중이었는데, 해당 goods 테이블에는 id, itemid, itemname, price등과 같은 컬럼을 만들지 않았다.
내가 작업 중인 lango Database 안의 goods 테이블의 내용은 다음과 같다.
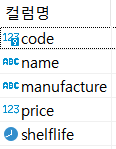
code, name, manufacture, price, shelflife라는 컬럼으로 구성된 테이블에 삽입을 하려 했지만, 생뚱 맞게 id, itemid, itemname 등과 같은 컬럼에 삽입할 수 없다는 SQL 에러가 발생한 것이다.
그래서 SimpleJdbcInsert 클래스를 이용한 코드를 살펴보았다.
@Autowired
private SimpleJdbcInsert template;
@Transactional
public void insert() {
template.withTableName("goods");
...
}SimpleJdbcInsert를 외부에서 주입받아 template.withTableName("goods"); 구문을 실행하는 것말곤 특별하지 않다.
Search Solution
뭐가 문제일까? 고민을 해보았다. 가장 먼저 해볼 수 있는건 역시 눈에 보이는 로그이다. 그렇게 콘솔에 출력된 로그를 살펴보니 lango Database의 goods가 아닌 post Database의 goods 테이블을 가져왔음을 알 수 있었다.
Retrieving meta-data for post/guest1/goods
Retrieved meta-data: id 4 false
Retrieved meta-data: itemid 4 false
Retrieved meta-data: itemname 12 true
Retrieved meta-data: price 4 true
Retrieved meta-data: description 12 true
Retrieved meta-data: pictureurl 12 true
Retrieved meta-data: updatedate 12 true
Retrieved meta-data: createdAt 93 false
Retrieved meta-data: updatedAt 93 false
Retrieved meta-data: deletedAt 93 true내가 연결해놓은 MariaDB에는 lango Database뿐만 아니라 post Database와 jdbc Database에도 goods라는 테이블들이 만들어져 있다.
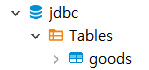
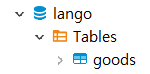
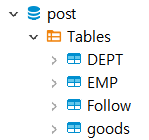
다른 Database에 goods라는 이름으로 테이블이 존재하지만, jdbc 설정을 lango Database로 연동했는데, 어째서 lango Database에 있는 goods 테이블이 아닌 다른 Databse의 goods 테이블에 접근을 하는 것인지에 대해서 큰 의문점이 생겼다.
jdbc 설정과 관련된 코드는 다음과 같이 작성하였다.
<!-- jdbc 설정 -->
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName">
<value>net.sf.log4jdbc.sql.jdbcapi.DriverSpy</value>
</property>
<property name="url">
<value>jdbc:log4jdbc:mariadb://localhost:3306/lango</value>
</property>
...
</bean>Read Document
그렇다면 내가 SimpleJdbcInsert 클래스를 잘못 사용했던 것은 아닐까? 라고 생각하여 SimpleJdbcInsert 공식문서를 통해 SimpleJdbcInsert에 대해서 읽어보았다.
- SimpleJdbcInsert는 테이블에 대한 간편한 삽입 기능을 제공하는 재사용 가능한 다중 스레드 개체이며, 제공해야 할 것은 열 이름과 열 값을 포함하는 테이블 및 맵의 이름이다.
- 메타 데이터 처리는 JDBC 드라이버에서 제공하는 DatabaseMetaData를 기반으로 하는데, JDBC 드라이버가 지정된 테이블에 대한 열 이름을 제공할 수 있는 한 이 자동 감지 기능을 사용할 수 있다.
공식문서의 내용을 통해서 새로 알게된 것은 직접 lango Database를 연동했다고 하더라도 내 접속정보로 연결된 MariaDB의 모든 테이블에서 goods라는 테이블을 찾게된다는 것이다.

그렇다면 goods라는 테이블을 유일무이하게 존재시키면 되는 걸까?
post Database와 jdbc Database의 goods 테이블의 이름을 변경한 뒤 다시 실행해보니 정상적으로 lango Databse의 goods 테이블에 데이터 삽입이 동작하는 것을 확인할 수 있었다.
이번 이슈를 통해서 공식문서 정독의 필요성을 크게 깨달았다. 단순히 제공되는 하나의 클래스를 사용하는데도 사용법을 모르게 사용한다면 이번 이슈와 같이 시간을 낭비할 수도 있다는 것이다.
Day - 48
Spring MVC와 Spring Boot
Spring MVC와 Spring Boot의 차이점을 알아보기 전에 이 두가지가 뭔지 간단하게 정리하고 넘어가자.
Spring MVC란?
Spring MVC는 MVC(Model-View-Controller) 디자인 패턴을 적용하여 웹 기반 애플리케이션을 구축하는 데 사용되는 Java 프레임워크이다. 따라서 Spring MVC는 Spring 프레임워크와 MVC 패턴을 결합한 버전이라고 볼 수 있다.
- Model: Model은 애플리케이션의 핵심 데이터가 포함되며, 일반적으로 POJO(Plain Old Java Object)로 구성된다.
- View: View는 Model의 데이터를 렌더링하는 역할을 담당하며, 클라이언트의 브라우저가 해석할 수 있는 HTML을 출력한다.
- Controller: Controller에는 애플리케이션의 비즈니스 로직이 포함되어 있다.
Spring Boot란?
Spring Boot는 REST API를 따르는 애플리케이션을 구축하는 데 사용되는 Java 프레임워크중 하나이다. 주로 마이크로 서비스를 만드는 데 중점을 두며, MSA(MicroService Architecture, 마이크로서비스 아키텍처)를 통해 애플리케이션을 독립적으로 개발하고 배포할 수 있다. Spirng Framework의 확장 버전으로써 개발 시간을 줄이는 데 많은 도움을 제공한다.
스프링 부트에서는 4개의 계층이 있다.
- Presentation layer: 프론트엔드(front-end) 부분으로 구성되며 보통 HTTP 요청을 처리하는 계층이다. 요청에 대한 작업을 위해 비즈니스 계층으로 전송하는 역할을 수행한다.
- Business layer: 비즈니스 로직을 처리하는 계층으로 서비스 클래스를 포함하고 인증 및 유효성 검사를 수행한다.
- Persistence layer: 비즈니스 개체를 데이터베이스 행으로 변환하는 스토리지 논리를 포함하는 계층이다.
- Database layer: CRUD(Create, Retrieve, Update 및 Delete) 작업을 수행하는 계층이다.
Spring Framework에서는 Java Application 개발을 위해 다양한 인프라를 제공해주는데 그 중 Spring을 MVC 구조로 개발할 수 있게 도와주는 것이 Spring MVC라고 볼 수 있고, Spring Boot는 별개로 Spring Framework를 설정하는데 필요한 각종 설정들을 자동화해주는 확장 버전 정도라고 알고 있었다.
그렇다면 Spring MVC로 만든 프로젝트와 Spring Boot로 만든 프로젝트는 구체적으로 어떤 차이가 있을까?
Spring MVC와 Spring Boot의 차이점은?
설정 자동화
내가 배우고 사용했던 Spring MVC와 Spring Boot의 차이로는 가장 먼저 설정의 자동화 여부를 자신있게 말할 수 있다. Spring MVC 프로젝트를 만들어서 필요한 애플리케이션을 개발하려면 컴포넌트 스캔(Component-scan), 디스패쳐 서블릿(Dispatcher Servlet), 뷰 리졸버(View Resolver)를 설정해야 하며, 정적 컨텐츠를 제공하기 위한 jar 파일들도 준비해야 한다. 이 때, 별도의 xml 파일이나 initialzer 클래스를 이용하여 구성 작업을 진행한다. 그에 반해 Spring Boot에서는 애플리케이션을 구성하는데 필요한 기본 환경설정들을 auto-configuration(자동 구성) 프로세스를 통해서 자동으로 제공해준다.
WAS
Servlet 기반의 애플리케이션을 실행하려면 Tomcat과 같은 WAS(Web Application Server)가 필요한데, Spring MVC의 경우는 별도로 WAS 서버를 설치한 후 사용해야 한다. 반면에 Spring Boot는 기본적으로 Tomcat이 내장되어 있기 때문에 별도로 WAS를 설치할 필요가 없다.
Spring MVC와 Spring Boot에 대해서 알아보고 어떤 점이 다른지에 대해서 알아보았다. Spring MVC와 Spring Boot 모두 Spring Framework로써 사용하여 개발할 수 있기 때문에 Spring Boot를 무조건 사용해야 한다는 정답이 아니다. 결국 개발해야할 애플리케이션의 규모나 요구사항에 따라 결정하여 사용하면 된다.
Legacy System에 접근하여 개발 및 유지보수를 위해서 Spring MVC를 사용하거나, 빠른 테스트 및 배포를 위해서 Spring Boot를 통해 프로젝트를 진행할 수 있을 것이다.
Final..
카카오 클라우드 스쿨에서의 10주차 교육과정을 마쳤다.
Spring Framework를 통해 Java 애플리케이션을 개발하는 기술들에 대해서 배웠다. Legacy Project와 MVC Project를 통해서 다양한 설정 파일들을 직접 설정해주고 만들면서 Spring의 핵심 기술 원리를 이해하려고 노력했던 것 같다.
그래도 짧은 시간 안에 Spring의 다양한 요소들을 머릿속에 기록하기란 쉽지 않음을 느낀다. 특히 Spring을 이용하는 가장 큰 요소인 IoC와 DI에 대해서, Spring의 Bean에 대해서 다시 배우고 이해할 수 있었다.
다음 주에는 Spring Boot로 프로젝트를 만들어 다양한 실습을 진행할 예정이다. 교육과정 속에서 Legacy나 MVC로 만든 프로젝트에 비해 Spring Boot가 각종 설정들을 자동화해준다고 해서 Spring Boot를 맹신하지 말고 단지 Spring의 확장 버전 중의 하나를 배우고 적용하여 Spring을 통해 어떻게 개발환경을 구축할 수 있는 것인지를 목적으로 교육에 임하려 한다.
혹여 잘못된 내용이 있다면 지적해주시면 정정하도록 하겠습니다.게시물과 관련된 소스코드는 Github Repository에서 확인할 수 있습니다.
참고자료 출처
