
Intro
실습과 실무는 다르다.
Spring Boot를 활용한 실습 프로젝트를 진행하면서 학습 감정에 대한 기복을 포함하여 많은 것을 느꼈던 한 주가 아니었나 생각이 들었다. 실습 프로젝트를 하루 이틀 진행하면서 처음에는 코딩을 하긴 하지만 내가 고민하고 짜는 코드가 아니라 남이 짜준 코드를 copy & paste 하는 느낌이 강하게 들었다.
그런데 이런 생각을 생각보다 빨리 떨쳐냈다. 그리고는 남이 짜준 코드를 붙여넣으면서 개발하고는 있지만 왜 이렇게 작성했을지 개발자의 의도를 파악하거나 레거시한 기술들은 없는지 고민해보니 생각보다 코드를 리뷰하는 부분에 대해서도 생각해볼 수 있었다.
진행하던 실습 프로젝트에서 개발자의 의도를 파악하는 것은 여간 어려운 것이 아니었다. 어노테이션이나 메소드 하나하나가 '왜 이렇게 사용했을까?' 라는 의문만 들었고 생각보다 실무에서 사용하지 않는 속성들도 작성되어 있었다. 왜일까 생각해보니 실습 프로젝트의 궁극적인 목적은 실무에서 활용될만한 서비스가 아닌 학습 달성이기 때문이라고 느꼈다.
이러한 감정을 느끼자마자 실망감이 들었지만 아이러니하게도 내 실력은 아직 실무와 가까운 서비스나 프로젝트를 구현할 능력이 되지 못하다는 것을 직감하고 있었다. 실무와 가까운 프로젝트를 하기 위해서는 결국 학습의 반복이 이루어져야 하고 그 안에서 학습의 결과물들을 나만의 것으로 녹여낸 산출물이 있어야 한다.
그래서 다시 겸손한 마음을 가지고 실습 프로젝트를 가볍게 여기지 말고 실무에서는 어떻게 활용될지, 어떻게 리팩토링 할 수 있을지와 같은 고민들을 해보고 가능하다면 적용해보려 한다. 학습의 목표가 학습이 아닌 학습을 통한 성장이어야 함을 명심하자!
Day - 49
@RequestParam vs @PathVariable
@RequestParam과 @PathVariable 어노테이션은 모두 URI를 통해 전달된 값을 파라미터로 받아오는 역할을 수행한다. 즉 데이터 전달을 위해 사용된다는 공통점을 가지고 있다.
두 어노테이션은 파라미터를 받아오는 역할이지만 어느 정도 다른 점이 있기 때문에 다른 어노테이션이 되었을 것이다. 그래서 @RequestParam과 @PathVariable 어노테이션은 어떤 차이가 있으며 각각 쓰임새가 어떻게 다른지 궁금해졌다.
@RequestParam어노테이션은 요청의 파라미터를 연결할 매개변수에 결합해주는 어노테이션이며,@PathVariable어노테이션은 URI 템플릿의 변수 값을 파라미터로 할당해주는 어노테이션이다.
@RequestParam과 @PathVariable 어노테이션의 사용법은?
그렇다면 두 어노테이션은 파라미터를 받아올 때 URL에 포함된 쿼리 스트링(Query String)을 어떤식으로 사용하는지 예시 URL을 보면서 함께 살펴보자.
@RequestParam
http://localhost:8080/review?member=lango&point=5
@GetMapping("/review")
public String getReviewWithPoint(
@RequestParam(value = "member") String member,
@RequestParam(value = "point") int point) {
System.out.println("[parameter] member: " + member);
System.out.println("[parameter] point: " + point);
return "main";
}@RequestParam 어노테이션을 이용한 컨트롤러 요청 메소드를 하나 작성하였다. getReview 메소드는 GET 요청을 받으면 쿼리 스트링을 통해 전달된 member와 point를 받아와서 @RequestParam으로 선언해둔 member 변수와 point 변수에 각각 대입 해준다.
또한, 서버의 콘솔을 확인해보면 요청 URL로 전달해준 파라미터 값인 member와 point의 값을 확인해볼 수 있다.
[parameter] member: lango
[parameter] point: 5@PathVariable
http://localhost:8080/comment/100
@GetMapping("/comment/{commentId}")
public String getComment(@PathVariable(value = "commentId") int commentId) {
System.out.println("[parameter] commentId: " + commentId);
return "main";
}@PathVariable 어노테이션을 활용한 요청 메소드 getComment을 작성하였다.
getComment 메소드는 쿼리스트링으로 통해 전달된 commentId를 받아와서 @PathVariable로 선언한 commentId 변수에 대입해준다.
여기서 @RequestParam과 다른 점은 바로 @GetMapping 의 URI값이다. 해당 구문을 잘 살펴보면 실제 URI이 아니라 내가 임의로 지정한 URI 템플릿이 존재한다. 이처럼 @PathVariable 은 메서드 인자에 사용되어 URI 템플릿 변수의 값을 메서드 인자로 할당하는데 사용된다고 볼 수 있다.
서버의 콘솔을 확인해보면 다음과 같이 commentId의 값을 잘 확인할 수 있다.
[parameter] comment: 100@RequestParam과 @PathVariable은 무엇이 다를까?
두 어노테이션은 쿼리 스트링으로 받아온 값을 변수에 대입한다는 점 외에는 크게 다른 점은 없어보인다. 그런데 받아올 파라미터의 개수가 늘린다면 이야기가 달라진다.
@RequestParam 어노테이션은 받아올 값이 여러개라도 쿼리스트링에서 받아온 값을 @RequestParam으로 선언한 변수에 할당시켜준다. 그에 반해 @PathVariable 어노테이션은 어떤 요청이든 하나의 값밖에 받아오지 못한다. 그래서 @PathVariable 어노테이션을 이용한 메소드는 보통 기본 키값 하나만 전달받는 POST 방식으로 많이 이용한다.
@PathVariable을 이용한/{commentId}/{userId}같은 요청은/가 추가되어 URL Pathdml 깊이가 달라지기에@RequestParam을 이용한/comment?commentId=1&userId=lango와 같은 요청 방식처럼 하나의 URL Path에서 여러개의 값을 전달한다고 볼 수는 없다.
@RequestParam vs @PathVariable
간단하게 정리하자면 @RequestParam 과 @PathVariable은 둘 다 데이터를 받아오는 데에 사용하는데, @PathVariable은 값을 하나만 받아올 수 있기 때문에 여러 개의 데이터를 받아올 때는 @RequestParam을 사용하면 된다.
결국 요청 URL를 어떻게 전달할 것인지에 따라@PathVariable 어노테이션을 사용할 지, @RequestParam 어노테이션을 사용할지 고민하고 결정해야 한다고 생각이 들었다.
POST 요청에 이용하는 x-www-form-urlencoded, raw, form-data 방식들에 관하여
Postman을 통해 API 개발을 하는데, 보통 POST 방식으로 요청할 경우 form-data, x-www-form-urlencoded, raw 등의 방식을 선택하여 데이터와 함께 요청을 보낼 수 있다.
과연 각각의 방식은 어떤 차이가 있길래 방식을 나누어 요청하는지 의문이 생겼다. 그래서 POST 방식의 요청방식에 대해서 살펴보려고 한다.
form-data
form-data 방식은 content-type을 multipart로 설정하여 요청을 보내는데 데이터와 파일을 함께 전송하기 위해서 사용한다. Key-Value 쌍으로 작성하여 전송하는데, Key는 보내는 항목의 이름이고 Value는 실제 값이라고 보면 된다.
x-www-form-urlencoded
x-www-form-urlencoded 방식은 form-data 방식과 유사하다. 다만, 다른 점은 바로 인코딩된 데이터를 서버로 전송한다는 것이다.
urlencoded는 url 형태로 표현된 방식을 뜻하는데, 결국 인코딩이 된다는 것은 전송되는 데이터가 알기 어려운 문자로 변환되어 보안성을 향상시킬 수 있다는 의미이다.
raw
raw 방식은 content-type을 제공되는 타입으로 구성하여 요청하는 방식이다. 요청 본문(Body)과 및 헤더와 함께 Postman에서 지원하는 다양한 서식 스타일을 설정할 수 있다.
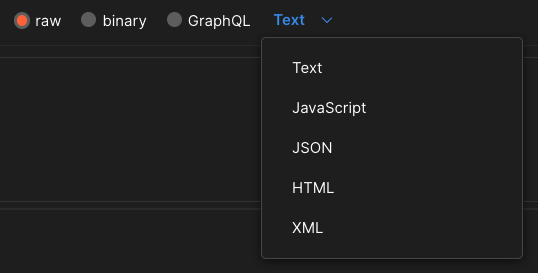
제공되는 content-type으로는 Text, JavaScript, JSON, HTML, XML 등이 있다. POST 방식을 테스트하며 가장 많이 사용되는 방식은 Raw의 content-type을 application/json로 설정하는 요청 방식이다. application/json 타입은 전송할 데이터를 JSON 형태로 만들어 전송할 수 있다.
x-www-form-urlencoded, raw, form-data간의 차이점은?
일단 x-www-form-urlencoded 방식은 데이터를 인코딩하여 전송하기 때문에 크기가 큰 데이터의 경우 전송에 제약이 생기게 된다. 크기가 큰 데이터를 전송할 때는 text나 form-data를 사용하는 것이 바람직하다.
raw로 데이터를 전송하는 방식은 일반적인 text 데이터나 JSON 데이터를 전송한다. 또한, Body의 내용을 전송할 때, HTML 및 XML과 같은 마크업 언어 등을 포함한 다양한 유형으로 데이터를 보낼 수 있다.
이렇게 데이터를 전송할 때 Postman에서 지원하는 데이터 전송 방식을 살펴보았다. 그 중 form-data, x-www-form-urlencoded 및 raw 방식들은 무엇이고 어떻게 사용해야 하는지를 더욱 구체적으로 알게되었다. 이는 앞으로 Postman으로 데이터 전송 테스트를 하는데 큰 도움이 될 것 같다.
Day - 50
spring Boot 3 버전의 등장?!

비교적 최근(?)인 2022년 11월 24일에 Spring Boot 3 버전이 정식으로 릴리즈되었다. 기존의 2.7 버전에서의 메이저 버전 업데이트이다. Spring Boot 3 버전은 기존의 2 버전과 비교하여 달라진 것은 무엇인지, 또 그에 따른 요구사항은 어떤 것들이 있는지 알아보려 한다.
Spring Boot 3 버전의 요구사항
1. Java 17 버전 이상만을 지원한다.
Spring Boot 2 버전과 가장 큰 차이점은 바로 17 이상의 Java 버전만을 지원한다는 것이다. 기존의 안정화된 Java버전은 8과 11이 있는데, 이후로 채택된 17 버전을 Spring Boot 3에서 공식적으로 채용했다고 볼 수 있다. Spring Boot 3의 코드를 보면 17 미만의 Java 문법이 제거됨을 확인할 수 있다. 그래서 프로젝트에서 17 이하의 Java 버전을 쓰고 있다면 버전을 업그레이드 해야 사용할 수 있다.
2. Spring Boot의 버전 업데이트는 순차적으로 진행해야 한다.
대부분 사용되고 있는 Spring Boot의 버전은 2 버전일 텐데 3.0으로 버전 업데이트를 해야할 경우 다이렉트로 업데이트를 진행할 수 없다. Spring Boot 3 버전으로 업데이트 하기 전에 Spring Boot 2 버전에서의 최신 버전으로 선행 업데이트가 요구된다. 다이렉트 업데이트를 진행한다면 많은 변경점으로 인해 마이그레이션이 복잡해지기 때문이다.
그래서 2.5 버전을 사용하고 있다면 먼저 2.5에서 2.6으로 버전 업데이트를 진행한 후 기능 정상 동작 여부를 테스트 한뒤 2.6에서 2.7로 업데이트를 진행하고 다시 한번 기능 정상 동작 여부를 테스트한다. 이후 마지막으로 2.7에서 3.0 버전으로 순차적인 업데이트 절차를 밟아야 한다.
3. Spring Boot 2 버전에서 사용하지 않거나 지원하지 않는 코드나 문법을 제거해야 한다.
Spring Boot의 레거시 버전, 즉 2.7 버전에서 더 이상 사용되지 않는(Deprecated)된 기능은 사용하지 않거나 변경하여 사용해야 한다.
예를 들어 Spring Security의 경우 5.7 버전부터 WebSecurityConfigurerAdapter 기능이 Deprecated로 적용되었으며, Spring Security 6.0 버전에서 호환되는 Spring Boot 3 버전에서는 WebSecurityConfigurerAdapter 기능이 제거되었다.
Spring Boot 3 버전 업데이트로 발생할 수 있는 컴파일 에러
Spring Boot 3 버전으로 업데이트하게 되면 2 버전에서는 없었던 다양한 컴파일 에러가 발생할 수 있다. 종종 발생할 수 있는 몇 가지 컴파일 에러를 살펴보자.
javax 패키지를 jakarta로 변경한다.
Spring Boot 3 버전으로 업데이트 한다면 발생할 수 있는 대표적인 컴파일 에러 중에 하나이다. Java EE에서 Jakarta EE로 전환하며 생기는 에러인데, javax로 시작하는 패키지 이름은 jakarta로 변경하여 사용해야 한다.
javax.persistence. ➔ jakarta.persistence.
javax.validation. ➔ jakarta.validation.
javax.servlet. ➔ jakarta.servlet.
javax.annotation. ➔ jakarta.annotation.
javax.transaction. ➔ jakarta.transaction.
Querydsl 설정 변경
javax.persistence.가 jakarta.persistence.로 변경되면서 Querydsl 관련하여 build.gradle 설정파일을 변경해야 한다. dependencies 옵션에만 몇 줄 작성하면 되기에 2 버전에서의 Querydsl 설정보다 더욱 간단하게 Querydsl 설정을 할 수 있다.
dependencies {
// Querydsl 설정
implementation 'com.querydsl:querydsl-jpa:5.0.0:jakarta'
annotationProcessor "com.querydsl:querydsl-apt:${dependencyManagement.importedProperties['querydsl.version']}:jakarta"
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"s
...
}Spring Boot 3 버전에서 추가된 기능들
마지막으로 Spring Boot 3 버전에서 새로 사용할 수 있거나 지원해주는 기능들도 많은데, 그 중 인상 깊었던 사항들 몇 가지만 추려서 살펴보자.
1. Java 17 버전 이상을 지원한다.
앞서 요구사항에서도 언급하였지만, 이는 요구사항이면서 동시에 새로 지원되는 기능 사항 중 하나로 볼 수 있다.
2. javax 패키지는 Jakarta 패키지로 대체된다.
기존에 사용되고 있던 JPA 의 패키지명은 javax.* 이었다. Spring Boot 3 버전에서는 Jakarta EE 기본 지원 버전을 높여 jakarta.* 로 대체되었다.
3. 로그 포멧 변경
로그(Logback이나 Log4j2은)의 경우 기존에는 yyyy-MM-dd HH:mm:ss.SSS 형식으로 사용되고 있었다. Spring Boot 3 버전에서는 날짜 및 시간 기본값 표준인 ISO-8601 을 따르게 되어 yyyy-MM-dd’T’HH:mm:ss.SSSXXX 형식으로 날짜와 시간 사이에 구분 문자로 공백문자가 아닌 T를 사용하게 되었다.
4. Tomcat 10.1, Jetty 11, Undertow 2.3 등과 같은 최신 WAS와 호환이 가능하다.
Spiring Boot에 내장된 WAS는 주로 Tomcat을 사용하고 있었다. Spring Boot 3 버전에서는 Tomcat 10 버전 등과 같은 더욱 강력한 기능을 제공하는 WAS를 지원하도록 확장되었다.
여기까지 Spring Boot 3 버전의 릴리즈에 대해서 알아보며, 기존 2 버전과의 차이점과 2 버전에서의 레거시한 기능들은 무엇이었는지 알 수 있었다. 사실 2 버전도 제대로 사용할 줄 모르기 때문에 지원되는 다양한 기능들은 직접 실습하고 적용해보며 느껴봐야겠다.
Day - 51
JPA의 영속성 컨텍스트란?
Spring에서 JPA를 사용하면서 클래스 객체를 만들고 엔티티(Entity)로 매핑하는 과정들을 학습하고 실습해보며 별도의 쿼리문 없이 DB 테이블과 매핑된 엔티티 객체만을 다루는 것으로 DB 테이블의 데이터를 조작할 수 있다는 것이 너무나 신기했다. 그렇게 JPA에 대한 내용들 찾아보다보니 많이 거론되는 영속성 컨텍스트에 대해서 궁금해졌고 이번에 간단하게 정리해보려 한다.
영속성(Persistence)의 사전적 의미를 살펴보면 고집, 없어지지 않고 오래 지속되는 성질이라는 뜻을 내포한다고 한다. IT적으로 해석해보자면 데이터를 영구적으로 저장하는 것을 의미한다고 볼 수 있다.
JPA 영속성 컨텍스트(Persistence Context)는 엔티티(Entity)를 영구 저장하는 환경이라는 뜻이다. 영속성 컨텍스트는 애플리케이션과 데이터베이스 사이에서 객체를 보관하는 가상의 저장소 역할을 수행한다.
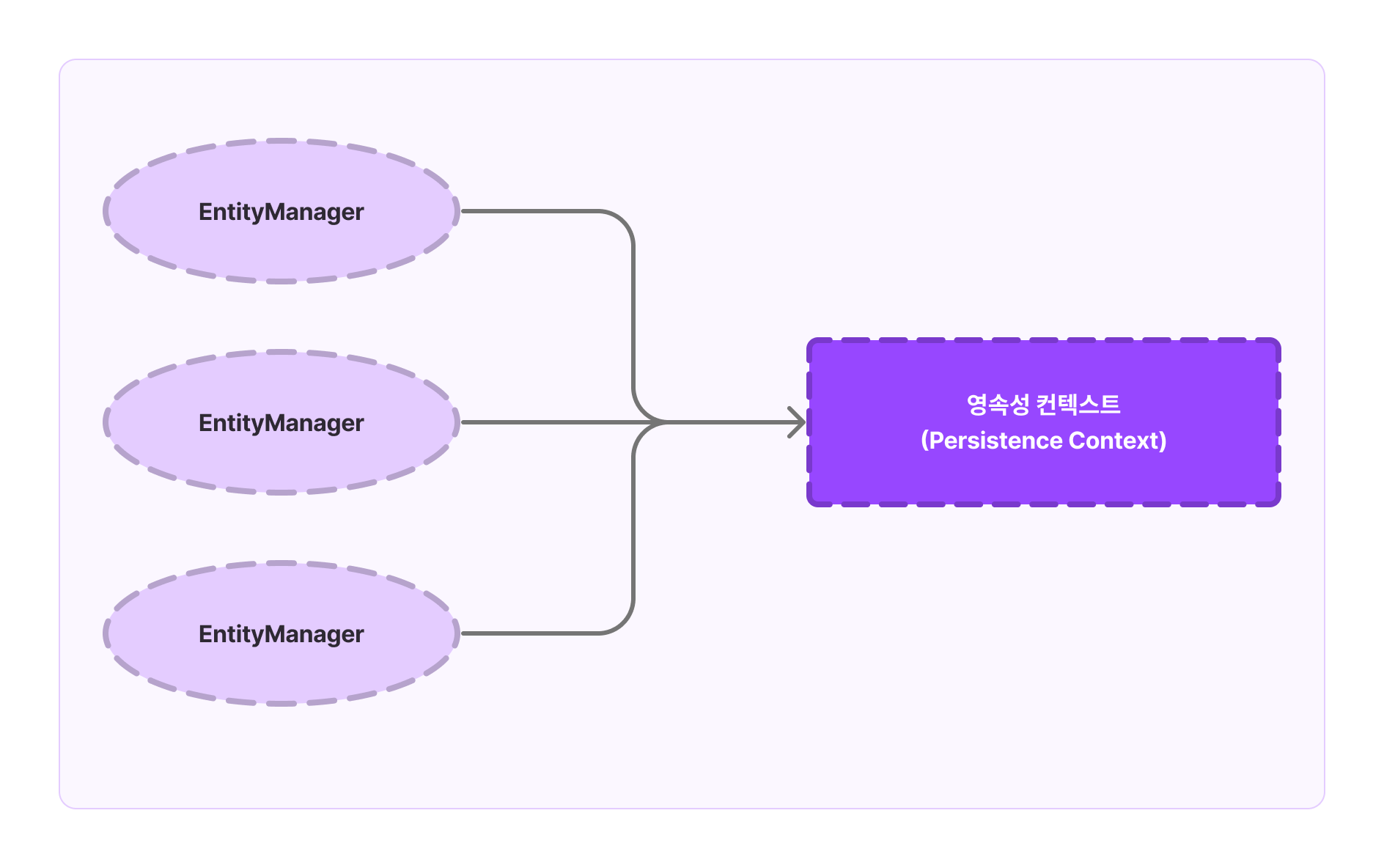
Spring에서는 엔티티 매니저(EntityManager)를 이용하여 영속성 컨텍스트로 접근할 수 있다. Entity를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 해당 엔티티를 보관하고 관리한다. (이 때, Entitymanager는 영속성 컨텍스트 내의 Entity들을 관리하는 역할을 담당한다.)
엔티티의 생명주기(Entity Life Cycle)
영속성 컨텍스트를 엔티티의 영속성 상태는 어떤 기준으로 관리되는 것인지를 엔티티의 생명주기를 통해 알아보자.
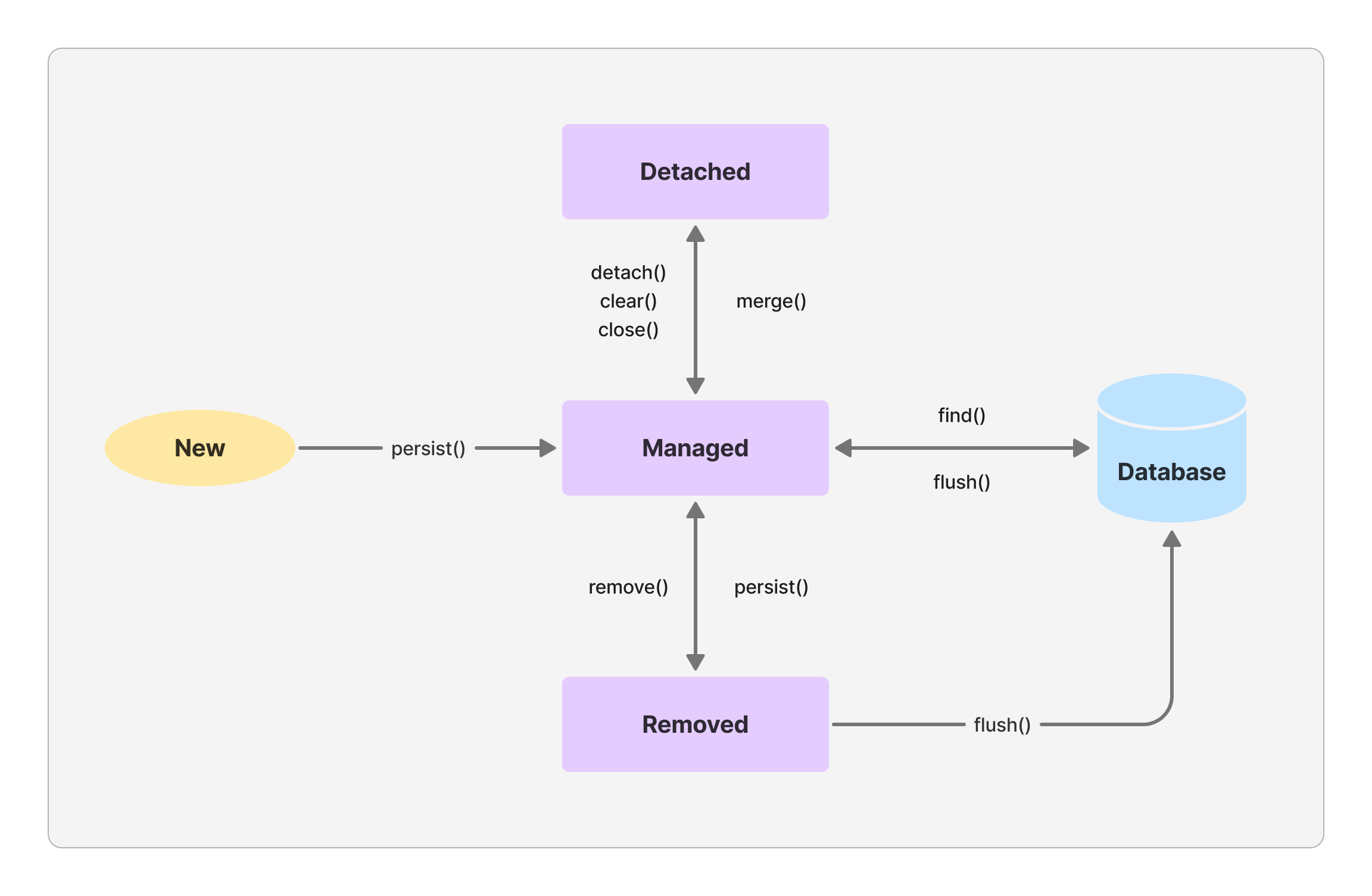
엔티티의 영속성 상태는 다음과 같은 상태들로 구분된다.
- 비영속 상태(new/transient)
- 영속 상태(managed)
- 준영속 상태(detached)
- 삭제 상태(removed)
비영속 상태(new/transient)
비영속 상태는 영속성 컨텍스트와 전혀 관계가 없는 상태이다. 엔티티(객체)를 생성했지만 아직 영속성 컨텍스트에 등록되지 않은 상태로 볼 수 있다.
// 객체를 생성만 해둔 상태이다.
Member member = new Member(1L, "lango");영속 상태(managed)
영속 상태는 영속성 컨텍스트에 저장된 상태를 말한다. 생성한 객체를 EntityManager를 통해 영속성 컨텍스트에 등록해두었기에 등록된 엔티티는 영속성 컨텍스트에서 관리하게 된다.
EntityManager entityManager = new EntityManager();
entityManager.persist(member);엔티티가 영속 상태가 되었다고 하더라도, 바로 매핑된 DB 테이블에 변경점을 적용하지 않고, 트랜잭션(Transaction)의 커밋(Commit) 시점에 영속성 컨텍스트에 있는 정보들을 DB 테이블에 적용하게 된다.
준영속 상태(detached)
영속성 컨텍스트에 저장되었다가 분리된 상태, 즉 영속성 컨텍스트가 관리하지 않게 된 엔티티는 준영속 상태라고 볼 수 있다. 특정 엔티티를 준영속 상태로 만들고자 한다면 detach 메소드를 호출하면 된다.
// member 엔티티를 준영속 상태로 변경한다.
entityManager.detach(member);
// 엔티티를 비우거나 종료해도 준영속 상태가 된다.
entityManager.clear(member);
entityManager.close(member);준영속 상태에서는 식별자 값은 가지고 있지만 1차 캐시, 쓰기 지연, 변경 감지, 지연 로딩을 포함한 영속성 컨텍스트가 제공하는 어떠한 기능도 동작하지 않는다.
삭제 상태(removed)
삭제(removed) 상태는 말 그대로 삭제된 상태인데 해당 엔티티를 영속성 컨텍스트와 데이터베이스에서 삭제한다.
// member 엔티티를 영속성 컨텍스트에서 삭제
entityManager.remove(member);영속성 컨텍스트를 사용하는 이유
영속성 컨텍스트를 사용하는 이유는 아래와 같은 사항들을 챙길 수 있기 때문이다.
- 1차 캐시(Cache)
- 엔티티 객체의 동일성(identity) 보장
- 트랜잭션(Transaction) 지원
- 변경 감지(Dirty Checking)
- 지연 로딩(Lazy Loading)
각각의 사항들 중에서 1차 캐시, 엔티티 객체의 동일설 보장, 트랜잭션 지원, 변경감지 사항에 대해서 살펴보려 한다.
1차 캐시(Cache)
엔티티 객체를 생성하고 persist() 메소드를 이용해 해당 엔티티 객체를 영속성 컨텍스트에 등록하여 영속성 상태로 만들어둔다면 해당 엔티티 객체는 영속성 컨텍스트에 key-value 형태로 저장된다.
Member member = new Member();
member.setId(1L);
member.setUsername("lango");
// entity 객체를 영속성 컨텍스트에 저장한다.
entityManager.persist(member); 중요한 점은 이 상태에서 EntityManager의 find 메소드를 이용해 해당 엔티티를 조회하면 데이터베이스에 접근할 필요없이 1차 캐시에 저장된 데이터를 가져온다.
Member lango = entitiyManager.find(Member.class, "1L");우선적으로 1차 캐시에서 엔티티를 찾고, 해당 엔티티가 존재한다면 바로 반환한다. 1차 캐시에 존재하지 않는다면 데이터베이스로 접근하여 찾아와서 1차 캐시에 저장해두고 엔티티를 반환한다.
결국 동일한 조회 작업에 대해서 같은 조회 로직을 여러 번 호출하는 것이 아니라 딱 1번만 호출하여 엔티티를 가져올 수 있기에 데이터베이스의 접근을 줄여 성능을 향상시킬 수 있다.
엔티티 객체의 동일성(identity) 보장
영속성 컨텍스트에 등록된 객체는 동일성을 보장받는다. 이 말은 해당 엔티티의 값 뿐만 아니라 생성된 인스턴스 또한 같다는 것을 의미한다.
Member member1 = entityManager.find("Member.class", "1L");
Member member2 = entityManager.find("Member.class", "1L");
System.out.print(member1 == member2);
// true 출력트랜잭션(Transaction) 지원
다음으로 영속성 컨텍스트에 등록된 엔티티 객체의 값이 변경된다고 해서 바로 DB의 값을 업데이트 하지 않는다. 이는 영속성 컨텍스트에서 트랜잭션(Transaction)을 지원하기 때문인데 트랜잭션 내부에서 영속 상태에 있는 엔티티의 값에 변경점이 생겼을 때 DB에 바로 적용하는 것이 아니라 별도의 쿼리 저장소에 쿼리문들을 생성하여 담아둔다. 그리고 이 쿼리들은 Entitymanager의 flush() 메소드나 트랜잭션의 commit 메소드가 호출되는 시점에 DB에 적용시키게 된다.
entityManager.flush();변경 감지(Dirty Checking)
더티 체킹이란 엔티티 객체의 변경점이 생겼을 때 이 변경점을 개발자가 영속성 컨텍스트에게 알려주지 않아도 자동으로 변경점을 감지하는 것이다.
더티 체킹은 데이터를 가져와서 1차 캐시에 데이터를 저장할 때 해당 엔티티에 대한 가짜 객체(,스냅샷 SNAPSHOT)도 함께 저장하는데 트랜잭션이 끝나는 시점에 엔티티와 이 스냅샷을 비교해서 변경점이 있다면 자동으로 DB에 적용시켜준다.
주로 데이터 수정(update)을 처리하는데 적용되는데 트랜잭션 안에서 데이터베이스에 접근하여 데이터를 가져온다면 이 데이터는 영속성 컨텍스트 등록되어 영속성 상태를 유지하게 된다. 이 때 해당 엔티티의 값을 변경한다면 트랜잭션이 끝나는 시점에 해당 엔티티의 변경점을 DB에 적용한다. 그래서 트랜잭션 안에서 엔티티의 값만 변경하면 별도로 update 쿼리를 보낼 필요 없이 데이터를 수정할 수 있게 되는 것이다.
EntityManager entityManager = new EntityManager();
EntityTransaction transaction = entityManager.getTransaction();
// 데이터 변경 시 트랜잭션을 시작하기
transaction.begin();
// 엔티티 조회하기
Member member = entityManager.find(Member.class, "1L");
// 엔티티 데이터 수정하기
member.setName("Developer");
// 트랜잭션에서 commit할 때 DB에 UPDATE 쿼리를 적용한다.
transaction.commit();위와 같이 JPA 영속성 컨텍스트에 대해서 알아보고 공부해볼 수 있었다. JPA를 사용한다면 필수로 숙지해야 하는 내용들이라 어렵지만 재미있고 흥미롭게 공부할 수 있었다.
Day - 52
Spring Data JPA에서 persistence Layer를 구성할 때 @Repository 어노테이션으로 빈 등록하지 않는 이유는?
Spring 기초를 다룰 때 각 계층마다 @Component 어노테이션을 통해 빈을 등록해야 한다고 알고 있었다. 그래서 Contoller 계층에서는 @Controller를, Service 계층에서는 @Service을, Persistence 계층에서는 @Repository어노테이션을 사용하여 싱글톤 패턴으로 각각 빈을 등록해야 한다.

그런데, Spring Data JPA 실습읗 하다가 사용하던 Repository interface가 @Repository 어노테이션 없이 잘 동작하고 있음을 알게되었고, 어떻게 동작하고 있었던 건지 의문점이 생겼다.
기존의 @Repository 어노테이션
Spring Data JPA를 사용하지 않았다면 Repository 인터페이스에 @Repository 어노테이션을 붙여 인터페이스로 정의하고 이 인터페이스의 구현체 클래스를 만들어서 사용했었다. 그래서 Repository의 인터페이스에 @Repository 어노테이션을 생략하게 된다면 빈 등록이 되지 않아 의존성 주입이 되지 않았다.
JpaRepository의 @NoRepositoryBean 어노테이션
어떻게 @Repository 어노테이션 없이 빈 주입을 할 수 있는지 고민을 하던 중 인터페이스에서 상속받는 JpaRepository 인터페이스 코드를 살펴보게 되었다.

JpaRepository 인터페이스를 뜯어보니 @NoRepositoryBean 어노테이션이 존재하는 것을 알 수 있었다. 구현 코드의 주석을 해석해보니 저장소 인터페이스를 선택할 수 없도록 하여 인스턴스를 생성하는 것을 제외하는 어노테이션이라고 적혀있었다.
@NoRepositoryBean 어노테이션은 Repository 인터페이스를 상속받았기 때문에 실제 빈을 만들지 않도록 하기 위해서 작성한다고 한다.
그렇다면 실제 빈은 어디서 만드는 것일까?
@EnableJpaRepositories 어노테이션
다른 개발자분들의 공유 글을 살펴보니 @EnableJpaRepositories 어노테이션에서 빈 등록이 이루어진다고 한다. @EnableJpaRepositories 어노테이션은Spring Boot에서는 자동으로 설정되버리기에 별도로 설정된 곳을 찾기 어려워 직접 @EnableJpaRepositories 어노테이션 내부 코드를 살펴보았다.
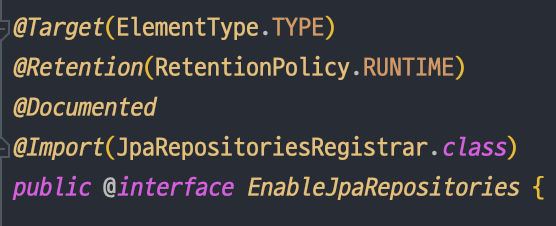
4번째 라인의 import 구문에서 JpaRepositoriesRegistrar.class가 사용되고 있음을 확인할 수 있다. 이 JpaRepositoriesRegistrar가 실제로 JpaRepository를 상속받은 모든 인터페이스를 빈으로 등록해주는 것이다.
또 JpaRepository를 상속하면 @Repository가 없어도 빈으로 등록되는데, 이는 컴포넌트 스캔에 의해 빈으로 동작하는 것이 아니라, spring data에서 해당 인터페이스를 구현한 클래스를 찾아서 사용한다. 실제로는 인터페이스를 구현한 클래스를 바로 사용하는게 아니라, 스프링이 동적으로 임의의 구현 클래스를 생성하고, 내가 구현한 클래스를 연결해준다.
그래서 Spring Data JPA를 이용해 인터페이스 하나만 생성한다면 @Repository 어노테이션을 사용할 필요가 없이 손쉽게 의존성을 주입하거나 빈 등록을 할 수 있다는 것을 알게 되었다.
Day - 53
기본 키 auto_increment와 관련된 이슈
게시판 프로젝트를 진행하던 중 게시글의 기본 키 값이 의도하던 대로 증가되지 않음을 확인하였다.
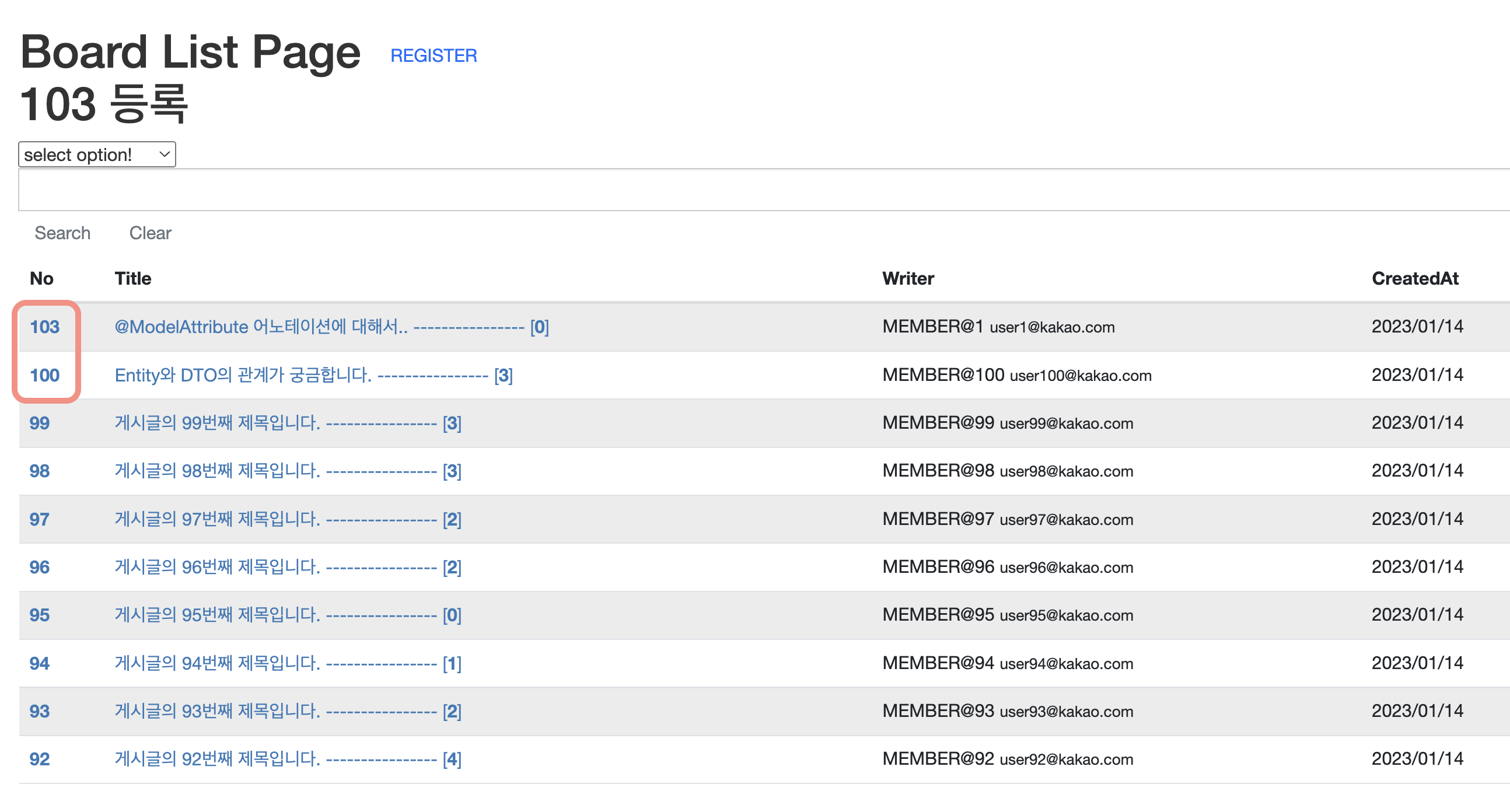
테스트를 통해서 100개의 게시글을 등록해둔 뒤 얼마 지나지 않아 하나의 새로운 게시글을 등록했는데 위 사진과 같이 101번이 아닌 103번으로 등록이 되었다. 왜 기본 키로 지정된 값이 순서대로 증가되지 않는 것일까?
@GeneratedValue 어노테이션을 통한 기본 키 생성 전략에 대해서
기본 키 값이 원하는 대로 증가되지 않는 문제를 살펴보기 전에 기본 키 값을 어떻게 부여하는지를 알아보았다. 먼저 작성한 게시글(Board)의 Entity 코드는 다음과 같다.
@Entity
public class Board extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long bno;
...
}bno라는 속성을 기본 키 설정하였는데 @GeneratedValue 어노테이션을 strategy=GenerationType.AUTO 이라는 옵션을 이용하여 설정하였다. 이 옵션은 기본 키를 자동으로 생성해준다.
GenerationType.AUTO옵션은 기본 설정 값으로 연결된 데이터베이스 종류에 따라 기본키를 JPA 구현체가 결정하여 자동으로 생성해준다.
GenerationType.AUTO 외에도 @GeneratedValue 어노테이션에서 제공하는 기본 키 자동 생성전략을 살펴보자.
| 생성 전략 | 설명 |
|---|---|
| IDENTITY | 기본키 생성을 데이터베이스에 위임한다. MySQL의 경우 AUTO_INCREMENT를 사용하여 기본키를 생성한다. |
| SEQUENCE | 데이터베이스의 특별한 오브젝트 시퀀스를 사용하여 기본키를 생성한다. |
| TABLE | 데이터베이스에 키 생성 전용 테이블을 하나 만들고 이를 사용하여 기본키를 생성한다. |
| AUTO(default) | JPA 구현체가 자동으로 생성 전략을 결정한다. |
이와 같이 @GeneratedValue 어노테이션을 통해서 기본 키 생성 전략을 4가지로 지정해 줄 수 있는데, 그렇다면 GeneratedValue-AUTO 옵션을 사용했을 때 어떻게 기본 키의 값을 자동으로 부여해주는 것일까?
JPA의 구현체인 하이버네이트(Hibernate)의 Interpreting AUTO
문서를 찾아보았다.
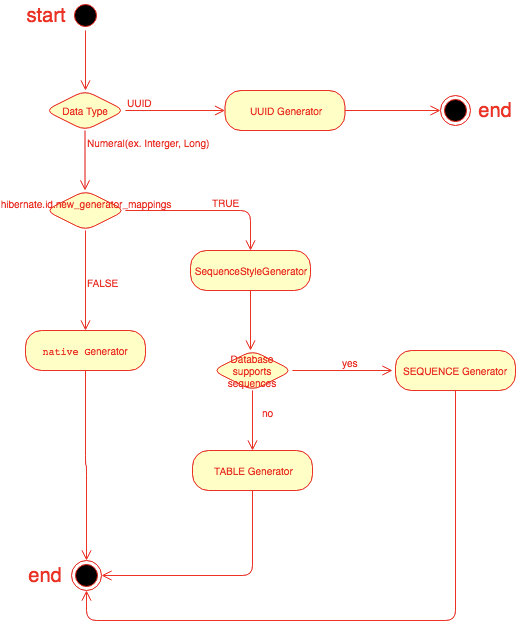
GenerationType.AUTO 성정을 통해 기본 키가 생성되는 과정은 다음과 같다.
-
Entity의 기본 키로 매핑된 속성의 타입이 UUID일 경우 UUID Generator를 통해 기본 키 값을 생성해준다.
-
Integer나 Long과 같은 숫자 타입일 경우 하이버네이트 프로퍼티인
hibernate.id.new_generator_mappings설정 값을 확인한다. -
위 설정값이 False라면 Native Generator가 되는데
GenerationType.IDENTIFY옵션으로 처리된다. -
위 설정값이 True라면, 연결된 데이터베이스가 시퀀스를 지원하는지 확인하고, 지원하면
GenerationType.SEQUENCE옵션으로 처리된다. -
연결된 데이터베이스가 시퀀스를 지원하지 않는다면,
GenerationType.TABLE옵션으로 처리된다. 이 때, 기본 키 전용 테이블인 hibernate_sequence 테이블이 생성된다.
GenerationType.AUTO 설정을 통한 원인 분석
앞서 살펴본 하이버네이트의 Interpreting AUTO 문서를 통해 기본 키 생성전략을 가지고 Board Entity의 기본 키를 생성하는 과정을 분석해보자.
bno라는 속성을 기본 키로 지정했고 bno는 Long 타입으로 선언하였다. Long 타입은 숫자 타입이기에 하이버네이트 프로퍼티 hibernate.id.new_generator_mappings 설정 값을 확인하게 되는데 GenerationType.AUTO 옵션에서 알 수 있듯이 명시적으로 설정해주지 않았기 때문에 이 설정값은 true가 되고,GenerationType.SEQUENCE 옵션으로 처리되어야 하지만 내가 사용하고 있는 데이터베이스는 MariaDB이므로 시퀀스 오브젝트를 지원하지 않는다. 결국 GenerationType.TABLE 옵션으로 결정되어 기본 키를 생성할 것이다.
GenerationType.TABLE 옵션으로 기본 키를 생성했다면 기본 키 전용 테이블인 hibernate_sequence 테이블이 존재해야 했다.
직접 테이블 내역을 살펴보니 board_seq 라는 테이블이 생성되어 있었다.
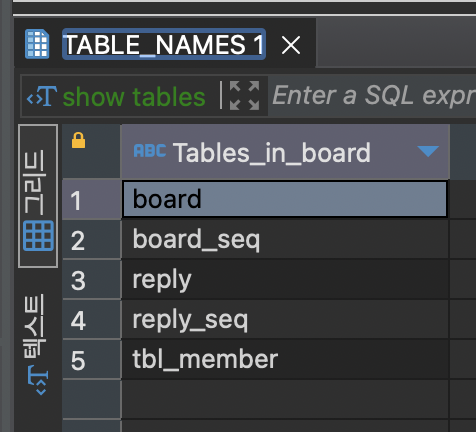

또한 서버 콘솔에서도 board_seq 기본 키 테이블의 생성 구문을 확인할 수 있었다.

GenerationType.IDENTIFY 옵션을 사용하자.
결국 의도했던 대로 기본 키를 순서대로 늘려가려면 GenerationType.AUTO 옵션이 아닌 GenerationType.IDENTIFY 옵션을 사용해야 했다.
public class Board extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
...
}위와 같이 Board Entity의 @GeneratedValue 어노테이션 옵션 값을 GenerationType.IDENTITY로 수정하고 다시 게시글 등록을 테스트하였다.
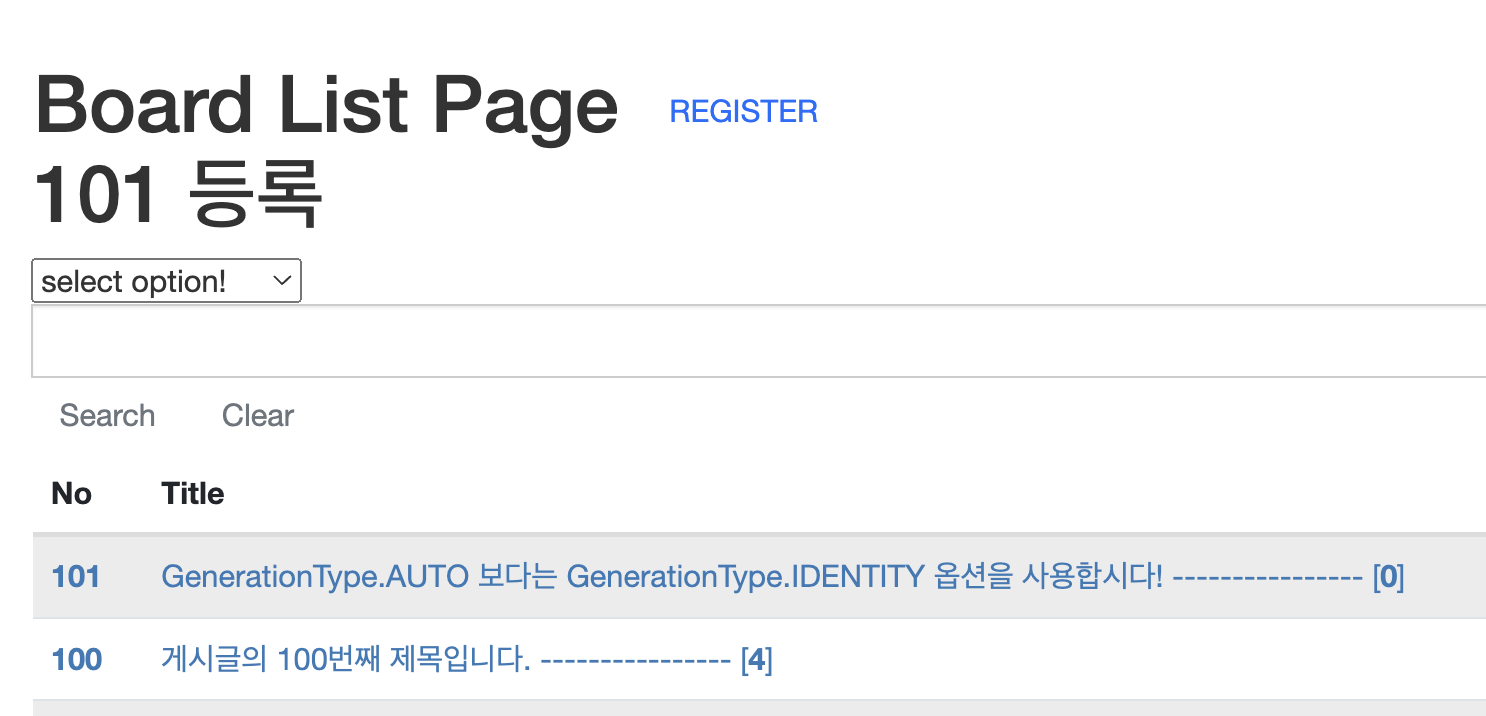
원했던 대로 100의 다음인 101이라는 기본 키 값이 잘 지정된 것을 확인할 수 있었다. 이로 인해 기본 키 생성전략을 구성하는데 많이 고민해볼 수 있었고 무엇보다 Table과 Entity의 설계가 중요하다고 느끼게 되었다.
Final..
이번주는 Spring Boot 2 버전과 3 버전을 활용한 실습 프로젝트 위주의 교육과정이 진행되었다.
Intro에서 언급했듯이 남의 코드를 복사, 붙여넣기 하는 코딩을 하였지만 복사, 붙여넣기에서 끝나지 않고 해당 코드를 어떻게 리팩토링하고, 어떤 것이 레거시한 것인지 고민하는 시간을 덧붙이니 하루하루가 너무 빠르게 지나갔다.
Spring Boot 프로젝트를 통해 화면 구성은 Thymeleaf 템플릿 엔진을 주로 사용했고, DB 연동은 Spring Data JPA와 Querydsl을 활용해보았다.
배운 내용을 통해 간단한 CRUD 게시판을 구성하는데 삽입이나 수정 삭제의 경우는 크게 어려움이 없었지만 게시글을 조회하거나 검색 기능을 구현할 때는 생각만큼 쉽지 않다고 느꼈다. 그렇지만 어려운만큼 궁금하거나 모르는 부분에 대해서 흥미롭게 배우고 적용해보는 시간이 귀했다.
다음주에는 Spring을 배우는 마지막 주간이다. 정말 2주만에 Spring을 끝낸다는 것이 너무 아쉽지만 개인적으로도 꾸준히 스프링에 대한 학습은 이어나갈 계획이다.
혹여 잘못된 내용이 있다면 지적해주시면 정정하도록 하겠습니다.게시물과 관련된 소스코드는 Github Repository에서 확인할 수 있습니다.
참고자료 출처
