🌳Random Forest
제목
Random Forest을 클릭하면 더 상세한 설명을 볼 수 있습니다.
출처: R을 이용한 자료분석 - 위키독스
랜덤 포레스트는 배깅(Bagging, Bootstrap Aggregating) 기법을 기반으로 동작하며, 여러 개의 결정 트리를 학습하여 투표(voting) 방식으로 최종 예측값을 결정하는 알고리즘
📌 핵심 원리
데이터 샘플링 (Bootstrap Sampling)
원본 데이터에서 중복을 허용하는 방식으로 여러 개의 샘플을 랜덤하게 선택하여 각 결정 트리의 훈련 데이터셋을 만듭니다.
이를 통해 개별 트리들이 서로 다른 데이터셋으로 학습하게 되어 모델의 다양성을 증가시킵니다.
특성 랜덤 선택 (Feature Randomness)
각 트리를 학습할 때, 모든 특성을 사용하지 않고 랜덤하게 선택된 일부 특성(feature)만 고려하여 분할을 수행합니다.
이렇게 하면 개별 트리들이 서로 다른 특성에 집중하도록 유도할 수 있습니다.
다수결 투표 (Majority Voting, 분류 문제)
여러 개의 트리들이 독립적으로 예측을 수행한 후, 가장 많이 예측된 클래스를 최종 예측값으로 결정합니다.
평균 결정 (Averaging, 회귀 문제)
회귀 문제에서는 각 트리의 예측값을 평균 내어 최종 예측값을 결정합니다.
⚡ 랜덤 포레스트의 장점
✔ 과적합 방지: 여러 개의 트리를 결합하여 과적합을 줄이고 일반화 성능을 향상시킵니다.
✔ 높은 예측 성능: 단일 결정 트리보다 높은 정확도를 가지며, 특히 데이터가 크거나 특성이 많을 때 효과적입니다.
✔ 이상치(Outlier)와 결측치(Missing Value)에 강함: 일부 데이터가 이상치거나 결측값을 포함하더라도 랜덤 포레스트는 안정적으로 동작합니다.
✔ 특성 중요도 제공: 각 특성이 예측에 얼마나 중요한지 평가할 수 있어 해석이 용이합니다.
❌ 랜덤 포레스트의 단점
✖ 메모리 사용량이 많음: 여러 개의 트리를 학습해야 하므로 계산 비용과 메모리 사용량이 증가합니다.
✖ 예측 속도가 느림: 새로운 데이터를 예측할 때 개별 트리들의 예측을 결합해야 하므로, 단일 결정 트리보다 속도가 느립니다.
✖ 설정할 하이퍼파라미터가 많음: 트리 개수(n_estimators), 최대 깊이(max_depth), 최소 샘플 수(min_samples_split) 등 다양한 하이퍼파라미터를 조정해야 합니다.
🔧 하이퍼파라미터 튜닝
랜덤 포레스트의 성능을 최적화-> 몇 가지 주요 하이퍼파라미터 조정

하이퍼파라미터 최적화를 위해 GridSearchCV, RandomizedSearchCV 등의 기법을 사용
🔥 랜덤 포레스트 vs 결정 트리 vs 다른 앙상블 모델
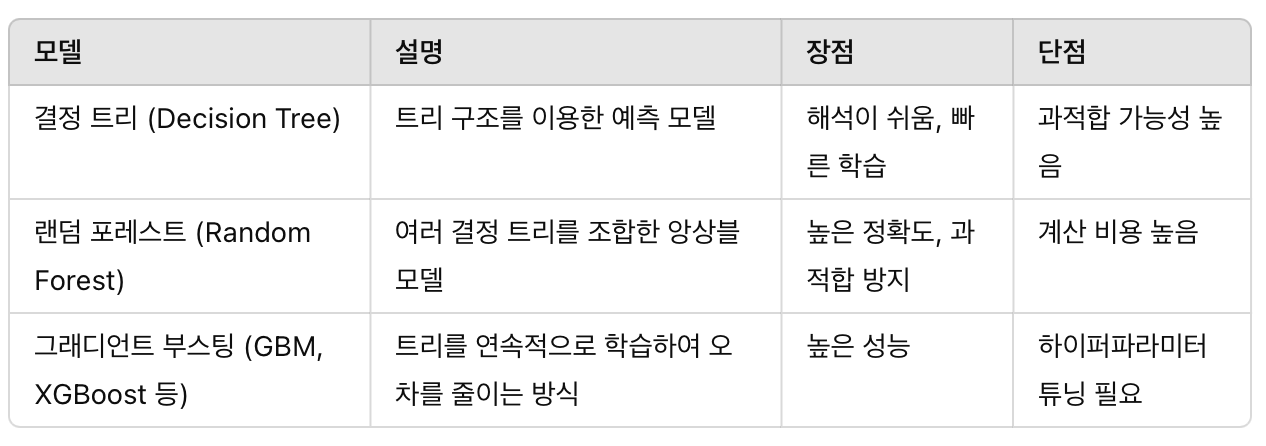
✅ 결론
랜덤 포레스트는 강력한 앙상블 학습 기법으로, 데이터가 복잡하거나 다차원일 때 높은 성능을 발휘하는 모델
하지만 트리 개수가 많아지면 계산량이 증가하므로, 적절한 하이퍼파라미터 튜닝이 필요
사용 목적(예: 이상 탐지, 이미지 분류, 텍스트 분류 등)에 따라 적절한 설정을 하면 효과적인 결과를 얻을 수 있음
특히, 부정 거래 탐지(예: 부동산 사기 탐지) 같은 문제에서는 랜덤 포레스트가 유용