[PR | 22-08] data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
SSL

0. Abstract
Self-supervised learning 의 일반적인 아이디어는 다양한 모달리티에 동일하게 적용될 수 있지만, 실제로 알고리즘과 objective 는 모달리티마다 달랐다. 그래서 본 논문에서는 Speech, NLP, CV 에서 같은 학습 방법을 쓸 수 있는 하나의 프레임워크, data2vec 을 제안한다.
- The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup.
- Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input.
2. Related work
data2vec은 BYOL, DINO 처럼 student-teacher 모델이지만 masked prediction objective 를 가지는 self-supervised model 이다. 이 때 target representation 은 contextualized 되어있다.
-> data2vec 에 대한 나의 짧은 요약!
-
Momentum encoder 를 이용한 모델 (BYOL, DINO) 과의 차이점
(1) use a masked prediction task
(2) regress multiple neural network layer representations instead of just the top layer which we find to be more effective.
(3) Moreover, data2vec works for multiple modalities. -
Vision Transformers with masked prediction objectives predict visual tokens or the input pixels. Instead:
(1) data2vec predicts the latent representations of the input data.
(2) The latent target representations are contextualized, incorporating relevant features from the entire image instead of targets which contain information isolated to the current patch, such as visual tokens or pixels
3. Method
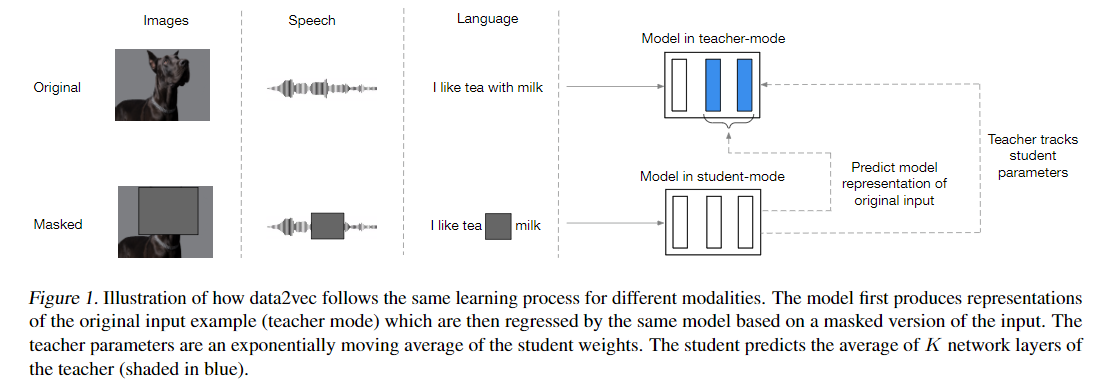
Contrastive learning 방식이 아니라, masked auto-encoding 방식으로 학습하는데 타겟이 teacher 의 output 이다. 이는 transformer 의 아웃풋으로 contextualized representation 이다.
학습 방법을 요약하면, student model 의 masked representation 와 teacher model 의 output 인 unmasked representation 와 smooth l1 loss 를 계산해서 student model 학습시키고, teacher model 은 student model 의 파라미터에 대해 ema 방식으로 학습된다.
Model architecture
모든 모달리티에 대해서 Transformer 구조를 사용하지만 input data 를 인코딩하는 방식은 기존의 modality-specific 한 방법을 써야한다:
- Computer vision: ViT-strategy of encoding an image
- Speech: Multi-layer 1D CNN
- Text: sub-word units & learned lut
Masking
- Computer vision: block-wise masking strategy (BEiT)
- Speech: mask spans of latent
- Text: mask tokens
Training targets
-
모델은 masked sample 인코딩을 보고 원래의 unmasked rerpesentation 을 예측한다
-
예측하는 representation 은 time-step 뿐만 아니라 self-attention 으로 인해 샘플의 모든 정보를 담을 수 있는 contextualized representation 이다. (This is an important difference to BERT, wav2vec 2.0 or BEiT, MAE which predict targets lacking contextual information.)
-
Teacher parameterization: EMA
-
Targets
- Apply a normalization to each block to obtain
- Average top K blocks for time-step
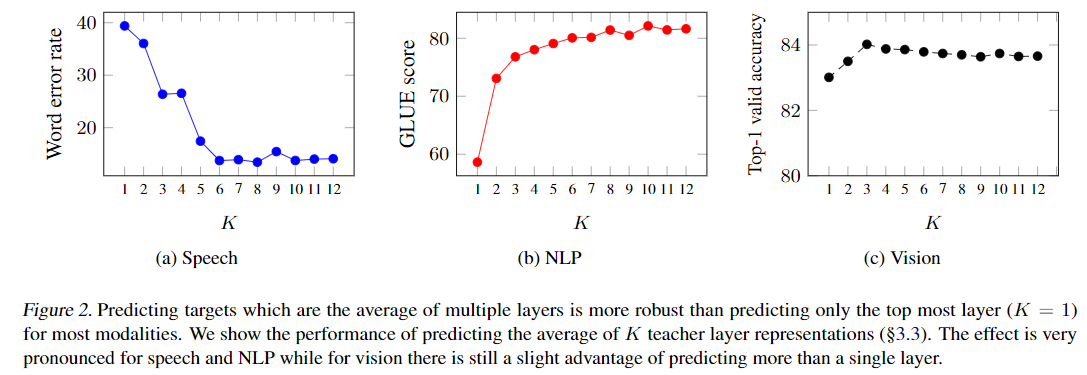
- Normalizing the targets helps
(1) prevent the model from collapsing into a constant representation for all time-steps
(2) prevents layers with high norm to dominate the target features. - Computer vision: We use the same modified image both in teacher mode and student mode.
Objective: Smooth L1 loss
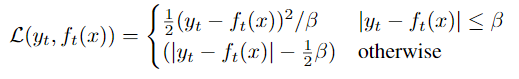
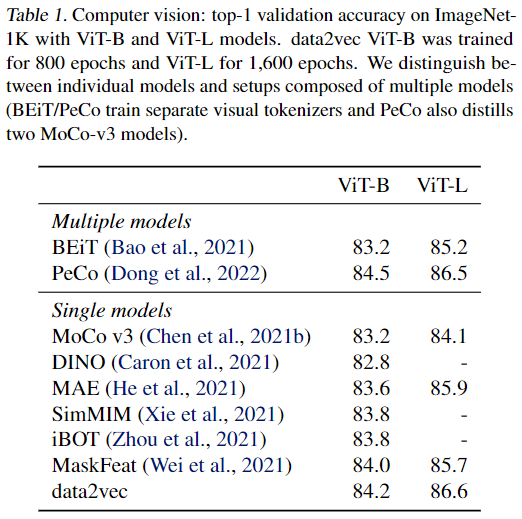
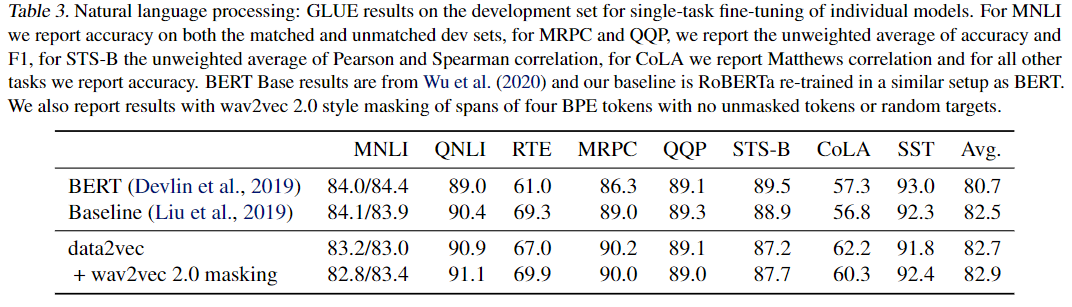
5. Results