Class
class 클래스_이름:
클래스_변수 = '값'
# 생성자를 통한 변수 초기화
def __init__(self, 초기값):
self.초기값 = 초기값
# 메소드 == 함수
def 메소드_이름(self):
return self.초기값
객체 = 클래스_이름('초기값')
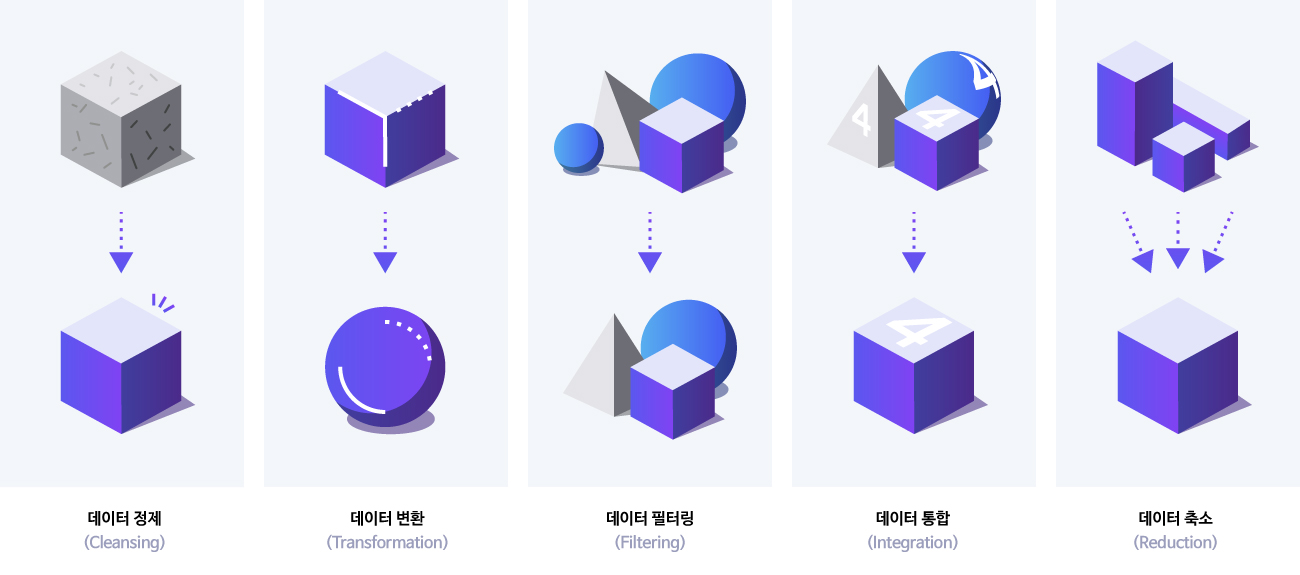
객체.새로운_값 = '새값'데이터 전처리
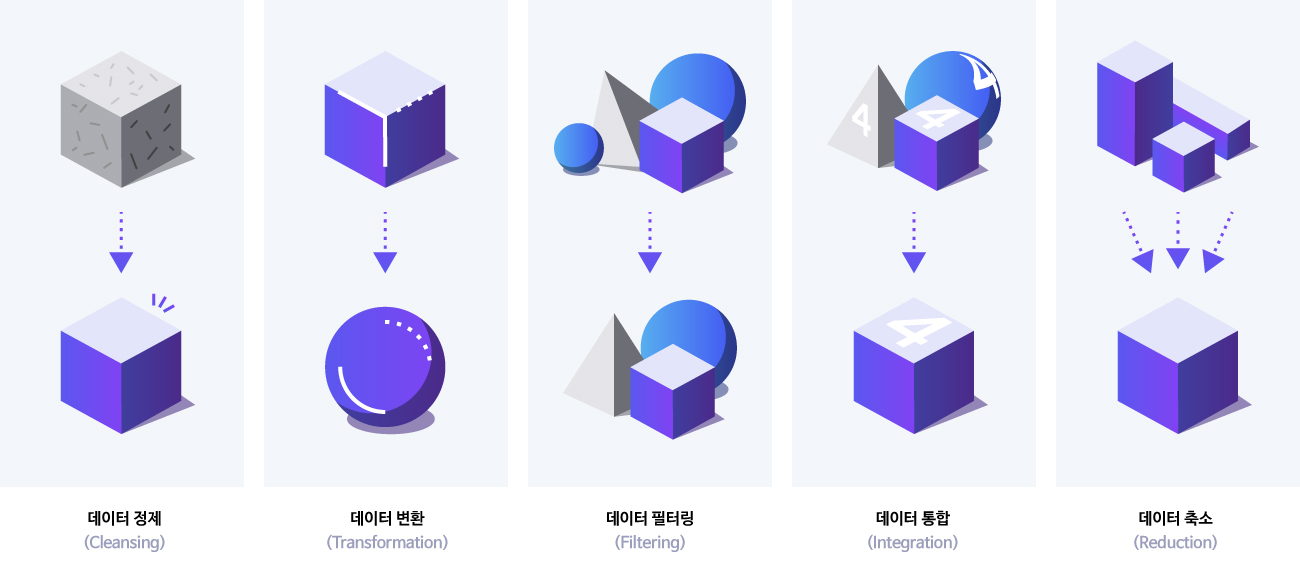

- 누락, 오차, 형태에 맞지 않는 값 == 문제가 있음
- 해결해야 함
데이터 정제(클리닝)
중복 데이터 제거
- 완벽하게 동일한 데이터 제거
- 한 사람이 동일한 기계에 동일 시간에 연속 결제가 불가능함
관련없는 데이터 삭제
- 목표 분석에 맞는 값만 사용
- 날씨와 아이스크림 판매량 분석에서 구매자 정보는 불필요
구조적 문제 수정
- NA 표기 통일
- NaN, None, nana, NAN, NA, N/A, NA!, 엑셀 빈 값, !VALUE
이상치(outlier) 처리
- 데이터 조작이 되지 않도록 함
- 종류
- 통계 기반
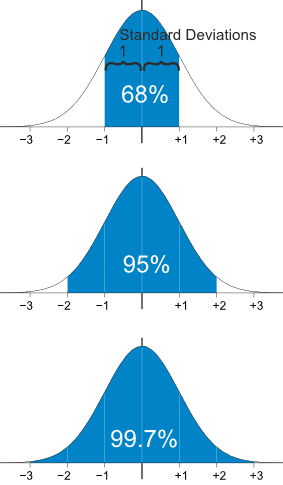
- 표준편차 95%를 넘김
- IQR 기반
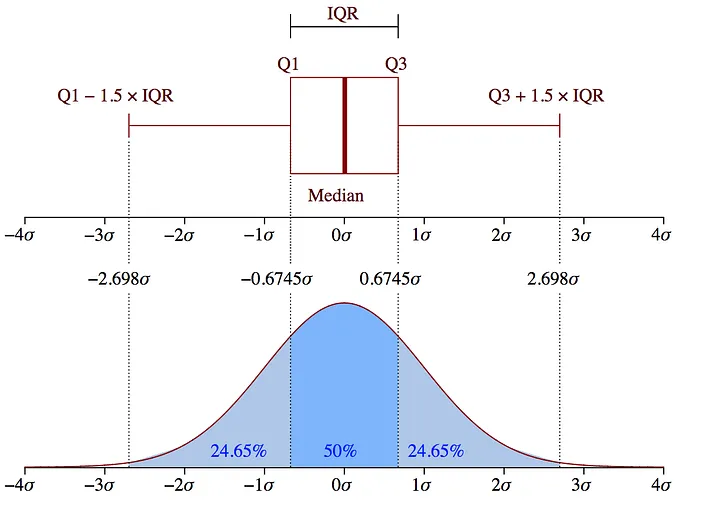
- Q - 1.5 IQR ~ Q3 + 1.5 IQR을 제외한 나머지
- IForest 기반 https://miro.medium.com/v2/resize:fit:1400/0*GtndbJ4s7R2o7wqU
- DBSCAN 기반

- 통계 기반
- 누락(NA) 데이터 처리
- 데이터 조작이 되지 않도록 함
- col 제거(50% 이상)
- row 제거(10% 이하)
- 채우기
- 0, 평균, 중앙, 최빈 채우기
- 앞뒤 값으로 대치
- 조건부 대치
- ML 사용
- 수정된 데이터 평가(이전과 이후의 차이)
Parsing(파싱)
- csv, tsv, json, xml 등 다양한 데이터 형태가 존재함
- 형태가 달라도 데이터로 만들 수 있어야 함
- 위 데이터를 읽을 때 인코딩을 조심해야함
- cp949, euckr, utf8, utf16이 대다수
실습
데이터 활용
Sexcolumn을 삭제한 뒤 진행
import pandas as pd
df = pd.read_csv('test.csv')
df_org = df.copy()
df = df_org.drop('Sex', axis=1)
pd.concat([df.head(), df.sample(5), df.tail()])Name으로Sex을 파악한 뒤,Sexcolumn에 등록
# 중간 이름에 성별을 구분할 수 있는 단어가 존재함
df['Sex'] = df['Name'].apply(lambda row : row.split(',')[1].split(' ')[1])
' '.join(df['Sex'].value_counts().index)
# Mr. Miss. Mrs. Master. Col. Rev. Ms. Dr. Dona.
# 남자 : Mr.(미혼, 기혼 남성) Col.(대령) Rev.(목사) Dr.(의사)
# 여자 : Miss.(미혼) Mrs.(기혼) Ms.(미혼, 기혼 여성) Dona.(귀부인)
# 알수 없음 : Master
change = {
'Mr.' : 'male',
'Miss.' : 'female',
'Mrs.' : 'female',
'Master.' : None,
'Col.' : 'male',
'Rev.' : 'male',
'Ms.' : 'female',
'Dr.' : 'male',
'Dona.' : 'female'
}
df.replace({'Sex':change}, inplace=True)Age항목의 결측치를 파악해 아래 중 하나 수행-
결측치를
0으로 대체 (fillna 함수 이용 가능)df['Age'].fillna(0) -
전체 값의
평균으로 대체 (mean 함수 이용 가능)df['Age'].fillna(df['Age'].mean()) -
중앙값으로 대체 (median 함수 이용 가능)df['Age'].fillna(df['Age'].median()) -
변화 확인
import matplotlib.pyplot as plt plot_num = len(datas) fig, axes = plt.subplots(plot_num, 2, figsize = (8 * 2, plot_num * 8)) titles=['base', '0', 'mean', 'median'] for i in range(2): for j in range(plot_num): if i == 0: datas[j].plot.box(ax=axes[j][i]) else: datas[j].plot.hist(ax=axes[j][i]) axes[j][i].set_title(titles[j])
-
남성이며 나이가10대인사람을 O, 아닌 사람을 X로 표기해check column을 만들어 저장
df['check'] = (df['Sex'] == 'male') & (10 <= df['Age']) & (df['Age'] < 20)
df['check'].replace({True:'O', False:'X'}, inplace = True)
# 또는
query_expr = "Sex == 'male' and 10 <= Age < 20"
df['check'] = 'X'
df.loc[df.query(query_expr).index, 'check'] = 'O'- 해당 파일을 result.tsv 파일로 저장
df.to_csv('result.tsv', sep='\t')추가 문제
- sibsp와 fare와의 관계성이 있는지 확인해보기
df[['SibSp', 'Fare']].corr('spearman') df.plot.scatter(x='SibSp', y = 'Fare')- 상관관계 분석으로 관계성 확인
- embarked와 ticket 사이에 어떠한 관계가 있는지 확인해보기
df['Ticket'] = df['Ticket'].apply(lambda row : int(row.split()[-1])) df.plot.scatter(x='Embarked', y = 'Ticket') df.pivot_table('Ticket', 'Embarked', aggfunc=[np.min, np.mean, np.median, np.max])
JSON 데이터 활용
- json 파일을 복사하지 않고, 파이썬에서 코드로 불러오기
- pandas dataframe 형식을 이용
- 단순 파일 읽기를 이용
df = pd.read_json('한국산업기술평가관리원_지역발전정책용어사전_20220627.json')
# null = None
df.replace({'null': None}, inplace =True)- MZ세대 정보에 대한 참고자료문헌을 알아본다
print(
df.loc[
df['참고자료문헌'].str.contains('MZ세대').fillna(False),
'참고자료문헌'
].values[0]
)
# 또는
print(
df.loc[
df['정책용어'] == 'MZ세대',
'참고자료문헌'
].values[0]
)- 고령친화우수식품 정보의 해외사례를 알아본다
print(
df.loc[
df['정책용어'] == '고령친화우수식품',
'해외사례'
].values[0]
)- 인터넷 사이트를 참고한 정책용어를 알아본다
df.loc[df['참고자료문헌'].str.contains('http').fillna(False), '정책용어'].values
# 또는
df[['http' in i for i in df['참고자료문헌']]]- 생성배경이 모호한 정책용어들을 알아본다
df.loc[df['생성배경'].isnull(), '정책용어'].values- 고령화 정책 관련 자료를 모두 수집한다
idxs = df[df['용어설명'].fillna('').str.contains('고령')].index
for i in df.columns[1:]:
idxs = idxs | df[df[i].fillna('').str.contains('고령')].index
# 또는
df[df.apply(lambda col : col.str.contains('고령')).sum(axis=1) != 0]- 참고자료가 논문인 것들을 추려낸다
text = ' '.join(df['참고자료문헌'].fillna(''))
text_sorted = sorted(text)
from collections import Counter
cnt = Counter(text_sorted)
len(cnt)
for i in range(0, len(cnt), int(len(cnt) / 20)):
print('\t'.join(list(cnt.keys())[i:i + 20]))
print('\t'.join(map(str, list(cnt.values())[i:i + 20])))
print()
# 갈호 기준으로 추출
df[df['참고자료문헌'].str.contains('\(').fillna(False)]회고
- 데이터 전처리 시각자료를 확실하게 이해할 것
- 다양한 이상치 처리를 할 수 있도록 코드를 준비할 것
- 누락 데이터의 처리 기준이 중간일 때 어떻게 할지 생각할 것
Ref
- 05-1 클래스 - 점프 투 파이썬
- 34.1 클래스와 메서드 만들기 - 코딩도장
- 현대로템의 빅데이터 전처리 기술 - 현대로템
- 데이터 전처리란? – 데이터 전처리 정의, 작업 단계, 순서 - 모두의연구소
- 데이터 이상치(Outlier)의 기준은 무엇일까? - Medium
- Titanic - Machine Learning from Disaster - kaggle
- 데이터 자료 형태에 따른 상관분석 방법 - blog
- 한국산업기술평가관리원_지역발전정책용어사전 - 공공데이터포털

DA DE DS
꼼꼼한 정리 잘 봤습니다~! 블로그 챌린지의 새로 안내드린 태그도 같이 입력해주시면 저 제니아는 더 큰 감동을 받을 것 같아요...(●'◡'●) 2월의 마지막도 3월의 시작도 화이팅입니다!!! ^^