Abstract
이 논문은 대형 VLM을 그대로 자율주행에 쓰면 GPU 메모리 사용량과 latency가 너무 크고, 반대로 작은 모델을 단순 SFT (Supervised Fine-Tuning) 만으로 학습하면 capability gap이 잘 안 메워진다는 문제에서 출발함
이를 해결하기 위해 저자들은 자율주행을 perception, reasoning, planning의 순차적 triad로 분해하고, 각 capability별로 적절한 distillation signal을 고른 뒤, 이를 multi-teacher distillation으로 통합
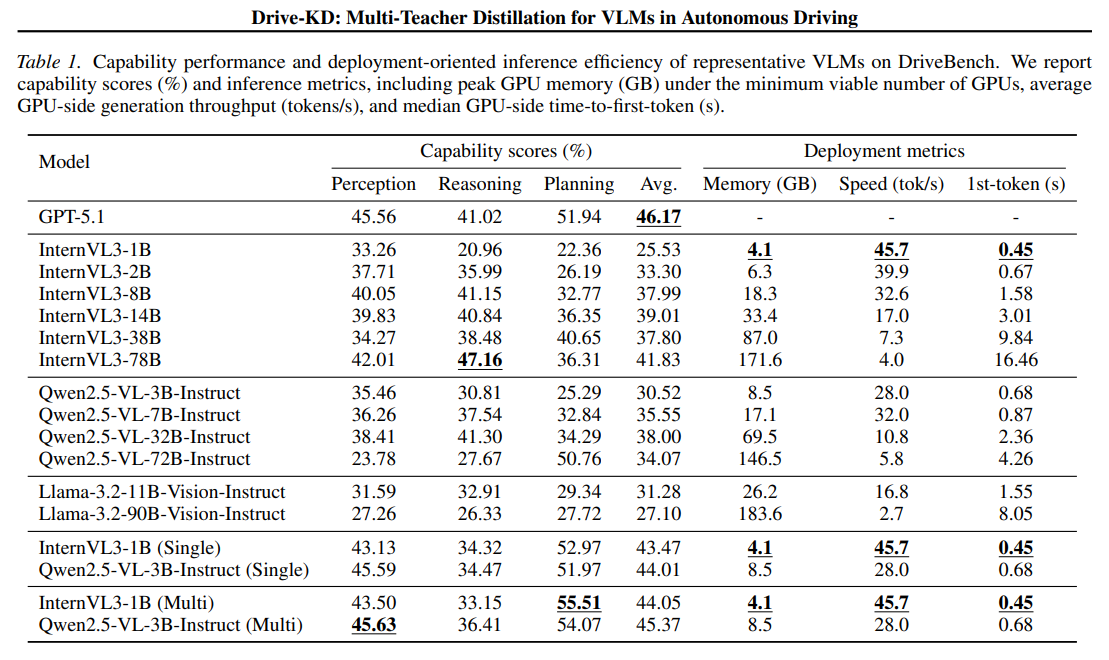
최종적으로 distilled InternVL3-1B는 같은 계열의 pretrained 78B 모델보다 DriveBench 평균 성능이 좋고, planning에서는 GPT-5.1도 넘는 결과를 보임
1. Introduction
서론에서는 기존 자율주행 방식의 두 축인 modular pipeline과 end-to-end learning을 짚음
모듈식은 stage 간 error accumulation 문제가 있고, end-to-end는 해석이 어렵고 복잡한 환경에서 brittle할 수 있다는 점을 강조함
저자들은 최근 LLM/VLM이 reasoning과 world knowledge를 제공해 자율주행에 유망하지만, 여전히 신뢰성·실시간성 문제가 있고, distillation 연구도 “어디를, 무엇으로, 어떻게” distill할지에 대한 원칙이 부족하다고 봄
그래서 이 논문의 기여는 단순히 KD를 적용한 것이 아니라, capability별 distillation 원리와 multi-teacher optimization 원리까지 체계화 함
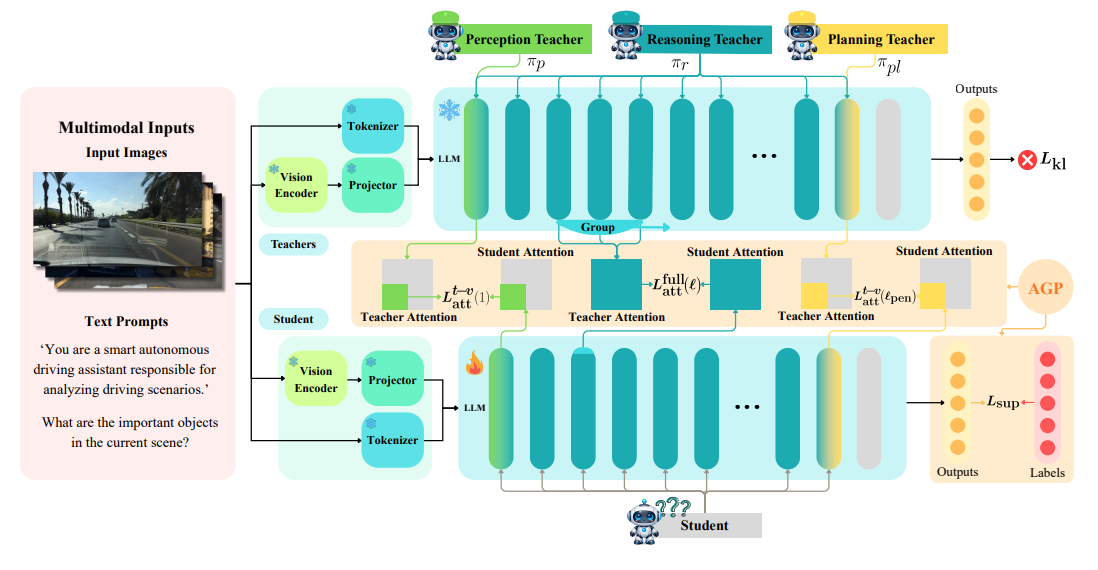
Figure 1
Drive-KD multi-teacher distillation framework.
세 개의 teacher가 student의 서로 다른 layer에서 attention을 distill한다. Perception과 Planning은 각각 첫 번째 layer와 마지막 바로 전 layer(penultimate layer) 의 cross-modal attention을 사용하고, Reasoning은 grouped-matching intermediate-layer full attention을 사용한다. 또한 student는 출력에서 hard-label supervision으로도 학습된다. 우리는 capability 간 gradient 충돌을 완화하기 위해 AGP를 적용한다.
2. Related Work
2.1 LLM/VLM in Autonomous Driving
이 섹션은 자율주행에서 VLM이 왜 자연스러운 선택인지 설명함
scene description, VQA, multi-step reasoning 같은 일반 VLM 능력이 자율주행 perception·reasoning·decision에 잘 맞기 때문
다만 기존 자율주행 VLM들은 hallucination, unstable decision-making, poor real-time performance 문제를 여전히 안고 있음
2.2 Distillation for LLM/VLM
여기서는 KD가 원래는 output distribution 정렬 중심이었다가, 점점 hidden states, attention, cross-modal alignment 같은 richer internal signal 쪽으로 확장되어 옴
하지만 자율주행처럼 안전과 복합 reasoning이 중요한 도메인에서는, 어떤 신호를 어떤 레이어에서 distill해야 하는지가 아직 불명확하다는 점을 논문의 출발점으로 둠
3. Methodology
3.1 Preliminary
저자들은 자율주행 능력을 perception → reasoning → planning의 순차적 구조로 봄
perception은 장면의 semantic cue를 파악하고, reasoning은 그 cue들 사이의 관계와 제약을 해석하며, planning은 이를 바탕으로 안전한 행동을 결정함
즉, 세 능력을 병렬 task가 아니라 의존 관계가 있는 순차적 capability로 보는 게 이 논문의 출발점
3.2 Distillation Signal Selection
저자들은 먼저 어느 레이어에서 distill할지를 찾기 위해, 인접 레이어 hidden state 유사도와 vision–text 유사도를 분석하고, capability별 intra-consistency도 같이 살펴봄
-
그 결과 perception은 Layer 1, planning은 penultimate layer, reasoning은 넓은 intermediate layers가 가장 적절하다고 결론냄
-
또한 무엇을 distill할지에 대해서는 hidden state보다 attention이 더 stable 하다고 봄
동일 이미지에 대해 질문 표현만 바꿔도 hidden state는 더 크게 흔들리지만, attention map은 capability-stable behavior를 더 잘 유지함
반대로, output-level KL alignment는 driving answer의 분포가 일반 QA보다 더 diffuse하고 confidence가 낮아서 noisy signal이 되기 쉽다고 판단 → 그래서 최종적으로는 attention distillation 중심 설계를 채택함
다음은 핵심 수식을 논문 흐름대로 간단히 정리함
여기서 는 Layer 1의 text-to-vision attention distillation, 는 intermediate-layer group matching attention distillation, 는 penultimate-layer text-to-vision attention distillation에 해당함
즉, capability마다 다른 레이어·다른 attention target을 쓰는 것이 포인트
3.3 Single-Teacher Distillation
single-teacher 단계에서는 hard-label supervised loss 위에 capability-specific attention distillation loss 를 얹음
perception은 Layer 1의 text-to-vision attention, reasoning은 intermediate layers에서 teacher-group 평균 attention, planning은 penultimate layer의 text-to-vision attention 을 맞추는 recipe를 사용함
즉, “한 teacher가 모든 걸 다 가르친다”가 아니라, capability별로 가장 잘 맞는 내부 attention recipe를 따로 설계함
3.4 Multi-Teacher Distillation
그 다음 이 single-teacher recipe들을 하나의 multi-teacher framework로 합침
각 batch의 capability에 대해 세 teacher의 loss를 mixing weight 로 섞고, hard-label supervision과 함께 최종 loss를 구성함 → 핵심은 각 capability 전용 teacher를 유지하되, 다른 teacher 신호도 완전히 버리지 않는다는 점
여기서 가장 중요한 장치가 AGP(Asymmetric Gradient Projection) : Stage 1에서는 supervised gradient를 anchor로 두고, distillation gradient를 follower로 두어 둘이 충돌할 때 follower의 anchor 방향 성분만 제거, Stage 2에서는 capability별로 합쳐진 gradient들 사이에서 shuffled symmetric projection을 적용해, 특정 capability가 다른 capability를 과도하게 망가뜨리지 않게 함 → 쉽게 말하면, CE가 기본 축을 잡고, KD가 그 축을 거스르는 부분만 잘라내는 구조
핵심 projection 식은 아래와 같음
즉, supervised gradient와 충돌하는 soft distillation 방향만 제거하고, 이후 capability 간 projection을 한 번 더 해서 최종 update를 만듬
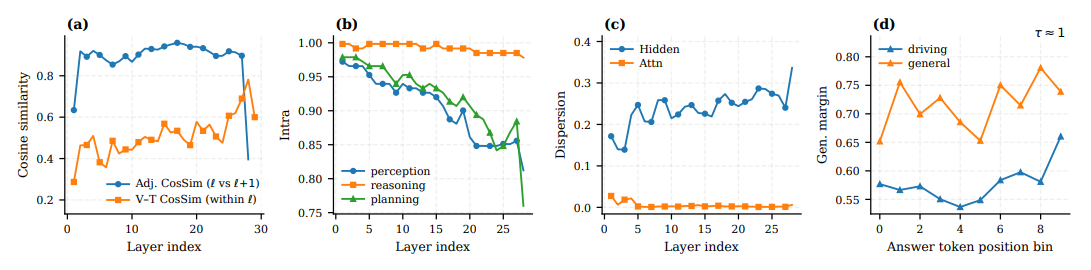
Figure 2
nternVL3-8B에 대한 사전 분석 요약
(a) cosine similarity를 이용해 측정한 레이어별 증류 정렬 정도(인접 레이어 간 유사도와 동일 레이어 내 vision–text 유사도),
(b) 각 능력별로 레이어 전반에 걸친 그룹 내부 유사도,
(c) hidden state와 attention map의 레이어별 분산 정도 (1 − cos),
(d) 답변 구간을 따라 위치 정규화된 generalized margin으로, τ ≈ 1.0일 때 주행 데이터와 일반 데이터를 비교한 결과를 의미합니다.
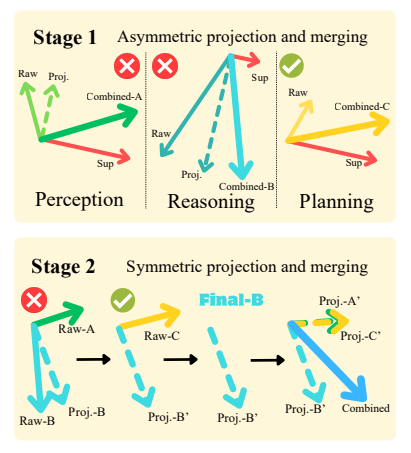
Figure 3
Asymmetric Gradient Projection (AGP) 는, Stage 1에서 각 capability 내부에 대해 비대칭적인(asymmetric) anchor–follower projection을 사용하고, 그렇게 얻어진 업데이트들을 합친다.
그리고 Stage 2에서는 capability들 사이에서 순서를 섞은(shuffled) 대칭적인(symmetric) pairwise projection을 적용하여 최종 gradient 방향을 얻는다. (그림에서는 예시로 gradient B가 표시되어 있다.)
4. Experiments
4.1 Experimental Setup
실험은 10k human-annotated driving distillation dataset 으로 수행되며, single-view와 multi-view VQA를 포함
주요 teacher-student 쌍은 InternVL3-8B → InternVL3-1B, Qwen2.5-VL-7B-Instruct → Qwen2.5-VL-3B-Instruct 이고, 평가는 DriveBench에서 수행함
reasoning 평가는 DriveBench의 prediction과 behavior dimension을 합쳐 보고, evaluator로는 DeepSeek-V3.2를 사용
4.2 Single-Teacher Evaluation
single-teacher만으로도 성능 향상이 매우 큼
InternVL3-1B는 평균 점수가 25.53 → 43.47, Qwen2.5-VL-3B-Instruct는 30.52 → 44.01로 크게 오름
planning은 각각 52.97, 51.97까지 올라 GPT-5.1의 planning 점수 51.94와 비슷하거나 더 좋음
저자들은 이를 통해 작은 모델에도 internal attention signal distillation이 driving behavior transfer에 효과적이라고 주장
4.3 Multi-Teacher Evaluation
multi-teacher로 가면 planning이 특히 더 좋아짐
InternVL3-1B는 Avg가 43.47 → 44.05, planning이 52.97 → 55.51로 올라감
perception은 거의 유지되고, reasoning은 비교적 민감하지만 overall로는 이득임, 효율 측면에서도 InternVL3-1B (Multi)는 4.1GB / 45.7 tok/s인데, pretrained InternVL3-78B는 171.6GB / 4.0 tok/s라서, 성능-효율 trade-off가 훨씬 나음
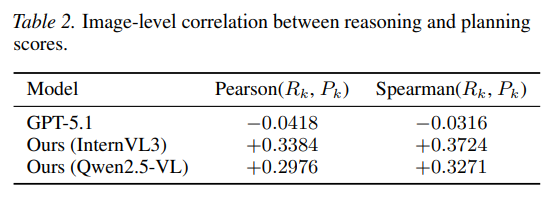
또 흥미로운 점은 reasoning이 높다고 planning도 자동으로 높은 것은 아니라는 분석
GPT-5.1은 reasoning 점수는 높지만 same-scene reasoning–planning correlation은 거의 0에 가깝고, Drive-KD Student 모델들은 약한 양의 상관을 보여 reasoning과 planning의 연결이 더 일관적이라고 해석함
즉, 이 논문은 planning 점수만 올린 게 아니라 reasoning-to-planning mapping도 정렬시키려는 관점이 있음
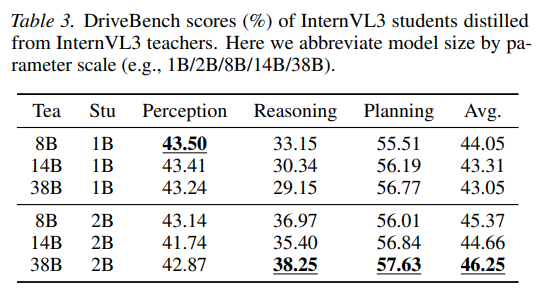
4.4 Distillation Scaling Across Model Sizes
teacher를 크게 한다고 항상 좋은 것은 아님 → 같은 student라도 teacher 크기에 따라 perception, reasoning, planning이 서로 다르게 반응하고, best teacher size는 student capacity에 따라 달라짐
반면 student가 더 큰 경우에는 전반적으로 더 잘 흡수함
예를 들어 2B student는 1B student보다 일관되게 더 강하고, 38B → 2B 조합이 Avg 46.25로 가장 좋음, 저자들은 이를 통해 teacher strength보다 student absorptive capacity가 여전히 중요하다고 봄
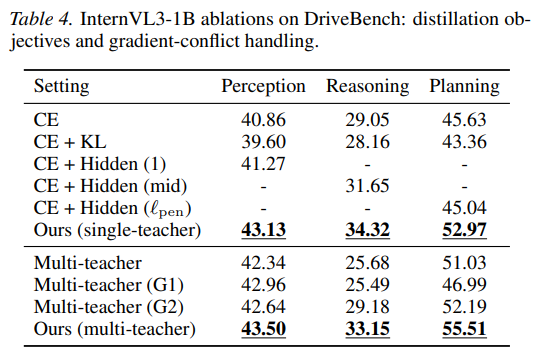
4.5 Ablation Study
CE + KL은 CE보다 오히려 나쁘고, hidden-state distillation도 저자들의 attention recipe보다 약함
multi-teacher를 그냥 돌리면 reasoning이 크게 깨지고, 단순 symmetric projection도 불안정, 반면 AGP를 넣은 최종 multi-teacher가 perception 43.50, reasoning 33.15, planning 55.51로 가장 균형이 좋음
즉, 이 논문의 이득은 단순 multi-teacher 때문이 아니라, capability-specific signal selection + AGP 조합에서 나온다고 볼 수 있음
5. Conclusion
자율주행 VLM distillation에서는 “모든 레이어, 모든 신호를 다 맞추는 것”보다, capability별로 맞는 attention signal을 골라 distill하는 것이 훨씬 중요함
perception은 Layer 1, reasoning은 intermediate layers, planning은 penultimate layer가 적합하고, hidden state보다 attention이 더 안정적이며, output KL은 driving 도메인에서 신뢰도가 낮다는 것이 최종 결론
실험적으로도 Drive-KD는 작은 모델에서 매우 강한 efficiency–performance trade-off를 보여줌
