BehaviorGPT: Smart Agent Simulation for Autonomous Driving with Next-Patch Prediction 논문 요약
자율주행
Abstract
기존 스마트 에이전트 시뮬레이터는 대체로 과거를 인코딩하고 미래를 디코딩하는 encoder-decoder 구조를 쓰는데, 저자들은 이 방식이 구조를 복잡하게 만들고, history/future를 인위적으로 나누기 때문에 데이터 활용도도 낮다고 봄
그래서 모든 시점을 대칭적으로 다루는 fully autoregressive Transformer 를 제안
또 10Hz 단위의 next-token prediction은 현재 상태를 거의 복사하는 식의 쉬운 shortcut으로도 loss를 줄일 수 있으므로, 여러 time step을 묶은 patch를 예측하는 Patch Prediction Paradigm (NP3) 를 도입
논문은 3M 파라미터 규모로도 매우 경쟁력 있는 결과를 냈다고 주장함
1. Introduction
도입부에서는 왜 agent simulation이 중요한지 설명
실제 도로 테스트는 비싸고 위험 상황이 적기 때문에, 자율주행 시스템 검증을 위해서는 현실적인 시뮬레이션이 중요
기존 규칙 기반 시뮬레이터는 복잡한 상호작용을 충분히 표현하기 어렵고, 학습 기반 방식도 대부분 motion forecasting을 따라 encoder-decoder 패러다임을 사용해 왔음
-
저자들은 LLM의 decoder-only 구조에서 영감을 받아, trajectory 전체를 동일한 블록으로 처리하는 단순하고 효율적인 구조가 더 낫다고 주장함
-
또 token 단위 autoregressive 학습은 장기 상호작용 reasoning을 약하게 만들 수 있으므로, patch 단위 예측이 필요하다고 문제를 제기함
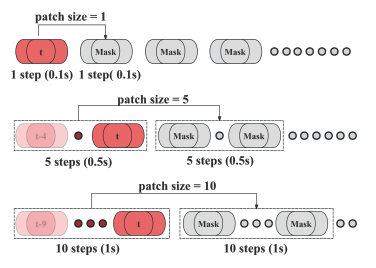
Figure 1
10Hz로 샘플링된 궤적에 대해, patch 크기를 각각 1, 5, 10 time step 으로 설정한 Next-Patch Prediction Paradigm 을 보여준다. 진한 빨간색 캡슐은 현재 시점 t 에서의 에이전트 상태를 나타내고, 흐릿한 빨간색 캡슐은과거 상태를 나타낸다. 회색 원은 생성을 위해 예측해야 하는 마스킹된 에이전트 상태를 의미한다. 우리 방법은 여러 시간 스텝에 걸친 에이전트 상태들을 하나의 patch 로 묶고, 학습 과정에서 각 patch가 그 다음 patch를 예측하도록 만든다.
2. Related Work
2.1 Multi-Agent Traffic Simulation
이 절에서는 기존 시뮬레이션 방법을 규칙 기반과 데이터 기반으로 나눠 설명함
최근에는 VAE, GAN, diffusion, autoregressive 기반 방법이 등장했고, 그중 autoregressive 모델이 시간 의존성을 자연스럽게 다룸
다만 MotionLM, Trajeglish 같은 대표 autoregressive 방식도 여전히 복잡한 scene encoder + decoder 구조를 사용함
→ BehaviorGPT는 여기서 더 나아가 완전 autoregressive decoder-only 구조를 택한 것이 차별점
2.2 Patching Operations in Transformers
이 절에서는 patch 개념이 왜 유효한지 정당화함
NLP에서는 subword, 비전에서는 image patch, 시계열에서는 local semantics 보존과 계산 효율 개선을 위해 patching이 쓰였듯이, agent simulation도 시계열 데이터이므로 patch를 쓰면 공간-시간 상호작용을 더 잘 잡을 수 있다고 연결
→ 즉, NP3는 자율주행 시뮬레이션에 patching을 본격적으로 도입한 설계
3. Methodology
3.1 Problem Formulation
이 논문은 각 agent의 trajectory를 길이 ℓ 인 patch로 나눔
여기서 는 agent 의 번째 trajectory patch
그리고 전체 multi-agent 상태 분포를 아래와 같이 time-axis를 따라 patch 단위로 분해함
그 다음 한 patch 안에서는 agent별로 조건부 독립이라고 가정
아래와 같이 factorize 할 수 있음
또 agent 행동의 multi-modality를 반영하기 위해 mixture model 을 둠
각 mode 안에서는 아래와 같이 patch 내부의 상태를 autoregressive하게 전개함
직관적으로는, 한 patch 동안은 행동 모드를 유지한 채 상태를 순차적으로 생성하는 구조임, 그래서 inference 때는 patch 길이 와 실제 replanning 빈도를 조절해 agent의 반응성을 바꿀 수 있음
3.2 Relative Spacetime Representation
기존 motion forecasting은 보통 한 시점을 기준으로 모든 것을 정렬하는 agent-centric/polyline-centric 표현을 많이 쓰는데, 이 논문은 모든 patch를 “현재 patch”처럼 대칭적으로 취급해야 하므로 그런 기준 시점 의존 표현이 비효율적이라고 봄
그래서 QCNet류의 relative spacetime representation을 사용하며, 두 요소 사이의 상대 임베딩은 다음처럼 정의함
즉, 절대 좌표보다는 거리, 방향, yaw 차이, 높이 차이, 시간 차이 같은 상대적 관계를 넣어줌, 이 표현 덕분에 시공간 관계를 더 일관되게 모델링할 수 있음
3.3 Map Tokenization and Agent Patching
맵은 polyline을 5m 간격 segment로 나누고 semantic category를 임베딩해 map token으로 만듬
agent 쪽은 각 state에서 속도, velocity 방향, bounding box 크기, agent type 등을 MLP로 feature화한 뒤, ℓ개의 연속된 상태를 attention으로 묶어 patch embedding을 만듬
즉 patch는 단순 concat이 아니라, patch 내부 시점들 사이의 관계까지 attention으로 묶어서 만든 고수준 토큰, 이것이 NP3의 입력 단위가 됨
3.4 Triple-Attention Transformer Decoder
이 부분이 모델의 핵심 구조, 저자들은 decoder 안에서 세 종류의 attention을 사용함
(1) Temporal self-attention
한 agent의 patch sequence 내부에서 과거 patch들을 causal mask로 참고하며 시간적 의존성을 모델링함
→ 즉 “이 agent가 지금까지 어떻게 움직였는가”를 patch 수준에서 봄
(2) Agent-map cross-attention
agent의 현재 patch가 주변 map 요소와 어떻게 관계되는지를 반영함, 맵 전체를 다 보지 않고 kNN으로 가까운 map segment만 골라 씀
→ 즉 도로 형상, 차선, 경계, 횡단보도 같은 환경 제약을 agent feature에 주입함
(3) Agent-agent self-attention
같은 시점의 다른 agent들과의 사회적 상호작용을 반영함
→ 결국 이 decoder는 시간 관계, 맵 관계, agent 간 관계를 순차적으로 결합해 다음 patch를 생성하기 좋은 feature를 만듬
3.5 Next-Patch Prediction Head
decoder가 만든 feature 를 받아, 저자들은 다음 patch의 mixture distribution을 예측함, 먼저 mode별 mixing coefficient 를 예측하고, 각 mode 안에서는 GRU 기반 RNN으로 patch 내부 상태를 step-by-step 전개함,
위치와 속도는 Laplace 분포 파라미터, yaw는 von Mises 분포 파라미터로 모델링함
핵심 식은 다음과 같음
여기서 중요한 점은 모델이 다음 한 스텝이 아니라 다음 patch 전체를 생성해야 하므로 더 긴 구간의 행동 semantics를 이해해야 함, 이게 NP3의 핵심 효과
3.6 Training Objective
학습은 전체 factorized distribution에 대한 negative log-likelihood 로 함
학습 시에는 teacher forcing으로 병렬화하되, patch 내부 RNN hidden state 업데이트에는 정답 상태를 그대로 넣지 않아 자기 예측 오류를 어느 정도 복구하도록 유도함
즉 학습 안정성과 autoregressive robustness를 같이 챙기려는 설계
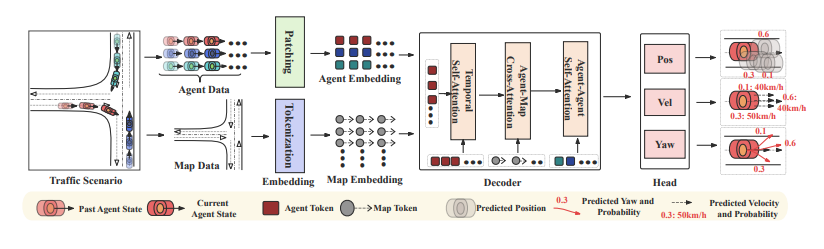
Figure 2
BehaviorGPT의 전체 개요를 보여준다. 이 모델은 에이전트의 궤적 정보와 지도 요소(map elements) 를 입력으로 받으며, 이들은 각각 trajectory patch 임베딩과 지도 polyline segment 임베딩으로 변환된다. 이렇게 얻어진 임베딩들은 Transformer decoder에 입력되어, next-patch prediction 기반의 자기회귀 모델링을 수행한다. 이 과정에서 모델은 trajectory patch에 해당하는 위치, 속도, yaw 각도를 생성하도록 학습된다.
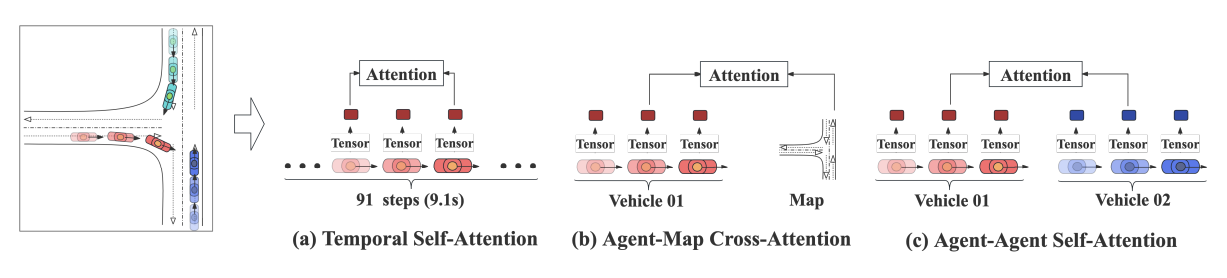
Figure 3
Triple Attention 은 attention 메커니즘을 적용하여 (a) 에이전트의 순차적인 행동, (b) 에이전트와 지도 맥락(map context) 사이의 관계, (c) 에이전트들 사이의 상호작용을 모델링한다.
4. Experiments
4.1 Dataset and Metrics
실험은 WOMD(Waymo Open Motion Dataset) 에서 수행, 각 시나리오는 91 step, 10Hz, 총 9.1초 길이이며, 초기 11 step을 주고 이후 80 step을 생성함
최대 128 agents를 시뮬레이션하고, agent마다 32개 simulation을 생성함, 평가지표는 minADE, 메타 지표인 REALISM, 그리고 속도/가속도/충돌/도로 이탈 등 세부 realism 지표들임
4.2 Implementation Details
최적 patch size는 10으로 설정했고, 이는 10Hz 기준 1초짜리 patch에 해당함, hidden size는 128, attention head는 8개, 각 head 차원은 16
최대 에이전트 수는 128, kNN neighbor 수는 32, prediction head는 16 modes를 출력
8개의 RTX 4090에서 30 epoch 학습했고, 2024 WOSAC 최종 리더보드 결과는 2Hz replanning 기준
4.3 Quantitative Results
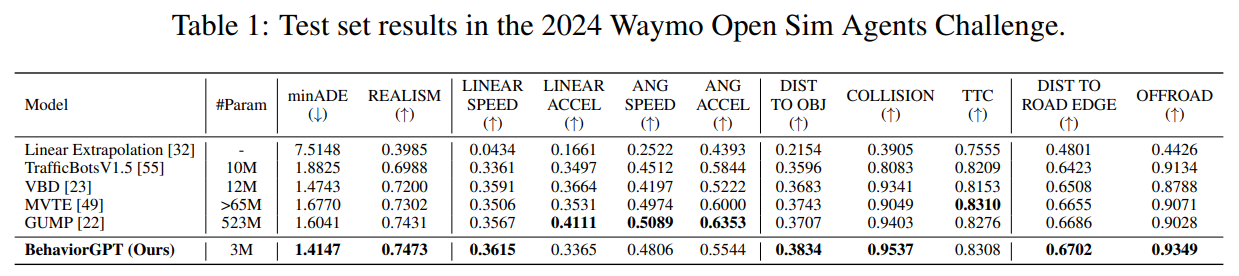
테스트셋에서 BehaviorGPT는 3M 파라미터로 minADE 1.4147, REALISM 0.7473를 기록했고, COLLISION 0.9537, OFFROAD 0.9349 등에서도 강한 성능을 보임
논문은 이 결과를 근거로, 훨씬 큰 모델들과 비교해도 파라미터 효율이 매우 높다고 주장함
또한 data augmentation, ensemble, post-processing 없이도 2024 Waymo Open Sim Agents Challenge 1위 달성
4.4 Qualitative Results
정성 결과에서는 같은 초기 상태에서 여러 개의 plausible한 미래 궤적을 만들어내며 multimodal behavior를 잘 보여줌
하지만 실패 사례도 제시하는데, autoregressive rollout이 길어지면서 오류가 누적되어 차량이 점점 도로 밖으로 나가는 경우가 나옴
즉 모델의 장점뿐 아니라 compounding error 문제가 여전히 남아 있음을 솔직히 보여줌
4.5 Ablation Studies
가장 중요한 ablation은 patch size, patch size 는 1보다 5가 크게 좋아지고, 10이 다시 더 좋아졌음
예를 들어 validation에서 patch size 1 → minADE 2.3752, REALISM 0.6783, patch size 10 → minADE 1.5203, REALISM 0.7335로 좋아짐, 저자들은 이를 통해 NP3가 장기 reasoning에 도움을 준다고 해석함

replan frequency도 흥미로움
patch size 10 모델에서 test set 기준 1Hz보다 2Hz가 더 좋고, 너무 높은 5Hz는 오히려 성능이 떨어짐
즉 큰 patch가 장기적 의미 이해에는 유리하지만, inference에서 적당한 replanning은 여전히 중요함

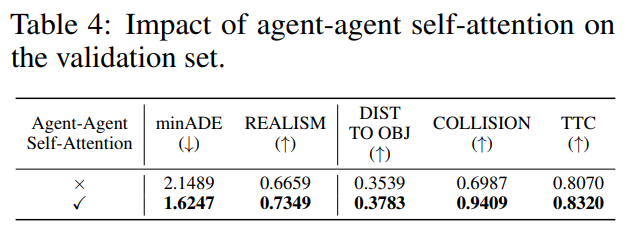
agent-agent self-attention 을 제거하면 성능이 크게 나빠짐
validation에서 collision realism이 0.6987 → 0.9409로 크게 올라가며, 논문은 이를 약 34.66% 개선으로 요약함, 즉 social interaction modeling이 핵심이라는 뜻
데이터 양과 모델 크기를 늘리면 성능도 꾸준히 좋아짐
5M 모델 기준으로 training data를 20%에서 100%로 늘리면 minADE가 1.4881 → 1.3804, REALISM이 0.7396 → 0.7438로 좋아짐, 또 depth를 2→4, width를 64→192로 키우면 전반적으로 성능이 향상됨
이는 구조가 단순해서 scaling law를 타기 좋은 모델이라는 해석이 가능함

마지막으로 extrapolation 실험에서는 5초 길이 시퀀스로 학습한 모델이 9.1초 생성에서도 거의 비슷한 성능을 냄, baseline이 minADE 1.6247 / REALISM 0.7349이고, 5초 학습 후 9.1초 생성은 1.6294 / 0.7333
즉 patch-level autoregression이 더 긴 rollout으로도 비교적 잘 일반화된다는 근거를 제공

5. Conclusion
결론적으로 이 논문은 decoder-only autoregressive 시뮬레이터를 제안했고, 이를 patch 단위 예측으로 강화해 데이터 효율, 파라미터 효율, 장기 상호작용 reasoning 을 함께 잡으려 했음
실험적으로도 성능이 매우 좋았고, 특히 소형 모델로 강한 realism을 얻었다는 점이 강점
Limitations
현재는 kinematics 관련 성능이 더 개선될 여지가 있고, language나 goal point 같은 controllable generation은 아직 지원하지 않으며, 이 모델이 motion planning 까지 직접 얼마나 기여할지는 앞으로 검증해야 한다고 말하고 있음
