AI Report
1. VLM(Vision-Language Model) 기술 현황 : CLIP에서 LLaVA까지

VLM(Vision-Language Model) 기술은 초기에는 이미지와 텍스트 간의 Representation Alignment에 초점을 맞췄어요. 대표적으로 CLIP은 이미지와 텍스트를 같은 벡터 공간에 매핑해 서로 잘 맞는 쌍을 찾는 데 강점이 있었죠. 이를 통해
2.머신러닝을 위한 '확률론'

머신러닝은 데이터를 바탕으로 패턴을 학습하고 예측을 수행하는 기술이에요. 이 기술들은 데이터에 숨겨진 구조를 발견하거나 미래를 예측하면서 세상의 복잡한 문제를 해결하려는 시도를 기반으로 발전해 왔습니다. 때문에 데이터를 제대로 다루고 활용하려면 그 이면에 있는 수학적
3. 머신러닝과 컴퓨터비전을 위한 '선형 대수'

선형대수는 머신러닝과 컴퓨터 비전에서 데이터를 표현하고 처리하는 데 필수적인 수학적 도구입니다. 이 장에서는 선형대수의 기초 개념과 연산을 정리하며, 각 개념이 AI/ML에서 어떻게 활용되는지 간단히 살펴보겠습니다.하나의 숫자를 나타내는 가장 기본적인 데이터 단위입니다
4.3D Computer Vision: SFM, SLAM, MVS 개념과 응용
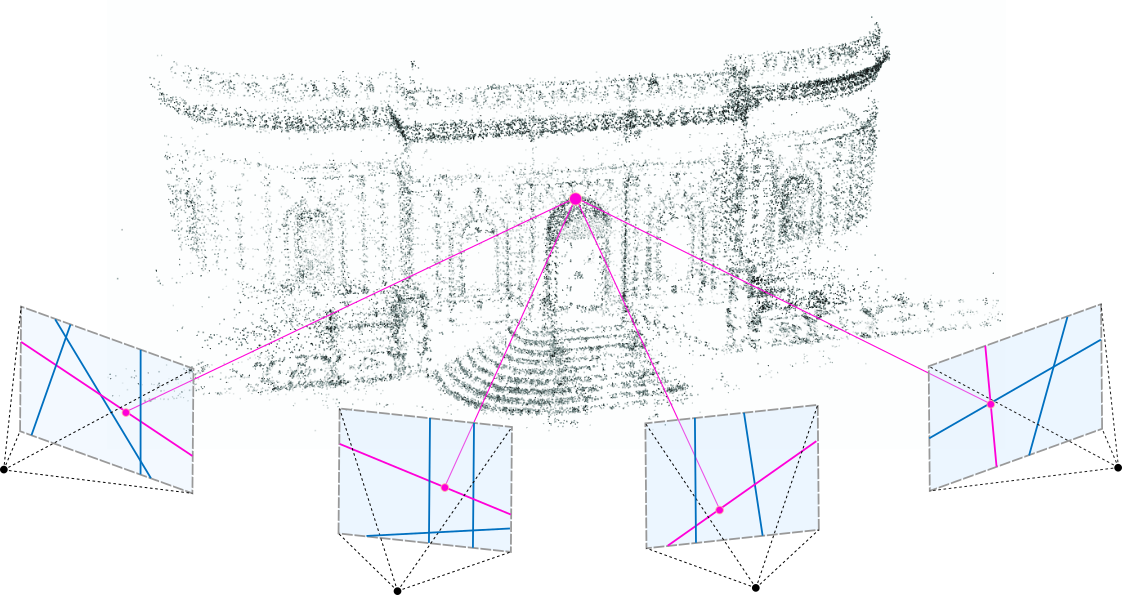
3D Computer Vision은 컴퓨터가 3차원 공간에서 사물을 인식하고 이해할 수 있게 하는 기술이에요. 간단히 말해, 2D 이미지나 비디오 데이터를 분석하여 3D 정보를 복원하거나 활용하는 분야를 의미하죠. 이 기술은 공간 컴퓨팅(Spatial Computing
5.정밀지도 생성을 위한 객체 검출 및 분할 기술의 발전
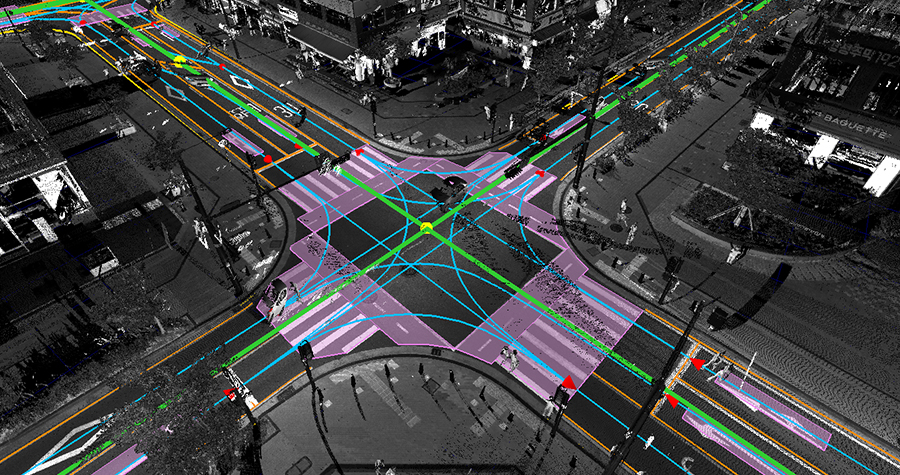
자율주행 기술이 상용화 단계에 접어들면서, 정밀지도(HD Map)는 단순한 길 안내용 지도가 아닌 차량의 '센서 보완 장치'로서 더욱 중요한 역할을 하게 되었다. 이러한 정밀지도는 도로 구조, 차선, 교차로, 신호 정보뿐 아니라 정적인 객체(건물, 표
6.Text-to-Video 기술: Stable Video Diffusion에서 Lumiere까지
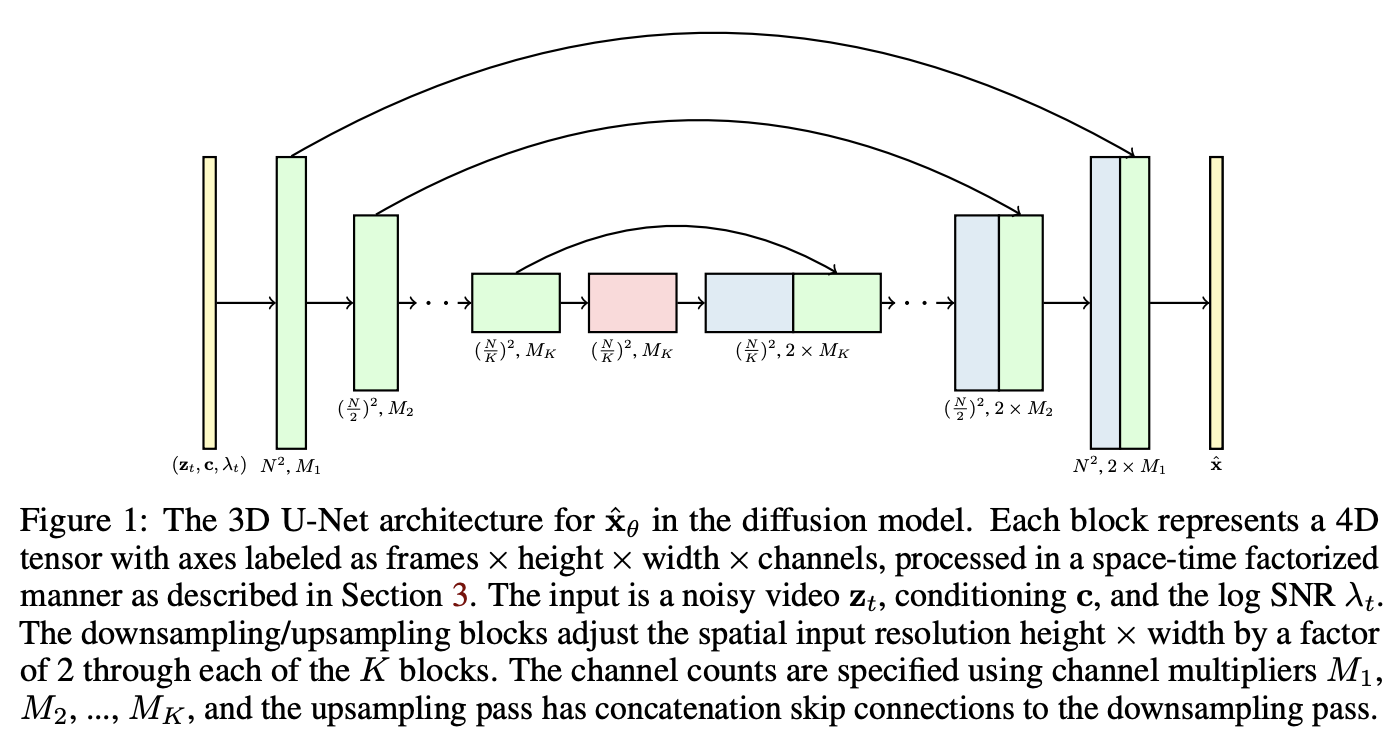
Diffusion 모델은 이미지 생성에서 이미 표준으로 자리잡았다. 최근에는 이 기술을 비디오로 확장하는 연구가 활발히 진행되고 있다. 하지만 비디오는 단순히 여러 이미지 프레임을 이어 붙이는 것이 아니라, 시간 축에서 자연스러운 움직임과 장면의 일관성을 유지해야 하기
7.Qwen-Image 테크니컬 리포트 분석

Qwen(Alibaba Cloud)에서 수준급의 오픈소스 이미지 생성 및 편집 모델을 공개하면서 화제가 되고 있다. 테크니컬 리포트가 함께 공개되었기에 살펴보고자 한다. 개인적으로는 데이터 수집 및 필터링 부분에 관심을 가지고 읽어봤다.Qwen은 새로운 이미지 생성 및