자율주행 기술이 상용화 단계에 접어들면서, 정밀지도(HD Map)는 단순한 길 안내용 지도가 아닌 차량의 '센서 보완 장치'로서 더욱 중요한 역할을 하게 되었다. 이러한 정밀지도는 도로 구조, 차선, 교차로, 신호 정보뿐 아니라 정적인 객체(건물, 표지판 등)의 위치와 속성까지 정밀하게 표현해야 하며, 이를 위해 핵심이 되는 인지 기술이 바로 객체 검출(Object Detection)과 시맨틱 분할(Semantic Segmentation)이다. 본 글에서는 2018년 이후의 기술 발전을 중심으로, BEV(Bird’s Eye View) 기반 접근과 통합 인지 모델, Polar 좌표계 변환을 통한 정합 향상, 멀티모달 센서 융합에 이르기까지의 주요 흐름을 논문 중심으로 소개한다. 더불어 정밀지도 생성에서 사용된 주요 BEV 기반 모델들의 발전사를 함께 살펴보며, 기술의 방향성과 실용화를 위한 시사점을 정리한다.
2025년 상반기에 작성된 글입니다.
1. 객체 검출(Object Detection): 2D에서 BEV 기반 통합으로
1.1 2D 기반 검출: 이미지 중심의 한계
2018년까지는 객체 검출의 주류는 2D 이미지 기반 방법이었다. YOLO, SSD, Faster R-CNN 등으로 대표되는 이러한 접근은 단일 카메라 또는 멀티 카메라의 RGB 이미지를 입력받아 차량, 보행자, 신호등 등 객체의 2D 바운딩 박스를 검출했다. 이후 LiDAR와의 Late Fusion을 통해 3D 위치를 추정하거나, 사전 보정된 카메라-라이다 보정 정보를 활용하여 투영 계산을 수행했다.
하지만 이러한 구조는 다음과 같은 한계를 지닌다.
- 카메라 시야각 기반 시점의 제한
- 깊이 추정의 불안정성
- 멀티 뷰 이미지 간 정합의 어려움
- 후처리 복잡도 증가
결과적으로 실제 3D 공간 상의 객체 위치를 정확히 파악하기 어렵고, 지도 정합용으로는 적합성이 떨어지는 경우가 많았다.
1.2 BEV 기반 검출의 시작: BEVDet, BEVDepth
BEV(Bird’s Eye View)는 자율주행 차량의 위치를 중심으로 하늘에서 지면을 내려다보는 시점이다. BEV 시점은 주변 공간을 일정 격자로 표현할 수 있고, 차량 주변 360도를 일관되게 표현하는 데 매우 유리하다. 이러한 BEV 표현을 처음부터 적극적으로 활용한 모델로는 BEVDet(CVPR 2022), BEVDepth(NeurIPS 2022) 등이 있다.
- BEVDet은 이미지에서 추출한 특징(feature)을 view transformation을 통해 BEV 공간으로 변환하고, BEV 공간에서 객체를 검출하는 구조를 도입했다.
- BEVDepth는 depth-aware feature를 반영해 BEV 변환 시 객체의 깊이 정보를 보존하며, BEV 공간에서의 정확도와 공간 정합성을 개선했다.
이들 모델은 기존 2D 기반 모델 대비 3D 공간 표현력이 높고, 다양한 카메라 시점으로부터 BEV 공간을 생성할 수 있어 지도 기반 표현과 자연스럽게 연결된다.
1.3 BEVFormer: Transformer를 활용한 BEV 생성
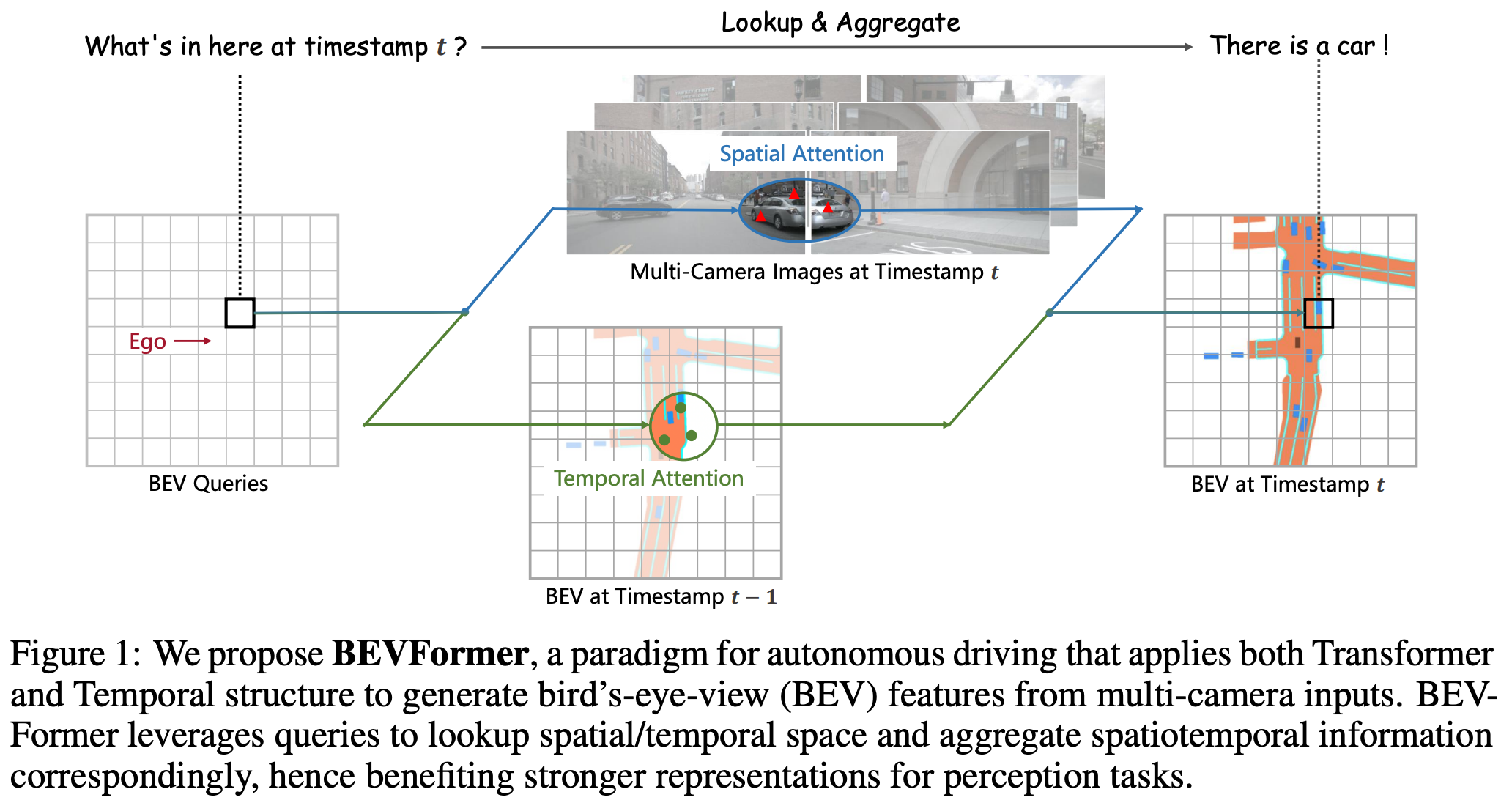
BEVFormer (CVPR 2022)는 BEV 공간 생성을 위해 query 기반의 Transformer 구조를 도입한 모델이다.
✅ 주요 단계
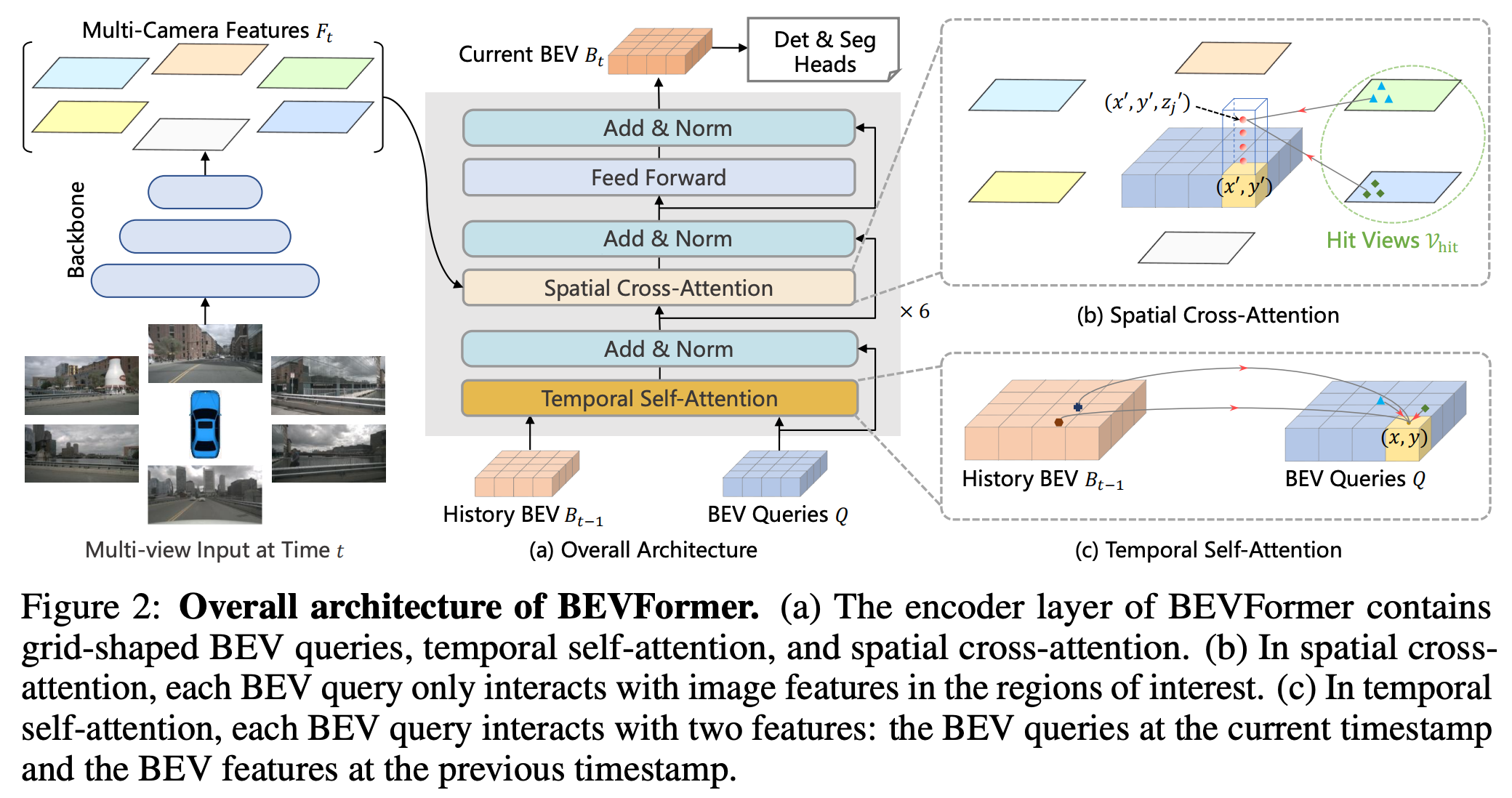
입력 데이터 준비
- 입력 데이터는 멀티 카메라 이미지로, 일반적으로 front, front-left, front-right, back, back-left, back-right 등의 시점이 포함됨.
- 또한 camera intrinsic/extrinsic와 시간 정보를 반영하기 위한 이전 프레임 BEV feature도 필요.
Image Feature 생성
- 각 카메라 이미지를 CNN Backbone에 통과시켜 image-level feagture map 생성
BEV Query 생성
- BEV 공간을 HxW grid로 나누고, 각 위치에 대응하는 learnable query를 생성
- 이 쿼리는 transformer의 key 역할을 하며, 최종 BEV feature를 구성하게 됨
- 비유하자면... 각 쿼리는 BEV 상에 격자 형태로 깔린 '가상의 센서'로 볼 수 있고, 이 센서가 다중 이미지들을 훑으며 "내 위치엔 뭐가 있어?"라고 물으며 각 이미지로부터 정보를 가져오는 것.
Deformable Cross-Attention
- BEV query가 image feature 상에서 어떤 위치를 바라봐야 하는지 학습을 통게 결정
- 각 query는 다중 이미지 뷰에서 관심 위치(K개의 샘플링 포인트)를 선택하고, 해당 위치에서 feature를 샘플링함
- 이 때 관심 위치를 찾기 위해 camera intrinsic/extrinsic이 사용됨
- 이 과정을 통해 multi-camera image feature를 하나의 BEV query로 정합
Temporal Attention
- 이전 프레임의 BEV feature와 현재 프레임의 query 간 attention 수행
- 시계열 정보가 포함되어 움직임, 정적 객체 구분에 유리
Transformer Encoder Stack
- Cross-attention(BEV query <-> imaga features)와 self-attention(BEV query 간 상호작용)을 반복 수행
- 이 과정을 거쳐 정제된 BEV feature map을 생성
추가 내용
- GT는 BEV에 정사영된 3D 객체(차량, 보행자, 자전거,...) 정보이며 3D bbox, 방향 정보가 포함됨
- 이러한 3D GT를 BEV 격자와 매칭하여 사용하게 되는 것이며, 덕분에 BEV query가 자신이 담당하는 셀에 객체가 존재하는지를 학습할 수 있게 된다.
- Query는 객체의 중심이 포함된 셀만 학습하며 검출 head에서 bbox offset를 regression하여 bbox의 구체적인 위치, 크기, 방향 등을 예측한다.
BEVFormer는 BEV 공간 생성의 효율성과 표현력을 동시에 확보했으며, 이후 대부분의 BEV 기반 모델들의 구조적 토대가 되었다.
1.4 MaskBEV 및 통합 멀티태스크 구조
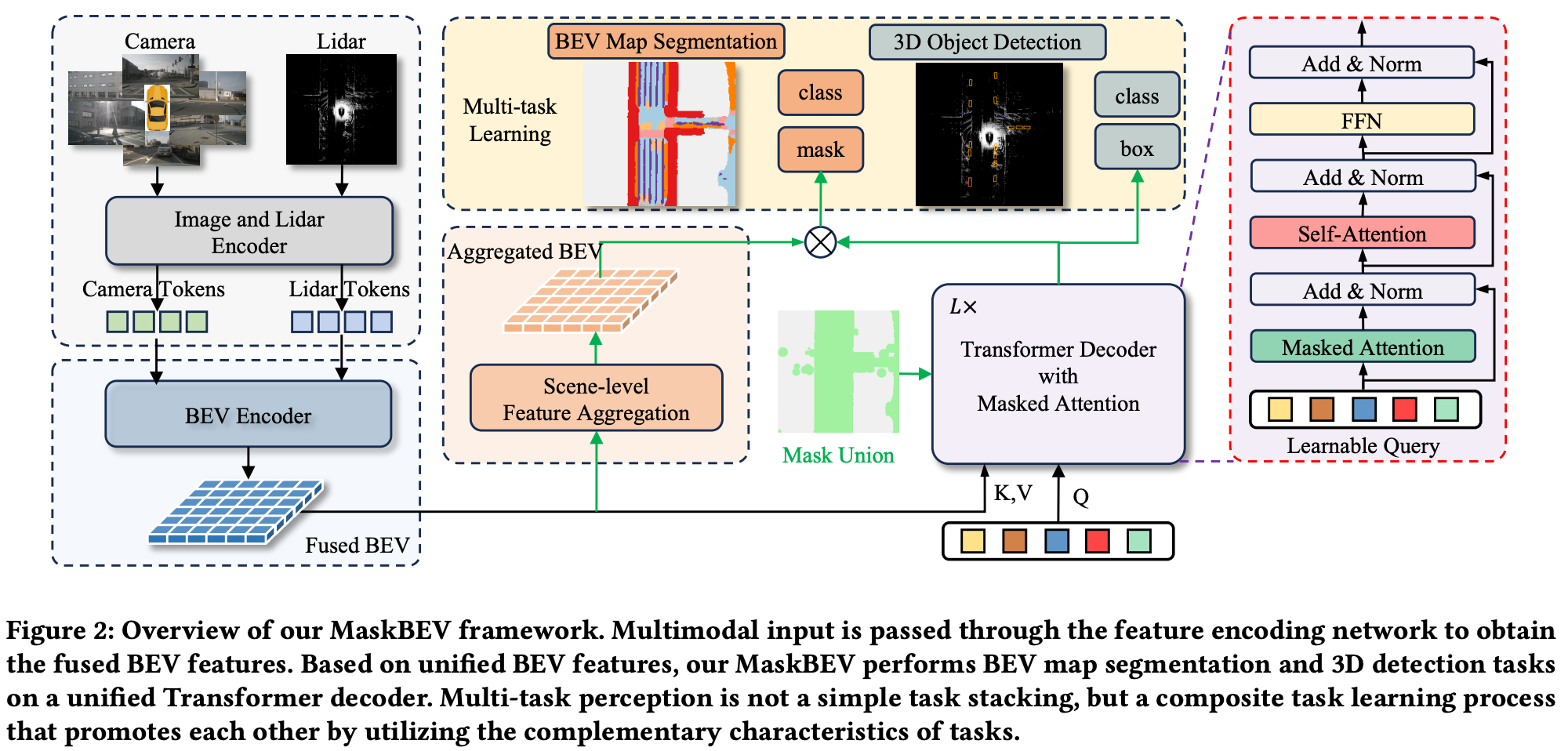
정밀지도 생성을 위한 객체 검출은 이제 단일 태스크로 다루기보다 시맨틱 분할과 통합된 구조로 진화하고 있는데, 대표적인 예가 MaskBEV (ACM MM 2024)이다.

- 단일 BEV feature map을 기반으로 3D 객체 검출과 지도 요소 분할을 동시에 수행한다.
- 기존 방식처럼 객체 검출과 분할을 각각의 헤드로 분리하지 않고, 하나의 공통 Transformer 디코더에서 attention 메커니즘을 통해 두 태스크를 함께 처리한다.
- 특히 task-agnostic하게 설계된 디코더 덕분에, 새로운 태스크를 추가할 때 구조 변경 없이도 통합 학습이 가능하다.
- nuScenes 기준으로 NDS와 mIoU 모두 기존 대비 향상되었다.
구체적인 방법
MaskBEV는 BEVFormer 기반의 query-centric 구조를 확장하여, 각 BEV query가 다양한 태스크에 대한 정보를 동시에 추론할 수 있도록 설계되었다. 구체적으로는, BEV query와 태스크를 식별하는 mask token을 결합하여 입력하면, Transformer 디코더는 이 task-aware query들을 병렬로 처리하면서, 객체 검출, 시맨틱 분할, 차선 추출 등의 다양한 결과를 한 번에 예측한다.
예를 들어, 동일한 BEV 공간 내 (x, y) 위치에 대해
- [query_xy + token_obj_det]은 해당 위치에 객체(차량 등)가 있는지를 추론하고 3D 바운딩 박스를 회귀한다.
- [query_xy + token_seg]은 동일 위치가 도로인지, 차선인지, 횡단보도인지 등을 구분하는 시맨틱 분할을 수행한다.
모든 태스크는 같은 BEV feature를 기반으로 이루어지기 때문에, 결과 간의 공간적 정합성(spatial alignment)도 자연스럽게 확보된다. 학습 시에는 각 태스크에 대응하는 손실 함수만 정의하면 되고, 모델 아키텍처 자체는 동일한 디코더 구조를 공유하므로 파라미터 효율성과 학습 효율이 모두 높아진다.
1.5 기타 주목할 BEV 기반 인지 모델들
| 모델명 | 발표 | 주요 기여 |
|---|---|---|
| BEVDet | CVPR 2022 | 이미지 feature → BEV 변환 후 3D 객체 검출 |
| BEVDepth | NeurIPS 2022 | depth-aware BEV 변환으로 정확도 개선 |
| BEVFormer | CVPR 2022 | deformable attention + query 기반 BEV 학습 |
| PETR | CVPR 2022 | LiDAR 없이 point cloud 형식 3D 예측 |
| UniBEV | CVPR 2023 | 3D 감지 + 분할 통합 BEV 파이프라인 |
| MaskBEV | ACM MM 2024 | 3D 검출 + BEV 분할 통합 구조 구현 |
2. 정합 개선을 위한 Polar 좌표계 기반 표현
기존의 BEV 표현은 직교 좌표(Cartesian grid)를 사용하여 BEV 공간을 구성해 왔다. 하지만 이 방식은 이미지 정보의 분포와 격자 구조 간의 불일치로 인해 여러 한계를 나타낸다. 예를 들어, 카메라에서 가까운 영역은 정보가 조밀하지만, 직교 BEV에서는 동일한 격자 크기를 사용하므로 근거리 정보가 희석되고, 반대로 원거리에서는 불필요하게 높은 해상도의 연산이 낭비되는 문제가 발생한다.
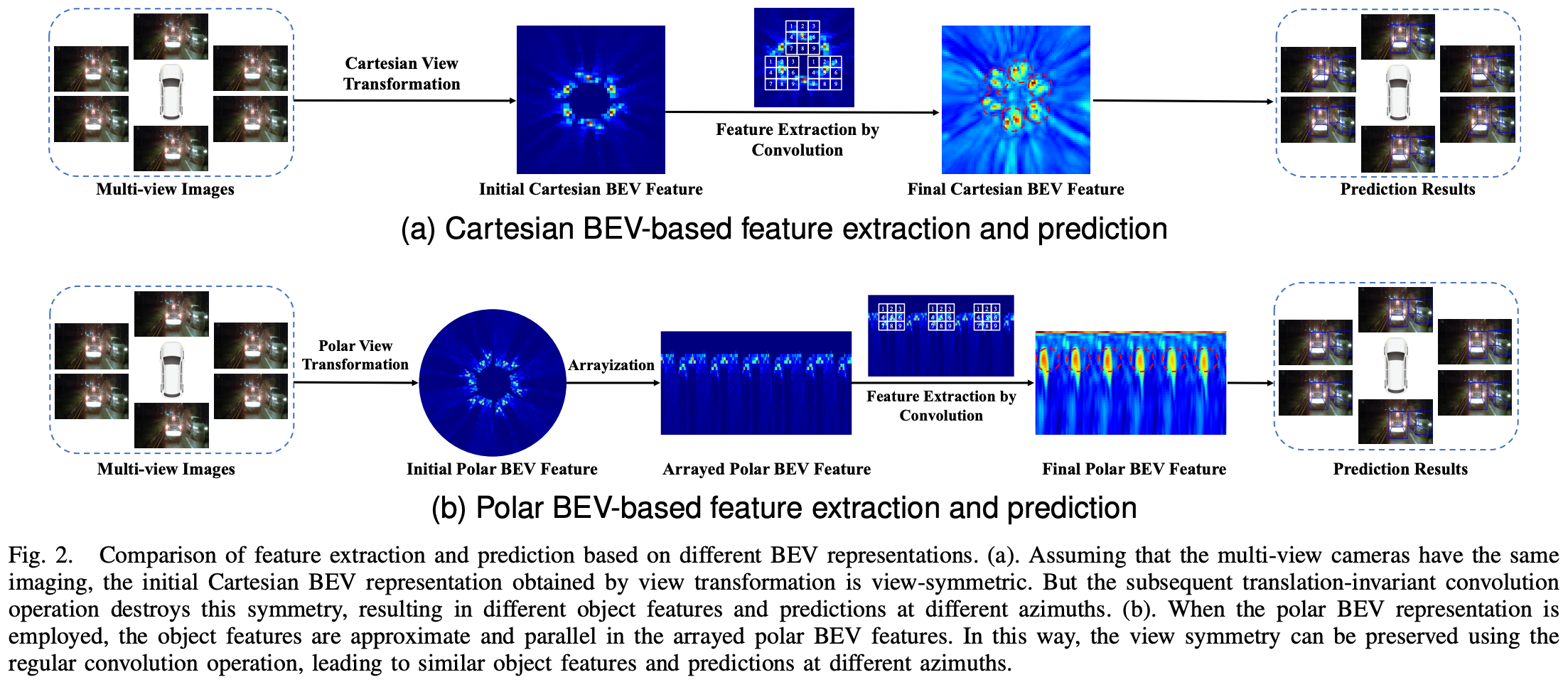
이러한 한계를 해결하기 위해 제안된 접근이 바로 Polar 좌표계 기반 BEV 표현이다. PolarBEVDet과 같은 모델은 BEV 공간을 반지름(radial)과 각도(angular) 축으로 구성하여, 거리 기반으로 격자를 조정한다.
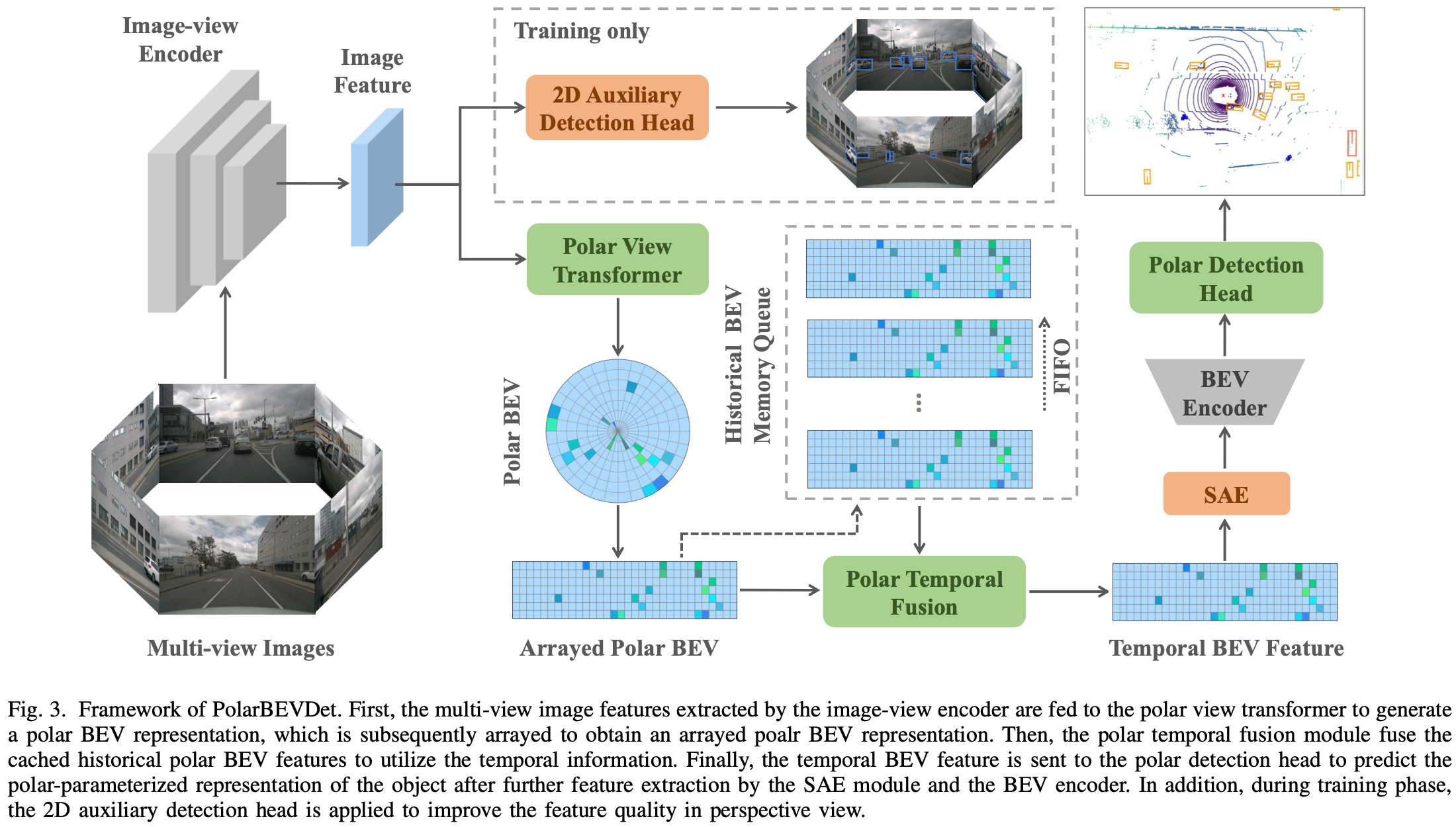
- 근거리 영역은 더 조밀한 해상도로 표현하고, 원거리는 저해상도로 표현하여 연산 자원을 효율적으로 분배한다.
- 멀티카메라 환경에서의 시각적 대칭성을 유지하여, 동일 객체가 다양한 시점에서 동일한 특징으로 학습되도록 유도한다.
- 차량 주변의 시계방향 정렬 표현을 가능하게 하여, BEV에서의 정합성과 표현력을 향상시킨다.
정밀지도 생성에서 중요한 것은 단순한 객체 검출 정확도뿐 아니라, 검출된 객체를 실제 공간 상에 얼마나 정밀하게 정합시키는가이다. Polar BEV 표현은 이러한 공간 정합성 향상에 효과적인 방법으로 주목받고 있다.
3. 멀티모달 센서 융합
정밀지도 생성을 위한 인지 정확도를 높이기 위해 다양한 센서를 융합하는 연구가 활발히 이루어지고 있다. 과거에는 주로 RGB 카메라 기반의 이미지 정보에 의존했지만, 카메라 단독 센서는 조도, 기상 조건, 깊이 추정 등에서 한계를 가진다. 이러한 문제를 극복하기 위해 LiDAR, 레이더, 적외선(IR) 등 다양한 센서를 조합하는 멀티모달 융합 방식이 중요해지고 있다.
3.1 융합 방식의 발전
- Early Fusion: 센서 입력을 전처리 단계에서 결합하는 방식이다. 구조는 간단하지만, 각 센서의 표현력이 제한된다.
- Late Fusion: 센서별로 독립된 인지 결과를 도출한 후, 후처리 단계에서 결합한다. 유연성이 높지만 센서 간 정보 상호작용이 부족하다.
- Mid Fusion (BEV 기반): 최근 주류가 된 방식으로, 각 센서의 feature를 추출한 뒤 BEV 공간으로 투영하여 공간 정합 후 융합한다. 표현력과 정합성을 동시에 확보할 수 있는 방식이다.
3.2 주요 멀티모달 BEV 융합 모델 정리
| 모델명 | 발표 | 사용 센서 | 특징 |
|---|---|---|---|
| BEVFusion | ICRA 2023 | RGB + LiDAR | 이미지와 라이다를 각각 BEV로 투영 후 결합하여 3D 객체 검출 수행 |
| UVTR | NeurIPS 2022 | RGB + LiDAR | 라이다 중심의 정밀한 spatial alignment를 통해 멀티뷰 이미지와 정합 |
| M2BEV | CVPR 2023 | RGB + LiDAR + Radar | 레이더를 포함한 삼중 융합 기반으로 BEV 예측 정확도 향상 |
| TransFusion | CVPR 2022 | RGB + LiDAR | Transformer를 기반으로 센서 간 feature alignment 수행 |
| SAMFusion | ECCV 2024 | RGB + LiDAR + Radar + IR | 다양한 센서 가중치를 환경 조건에 따라 적응적으로 조절하며 악천후 대응 |
3.3 SAMFusion: 날씨 강건성과 센서 신뢰도 기반 가중 조절

SAMFusion은 멀티모달 융합의 최신 사례로, 날씨나 시야 조건이 급변하는 실주행 환경에서 강건한 인지를 목표로 한다.
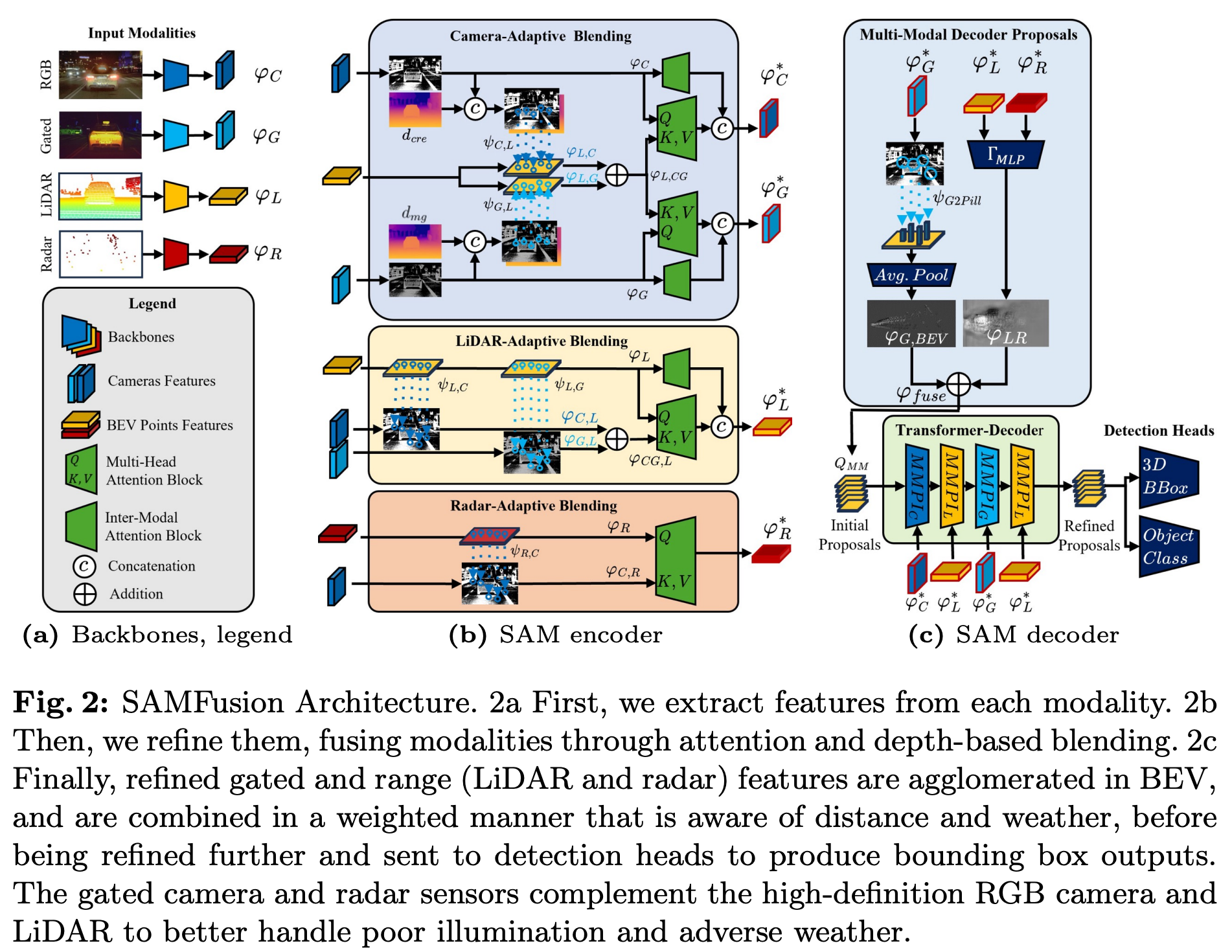
- RGB, LiDAR, 레이더, 적외선 센서 입력을 각각 BEV로 투영
- Transformer 디코더에서 각 센서별 가중치를 동적으로 조절
- 센서 신뢰도를 가시성 및 조건에 따라 자동 조절 (예: 안개 시 IR, 야간 시 라이다 비중 증가)
이 모델은 nuScenes 및 Waymo Open Dataset 기반 벤치마크에서 눈, 비, 야간 조건에서 기존 단일 센서 또는 고정 융합 방식보다 우수한 인지 성능을 보였다.
3.4 멀티모달 융합의 시사점
멀티모달 BEV 융합은 객체 검출 성능 향상뿐 아니라, 정밀지도 생성에서의 객체 위치 정합도와 지도 갱신 신뢰도 향상에도 크게 기여한다. 특히 도시 내 다양한 기상 조건과 교통 밀도가 높은 환경에서 안정적이고 지속 가능한 인지 성능을 확보할 수 있는 유력한 접근이다. 또한, 센서 간 상호보완적인 정보를 효과적으로 통합함으로써 특정 센서가 비정상적으로 작동하거나 사각지대가 생기는 상황에서도 시스템 전체의 인지 정확도를 유지할 수 있다.
향후에는 멀티모달 정보를 단순히 결합하는 수준을 넘어서, 센서 상태 인식(Sensor Condition Awareness), 자기신뢰도 기반 가중 조정(Self-attentive Fusion), 지도 업데이트와 연계된 변화 감지(Change-aware Fusion) 등과 결합하여 더욱 지능적인 정밀지도 생성 파이프라인으로 발전할 것으로 예상된다.
자율주행 인지 기술은 정밀지도 생성의 효율성과 정확성을 동시에 개선하기 위한 방향으로 빠르게 발전해왔다. 객체 검출과 시맨틱 분할은 개별 모델 기반 처리에서 시작하여, BEV 공간 기반 표현과 Transformer 구조를 활용한 통합 모델로 발전했다. Polar 좌표계와 같은 정합 보완 기술은 공간 해석의 정확도를 높였고, 멀티모달 센서 융합은 다양한 환경에서도 견고한 인지 성능을 가능하게 했다.
이러한 기술의 흐름은 단순히 인지 정확도를 높이는 것을 넘어, 지도 생성 파이프라인 전체의 구조적 단순화, 계산 효율 개선, 자동화 기반 지도 업데이트 등과 밀접하게 연결되고 있다. 향후에는 인지와 지도 구성 간의 경계를 허물고, 학습에서 추론, 지도 업데이트까지 일관된 End-to-End 파이프라인을 구축하는 것이 주요 목표가 될 것이다.
