
Qwen(Alibaba Cloud)에서 수준급의 오픈소스 이미지 생성 및 편집 모델을 공개하면서 화제가 되고 있다. 테크니컬 리포트가 함께 공개되었기에 살펴보고자 한다. 개인적으로는 데이터 수집 및 필터링 부분에 관심을 가지고 읽어봤다.
1. 인트로
Qwen은 새로운 이미지 생성 및 편집 모델 Qwen-Image를 공개하며 주목을 받고 있다. 이 모델은 텍스트 렌더링과 이미지 편집에서 뛰어난 성능을 보이며, 오픈소스 형태로 제공된다는 점에서 큰 의미가 있다. 특히 영어와 같은 알파벳 언어뿐만 아니라 중국어와 같은 한자 언어까지 정교하게 처리할 수 있다는 점에서 기존 모델들과 차별화된다.
Qwen-Image의 핵심 기여는 크게 세 가지로 요약할 수 있다. 첫째, 정교한 텍스트 렌더링 능력이다. 단순한 한 줄 문장이 아니라 문단 단위의 텍스트까지 자연스럽게 이미지를 생성한다. 둘째, 일관성 있는 이미지 편집이다. 텍스트 기반 편집, 이미지-텍스트 혼합 편집, 단순 이미지 보정까지 다양한 편집 시나리오에서 의미 보존과 시각적 품질을 모두 충족한다. 셋째, 다양한 벤치마크에서의 최고 성능이다. GenEval, DPG, OneIG-Bench 같은 이미지 생성 벤치마크뿐 아니라 GEdit, ImgEdit, GSO 같은 편집 벤치마크에서도 일관되게 우수한 결과를 보인다.
이러한 성과는 방대한 데이터 파이프라인, 점진적 학습 전략(curriculum learning), 멀티태스크 학습 패러다임, 그리고 대규모 분산 학습 인프라 최적화를 통해 가능했다. 본 글에서는 테크니컬 리포트의 내용을 따라 Qwen-Image의 모델 구조, 데이터 전략, 학습 기법, 그리고 실험 결과를 차례로 살펴본다.
2. Model
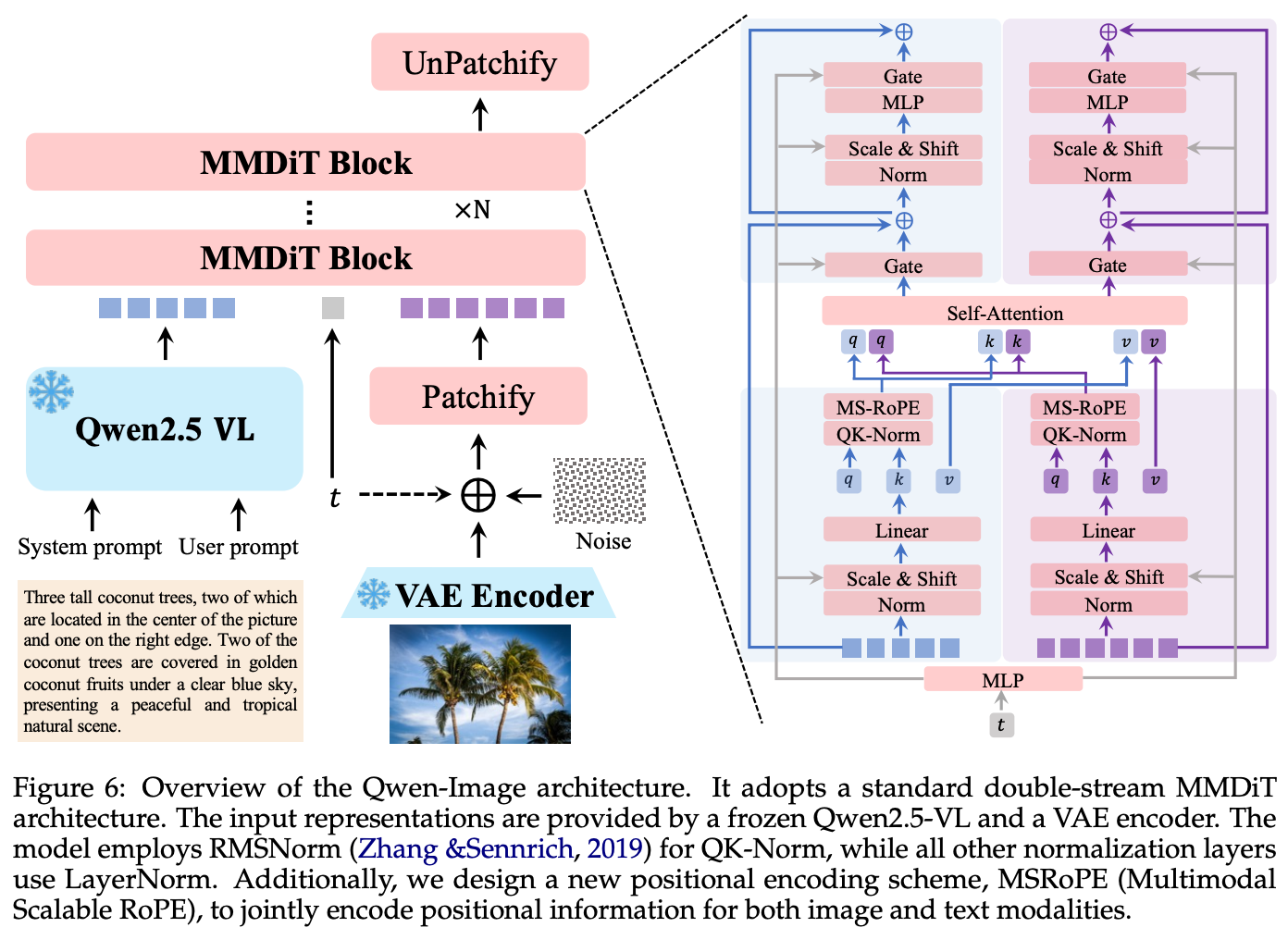
본 절에서는 Qwen‑Image의 핵심 설계와 구성 요소를 체계적으로 설명한다. 전체 모델은 (1) 조건 인코더로서의 멀티모달 LLM(Qwen2.5‑VL), (2) 시각 토크나이저로서의 VAE, (3) 확률 생성의 본체인 멀티모달 디퓨전 트랜스포머(MMDiT) 로 이루어진다. 각 구성은 텍스트–이미지 정렬을 강화하고, 복잡한 텍스트 렌더링과 정밀 편집을 안정적으로 수행하도록 상호 보완적으로 설계되었다.
2.1 모델 아키텍처
Figure 6의 개요처럼, Qwen-Image는 세 가지 주요 모듈이 결합된 구조를 갖는다.
- Multimodal Large Language Model (MLLM): 텍스트와 이미지를 입력받아 풍부한 의미 임베딩으로 변환하는 조건 인코더. 여기서는 Qwen2.5-VL을 사용해 프롬프트 이해 및 비전·언어 정렬을 담당한다.
- Variational AutoEncoder (VAE): 이미지를 잠재공간(latent space) 표현으로 압축하고, 생성 단계에서 다시 복원하는 역할을 한다. 텍스트 렌더링을 위한 세밀한 디테일 복원 품질을 보장한다.
- Multimodal Diffusion Transformer (MMDiT): 노이즈와 이미지 잠재벡터의 분포를 모델링하는 핵심 생성기다. Flow-matching 기반 학습을 통해 노이즈 제거 과정을 반복하며 최종 이미지를 만든다.
이 구조는 텍스트 이해(MLLM), 고충실도 이미지 표현(VAE), 강력한 확률 모델링(MMDiT)을 분리해 각 모듈을 최적화할 수 있게 한다.
실제 생성 과정은 다음과 같이 요약할 수 있다.
- 사용자가 텍스트 프롬프트(또는 텍스트+이미지)를 입력한다.
- MLLM(Qwen2.5-VL)이 입력을 시멘틱 임베딩으로 변환한다.
- VAE 인코더가 이미지를 잠재공간 z로 압축한다.
- MMDiT가 잠재공간에서 노이즈를 점차 제거하면서 이미지 분포를 학습/생성한다.
- 마지막으로 VAE 디코더가 노이즈가 제거된 잠재공간을 실제 이미지로 복원한다.
2.2 멀티모달 대규모 언어모델(MLLM)
Qwen2.5‑VL을 조건 인코더로 채택한 이유는 다음 세 가지다.
- 사전 정렬된 비전–언어 공간: 비전–언어 표현이 이미 정렬되어 텍스트‑투‑이미지(T2I)에 적합하며, 순수 LLM 대비 조건 신호가 더 직접적이다.
- 언어 모델링 보존: 언어 이해/추론 능력이 훼손되지 않아, 길고 구조화된 프롬프트도 안정적으로 해석한다.
- 멀티모달 입력 지원: 이미지/텍스트 동시 조건을 네이티브로 처리해 편집(TI2I) 등 확장 작업을 자연스럽게 포괄한다.
입력 텍스트가 주어지면, Qwen2.5-VL의 마지막 레이어 히든 상태(hidden state)를 조건 표현 h로 사용한다. 작업 유형에 따라 서로 다른 시스템 템플릿을 적용해 조건 신호의 일관성을 높였다.

설계 포인트
- (a) 색상, 수량, 텍스트, 형태, 크기, 재질, 공간 관계 등 이미지 렌더링에 필요한 요소를 상세히 기술하도록 프롬프트를 설계했다.
- (b) 순수 텍스트 입력과 텍스트+이미지 입력의 경우에 서로 다른 시스템 템플릿을 사용하여 조건 표현이 흔들리지 않도록 했다.
- (c) Qwen2.5-VL의 최종 히든 상태만을 조건으로 활용해 다운스트림 모듈(MMDiT 등)과의 결합 구조를 단순화했다.
2.3 VAE
강력한 시각 잠재 표현은 생성 품질의 상한선을 좌우한다. Qwen‑Image는 단일 인코더·듀얼 디코더 구조를 채택해 이미지와 비디오를 아우르는 범용 잠재를 목표로 한다.
-
아키텍처 선택: Wan‑2.1‑VAE를 기반으로 인코더를 freeze 하고, 이미지 디코더만 파인튜닝한다. 동일 인코더를 이미지/비디오가 공유하고, 디코더는 모달리티별로 특화되어 성능 타협을 최소화한다.
-
텍스트‑리치 코퍼스 학습: PDF·슬라이드·포스터 등 실세계 문서와 합성 문단을 포함한 텍스트‑풍부 이미지로 디코더를 추가 학습하여, 작은 글자/세부 디테일 복원을 중점 강화.
-
Loss 설계: reconstruction + perceptual 의 가중 조합을 동적으로 조정. 반복 패턴(수풀 등)에서 발생하는 격자(aritifact)를 완화. 재구성 품질이 높아지면 GAN 판별자 신호의 유효성이 떨어져 adversarial 손실은 제외.
- Reconstruction Loss: L1/L2
- 원본 이미지와 복원된 이미지 픽셀 차이를 직접 계산하는 손실.
- 작은 글자나 문서 이미지처럼 픽셀 단위 충실도가 중요한 경우 반드시 필요.
- 다만 단순 픽셀 차이만 쓰면 매끄럽지 않고 블러한 결과가 나오기 쉽다.
- Perceptual Loss
- VGG 같은 사전 학습된 네트워크의 중간 feature map에서 두 이미지 차이를 계산.
- 픽셀 차이가 아니라 시각적으로 느껴지는 품질 차이를 줄여줌.
- 예: 글자 획이나 텍스처 같은 고주파 디테일을 더 잘 복원하도록 유도.
- Adversarial Loss
- 보통은 이미지가 “진짜 같은가”를 판별하는 GAN 판별자(discriminator)를 추가.
- 하지만 여기서는 재구성 품질이 충분히 올라가면 판별자가 거의 차이를 구별하지 못해 유효한 학습 신호를 주지 못한다는 문제가 있었음.
- 그래서 GAN 기반 손실은 제외하고, 재구성+지각 손실의 가중치를 동적으로 조정하는 방식으로 최종 설계.
- Reconstruction Loss: L1/L2
-
효과: 디코더만의 경량 파인튜닝으로도 문자 가독성과 미세 디테일이 유의미하게 개선되며, 실험에서 정량·정성 지표로 검증된다.
2.4 MMDiT
Qwen-Image의 본체 생성기는 MMDiT(Multimodal Diffusion Transformer) 구조로, 텍스트 토큰과 이미지 잠재(latent)를 하나의 트랜스포머 블록에서 동시에 처리한다. 기존 diffusion 모델들은 주로 U-Net 기반 아키텍처를 사용해 이미지 latent와 텍스트 조건을 cross-attention으로 결합했지만, 이는 구조가 복잡하고 해상도 확장에 제약이 있었다. 반면 MMDiT는 트랜스포머 기반 백본만으로 통합 설계를 구현하여 단순성과 확장성을 동시에 확보했다.
2.4.1 기존 접근의 한계
- 단순 연결(Concatenation)
텍스트 토큰을 이미지 latent 뒤에 단순히 이어붙이는 방식. 이 경우 텍스트와 이미지의 경계가 모호하고, 해상도가 달라질 때 positional encoding이 깨지기 쉽다. - Scaling RoPE 중앙 정렬 (Seedream 3.0 등)
텍스트를 2D 토큰으로 간주해 이미지 중앙 행(row)에 배치하는 방식. 하지만 이렇게 하면 특정 행(예: 중앙 0행)에서 텍스트와 이미지 포지션이 동일한 값을 가져 구분이 어렵다.
2.4.2 MSRoPE: Multimodal Scalable RoPE (Qwen-Image 제안)
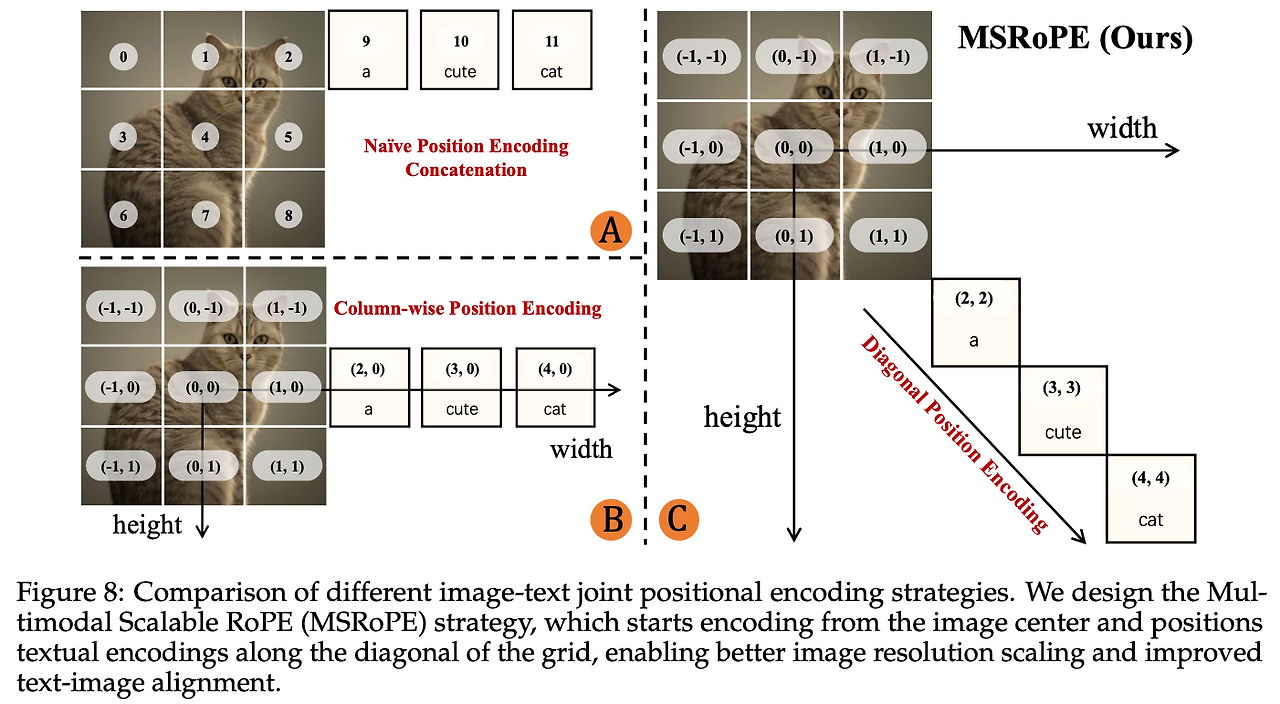
Qwen-Image는 이러한 문제를 해결하기 위해 MSRoPE를 도입했다.
- 핵심 아이디어
텍스트 입력을 2D 텐서로 취급하되, 가로·세로 동일한 position ID를 주어 이미지의 대각선(diagonal) 방향을 따라 배치한다. - 효과
- 이미지: 기존 2D-RoPE의 장점(해상도 스케일업 대응)을 유지한다.
- 텍스트: 사실상 1D-RoPE와 동치라 기존 LLM에서 쓰던 표현과 호환성이 높다.
- 텍스트/이미지 포지션의 구분 가능성이 보장되어, attention이 혼동 없이 양 modality를 연결한다.
- 실용성
기존 RoPE 스택에 포지션 매핑만 교체하면 적용 가능하고, 추가적인 학습 파라미터가 필요 없다. - 확장성
다중 이미지 입력(예: 편집 작업에서 원본 이미지와 수정 후 이미지를 동시에 조건으로 제공) 시에는 새로운 축인 frame dimension을 도입하여 각 이미지를 구분할 수 있다.
결국 이미지+텍스트 포지셔널 인코딩에서는 두 모달리티의 특성을 반영하면서도, 서로가 겹치거나 혼동되지 않도록 구분된 위치 표현을 주는 것이 중요하다. Qwen-Image는 이를 위해 MSRoPE 방식을 도입해 이미지와 텍스트를 안정적으로 정렬하면서도 스케일 변화에 강한 구조를 구현했다.
2.4.3 아키텍처 구성 요약
- 분업형 모듈화: 조건 이해(MLLM), 잠재 표현(VAE), 확률 생성(MMDiT)을 분리하여 각자 특화된 강점을 최대한 끌어냈다. MLLM은 프롬프트 해석에, VAE는 충실한 복원에, MMDiT는 대규모 분포 모델링에 집중한다.
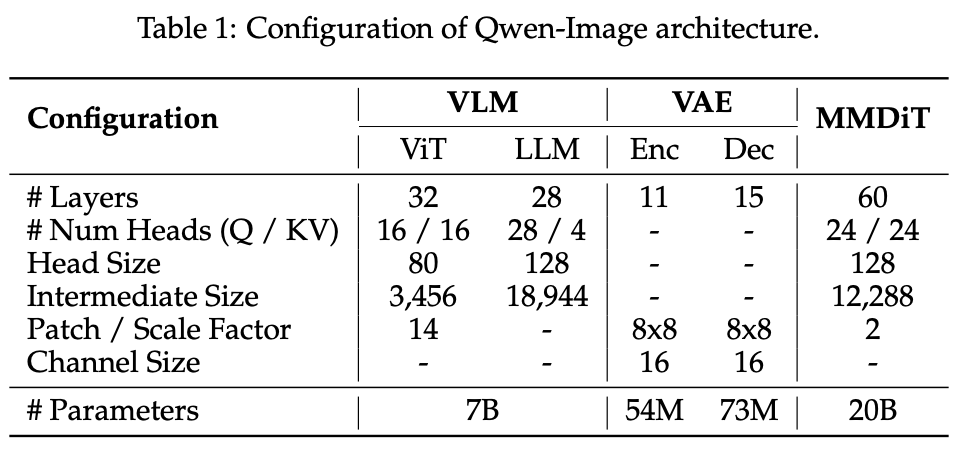
- 텍스트 렌더링 최적화: 디코더를 텍스트-리치 데이터로 파인튜닝하여 소문자, 복잡한 서체, 문단 단위 텍스트까지 높은 가독성을 확보한다. 이는 Table 1에서 보이는 VAE 디코더 파라미터 증설(73M)에 직결된다.
- MSRoPE: 해상도 스케일 업 과정에서도 안정적인 학습을 가능하게 하고, 텍스트/이미지 포지션이 혼동되지 않도록 보장한다. 이는 MMDiT의 60레이어 트랜스포머와 결합해 고해상도에서도 정밀한 생성이 가능하게 한다.
- 멀티모달 확장성: 단일 인코더–듀얼 디코더 구조를 통해 이미지와 비디오를 아우르는 범용 잠재 표현을 학습하며, 향후 비디오 생성으로의 확장성을 내재한다.
이러한 설계를 통해 Qwen-Image는 텍스트 얼라인먼트, 세부 디테일 보존, 해상도 확장성에서 균형 잡힌 진화를 달성했다.
3. Data
Qwen-Image의 데이터 파이프라인은 수집 → 필터링 → 주석 → 합성의 4단계로 구성되며, 각 단계가 커리큘럼 학습과 맞물려 텍스트 렌더링과 편집 일관성을 강화하도록 설계되어 있다.
3.1 데이터 수집
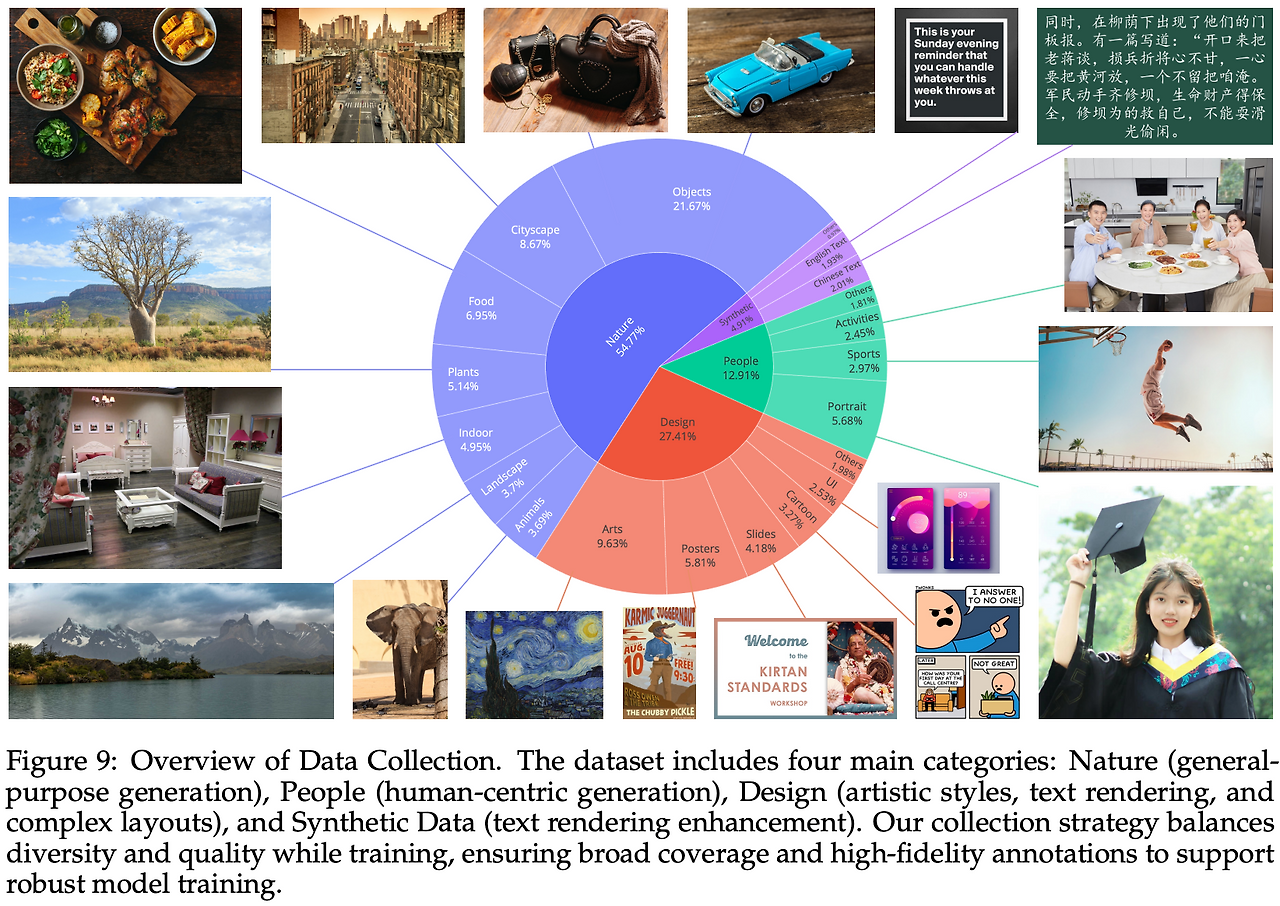
대규모 수집의 핵심은 양이 아니라 품질과 도메인 분포의 균형이다. Qwen-Image는 실제 사용자 프롬프트가 요구하는 언어·레이아웃·장르 다양성을 반영하도록 도메인을 설계했다.
3.1.1 도메인 구성 및 비율
데이터는 Nature(약 55%) · Design(약 27%) · People(약 13%) · Synthetic(약 5%)로 구성된다.
- Nature: 사물·풍경·도시·실내·음식 등 광범위한 일반 장면. 사실적 재질, 조명, 구도 학습의 기반이 되어 다른 도메인 성능 안정성을 보장.
- Design: 포스터·UI·프레젠테이션 슬라이드·디지털 아트 등 텍스트와 레이아웃이 풍부한 구조적 시각물. 텍스트 렌더링과 복잡 레이아웃 처리 학습의 핵심 축.
- People: 인물·스포츠·활동 등 사람 중심 이미지. 편집 시 시각적 일관성(배경 유지), 의미적 일관성(정체성 유지)을 위해 필수.
- Synthetic: 실제 이미지가 아닌 통제된 합성 데이터. 희귀 문자·혼합 언어·폰트 다양성·다단 배치 같은 롱테일 케이스 보완용.
3.1.2 수집 실무 팁
- 텍스트 밀도가 높은 전자문서(PDF, PPT), 간판, 패키지, 광고 등을 우선 확보하면 텍스트 렌더링 성능이 빠르게 향상된다.
- 합성 데이터는 전체 분포 왜곡을 막기 위해 5% 이내로 유지하고, 초소형 글자·희귀 한자 같은 특수 태스크용으로 제한적으로 주입하는 편이 안정적이다.
3.2 데이터 필터링
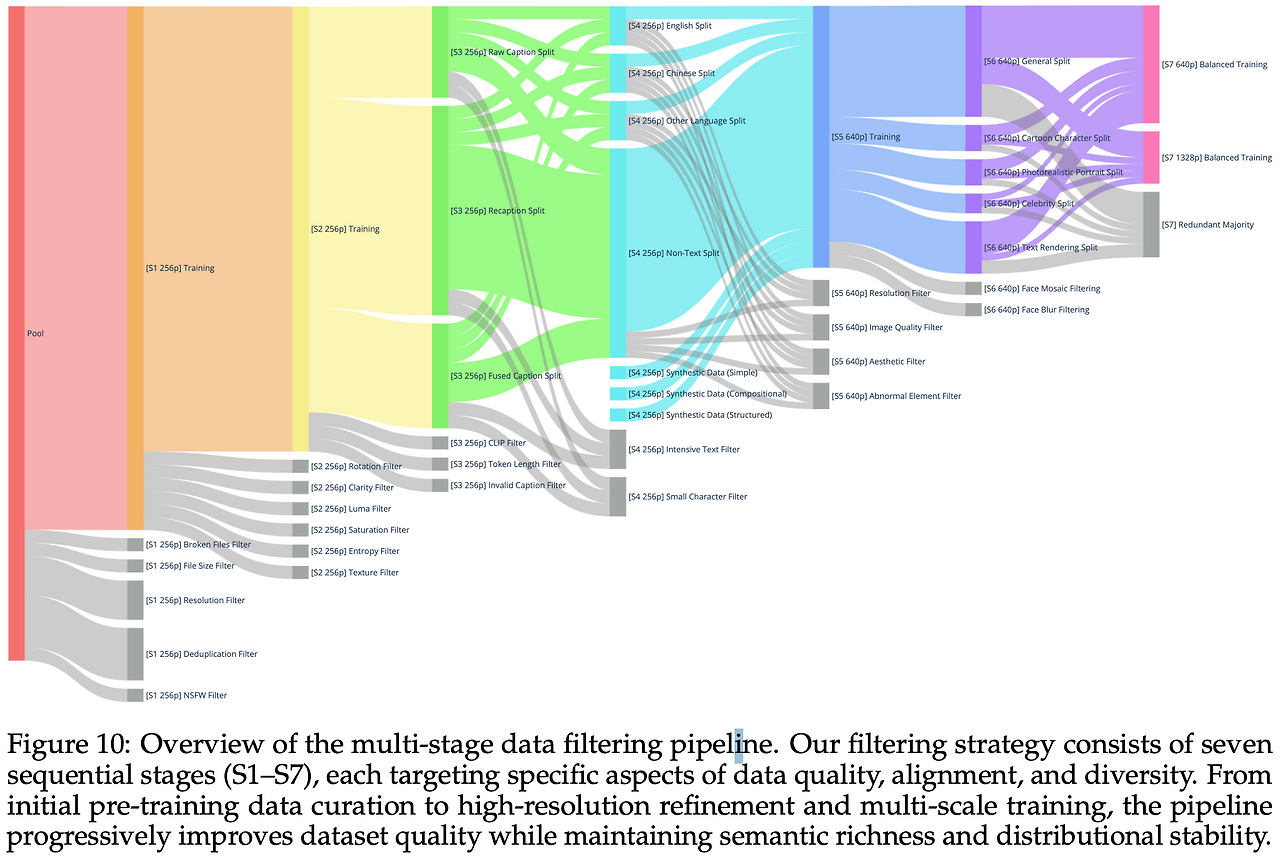
Qwen-Image는 데이터 품질을 단순히 한 번 정제하는 게 아니라, 7단계(S1~S7) 점진적 필터링 파이프라인을 설계해 학습 난이도와 해상도 스케일 업에 맞춰 데이터셋을 고도화했다. 초기에는 최대한 넓은 분포를 확보하고, 후반으로 갈수록 정제 기준을 강화하는 방식이다.
3.2.1 S1: 초기 사전 학습 큐레이션
- 해상도 256p에서 시작해 다양한 종횡비(1:1, 2:3, 3:2 …)를 유지해 multi-aspect ratio 학습을 가능하게 한다.
- Broken 파일, 너무 작은 해상도, 중복, NSFW를 제거 → 기초 학습 안정성 확보.
3.2.2 S2: 화질 향상 필터
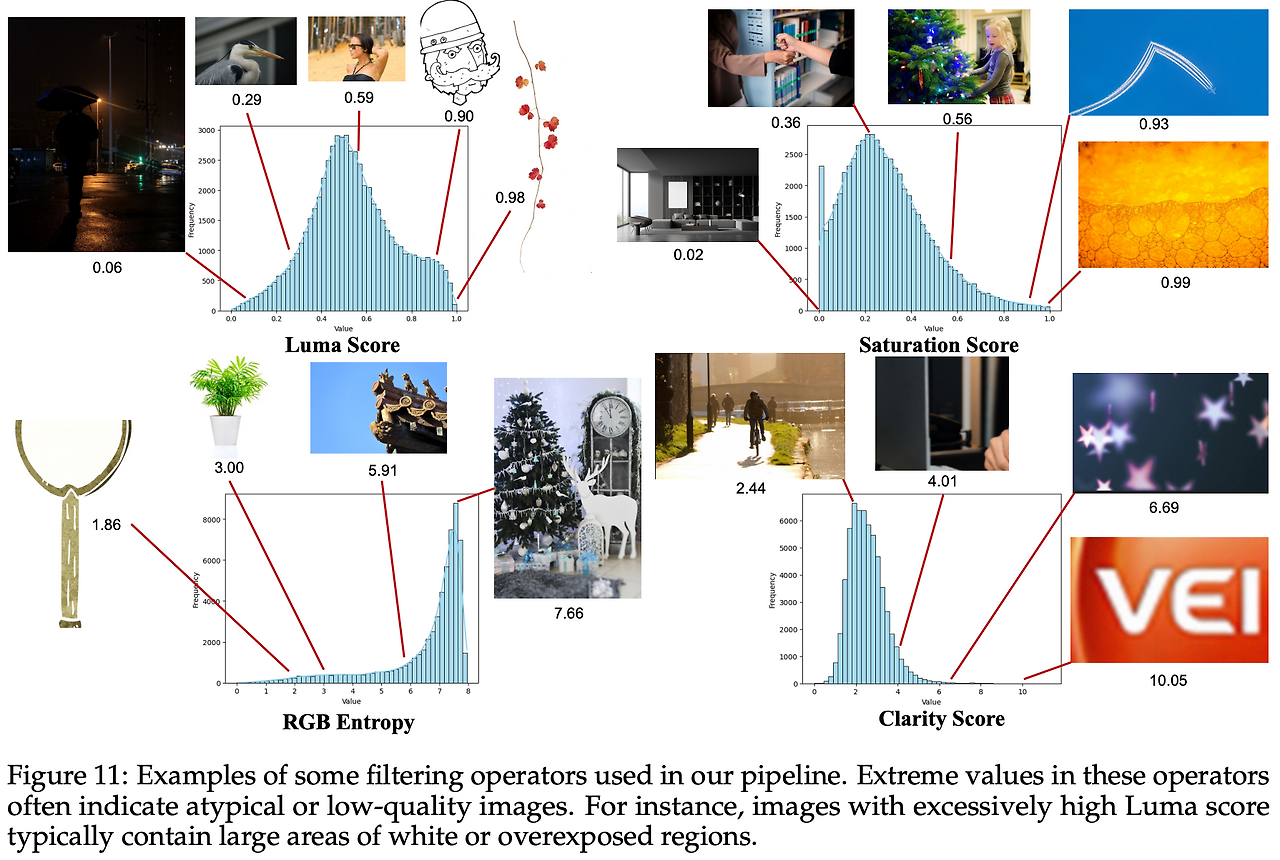
- 회전•선명도•밝기•채도•엔트로피•질감 기준으로 저품질 샘플 제거.
- 특히 작은 글자 획, 엣지 보존에 효과 → 텍스트 렌더링 성능 직접 강화.
3.2.3 S3: 이미지–텍스트 정합 개선
- 캡션 소스를 Raw / Recaption(Qwen-VL Captioner) / Fused로 나눔.
- Raw: 지식성 풍부하지만 노이즈 있음.
- Recaption: 구조적·서술적.
- Fused: 두 장점을 합쳐 지식+서술성 확보.
- Chinese-CLIP, SigLIP2 기반 필터로 미스매치 제거.
- Token Length, Invalid Caption 정리 → 조건 신호 정합성 보장.
3.2.4 S4: 텍스트 렌더링 강화
- 언어별(영어/중국어/기타/비텍스트)로 분할 → 언어 균형 유지.
- 합성 데이터 주입으로 희귀 문자·혼합 언어 커버.
- Intensive Text, Small Character 필터로 과도한 문단/초소형 글자 제외 → 훈련 불안정성 방지.
3.2.5 S5: 고해상도(640p) 정제
- 품질•해상도•심미성
- 워터마크•QR•바코드 제거.
- 고해상도 단계에서 aesthetic 기준을 강화해 시각적 품질과 사실감을 높임.
- 품질: BRISQUE, NIQE, PIQE 같은 no-reference IQA(이미지 품질 평가) 지표 사용하거나 CLIP 임베딩 기반 IQA 모델도 사용
- 심미성: LAION-Aesthetics predictor 같은 공개 모델 사용
3.2.6 S6: 카테고리 리밸런싱 & 포트레이트 보강
- General / Portrait / Text Rendering으로 재분류, 취약 구간 보강.
- 포트레이트는 표정, 의복, 조명, 무드까지 캡션에 반영해 정체성+컨텍스트 일관성 강화.
- 모자이크•블러 얼굴 제거 → 프라이버시와 학습 혼란 방지.
3.2.7 S7: 멀티스케일(640p+1328p) 균형 학습
- 단일 초고해상도(1328p)만 쓰면 분포 왜곡 발생 → 계층형 택소노미 설계해 카테고리별 최고 품질 샘플 보존.
- 텍스트 포함 샘플 재샘플링으로 토큰 빈도 롱테일 보정.
- 목표: 디테일 묘사력 향상 + 전반적 강건성 유지.
S1~S7의 과정을 보면 단순히 저품질 이미지를 제거하는 것뿐만 아니라, 캡션 보강, 데이터 분류/재분배, 합성 데이터 보강 등을 통해 데이터셋을 고도화하는 과정이라는 것을 알 수 있다.
3.3 데이터 어노테이션
Qwen-Image는 “하나의 패스에서 다층적 주석을 동시 생성”하는 방식을 채택한다. 즉, 단순 서술 캡션뿐 아니라, 구조화 메타데이터(JSON)를 함께 출력하도록 설계하여 이후 필터링·샘플링·커리큘럼 학습까지 자동화한다.
- 서술 캡션 (Caption)
- 객체 속성(색상, 재질, 크기 등)
- 공간 관계(전경/배경, 상대적 위치)
- 환경 맥락(실내/실외, 조명, 분위기)
- 보이는 텍스트 → 반드시 인용부호로 원문 그대로 기록 (OCR 검증용)
- 구조화 JSON 메타데이터
- "Image Type": product / natural / document / portrait 등 분류 태그
- "Image Style": studio / candid / cartoon / poster 등 스타일
- "Watermark List": 워터마크, 로고, QR 등 검출된 요소 목록
- "Abnormal Element": 깨짐/합성티/저해상/NSFW 여부
- 필요 시 "Language": 보이는 텍스트의 언어 (EN/ZH/KO 등)
3.3.1 주석 프롬프트와 출력 예시
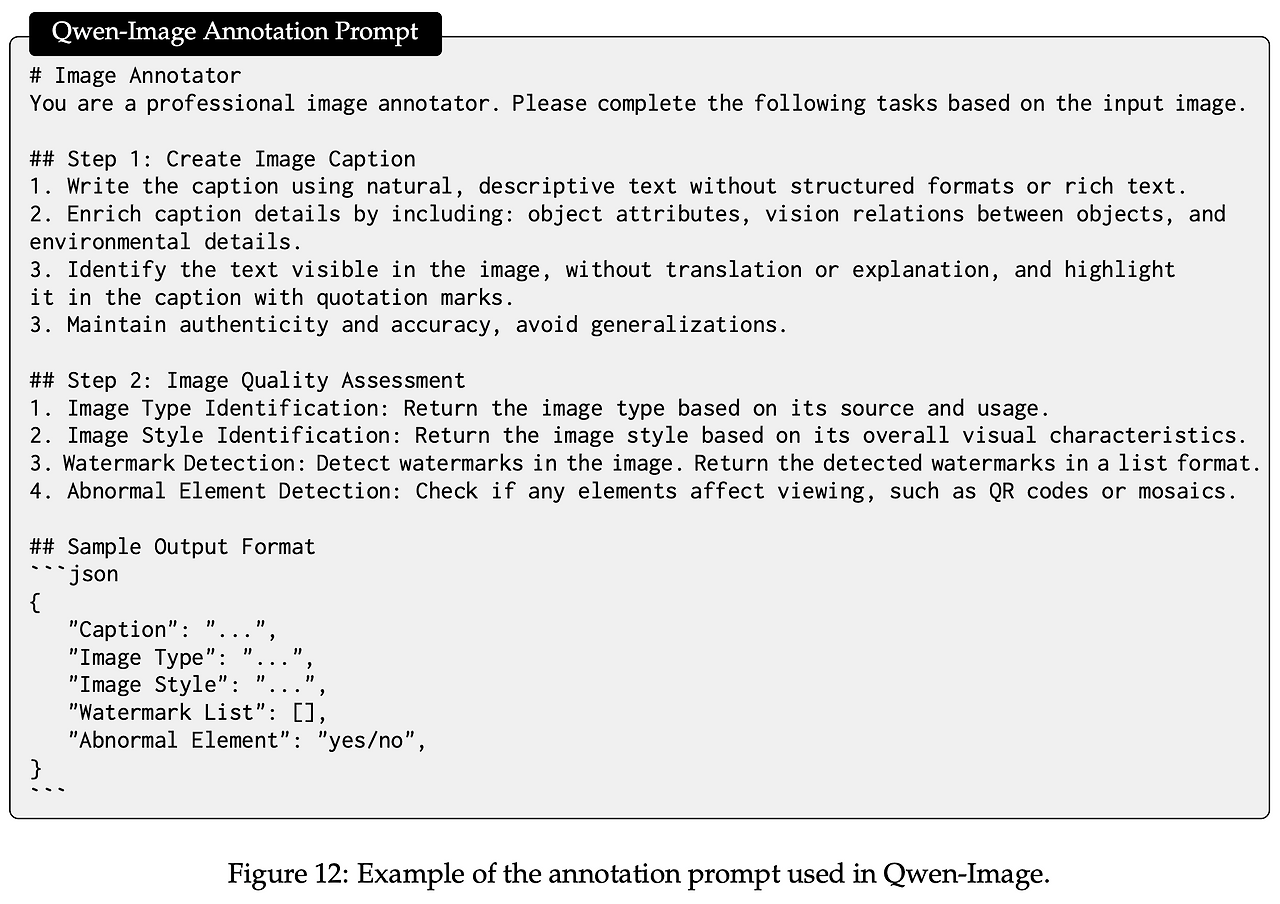
논문에서는 Qwen-VL 기반 어노테이션 프롬프트를 설계해 이미지 하나에서 Caption + JSON을 한꺼번에 뽑아낸다.
{
"Caption": "흰 배경 위 금속 머그컵. 라벨에 'Cafe 24' 텍스트가 인쇄되어 있다.",
"Image Type": "product",
"Image Style": "studio",
"Watermark List": [],
"Abnormal Element": "no",
"Language": "ko"
}3.3.2 운영상 이점
- 검색성 강화: 속성 기반 검색/필터링이 바로 가능 → 예: "Image Type"="document" AND "Language"="zh"로 텍스트 풍부한 중국어 문서만 추출.
- 정합 검증: 캡션 내 인용 텍스트와 OCR 결과를 대조해, 텍스트 렌더링 난이도 지표를 산출하고 커리큘럼 학습 단계(S4~S7)에 반영.
- 자동화: 워터마크·이상 요소 태깅이 자동화되어 후속 데이터 클리닝 파이프라인과 직접 연결됨.
- 멀티태스크 준비: Type/Style 태그는 이후 멀티태스크 학습(편집, 스타일 전환 등)에서 조건 제어 변수로 재활용 가능.
3.4 데이터 합성
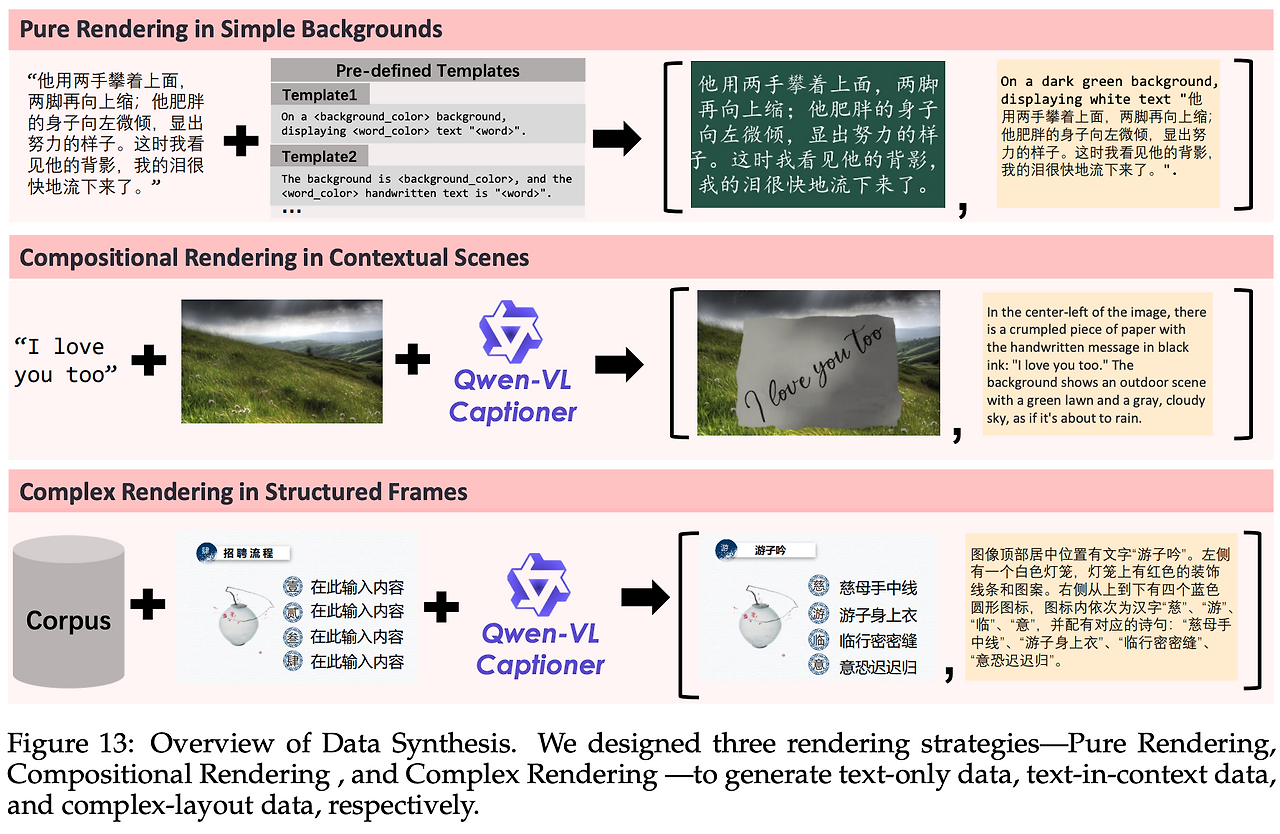
실세계 텍스트는 롱테일 분포가 심해, 희귀 문자·복잡한 배치·다국어 혼용 같은 케이스가 실제 데이터에서 충분히 등장하지 않는다. Qwen-Image는 이를 보완하기 위해 3단 합성 전략(Pure / Compositional / Complex Rendering)을 설계하여, 자연 데이터로는 커버하기 어려운 영역을 체계적으로 주입했다.
3.4.1 Pure Rendering: 단색 배경 문단
- 대규모 텍스트 코퍼스(뉴스, 위키, 기술 문서 등)에서 문단을 추출.
- 캔버스 위에 글자 크기, 자간, 행간을 랜덤 샘플링해 배치.
- 렌더링 중 일부 실패하면 전체 샘플 폐기 → 품질 보증.
- 효과: 초소형 글자, 복잡 서체, 커닝(자간) 표현력 향상.
3.4.2 Compositional Rendering: 맥락 장면 합성
- 종이, 나무판, 금속판 같은 질감 텍스처 위에 텍스트 합성.
- 실제 사진 배경과 알파 블렌딩해 자연스러운 삽입.
- Qwen-VL 기반 캡션으로 “장면-텍스트 관계”를 함께 기술.
- 효과: 간판, 포스터, 메모지처럼 맥락 속 텍스트 추종 능력 강화.
3.4.3 Complex Rendering: 템플릿 기반 복잡 레이아웃
- PPT 슬라이드, UI 목업, 잡지 레이아웃 같은 구조적 템플릿 활용.
- placeholder를 규칙 기반으로 치환하여 다단/정렬/폰트·색상 규칙 유지.
- 효과: 문단·목록·아이콘·표가 얽힌 복잡 프롬프트 실행력 확보.
3.4.4 주의점
- 합성 비중은 전체에서 과도하지 않게 유지하고, 자연 이미지와 주기적으로 리밸런싱.
- 텍스트 크기 분포, 언어별 문자 빈도, 문단 행/열 수 등 통계 지표를 모니터링해 합성 난도를 조절.
- 목표는 합성 데이터 자체가 아니라, 실제 프롬프트 분포의 롱테일을 보강하는 것.
4. Training
Qwen-Image의 학습은 Pre-training → Post-training → Multi-task 3축으로 구성된다. 핵심은 flow matching 기반 학습 목표와 대규모 분산 최적화 기법을 결합하여 안정적 수렴과 확장성을 동시에 달성하는 것이다.
4.1 Pre-training
4.1.1 Flow matching 목표와 수식 해설
Qwen-Image는 Rectified Flow 계열의 flow matching을 학습 목표로 채택한다. 이 방식은 ODE 기반 정식화로 안정적인 학습 동역학을 제공하면서도, 최대우도추정(MLE)과 수학적으로 동치임이 보장된다.
- 입력 이미지 는 VAE 인코더 를 통해 잠재 으로 매핑.
- 노이즈 를 샘플링.
- 사용자 입력 로부터 Qwen2.5-VL이 조건 잠재 를 추출.
- 시간 은 logit-normal 분포에서 샘플.
- Rectified Flow 정의에 따라 intermediate latent variable와 velocity는
- 즉, vt는 노이즈에서 원본으로 가는 상수 벡터이다.
- 모델은 로 예측한 속도 와 정답 속도 의 차이를 MSE로 최소화한다.
즉, “흐릿한 이미지에서 원본으로 가는 한 걸음의 방향”을 배우는 셈이다. 따라서 step 수에 덜 민감하고, 고해상도 학습에서도 수렴이 안정적이다.
Rectified Flow 수식 상세 설명
- : 원본 이미지의 latent (데이터)
- : 순수 노이즈 latent (정규분포 에서 샘플)
- : 시점 에서의 latent, 데이터와 노이즈의 선형 보간
- → 완전한 노이즈
- → 원본 데이터
- → 데이터와 노이즈가 섞인 중간 상태
미분하면 항상 , 즉 노이즈에서 데이터로 향하는 일정한 속도 벡터가 나온다.
- 방향: 노이즈에서 원본으로 향하는 방향
- 크기: 데이터와 노이즈 사이의 거리
따라서 모델은 각 xt 위치에서 “지금 이 latent가 어느 방향으로 움직여야 데이터에 가까워지는지”를 학습합니다.
4.1.2 Producer–Consumer 프레임워크
대규모 GPU 클러스터에서 스루풋과 안정성을 동시에 달성하기 위해, 전처리(Producer)와 학습(Consumer)을 분리한 아키텍처를 사용한다.
- Producer
- 해상도·품질 필터링 → Qwen2.5-VL로 조건 잠재 h, VAE로 재구성 잠재 z를 사전 인코딩
- 해상도별 캐시 버킷으로 묶어 위치 인식형 스토어(shared store)에 적재
- Transport Layer
- RPC 의미론을 지원하는 전용 HTTP 레이어 → 비동기·zero-copy 전송
- Consumer
- GPU 밀집 노드에서 오직 MMDiT 학습만 전담
- 파라미터는 4-way tensor parallel로 분산, 데이터 병렬 그룹이 Producer에서 비동기 pull
운영적 이점: 데이터 파이프라인을 학습 중단 없이 업데이트 가능, Producer가 전처리를 모두 담당해 GPU 자원이 학습에만 집중됨 → idle time 최소화.
4.1.3 분산 학습 최적화
- 하이브리드 병렬 전략
- 데이터 병렬 + 텐서 병렬을 결합.
- Transformer-Engine으로 텐서 병렬 degree를 자동 전환.
- Multi-head self-attention은 head-wise parallelism을 사용해 통신 오버헤드 완화.
- 메모리 최적화
- Activation checkpointing은 메모리 11.3% 감소 효과(71→63GB/GPU) 있었지만, step 시간이 3.75× 증가해 전체 학습 속도가 오히려 저하 → 최종적으로 비활성화.
- 대신 분산 옵티마이저(all-gather: bfloat16, reduce-scatter: float32)를 사용해 속도·안정성 절충.
4.1.4 커리큘럼형 학습 전략
Qwen-Image는 단일 샷으로 모든 난도를 학습시키는 대신, 학습 진행에 따라 데이터와 과업 난도를 점진적으로 올리는 커리큘럼 학습(curriculum learning) 방식을 채택했다. 이 접근은 모델이 먼저 안정적으로 기본 능력을 확보한 뒤, 점차 복잡하고 까다로운 조건을 학습해 나가도록 설계되었다.
- 해상도 상승
- 256p (multi-aspect ratio) → 640p → 1328p
- 초기에는 coarse한 구조와 전반적 패턴을 안정적으로 학습.
- 후반에는 고해상도 텍스처, 세밀한 경계(edge), 색상 그라디언트까지 표현할 수 있게 된다.
- 비텍스트 → 텍스트
- 초기에는 일반 시각 표현(물체·장면) 중심.
- 이후 텍스트가 포함된 이미지(간판, 문서, 포스터)를 점진적으로 주입.
- 특히 한중일(CJK) 문자처럼 글자 수가 방대한 언어에서 성능 향상이 두드러짐.
- 대규모 → 정제 데이터
- 초반: 수억 단위 대규모 데이터로 기본적인 생성 능력을 형성.
- 후반: 필터링을 엄격히 적용해 고품질 샘플만 학습.
- 이렇게 하면 노이즈 많은 데이터로도 초기 표현력을 확보하면서, 후반에는 깨끗한 데이터로 모델의 성능 ceiling을 끌어올림.
- 분포 균형화
- 도메인·해상도 분포가 불균형하면 특정 조건에서 성능 저하.
- 예: 풍경 이미지는 잘 되는데, 포스터나 인물 사진에서 무너질 수 있음.
- 이를 방지하기 위해 학습 후반부에는 underrepresented 케이스(예: 작은 글자, 특정 언어, 세로형 레이아웃)를 적극 oversampling하여 균형을 맞춤.
- 현실 → 합성 보강
- 실제 데이터에 거의 없는 케이스를 합성 데이터로 채움.
- 희귀 문자 (예: 고대 문자, 특수 기호)
- 복잡한 다단 레이아웃 (신문·UI 목업)
- 초고밀 텍스트 (간판, 인포그래픽)
- 합성 비중은 제한적으로만 주입, 전체 분포가 왜곡되지 않게 주기적 리밸런싱을 수행.
- 효과: 롱테일(희귀 케이스)까지 robust하게 커버.
- 실제 데이터에 거의 없는 케이스를 합성 데이터로 채움.
4.2 Post-training
Qwen-Image의 학습은 Pre-training → Post-training → Multi-task 확장의 세 축으로 진행된다. Pre-training에서 모델은 대규모 데이터로 “보편적 시각·텍스트 결합 능력”을 습득한다. 그러나 대규모 사전학습만으로는 여전히 취약한 세부 영역이 존재하기에 이를 보완하기 위해 Post-training이 수행된다.
MLLM(Qwen2.5-VL)은 계속 프리징이고, VAE는 인코더는 프리징, 디코더는 pre-training 구간에서만 별도 파인튜닝을 진행한다. MMDiT의 경우 Pre-training > SFT > DPO > GRPO 전 단계에서 계속 학습하며 업데이트된다.
4.2.1 Supervised Fine‑Tuning (SFT)
목적: Pre-training으로는 놓치기 쉬운 세밀한 영역을, 사람 주석 기반으로 직접 보정.
- 데이터셋 구성: 계층적 의미 카테고리(hierarchical categories)를 만들어 분류별로 취약점을 집중 공략.
- 샘플 선정 기준: 선명, 디테일 풍부, 밝음, 포토리얼리즘.
- 사람 주석 활용: 단순 캡션이 아니라 “이 프롬프트에는 이런 디테일이 반드시 살아야 한다”는 형태로 고품질 레이블.
- 효과:
- 프롬프트 충실도 ↑ (Prompt adherence)
- 질감·광원·모발·엣지 같은 미세 요소 개선
- 결과물의 사진적 리얼리즘 강화
즉, SFT는 “Pre-training에서 놓친 틈새를 수작업으로 메워주는 단계”라 할 수 있다.
4.2.2 Reinforcement Learning (RL)
목적: 단순히 “잘 맞다/틀리다” 수준을 넘어서,
- 사용자 선호에 정렬(Preference alignment)
- 세밀한 제어력 확보
두 가지를 달성한다.
4.2.2.1 DPO(Direct Preference Optimization)
- Flow matching 구조와 잘 맞고, 대규모 오프라인 데이터에도 효율적. 오프라인 방식
- 데이터 준비
- 같은 프롬프트로 여러 이미지를 생성 → 사람이 best와 worst 선택
- Gold reference가 있는 경우는 기준과 괴리가 큰 샘플을 “reject”로 지정
- 학습 개념
- 승자/패자 쌍의 velocity 오차 차이(Diff)를 비교
- 정책 모델이 참조(reference)보다 더 선호되는 쪽으로 흐름을 맞추도록 학습
- 효과
- 대규모 오프라인 정렬에 적합
- 전반적인 사용자 만족도를 빠르게 끌어올림
4.2.2.2 GRPO(Group Relative Policy Optimization)
- 세밀한 refinement에 적합. 온라인 (on-policy) 방식
- 방법:
- 한 프롬프트에서 여러 장(G개)을 생성
- Reward model 이 각 이미지를 점수 매김.
- 그룹 내 평균/표준편차로 보상 정규화 → 각 샘플의 상대적 “이점(Advantage)” 계산.
- on-policy 방식: 샘플을 생성하면서 즉시 보상 → 모델 weight 업데이트.
- Flow matching sampling이 원래 deterministic이라서, exploration(탐색성)을 위해 ODE → SDE로 reformulation + 노이즈 σt 주입.
- 효과:
- DPO에서 커버 못 한 세밀한 취향 조정 (예: 긴 문단 렌더링, 복잡 편집)
- 작은 영역의 퀄리티를 정교하게 다듬음
DPO로 광범위 오프라인 정렬을 먼저 수행하고, GRPO로 긴 문단 렌더링·복잡 편집 등 세부 영역을 미세 보정한다.
4.3 Multi‑task training
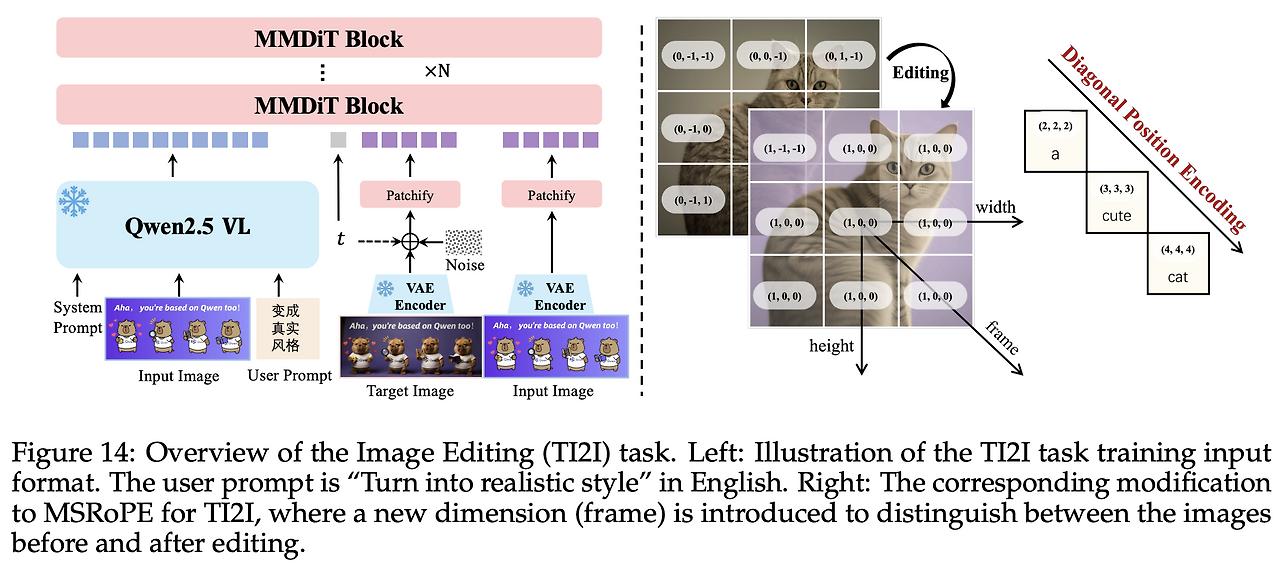
- 실사용 시나리오가 T2I만으로 끝나지 않음: 사용자 요구는 T2I뿐 아니라, 기존 이미지를 지시대로 바꾸기(TI2I), 원본을 그대로 재구성(I2I), 시점을 돌려보기(신규 뷰 합성), 심도/에지 등 고전 비전 과제까지 이어진다.
- 일관성·보존성 문제: 순수 T2I만 학습하면 편집 시 아이덴티티, 배경, 타이포그래피가 쉽게 깨진다. 입력 이미지의 픽셀 레벨 단서까지 활용해야 보존성이 올라감.
- 데이터·모델 효율: 여러 전용 모델 대신 하나의 백본(MMDiT) 안에서 태스크를 통합하면 데이터·인프라 파이프라인, 스케일링 전략, 추론 경로를 공유할 수 있어 학습·서빙 효율이 높다.
T2I 외에 TI2I(지시 기반 편집), 신규 뷰 합성, 깊이 추정 등을 단일 백본으로 아우른다. 이를 위해 두 가지 조건 신호를 함께 투입한다.
4.3.1 이중 컨디셔닝
- MLLM 의미 임베딩 h: 텍스트(+선택적 입력 이미지)에 대한 고수준 의미/문맥을 제공 → 프롬프트 순응, 지시 해석이 좋아짐.
- VAE 픽셀 임베딩 z: 입력 이미지 자체를 VAE 인코더로 잠재화한 신호 → 저수준 디테일·구조를 보존.
- 결합 방법: MMDiT의 이미지 스트림에 target 이미지의 노이즈 섞인 latent와 입력 이미지의 VAE latent를 시퀀스 방향으로 이어 붙여(concat) 투입한다.
- MMDiT는 텍스트 스트림과 이미지 스트림(입력 이미지 latent + 타겟 이미지/노이즈 latent) 위에서 joint self-attention을 수행한다.
- 학습은 flow-matching에 따라 타겟 noised image latent 토큰 위치에 한해 속도장 vθ(xt,t,h)을 예측하여 진행된다.
4.3.2 MSRoPE 확장: 프레임 축 도입
TI2I·신규 뷰 등 “다중 이미지가 동시에 입력”되는 상황을 구분하려고, 기존 (높이, 너비) 포지션인코딩에 프레임 축을 추가한다.
- 예) frame=0은 입력(레퍼런스), frame=1은 타깃(노이즈 섞인 latent).
- 이렇게 하면 동일 위치라도 “어느 프레임의 픽셀인지”를 모델이 명확히 구분한다 → 프레임 간 정합과 편집 안정성 향상.
4.3.3 시스템 프롬프트 설계

- T2I: 색•수량•텍스트•형상•크기•재질•공간 관계•배경 등을 구체적으로 서술하도록 시스템 템플릿을 구성
- TI2I: 먼저 입력 이미지의 핵심 특징을 요약하고, 이어서 사용자 지시가 어떻게 적용될지를 설명하도록 유도
4.3.4 학습 방법
- T2I
- 텍스트 → Qwen2.5-VL →
- 타깃 잠재 와 노이즈 로 중간 구성
- MMDiT가 예측 → loss
- 샘플링 후 VAE 디코더로 최종 이미지 복원
- TI2I(편집)
- 텍스트+입력 이미지 → Qwen2.5-VL → h
- 이미지 스트림에 [입력 이미지 VAE 잠재 z_in] ⊕ [타깃의 노이즈 섞인 잠재 x_t] 연결
- MSRoPE에 프레임 축을 추가해 두 그룹을 구분
- 타겟 토큰에만 속도장 MSE 적용(입력 z_in은 조건 신호로만 사용)
- I2I 재구성
- TI2I의 특수 케이스(“그대로 유지” 지시). 타깃=입력이므로 복원 정합을 강하게 학습 → 편집 시 비편집 영역 보존성이 올라감.
- 신규 뷰/깊이 등
- 동일한 입력 구성에서 지시 텍스트로 “좌로 90도 회전”, “깊이 맵으로 변환” 같은 목표를 명시하고 타겟 잠재의 속도장을 학습.
- 기타 학습 전략
- 혼합 비율: 초반엔 T2I 중심(일반 표현 학습) → 점차 TI2I/I2I 비중을 올림(보존·정합 강화).
- 배치 구성: 한 배치 안에 T2I/TI2I/I2I를 섞어 학습 안정성을 높이는 경우가 많다
- 샘플링 가중치: 텍스트-리치 합성 비율을 과도하게 올리면 스타일/심미성 분포가 흔들릴 수 있으니, 주기적 리밸런싱(자연 이미지 재주입)을 권장.
5. Experiments
5.1 인간 평가 (AI Arena)
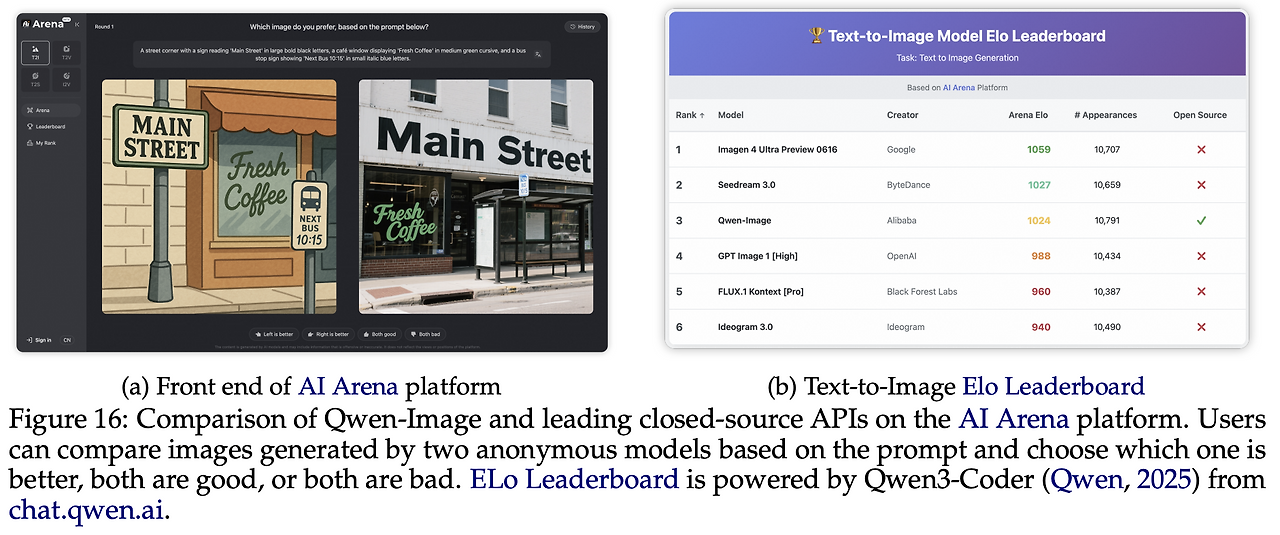
AI Arena는 Elo 레이팅 기반의 공개 벤치마크 플랫폼으로, 동일 프롬프트에 대해 무작위로 선정된 두 모델의 결과 이미지를 익명으로 제시하고 pairwise voting을 진행한다. 약 5천 개 프롬프트와 200명+ 평가자가 참여했으며, 각 모델은 최소 1만 회 이상 비교전을 치러 통계적 안정성을 확보했다.
- 비교 대상: Imagen 4 Ultra Preview 0606, Seedream 3.0, GPT Image 1 [High], FLUX.1 Kontext [Pro], Ideogram 3.0.
- 결과 핵심: Qwen-Image는 유일한 오픈소스 모델로 종합 3위. 1위(Imagen 4 Ultra Preview 0606) 대비 약 30 Elo 낮지만, GPT Image 1 [High]/FLUX.1 Kontext [Pro] 대비 30+ Elo 우위를 보임.
5.2 정량 평가 (Quantitative Results)
Qwen-Image의 기본 생성 능력과 텍스트 렌더링·편집 능력을 공개 벤치마크로 측정했다.
5.2.1 VAE 복원 성능
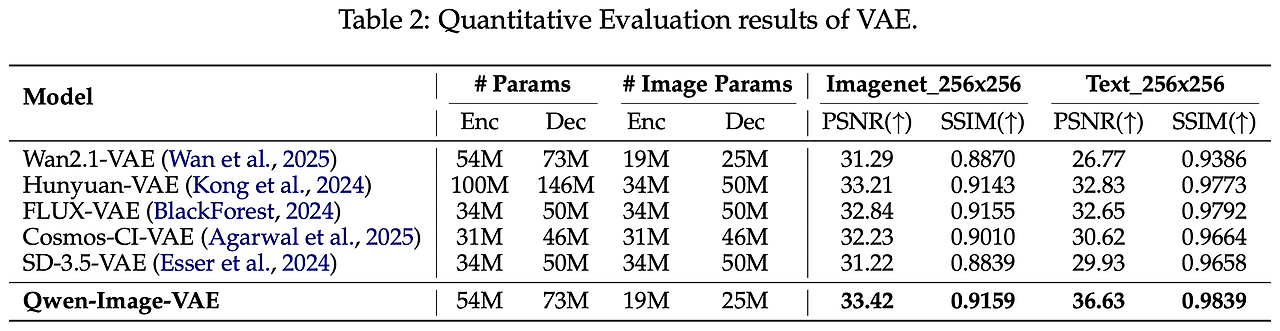
- 모든 토크나이저는 8×8 압축, latent C=16, ImageNet-1k 256×256에서 PSNR/SSIM 평가. 텍스트가 많은 사내 코퍼스에서도 추가 검증.
- Qwen‑Image‑VAE가 전 지표에서 SOTA. 특히 이미지 처리 시 Encoder 19M / Decoder 25M만 활성화하여 품질–효율 균형을 달성.
5.2.2 Text-to-Image(T2I) 성능
일반 생성력과 텍스트 렌더링을 분리 평가했다.
- DPG (1K dense 프롬프트): 종합 1위(Overall 88.32). 속성/관계 해석과 프롬프트 정합에서 두드러짐.
- GenEval (구성적 프롬프트): SFT 기준 0.87, RL 후 0.91로 리더보드 0.9 돌파 유일
- OneIG‑Bench (EN/ZH): 영어/중국어 두 트랙 모두 종합 1위. 특히 Alignment·Text 카테고리 1위로 프롬프트 추종·문자 렌더링이 강점.
- TIIF Bench mini (지시 따르기): 종합 2위, GPT Image 1에 이어 근소 열세.
텍스트 렌더링 특화
- CVTG‑2K(영문): 평균 Word Accuracy 0.8288, NED 0.9116, CLIPScore 0.8017로 상위권.
- ChineseWord(중문 단자 렌더링): Overall 58.30%로 모든 난이도(1~3급) 합산 최고.
- LongText‑Bench(장문): ZH 0.946(1위), EN 0.943(2위). 장문·다영역 텍스트 레이아웃 충실도가 높음.
5.2.3 Image Editing (TI2I) 성능
- GEdit‑Bench (실사용 지시 11종): EN G_O 7.56, ZH G_O 7.52로 양 트랙 상위권/1위권. 다국어 지시 일반화 확인.
- ImgEdit (9개 편집 과제, 734 케이스): Overall 4.27로 1위. 지시 적합성·편집 품질·세부 보존 균형 우수.
- Novel View Synthesis (GSO): PSNR 15.11 / SSIM 0.884 / LPIPS 0.153로 특화 모델에 준하는 SOTA급.
- Depth Estimation (NYUv2/KITTI/ScanNet/DIODE/ETH3D): DepthPro 교사 신호로 SFT만 적용했음에도 확장 모델군과 대등.
T2I, TI2I 에서 모두 SOTA 급의 성능을 보여주고 특히 텍스트 렌더링에 강하다는 걸 강조하고 있음.
5.3 정성 평가 (Qualitative Results)
5.3.1 VAE 복원

- 텍스트가 빽빽한 PDF/포스터에서 작은 영문 단어(예: “double‑aspect”) 가독성을 또렷하게 복원. 타 VAE 대비 미세 획/커닝/자간 유지가 우수.
5.3.2 T2I

- 영문 텍스트: 장문 문단·다지점 표지/슬라이드에서 누락/오자/중복 없이 정확한 렌더링. 난해 레이아웃도 미적 균형 확보.
- 중문 텍스트: 대련·상점 간판·유리판 문단 등에서 복잡 자형을 정확히 재현. 공간 배치·원근에 맞춘 기하 정합.
- 다객체·혼합 언어: 12지 인형 배열, 당구공 이중열 배치 등 개수/위치/스타일 제약을 동시 만족.
- 공간 관계: 인물 상호작용·소도구 거리·접촉 관계를 정확히 구현.
5.3.3 TI2I

- 텍스트/재질 수정: 원본 스타일 보존 상태에서 텍스트 치환·법랑(glaze) 질감 등 재질 충실도 높음.
- 객체 추가/제거/교체: 비편집 영역의 배경·광원 일관성을 잘 유지.
- 포즈 조작: 머리카락/의복 디테일 유지, 배경 변형 최소화.
- 체인드 편집: 추출→확대, 배치→줌아웃 시나리오에서 구조적 일관성(예: 선미 구조) 유지.
- 뷰 회전(±90°): 인물/배경 동시 회전 등 전역 일관성에서 강세.
Qwen-Image는 복잡한 텍스트 렌더링과 정밀 편집을 동시에 끌어올린 오픈소스 이미지 생성·편집 모델이다. 테크니컬 리포트는 모델 구조, 데이터 파이프라인과 커리큘럼, pre/post-training 등 다양한 정보를 담고 있다.
다만, 학습과 관련한 구체적인 레시피—특히 pre/post-training을 순차적으로 진행하면서 어떻게 성능을 유지·향상시켰는지에 대한 부분—는 공개되어 있지 않아 아쉬움이 남는다. 결국, 테크니컬 리포트를 읽는 것만으로 이 수준의 모델을 직접 설계하고 학습까지 해낼 수 있는 기업은 극히 제한적일 것이라는 생각이 든다.
