S1-WEEK3 Note 01 : Vector / Matrix
학습목표
- vector 기본연산
- matrix 기본연산
- numpy
Warm-up : Essence of Linear Algebra
- 수학적관점
vector can be anything
두 벡터의 덧셈, 벡터의 상수배...etc 같은 연산이 성립하면 뭐든 벡터
Linear Regression (선형회귀)
numpy, pandas, scikitlearn 라이브러리로 계산
데이터 표현 방법
순서(order)가 유지 되어야 함
-
list []
<-> set (집합, 순서X) -
pd.DataFrame
-
np.array (가장 많이 쓰임)
-
np.matrix (권장X)
Determinant (행렬식)
Regression
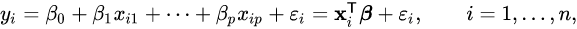
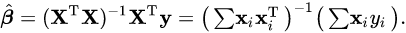
scipy
from scipy import stats
stats.linregress([ ], [ ])Dimensionality Reduction : PCA, SVD
사이즈가 큰 데이터셋을 사이즈가 작은 부분으로 나누는 작업 (일반적으로 시각화나 다른 모델링을 위해서 사용)
딥러닝 : CNN
- Convolving
필터, 커널을 (작은 매트릭스) 통해 이미지를 축소화 하여 그 결과물을 분석에 사용
필터를 통해서 수정된 이미지는 특수한 부분이 "강조"되어 이미지 분석에 사용 가능
vector
-
n차원 벡터
n개의 원소(컴벡터의 길이(length)는 벡터의 차원수와 동일포넌트)를 가지는 순서를 갖는 모음 -
벡터의 길이(length)는 벡터의 차원수와 동일
vector의 크기 (Magnitude, Norm, Length)
Matrix
Matrix의 크기 Dimension
표현방법(행->열 순서)
- 3x3
- 3 by 3
square matrix
-
Diagonal (대각)
-
Upper Triangular (상삼각)
-
Lower Triangular (하삼각)
-
Identity (단위 매트릭스)
Diagonal 매트릭스 중에서, 모든 값이 1인 경우 -
Inverse(역행렬)
-
Symmetric (대칭)
Determinant (행렬식)
singular matrix (특이 매트릭스)
인 매트릭스
2개의 행 혹은 열이 선형의 관계를 (M[,i]= M[,j] * N) 이루고 있을때 발생
매트릭스의 행과 열이 선형의 의존 관계가 있는 경우 매트릭스의 행렬식은 0이다.
np.array와 list의 차이
- list
a = [1, 2, 3]
b = [4, 5, 6]
a + b
Out:
[1, 2, 3, 4, 5, 6]- np.array
import numpy as np
a_np = np.array(a)
b_np = np.array(b)
a_np + b_np
Out:
array([5, 7, 9])np.array
- 각 성분들의 곱
a_np * b_np
Out:
array([ 4, 10, 18])- 내적
#solution1
(a_np * b_np).sum()
#solution2
np.dot(a_np, b_np)
Out:
32