
1. Introduction
-
LLM의 출력 길이가 모델의 추론 성능과 시간에 미치는 요인을 분석하고, 이를 평가하기위한 새로운 메트릭 기법을 제안
-
모델에 최대치보다 짧은 길이의 출력을 명시적으로 요청해서 LLM이 간결한 추론을 하도록 유도함
-
Llama2-70b 기준 _ GSM8K 벤치마크
- 단어수 : 99(CoT) → 71(CCoT-100)
- 정확도 : 36.01%(CoT) → 41.07(CCoT-100)
-
Falcon-7b, Vicuna-13b과 같은 작거나 중간 크기의 모델은 오히려 CCoT로 인해 정확도 감소
2. Motivational considerations
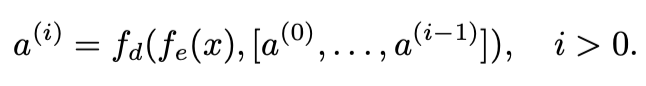
 |
 |
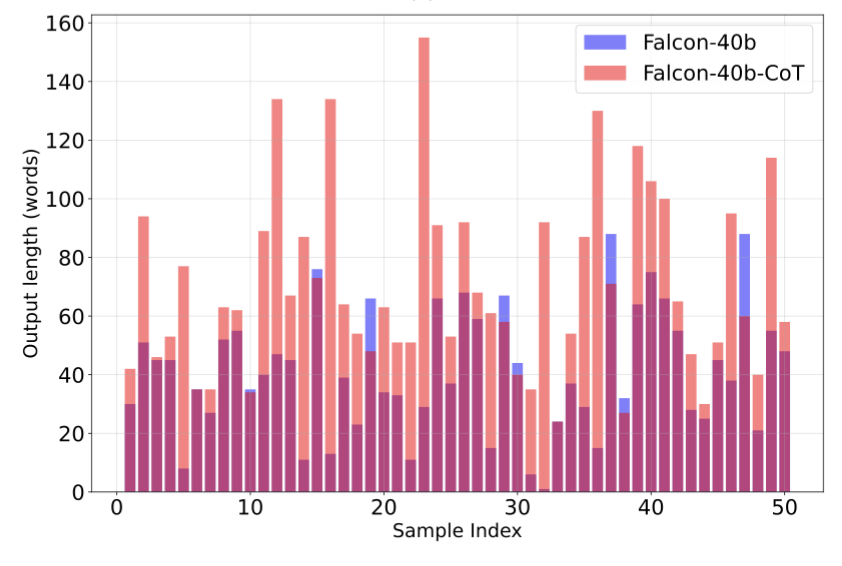 |
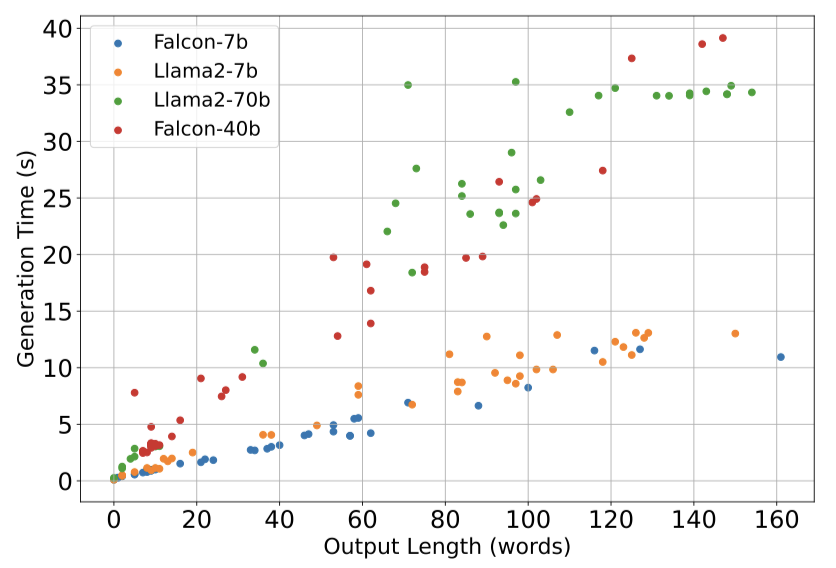
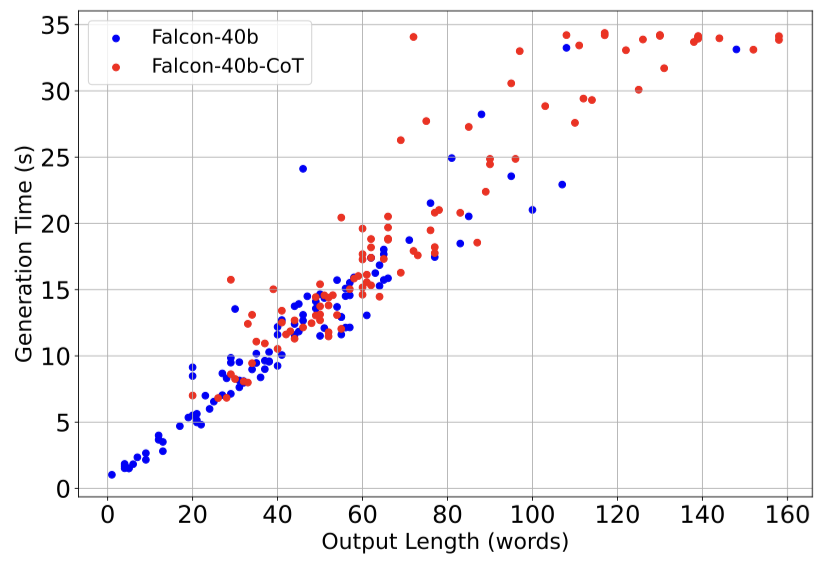
그림1. 단어수 별 생성에 걸리는 시간
3. Metrics for concise correctness

[방정식1. 모델의 정확도를 계산하는 식]
- ŷ(모델의 출력)이 y(실제 값)와 얼마나 일치하는지 평가.
- Γ 함수는 출력을 후처리(정규 표현식 기반)하여 특정 포맷이나 기준에 맞춰 조정하는 역할.
- Γ에서 정규표현식 대신 Pseudo-judge을 사용한 접근 → 보조로 대규모 모델 사용.
- 데이터의 진위 판단하거나 내용의 적합성을 평가하는등의 판단 작업 수행
- 주로 머신러닝 모델이 독립적인 평가자로서 작동하는 상황에서 사용
- Γ에서 정규표현식 대신 Pseudo-judge을 사용한 접근 → 보조로 대규모 모델 사용.
- 각 샘플의 평가 결과 합산 후 N(전체 샘플 수)로 나누어 정확도 계산↓
[방정식2. 방정식1에 간결성을 추가한 공식]
- ŷ의 간결성을 정확성과 통합하기 위해 패널티 항을 곱해줌
- 출력의 길이가 길어질수록 값이 감소 → 길이가 긴 출력에 대해 패널티 부여
Hard-k Concise Accuracy : HCA(K)
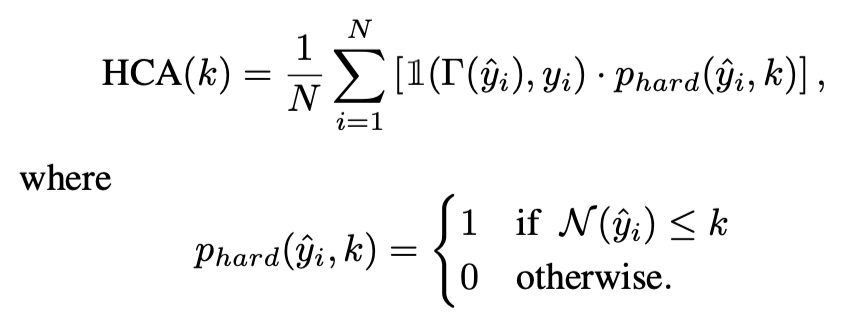 [방정식3. 특정 길이(k)를 초과하지 않는 출력의 비율 측정]
[방정식3. 특정 길이(k)를 초과하지 않는 출력의 비율 측정]
-
길이 제한을 만족하는지를 확인하는 함수 추가
-
출력의 길이가 사용자가 지정한 최대 길이(K) 이하라면 1, 초과라면 0을 반환
-
출력이 정확하면서도 짧은 응답을 생성하는데 초점을 맞춤, 길이 제약이 엄격할 때 유용함
-
실시간 시스템이나 컴퓨팅 자원이 제한된 환경에서 유용하다
-
엄격한 정확도라고 할 수 있음
- k == 100일때 101단어로 답변하면 0이 되어버림
Soft-K Concise Accuracy : SCA(k,α)
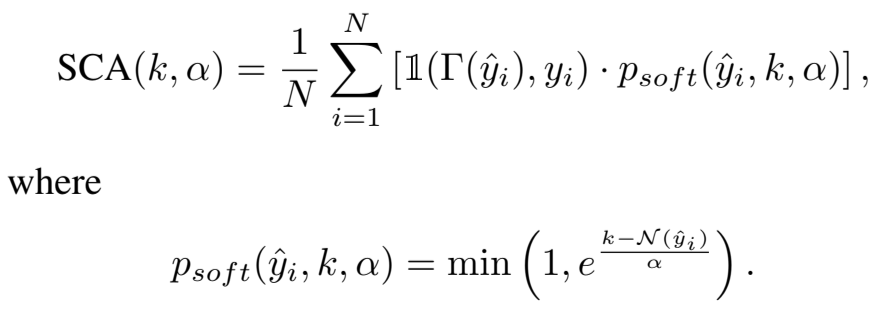 [방정식4. 특정길이(K)를 초과하면 점수 감소 패널티(α)]
[방정식4. 특정길이(K)를 초과하면 점수 감소 패널티(α)]
-
HCA를 일반화
-
α는 사용자가 지정하는 감소 인자(decay factor)
- α 값이 클수록 출력 결과가 K를 초과해도 허용범위가 넓어짐
- α == 0 이라면 SCA == HCA
-
관대한(?) 정확도라고 할 수 있음
- k == 100 일때 150단어로 답해도 답변이 정확하다면 60점은 답을 수 있음
Consistent Concise Accuracy : CCA(K,α, β)
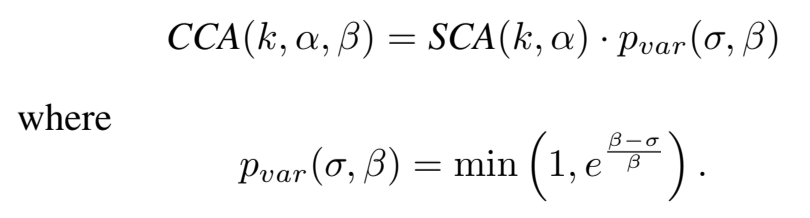 [방정식5. 출력된 모든 응답의 길이 변동성 고려]
[방정식5. 출력된 모든 응답의 길이 변동성 고려]
-
SCA(k,α)의 값에 길이 변동성에 대한 패널티항을 곱해줌
-
σ는 출력 길이의 표준편차(standard deviation) → 출력 길이의 변동성
- σ ↓
- 일관된 길이의 응답 생성
- 출력 시간 예측 가능성 ↑
- σ ↑
- 응답의 길이가 크게 변동
- 출력 시간 예측 가능성 ↓
- σ ↓
-
β는 길이 변동성에 대한 허용도 조절하는 매개변수
- β값이 클수록 더 큰 길이 변동성 허용
- σ ≤ β 라면 1이 되어 길이 변동성에 따른 패널티 X
- σ ≥ β 라면 패널티항이 지수적으로 감소하여 패널티 O
-
응답 길이의 일관성도 보는 정확도
- 일부는 60단어로, 일부는 150 단어로 답하는 것보다 일관된 단어수로 답하는게 더 좋은 점수
4. CCoT Prompting
 [그림2. CoT와 CCOT 비교]
[그림2. CoT와 CCOT 비교]
-
CoT
- x = concat(x_us, x_p)
- x_us는 사용자의 입력, x_p는 생성된 답변에서 추론 단계를 포함하도록 하는 명시적 요청
- “Let’s think a bit step by step”
-
CCoT
- x = concat(x_us, x_p, x_l)
- x_l은 출력 길이에 대한 제한을 명시하는 문장
- “limit the answer length to 45 words”
-
더 적은 단어를 쓰고 있음에도 답을 맞추는걸 볼 수 있음
5. Experiments
-
RQ(Research Questions)
- RQ1. Is the CCoT approach beneficial in terms of efficiency and accuracy?
- RQ1. CCoT 접근법이 효율성과 정확성 측면에서 유익한가?
- RQ2. Which Model benefit from CCoT, compared to classic CoT?
- RQ2. 어떤 모델들이 클래식 CoT에 비해 CCoT 접근법의 이점을 누리는가?
- RQ3. How capable is an LLM of controlling the output length based on an explicit prompt request?
- RQ3. LLM이 명시적인 프롬프트 요청에 따라 출력 길이를 제어하는 능력은 어느정도인가?
- RQ4. Are the proposed metrics helpful in addressing both efficiency and accuracy aspects? Is the impact of CCoT reflected in the proposed metrics?
- RQ4. 제안된 평가 지표들이 효율성과 정확성 측면에서 유용한가? CCoT의 영향이 제안된 지표들에 반영되고 있는가?
- RQ1. Is the CCoT approach beneficial in terms of efficiency and accuracy?
-
LLM
- Vicuna-13b-v1.5
- Falcon-40b-instruct
- Falcon-7b-instruct
- Llama2-7b-chat-hf
- Llama2-70b-chat-hf
-
test set
- GSM8k
RQ1. Is the CCoT approach beneficial in terms of efficiency and accuracy?
 [그림2. CoT와 CCOT 비교]
[그림2. CoT와 CCOT 비교]
RQ2. Which Model benefit from CCoT, compared to classic CoT?
-
대형 모델(Llama2-70b, Falcon-40b)
- Llama2-70b
- 자가회귀적 대형 언어 모델
- 인간 피드백을 기반으로 미세조정, 다양한 범용 및 오픈소스 데이터셋을 사용하여 훈련
- CCoT 프롬프트로 출력길이를 효과적으로 제어, 간결한 답변, 정확도 ↑, 응답 시간 ↓
- Falcon-40b
- RefinedWeb 데이터를 사용하여 훈련
- CCoT를 사용해도 CoT의 정확도를 넘지는 않음, 하지만 Base보다는 나은 성능을 보여주었고, CoT에 비해 응답 시간 ↓
- 정확도를 조금 포기하고, 시간을 단축시킴
- Llama2-70b
-
소형 모델(Falcon-7b, Llama2-7b)
- Falcon-7b
- CCoT-100 같은 경우에서 오히려 추론 시간도 길어지고, 정확도도 떨어짐
- Llama2-7b
- CCoT 프롬프트에서 짧은 길이를 사용했을 때 정확도가 매우 낮음
- Falcon-7b
-
CCoT 프롬프트의 효과는 모델의 크기와 훈련 방식에 크게 의존함. 대형모델은 CCoT의 이점을 잘 활용하지만, 소형 모델은 CCoT 조건을 적절하게 처리하지 못해 오히려 성능이 저하되거나 응답 시간이 길어지는 경향이 있음.
RQ3. How capable is an LLM of controlling the output length based on an explicit prompt request?
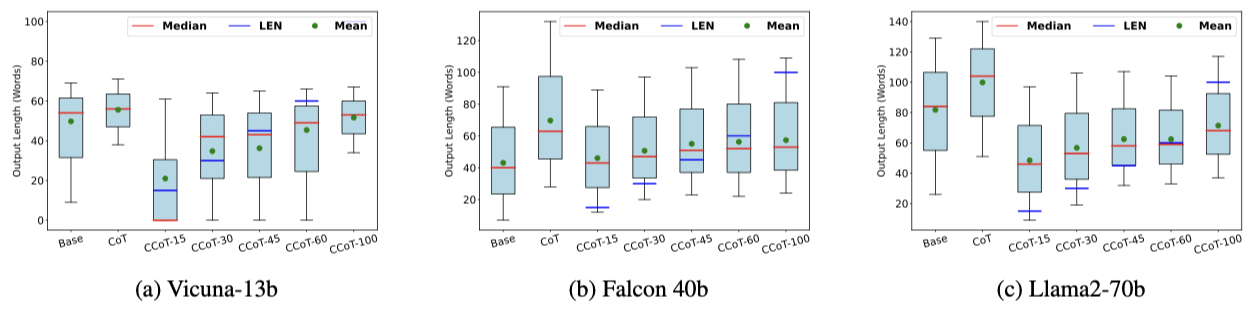
-
Median : 중앙값
- 데이터 셋에서 값을 크기 순으로 정렬했을 때 가운데 위치한 값
-
Len : 길이 제한
- CCoT 프롬프트에서 명시한 출력의 최대 길이
-
Mean : 평균값
- 모든 데이터 포인트의 합을 데이터 포인트의 개수로 나눈 값
-
15, 30, 45 단어와 같은 짧은 값에는 거의 준수하지 못하고 있음
RQ4. Are the proposed metrics helpful in addressing both efficiency and accuracy aspects? Is the impact of CCoT reflected in the proposed metrics?
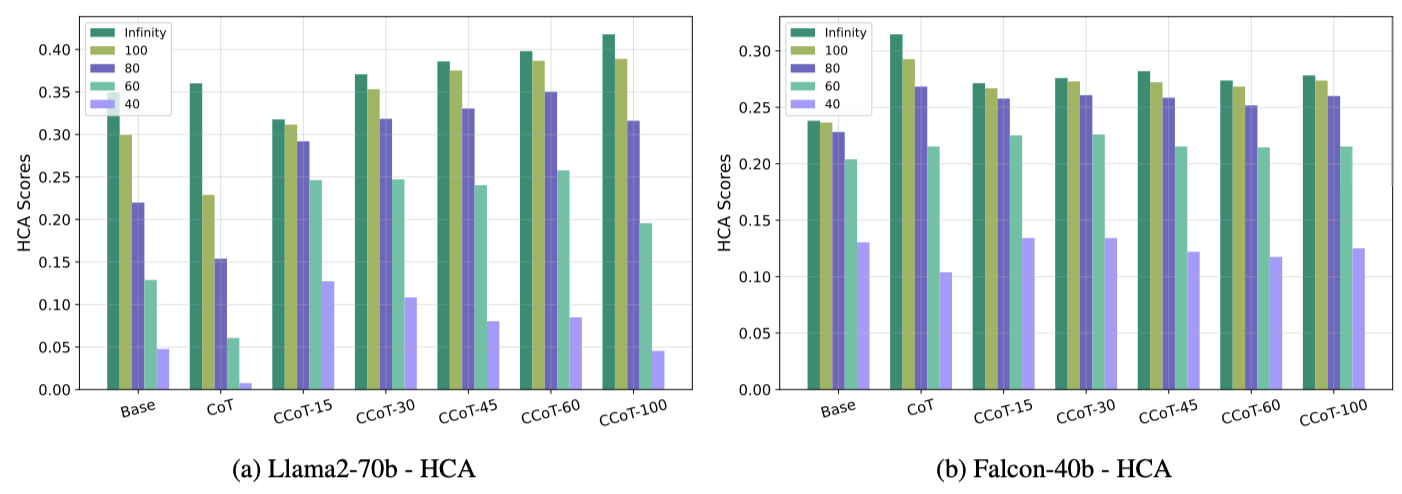
HCA evaluation
-
k = ∞ 는 classic accuracy
-
CCoT-100은 문장 생성할 때 100단어 이하로 생성해달라고 프롬프트에 적용하는 것이고
각 막대의 숫자는 HCA를 계산할 때의 K값을 의미한다.
-
classic accuracy와 비교했을 때, HCA값은 항상 같거나 낮음
- 출력 길이가 제한될수록 평가 대상이 되는 출력의 수가 줄어들기 때문
- CCoT 프롬프트를 사용하면 HCA값이 classic accuracy보다 크게 감소하지는 않음
- CCoT가 출력 길이를 효과적으로 제어하면서 정확성을 유지할 수 있음을 의미
-
Llama2-70b
- CCoT를 사용하면 모든 k값에 대해 base, CoT보다 더 나은 성능을 보임
- CCoT-30 이상부터 더 나은 성능을 보임
- k값이 100, 80, 60일 때 성능 향상이 눈에 띔
- k가 40처럼 매우 작을때는 CoT에서 매우 낮은 점수를 보임
- CoT가 논리적 추론을 포함하다보니 출력 길이를 초과함
- 길이 제한이 너무 엄격하지 않을 때 CCoT가 더 효과적 이라는 것을 보여줌
- CCoT를 사용하면 모든 k값에 대해 base, CoT보다 더 나은 성능을 보임
-
Falcon-40b
- CCoT가 base와 CoT사이에서 타협점을 제공하는 역할을 할 수 있음
- k가 60,40과 같이 작을때도 CCoT를 사용한 HCA값이 CoT보다 높음
- CCoT가 base와 CoT사이에서 타협점을 제공하는 역할을 할 수 있음
CCoT를 적용했을 때 classic accuracy가 높아진건 좋은 듯 하다.
그런데 HCA는 길이 제한을 염두에 둔 계산 식이니까 CCoT를 적용한게 점수가 좋게 나오는건 당연한거 아닌가 하는 의문이 생긴다.
Falcon-40b에서는 오히려 CoT가 CCoT보다 Score가 높은데, 그러면 CoT에 비해 CCoT의 출력 시간이 얼마나 줄었는지도 있었으면 좋았을듯 하다.
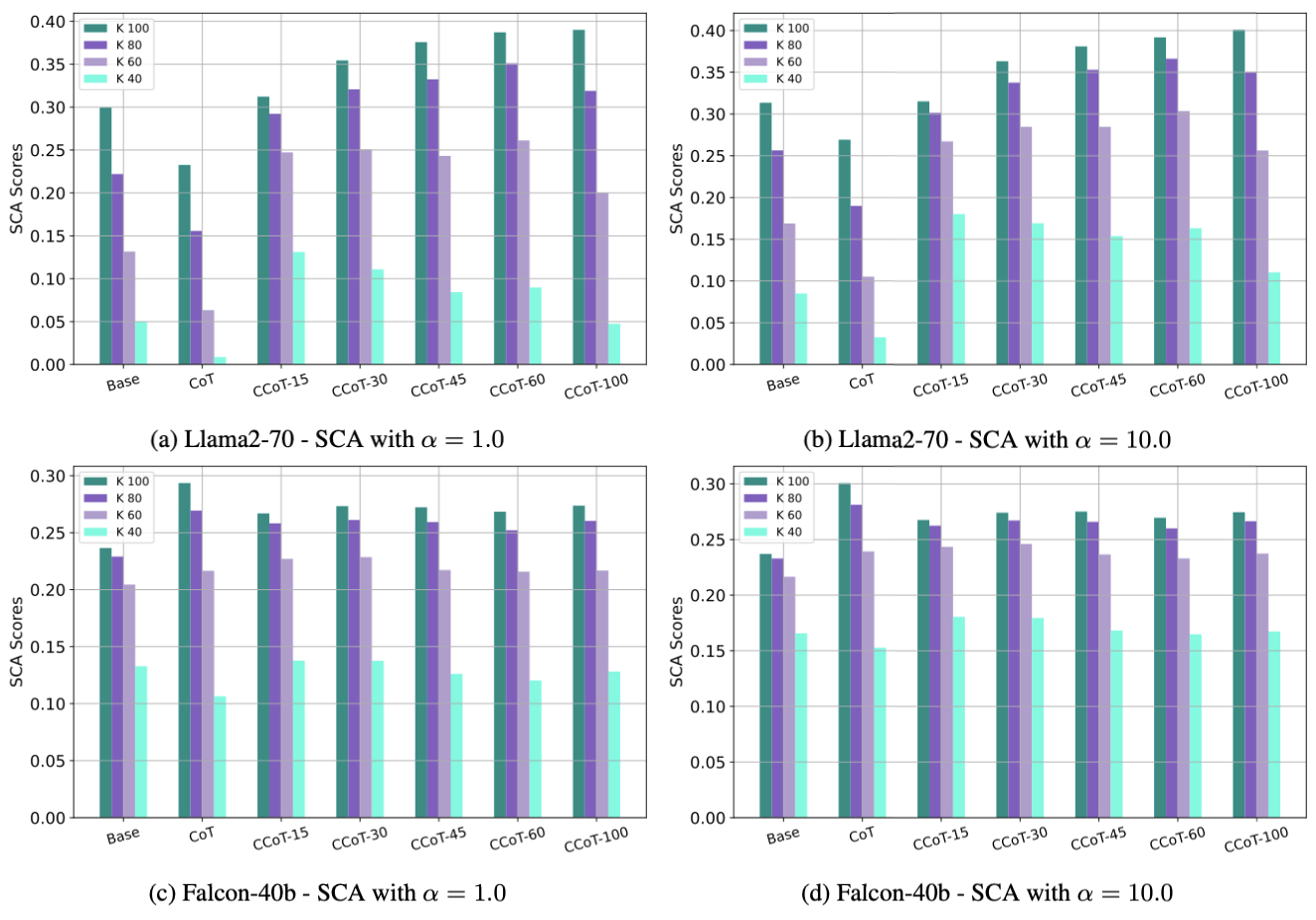
SCA evaluation
-
높은 k
- k값이 80, 100처럼 높을때는 SCA와 HCA값이 유사하게 나옴
- CCoT 프롬프트에서 이정도 길이제한은 효과적으로 출력 길이를 제한할 수 있음
- α의 필요성 ↓
-
낮은 k
- k값이 40일 때 SCA값이 HCA를 초과
- 일부 출력이 k값을 초과함을 의미
- α값을 높이면 Base나 CoT 프롬프트보다 높은 성능 향상을 보임
-
모델 비교
- Llama2-70b 모델이 Falcon-40b 모델보다 길이를 더 잘 제어하고 정확한 출력 생성
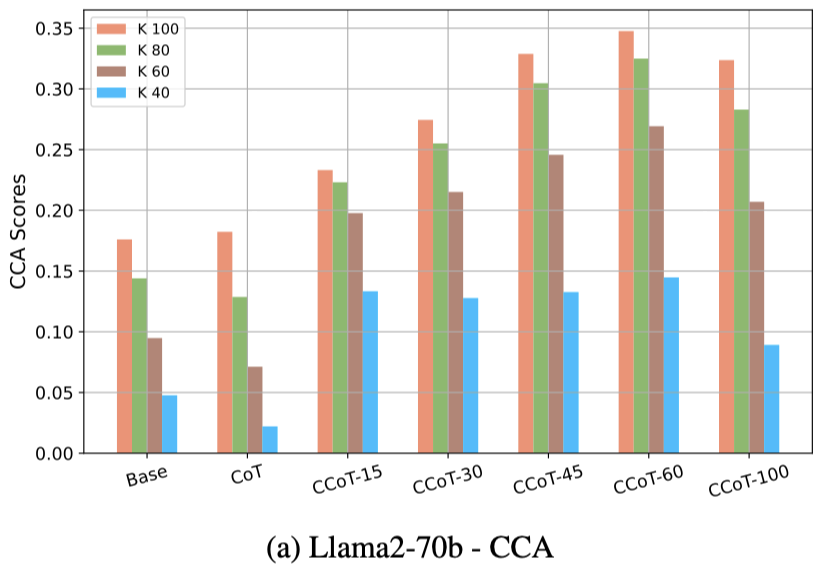
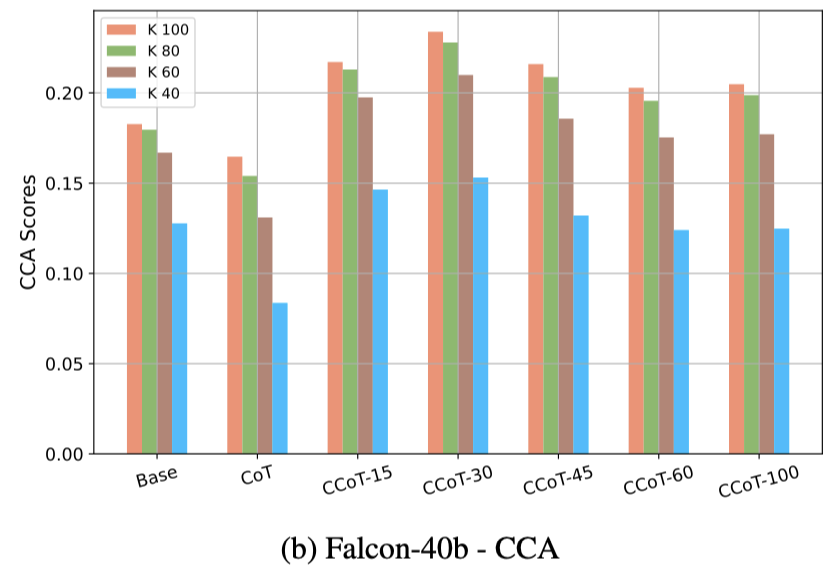
CCA evaluation
 |  |
|---|
-
높은 k
- k값이 100일 때 CCA점수가 감소하는 경향 있음
- 길이 제한에 대한 범위가 커질수록 출력 길이 변동성이 증가
- k값이 100일 때 CCA점수가 감소하는 경향 있음
-
낮은 k
- Llama2-70b 모델에서 CCoT를 적용한게 Base나 CoT보다 항상 높음
Illustration of CCoT

-
첫번째 예시
- CoT
- 추론 과정이 확장되지만, 길이가 많이 늘어남
- CCoT
- 올바른 추론 과정과 정확한 답변을 제공하면서도 짧은 문장 길이
- CoT
-
두번째 예시
- Base, CoT
- 올바른 추론 과정을 거쳤지만 마지막에 답을 틀렸음
- CCoT
- 올바른 추론 과정과 정확한 답변을 제공하면서도 짧은 문장 길이
- Base, CoT
6. Discussion and Conclusions
- 소형 모델의 어려움
- Falcon-7b, Llama2-7b, Vicuna-13b 같은 작은 모델에서 CCoT 길이제한을 준수하기 어려움
- 훈련에 사용된 데이터셋이나 모델 파라미터 수와 같은 여러 요인 때문인것으로 보임
- 대형 모델의 이점
- Falcon-40b, Llama2-70b와 같은 대형 모델에서 정확성과 효율성 ↑
- Llama2-70b, Vicuna-13b 모델에서 정확성의 개선이 관찰
- Vicuna-13b같은 경우에는 길이 제한을 완벽하게 준수하기는 어려웠지만 정확성이 개선되었음을 보임
