Abstract
- 질문과 관련이 있지만 답을 포함하지 않은 문서는 LLM의 정확도를 하락시킬 수 있음
- 무작위 문서(무관한 문서)를 RAG 시스템에 추가했을 때 오히려 LLM의 정확도가 상승하였음
- 검색된 문서의 개수가 증가할수록 성능 저하
- 골드 문서가 프롬프트 내애서 질문과 가까운 위치에 있을 때 정확도가 높아짐
Condition
Dataset
- Natural Questions(NQ) dataset
- 구글 검색 데이터에서 실제 사용자 쿼리를 기반으로 수집된 데이터
{
"Question": "Short Answer",
"Long Answer": {
"question_text": "who founded google",
"question_tokens": ["who", "founded", "google"],
"document_url": "http://www.wikipedia.org/Google",
"document_html": "<html><body><h1>Google</h1><p>Google was founded in 1998 by ..."
}
}- NQ-Open dataset
- NQ 데이터셋과 달리 정답이 특정 Wikipedia에 직접 연결 X
| Question | Answer |
|---|---|
| where did they film hot tub time machine | Fernie Alpine Resort |
| who has the right of way in international waters | Neither vessel |
| who does annie work for attack on titan | Marley |
- Wikipedia dataset
- 100단어 구절로 나뉘어 사용
Types of Documents
문서 유형 분류
- 골드 문서 (Gold Document)
- 쿼리에 대한 답변과 직접적인 연관이 있는 문서
- 관련 문서 (Relevant Documents)
- 쿼리에 대한 답변에 유용한 문서
- 방해 문서 (Distracting Documents)
- 쿼리에 직접적으로 답변하지 않지만, 의미적 또는 맥락적으로 주제와 연결된 문서
ex) 나폴레옹의 말 색깔을 물어봤을 때, 조제핀 드 보아르네(첫 번째 아내)의 말 색깔을 묘사하는
문장은 정확한 정보를 포함하고 있지는 않지만 연관성은 높다
- 쿼리에 직접적으로 답변하지 않지만, 의미적 또는 맥락적으로 주제와 연결된 문서
- 무작위 문서 (Random Documents) 🂦
- 쿼리와 전혀 관련이 없는 문서(정보적 노이즈)
Retrieval
Two-step approach
- 첫 번째 단계에서 질문에 대해 검색된 문서 선택
- 두 번째 단계에서 검색된 문서를 바탕으로 답변 생성
Contriever
- BERT 기반 밀집 검색기
- 텍스트 데이터를 벡터로 변환하여 문서와 질문간의 의미적 일치도 계산
FAISS IndexFlatIP
- 문서 벡터와 질문 벡터의 내적을 계산하여 가장 유사한 문서들 반환
LLM Input
입력 구성 요소
- 문서 (top-k documents)
- Contriever
- FAISS IndexFlatIP
- 작업 지시 (task instruction)
- 질문 (query)
NQ-Open 데이터셋의 특성
- NQ-Open 데이터셋은 답변이 다섯 토큰 이하로 구성
- 따라서 LLM은 최대 다섯 개의 토큰으로 구성된 답변을 생성
프롬프트 디자인

- 작업지시 → 문서 → 질문
LLMs Tested
-
Greedy 생성 방식
-
최대 답변 길이 15토큰
-
4비트 양자화
-
Few-Shot Learning 없이 사용
-
Base와 Instruct 버전 중 Instruct 버전에 중점
-
Llama2(7B)
-
Falcon(7B)
-
Phi-2(2.7B)
-
MPT(7B)
Accuracy
- NQ-Open 데이터셋에서는 하나의 질문에 여러 가지 형태의 답이 있을 수 있음
- 사전에 정의된 정답 중 하나라도 LLM의 응답에 포함되어 있는지를 확인
- President D. Roosevelt 또는 President Roosevelt
- 하지만, 답이 President Roosevelt일 때 Roosevelt라고만 답하면 정답 X
Impact of Distracting Documents
- 방해 문서의 수 ↑ 정확도 ↓
- 방해 문서 한 개만 추가되어도 정확도가 0.24 (25%) 감소
- 방해 문서 많아질수록(특히 10개 이상), 정확도가 0.38 (67%) 하락하는 사례도 관찰되었음
Results


- 골드 문서의 위치가 LLM의 성능에 미치는 영향 분석
- 문서 위치 설정
- Near : 문서가 질문 바로 옆에 위치
- Mid : 문서가 중간에 위치
- Far : 문서가 질문에서 가장 멀리 위치
I Task instruction
⭐️ Gold Document
🔗 Distracting Document
🂦 Random Document
Q Query
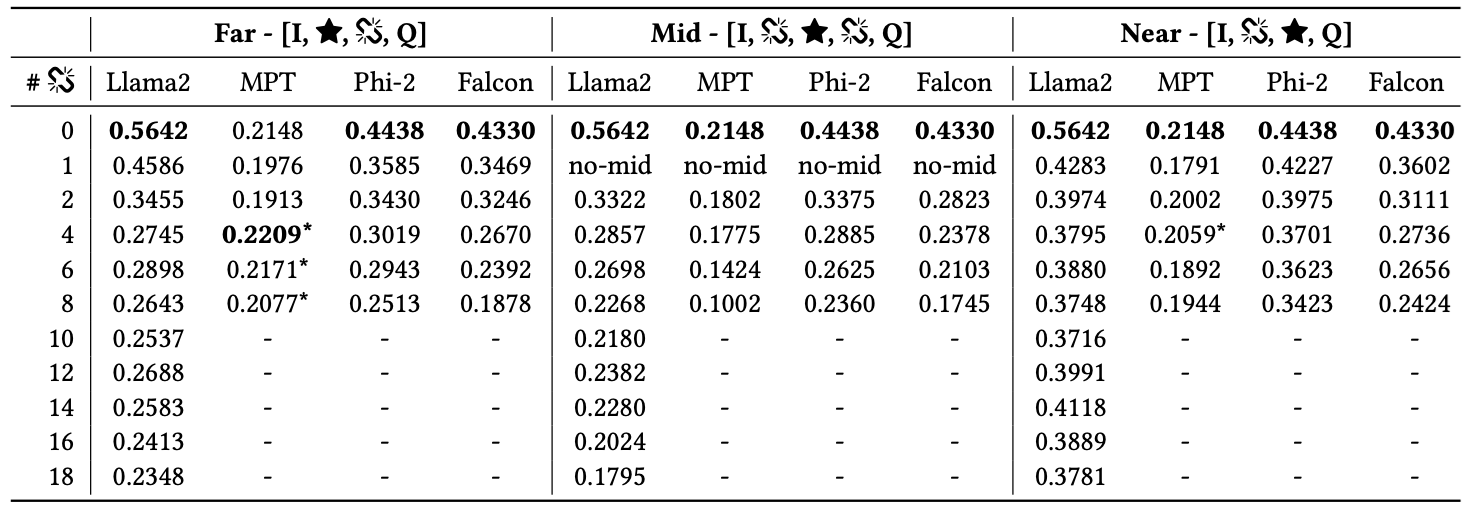
방해 문서의 수, 문서의 위치에 따른 정확도 계산
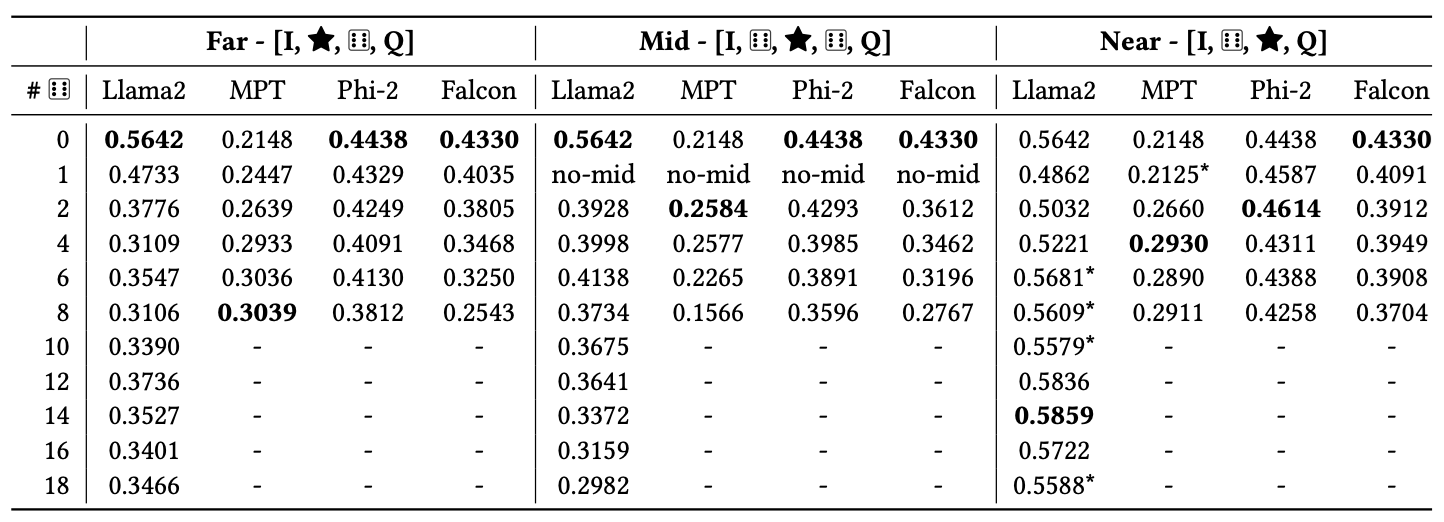
랜덤 문서의 수, 문서의 위치에 따른 정확도 계산
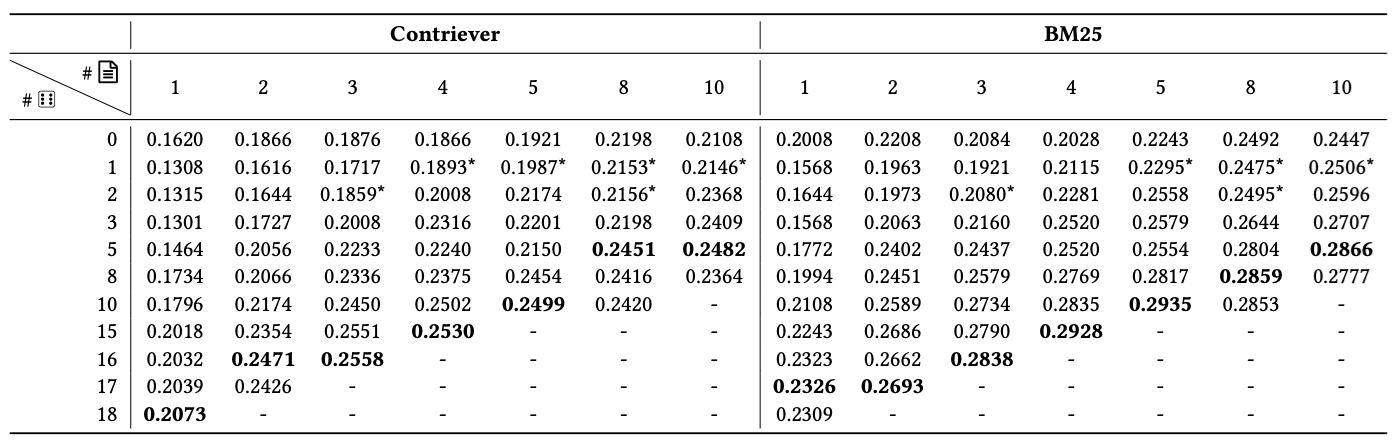
행 : 무작위 문서 수 열 : 검색된 문서 수
- Random Document가 오히려 모델의 성능을 개선하였음
- Related Document는 모델의 성능에 안좋은 영향을 줌
- Gold Document는 Query의 근처에 놓이는 것이 좋음
Related Document는 사용자 질문에 대한 내용이 포함되어 있기는 하지만 정답은 없었기에 모델에 혼란을 주는것으로 예상.
개인적인 생각
- 실제로 사용하기 위해선 질문에 대한 Gold Document가 어떤건지 잘 알고 있어야 GoldDocument와 Random Document를 넣을 수 있는것인데, Gold Document를 이미 알고있다면 RAG를 할 필요가 있을까?
- 기존 RAG가 엉뚱한 답변을 하는 경우가 여러 문서의 유사도가 근소한 차이만 있을 때 발생한다고 생각함. 그래서 Random Document를 넣어주면 유사도가 확연한 차이를 보이기에 RAG가 잘 되는게 당연하다고 생각한다.
