0.주피터 노트북 깃허브 링크
https://github.com/guraudrk/bootcampcode_Deeplearning_pytorch
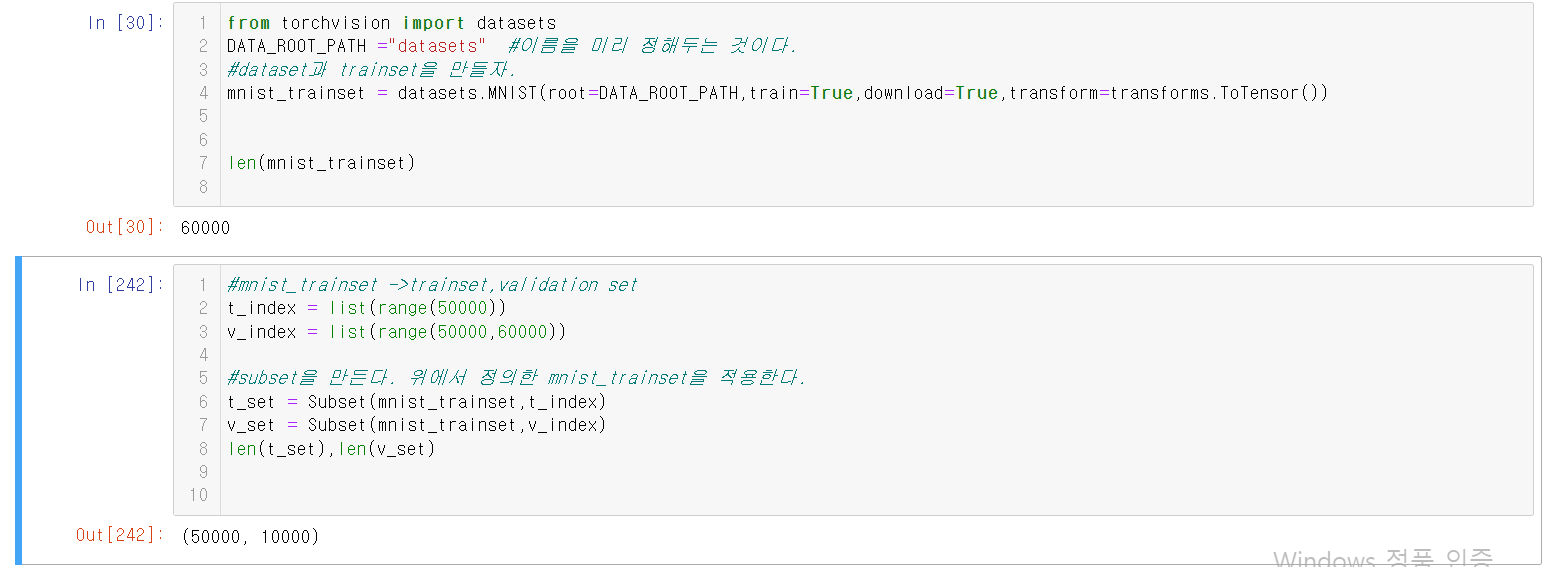
1.Dataset과 DataLoader
torch.utils.data.Dataset은 원본 데이터셋을 저장하고 있으면 인덱싱을 통해 데이터를 하나씩 제공한다.
torch.utils.data.DataLoader는 Dataset의 데이터를 batch단위로 모델에 제공하기 위한 객체이다.
보통 반복문을 통해 데이터에게 값을 제공하는데, 보통의 타입은 iterable 타입이다.
2.간단하게 이야기해서, 데이터를 dataset이라고 하고,
dataloader는 데이터를 제공하는 놈이다.
dataloader는 데이터를 제공하는 놈이기 때문에 1놈밖에 없다.
3.Built-in Dataset
파이토치는 분야별 공개 데이터셋을 종류별로 torchvision, torchtext,
torchaudio 모듈을 통해 제공한다.
모든 built-in dataset은 torch.utils.data.Dataset의 하위클래스로
구현되있다.
built in 은 한마디로 파이토치에서 제공한 dataset이라는 의미이다.
4.Image Built-in dataset Loading
torchvision 모듈을 통해 다양한 오픈소스 이미지 데이터셋을 loading할
수 있는 Dataset 클래스를 제공한다.
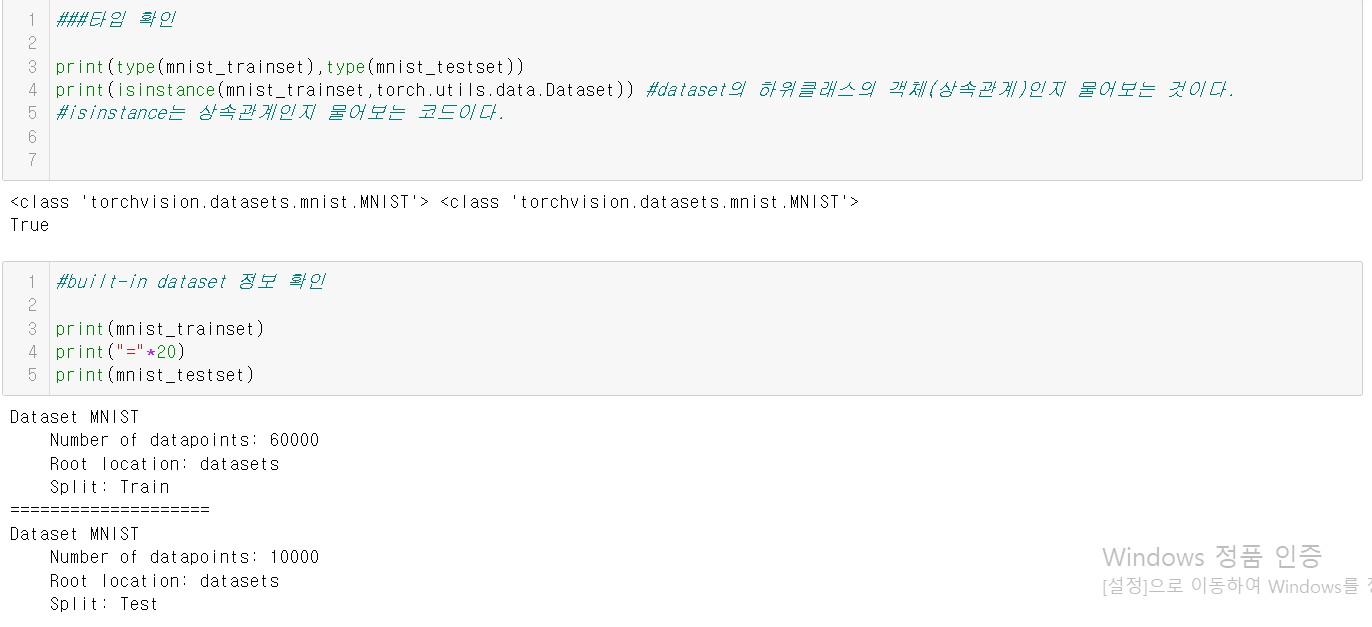
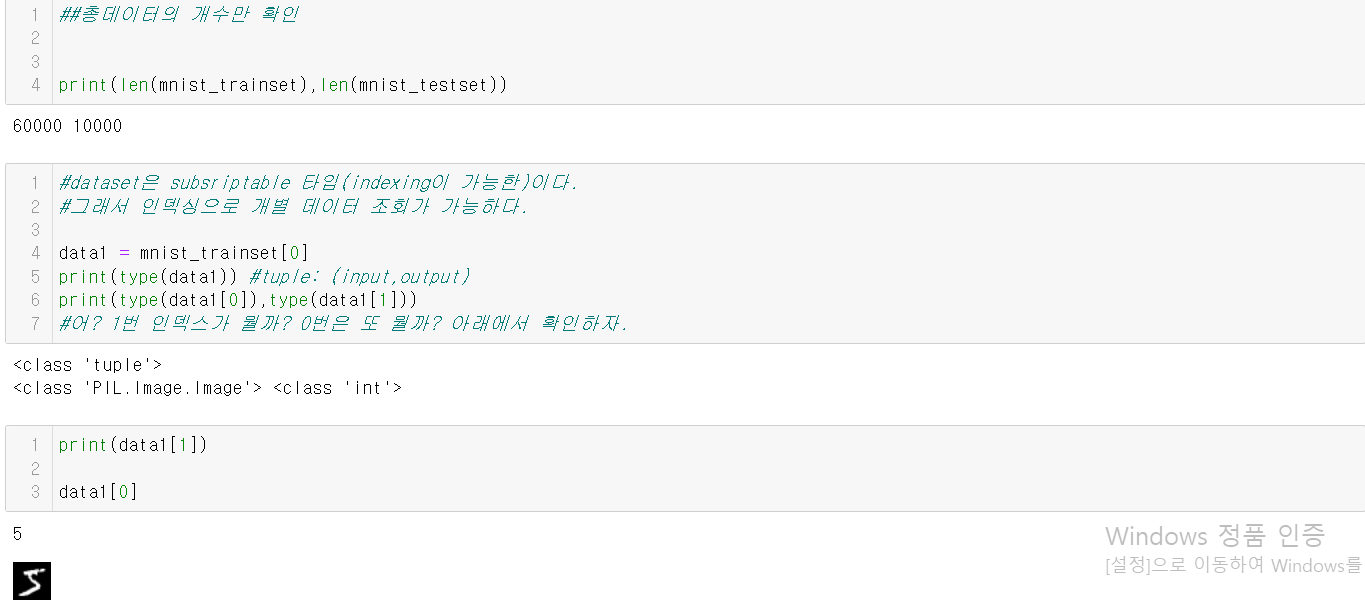
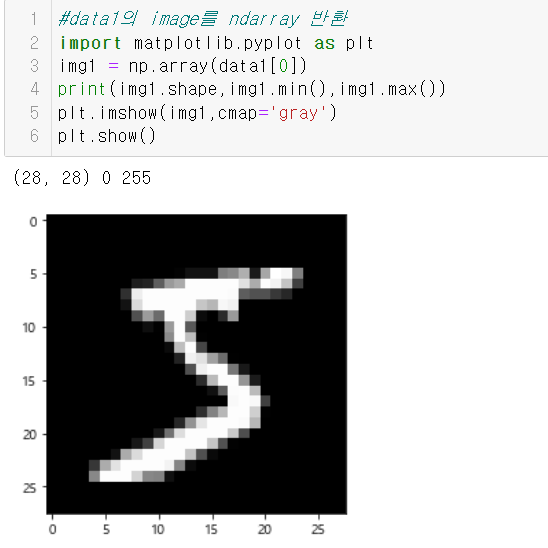
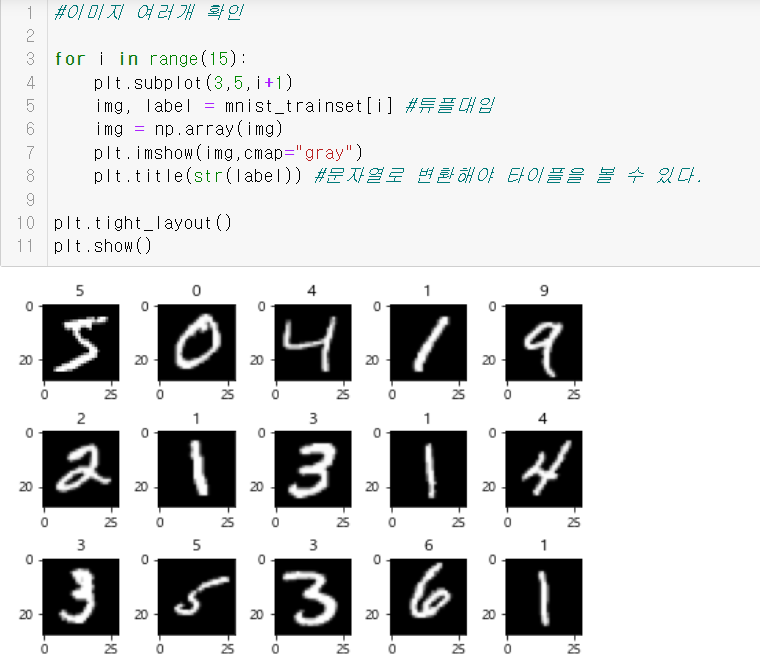
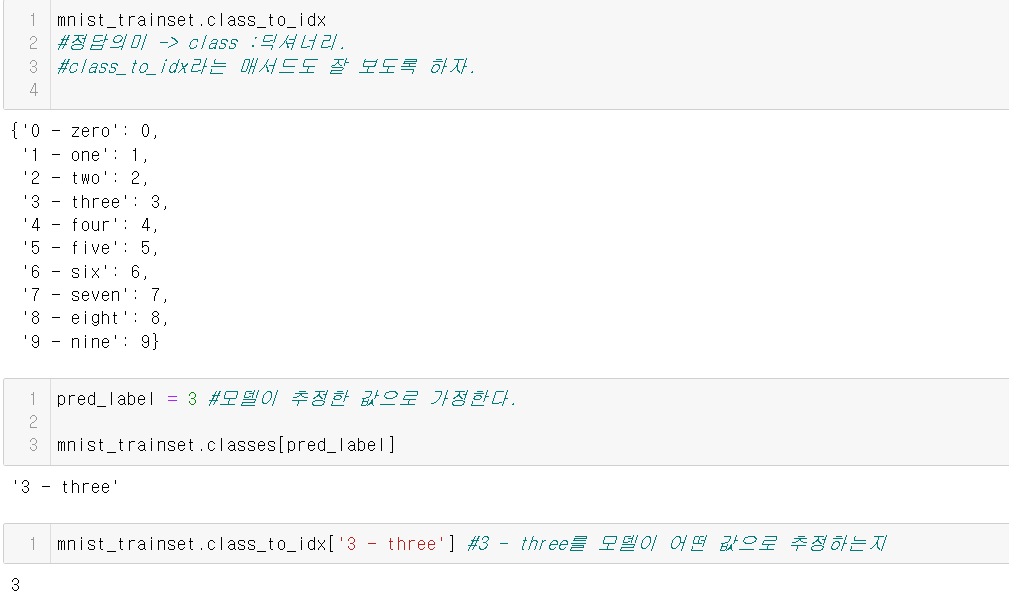
아래는 이와 관련된 예시 코드의 캡쳐본이다. 결과에 사진도 포함이 되어 사진으로 대체한다.



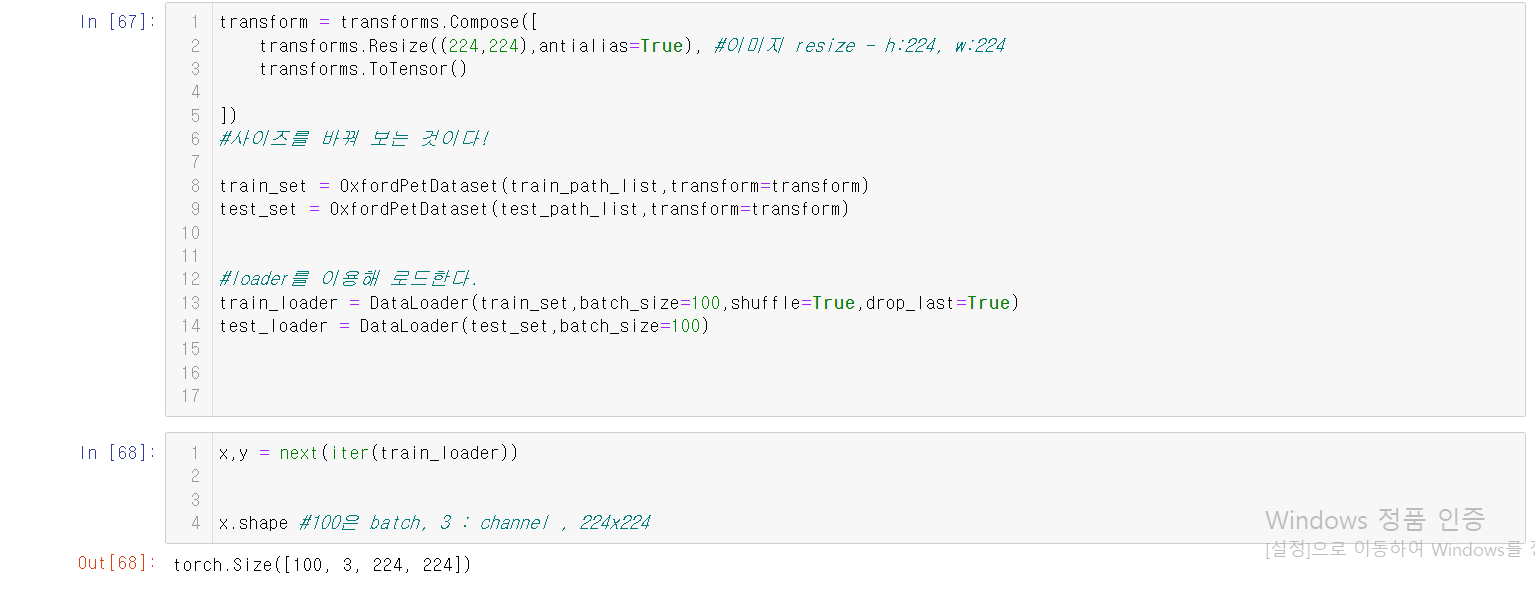
5.transform 매개변수를 이용한 데이터전처리
Dataset 생성할 때 전달하는 함수로 원본데이터를 모델에 주입(feeding)하기 전 전처리 과정을 정의한다.
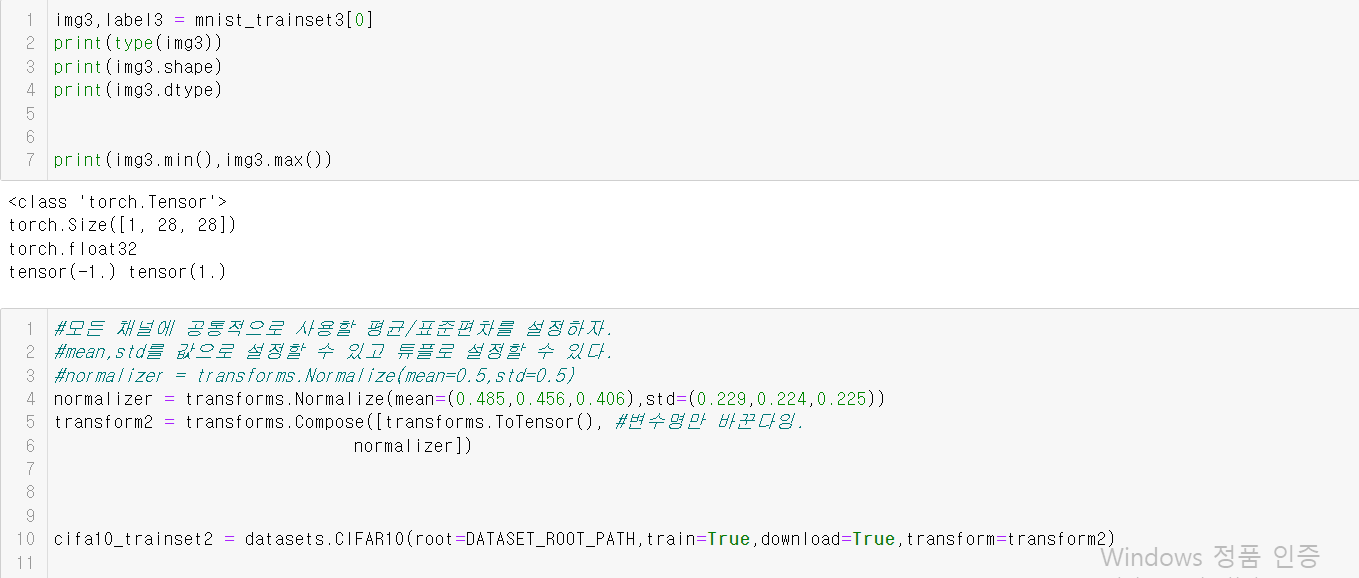
1.torchvision.transforms.ToTensor
IL Image나 NumPy ndarray 를 FloatTensor(float32) 로 변환하고, 이미지의 픽셀의 크기(intensity) 값을 [0., 1.] 범위로 비례하여 조정한다.


2.transform.Normalize
채널별로 지정한 평균을 뺀 뒤 지정한 표준편차로 나누어서 정규화를 진행한다.
torchvision.transforms.Compose 클래스를 이용한다.



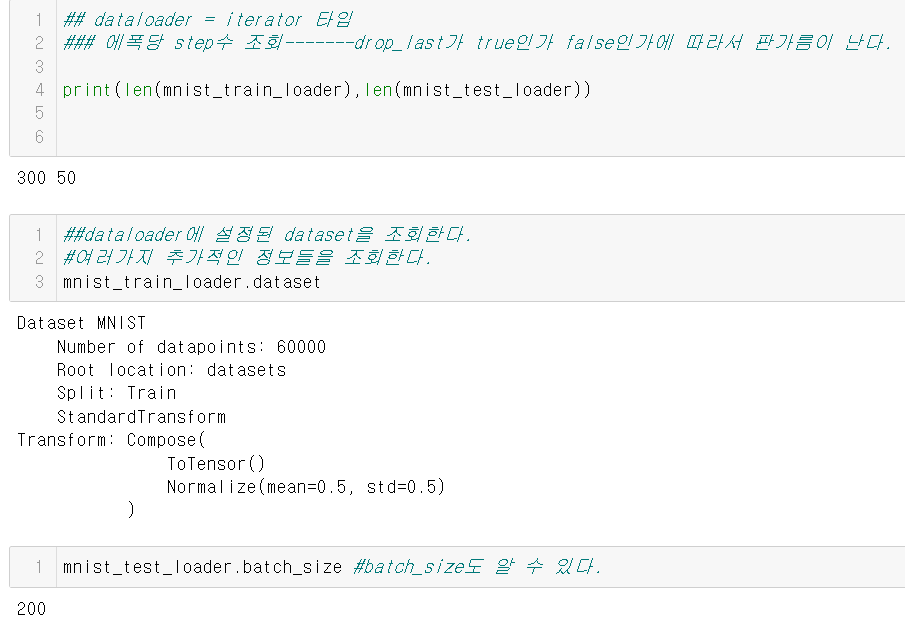
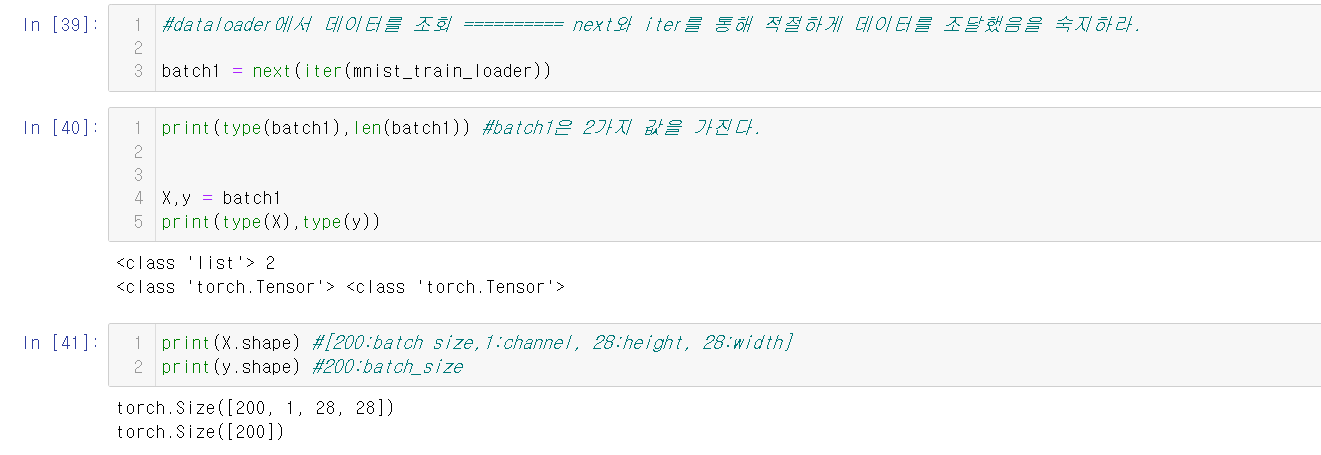
3.DataLoader 생성
DataLoader는 모델이 학습하거나 추론할 때 dataset의 데이터를 모델에 제공한다.

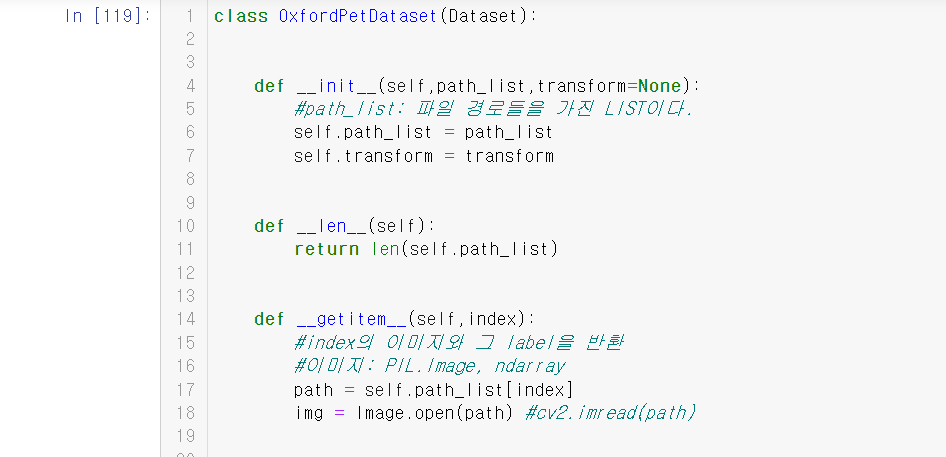
4.Custom Dataset 구현
1.init(self,....)
dataset 객체 생성시 필요한 설정들을 초기화한다.
2.len(self)
총 데이터수를 반환하도록 구현한다.
3.getitem(self,index)
index의 data point를 반환한다.
input(X), output(y) 를 튜플로 반환한다.
아래는 custom dataset의 예시이다.
#subscriptable 타입 클래스 구현 ->indexing 기능 객체
class Mysub():
def __init__(self):
#제공할 값들을 초기화한다.
self.one = "사자"
self.two = "호랑이"
self.three = "하마"
def __len__(self):
#제공할 데이터의 개수를 반환.
return 3
#인덱스를 반환하는 함수이다.
def __getitem__(self,idx):
# idx의 값을 반환
if idx==0:
return self.one
elif idx==1:
return self.two
elif idx==2:
return self.three
else:
raise IndexError(f"{idx}번째 값이 없습니다.")5.OxfordPet Dataset 생성
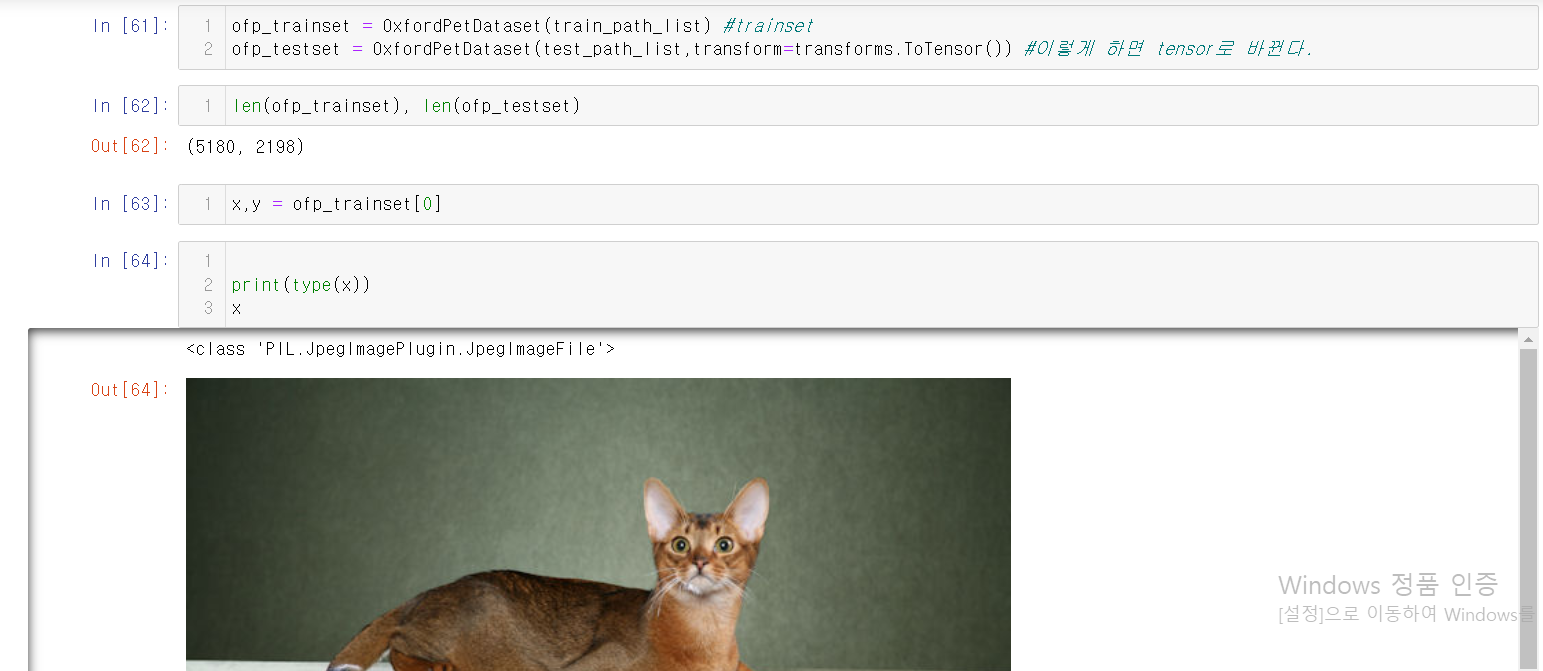
딥러닝을 한 문제의 예시라고 볼 수 있다.
아래는 홈페이지 링크이다.
https://www.robots.ox.ac.uk/~vgg/data/pets/
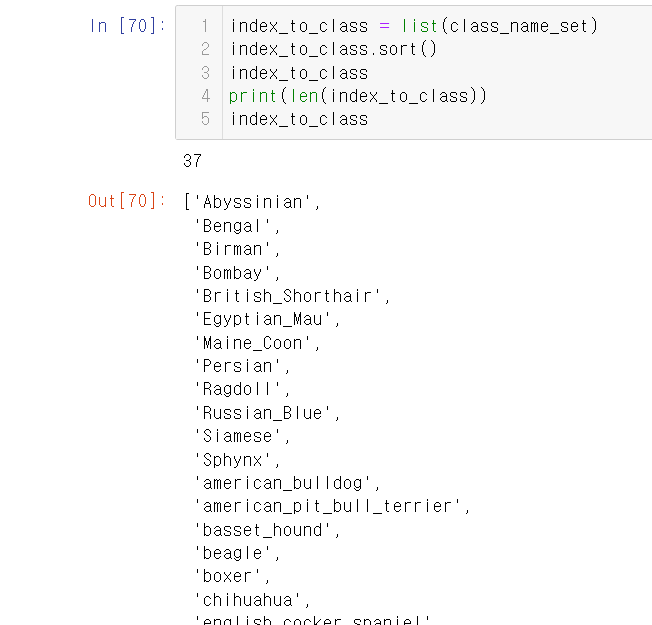
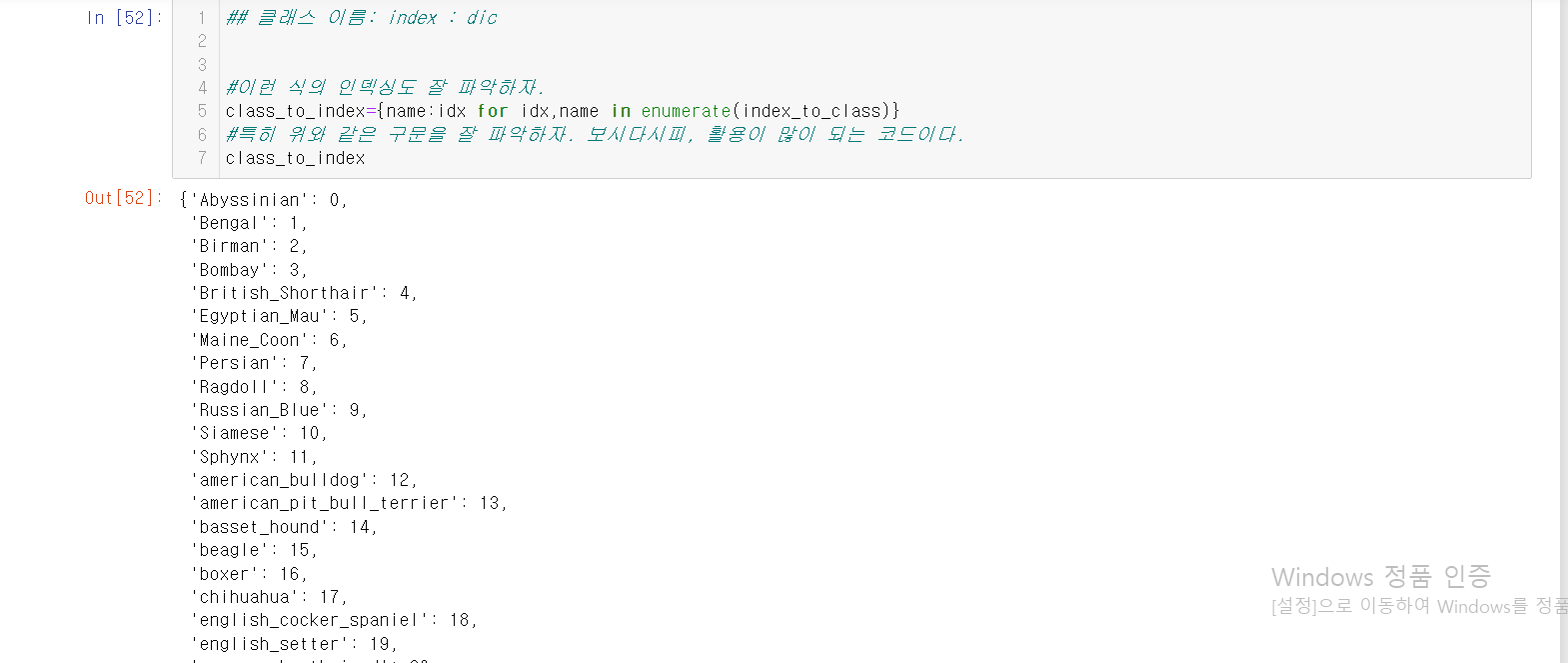
개,고양이가 총 37개 품종이 있으며,
품종별로 200장 정도씩 구성이 되었다.
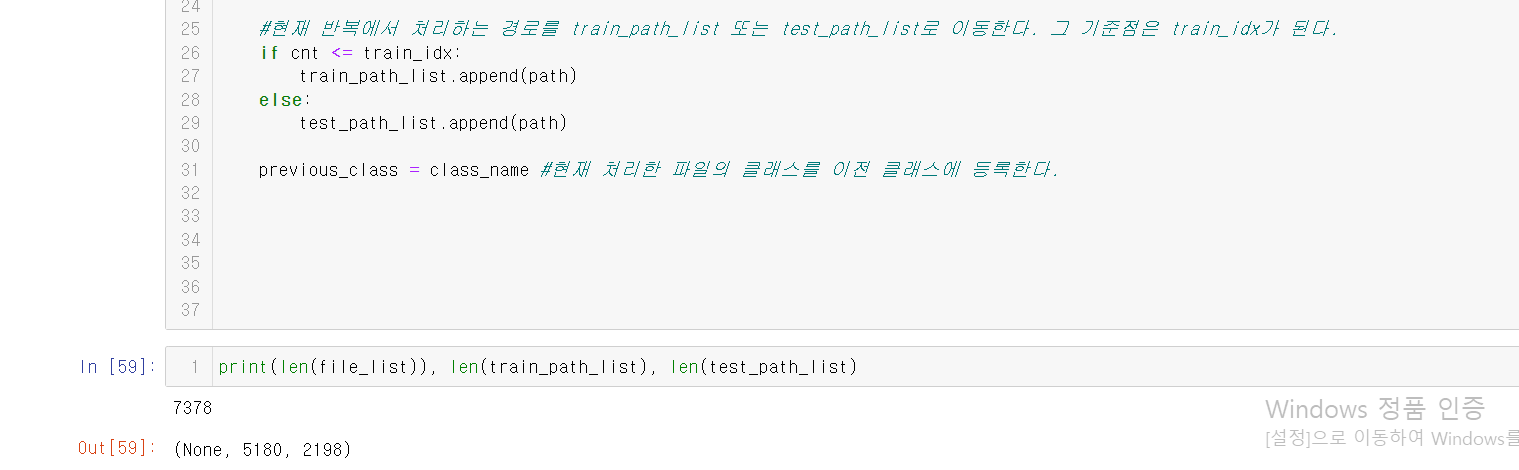
우리의 목표는 train:valid:test의 비율을 7:2:1로 조정하는 것이다.
아래의 이미지들을 잘 보면서 한 호흡에 내용을 이해하도록 하자.
부연설명은 중간중간에 #을 이용해서 잘 적었으니 걱정 마시라.



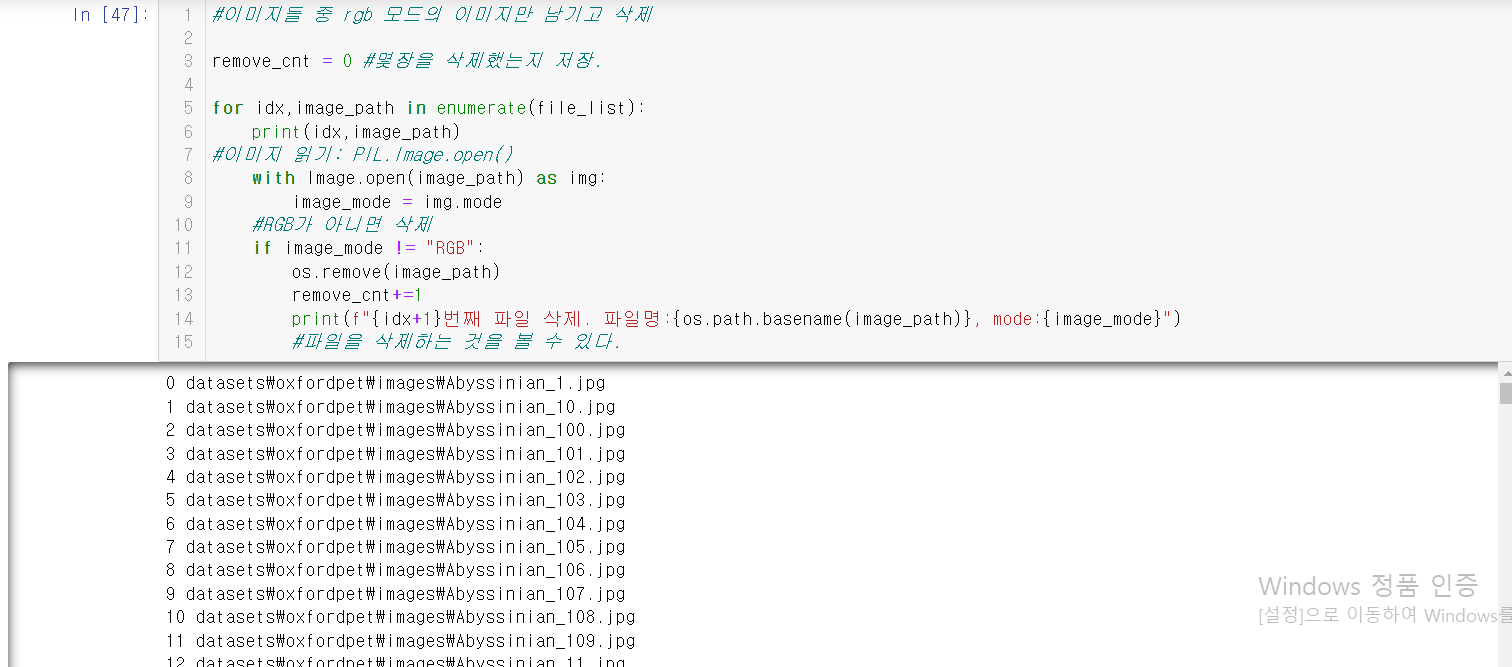
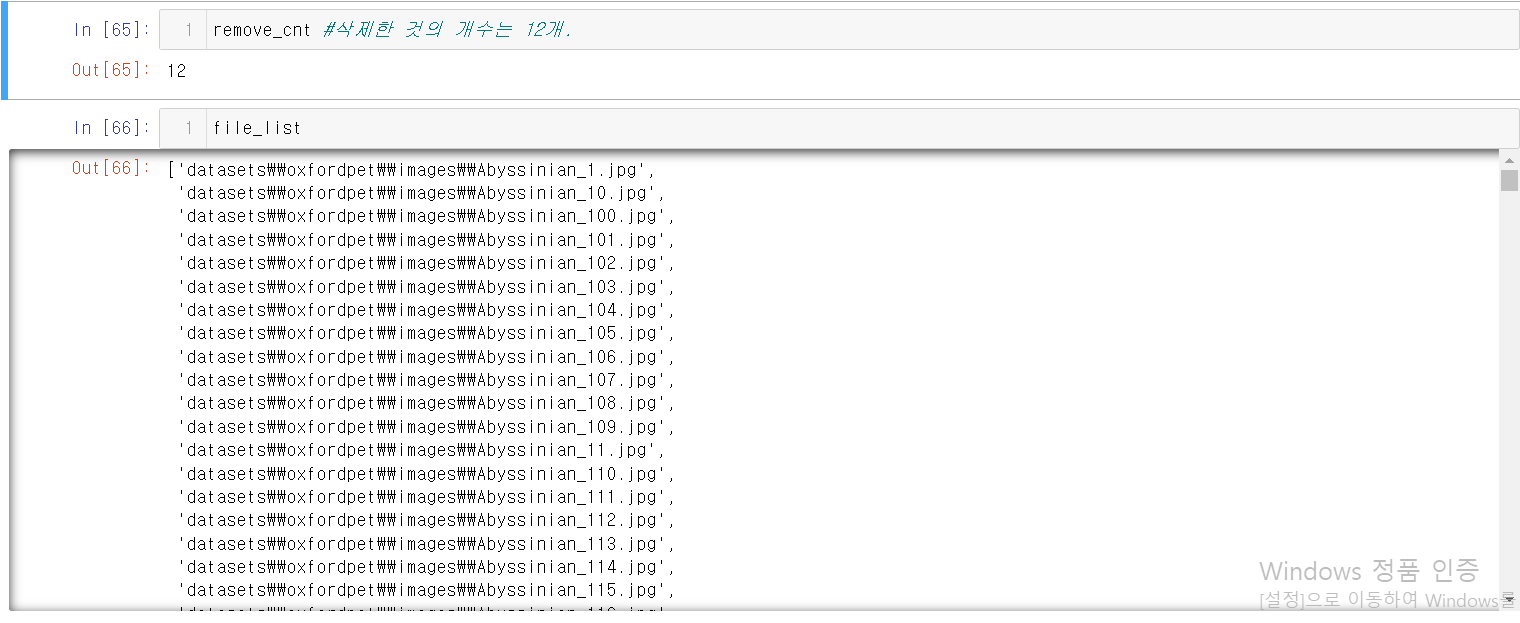








6.torchvision.datasets.ImageFolder 이용
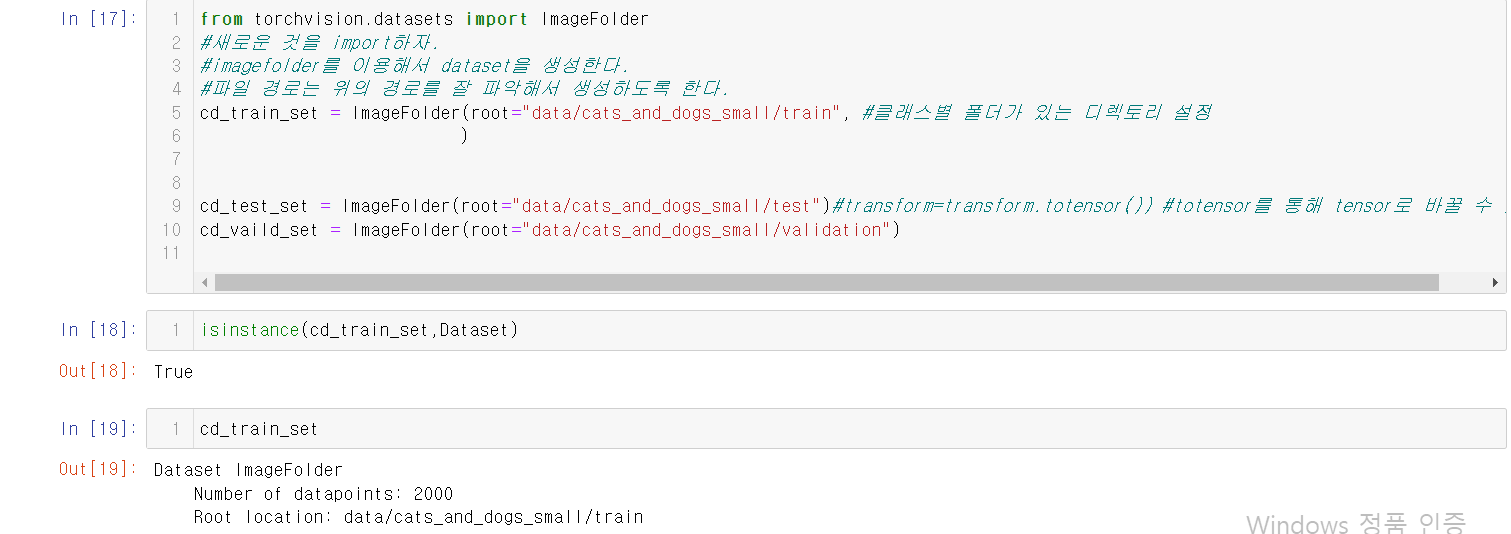
저장장치에 파일로 저장된 image들을 쉽게 로딩할 수 있게 한다.

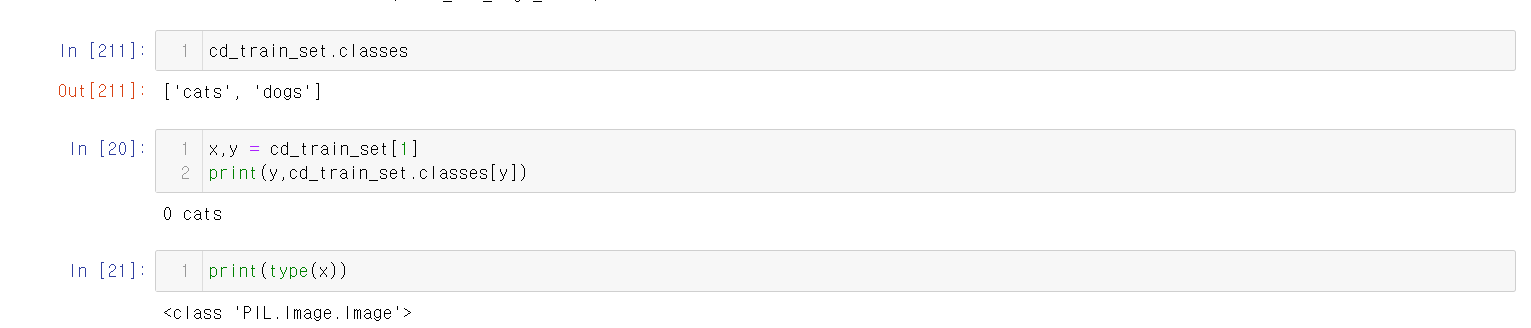
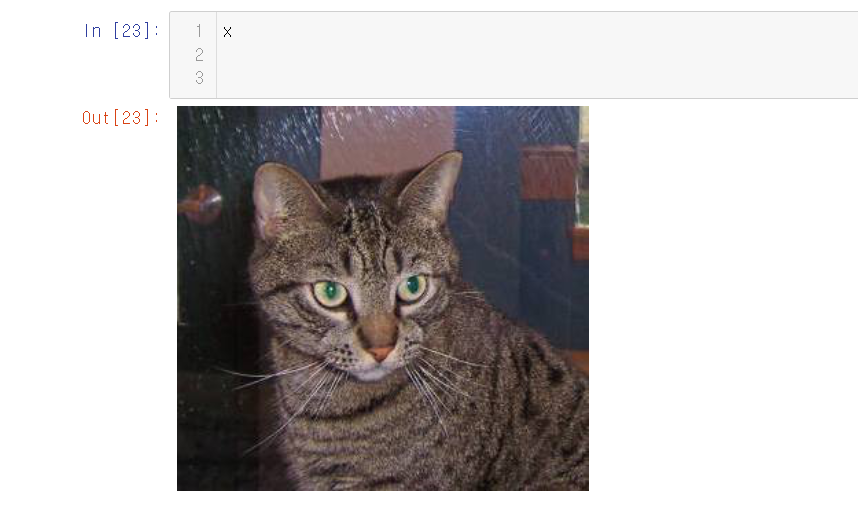
7.모델 성능 평가를 위한 데이터셋 분리
train 데이터셋은 모델을 학습시킬 때 사용할 데이터셋이다.
Vaildation 데이터셋은 모델의 성능 중간 검증을 위한 데이터셋이다.
test 데이터셋은 모델의 성능을 최종적으로 측정하기 위한 데이터셋이다.
파이토치로 데이터셋을 분리하는 방법은
torch.utils.data.Subset을 이용하는 것이다.
아래 코드의 캡쳐는 그 예시이다.
이 예시를 이용해 데이터들을 목적에 맞게 3등분하는 것이 좋다.