
(펩시를 마시는 중국 삼국시대의 장수 여포(呂布).)
0.들어가기 전에
위 그림을 보면 어떤 생각이 드는가?
그냥 비디오게임 일러스트 아녀? (
머리에 저건 닭벼슬이냐?)
음.... 맞다.(닭벼슬도 맞다) 하지만 우리는 딥러닝을 통해 이런 그림을 합성해서 만들 수 있다.
별로 놀랍지는 않을 것이다. 우리는 그 결과물을 많이 봐 왔으니까.
그걸 가능하게 하는 핵심 이론이 바로 cnn이다.
자, 이제부터 cnn에 대한 이야기를 할 것이다.
재미 있을 것이니, 잘 따라오시라! :)
1.개요
cnn은
Convolutional Neural Network
의 약자이다.
Yann Lecun 이라는 사람이 제안한 딥러닝 구조로서,
이미지,동영상 처리와 같은 컴퓨터 비전에서 사용된다.
특이점은 Convolution 레이어를 전처리 Layer로 포함시킨 딥러닝 모델이라는 점이다.
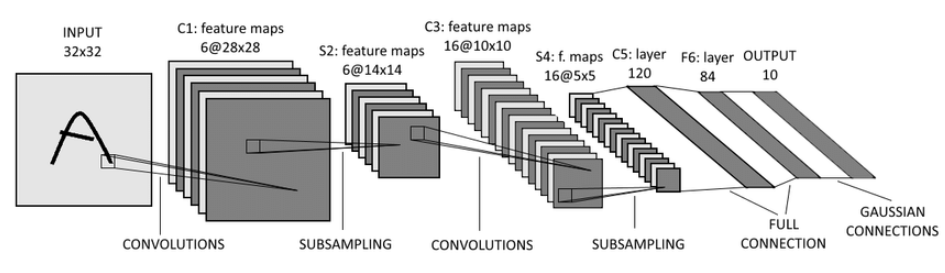
2.다양한 활용 영역
매우 다양한 활용 영역이 있다.
2.1.image classification(이미지 분류)
한마디로
이 그림이 강아지야 고양이야?
를 구분해준다.
솔직히 '킹간'(인간+킹)의 능력으로는 간단한 거지만,
코드 몇 줄로 '킹간'의 능력을 따라 할 수 있다는 것이 매우 인상깊다고 생각한다.

2.2.Object Detection(물체 검출)
이미지 안의 Object(물체)들의 위치를 찾고 어떤 물체인지 분류하는 작업을 한다.
localization과 Dection으로 나뉜다. 이 둘이 차이점이 있기 때문에 혼동하지 않도록 하자.
Localization : 이미지안에서 하나의 Object의 위치와 class를 분류한다.
Dection: 이미지 안의 여러개의 Object의 위치와 Class를 분류한다.

2.3.Image Segmentation (세분화)
한마디로 이미지를 픽셀별로 구분하는 것이다.
'자전거를 타는 사람'은 '자전거'와 '사람'으로 구분하는 식이다.

세분화에도 2가지가 있다.
Semantic segmentation(의미기반 세분화)
클래스 단위로 구분한다.
같은 클래스는 같은 것으로 구분한다.
Instance segmantation(인스턴스 기반 세분화)
각 객체 단위로 구분한다.
동일한 클래스라도 다른 객체일 경우 다른 것으로 구분한다.
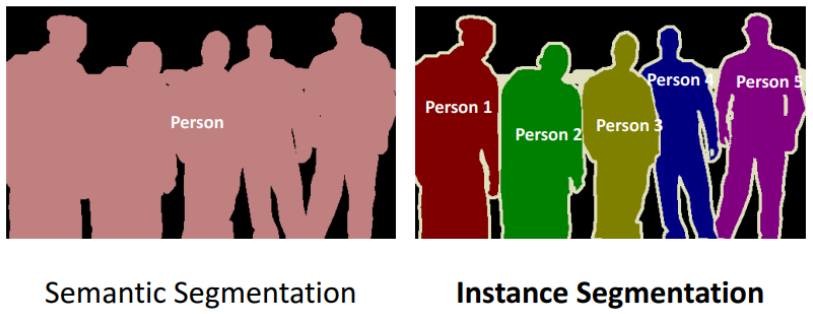
아래 그림 중에 Instance segmantation 부분을 잘 보면, 개념이 이해가 잘 될 것이다.

2.4.Image Captioning
이미지에 대한 설명문을 자동으로 생성한다.
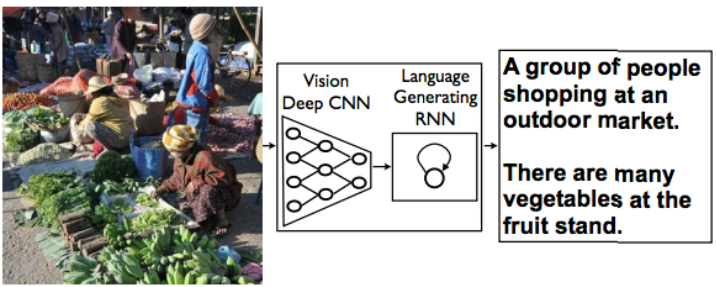
2.5.Super Resolution
저해상도의 이미지를 고해상도의 이미지로 변환한다.

2.6.이미지 생성
기계를 학습시켜서, 정말 쌈뽕한 그림을 만들 수 있다.

(이건 뭐지? 우주인 버전 여포인가?)

(참고로 이건 펩시 마시는 여포. 이 그림은 비디오 게임의 일러스트이지만, 딥러닝을 공부하면 이런걸 우리가 만들 수 있다.)
2.7.Neural Style Transfer
입력 이미지와 스타일 이미지를 합쳐 합성된 새로운 이미지 생성한다.
밑의 사진 보면 바로 이해가 간다.

2.8.Text Dectection & OCR
Text Dectection: 이미지 내의 텍스트 영역을 Bounding Box로 찾아 표시
OCR: Text Detection이 처리된 Bounding Box 안의 글자들이 어떤 글자인지 찾는다.

(약간 그거있지? 주민등록번호 인증하는 그런거. 정확하지는 않지만 대강 비슷한거 같다 ^^)
2.9.Keypoint Detection (특징점 검출)
인간의 특징점들을 추정한다.
풀고자 하는 문제에 따라, 사람의 관절을 검출하거나, 사람얼굴의 각 특징점을 추출하거나, 손가락 관절을 검출하거나 한다.



3.Computer Vision 이 어려운 이유
자, 이렇게 보면 마냥 쉽고 재미있기만 할 거 같은데......
근데 쉽지 않다.
이는 사람과 컴퓨터가 보는 이미지의 차이 때문이다.
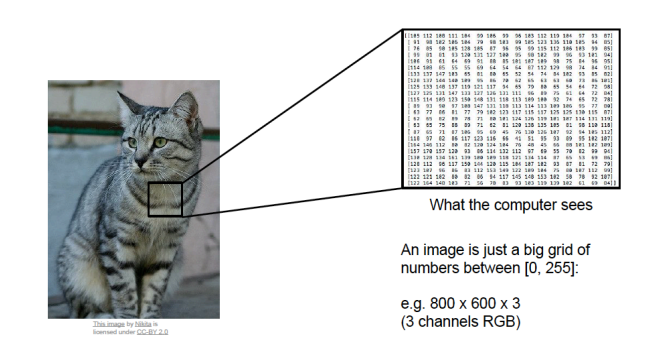
컴퓨터가 인간의 눈을 가지고 있지 않다는 것은 잘 알 것이다.
그래서 컴퓨터는 이미지를 0-255 사이의 숫자로 이뤄진 행렬로 본다.
그 숫자들 안에서 패턴을 찾는 것이 쉽지는 않다.
배경과 대상이 비슷해서 구별이 안되는 경우도 있고, 같은 종류의 대상이 형태가 매우 많은 경우도 있고, 대상이 가려져 있는 경우도 있고, 같은 class에 다양한 형태가 있는 경우도 있다.
(아래 그림은 설명의 예시이다. 고양이의 이미지를 컴퓨터는 숫자 덩어리(ㅋㅋㅋ)로 인식한다.)
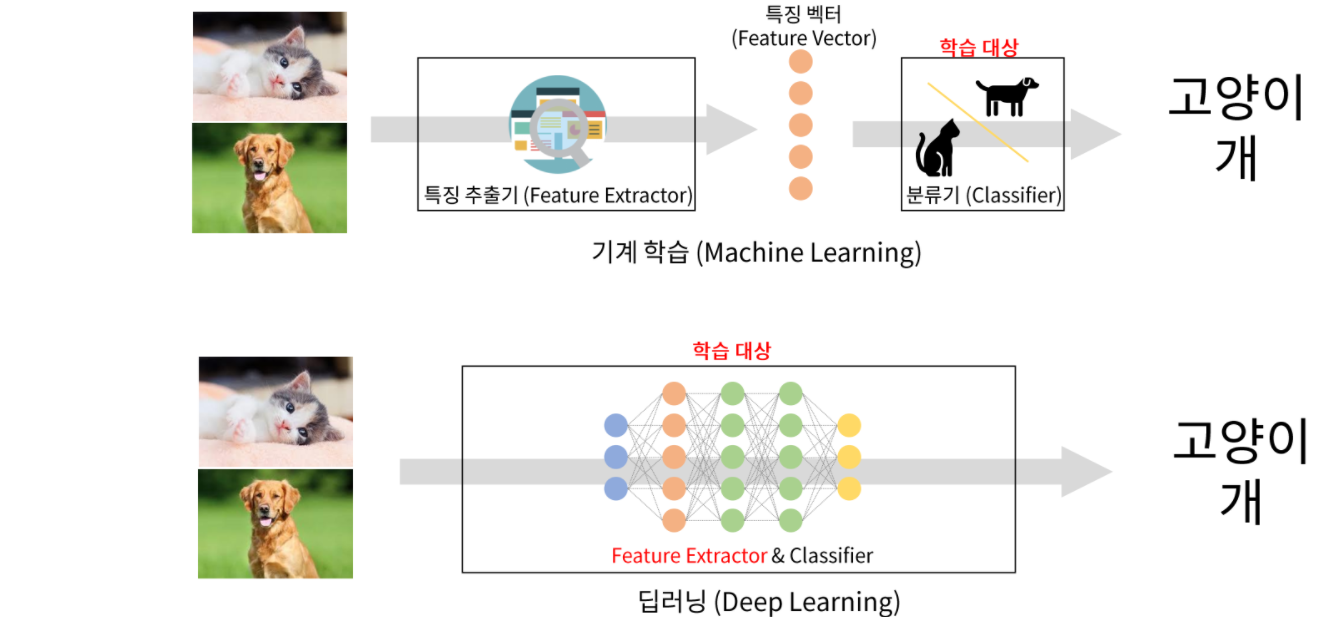
4.기존의 전통적인 이미지 처리 방식과 딥러닝의 차이
전통적인 영상처리 방식은 Handcrafted Feature이다.
분류하려고 하는 이미지의 특징들을 사람들이 직접 찾아서 만드는 것이다.
그리고 그 찾아낸 특징들을 기반으로 학습시키는 것이다.
말 그대로 수동이라는 것이지.
그런데, 이런 방식은 미처 발견하지 못한 특징을 가진 이미지에 대해서는
분류를 하지 못하기 때문에 성능이 떨어진다.
그렇기 때문에 다양한 많은 대상들에 대해 특성을 추출하는 것을 사람이 만드는 것이 어렵다.
사람의 시간은 유한하니까 말이다.
반면, 딥러닝은 이미지의 특징 추출부터 추론까지 자동으로 학습시킨다.
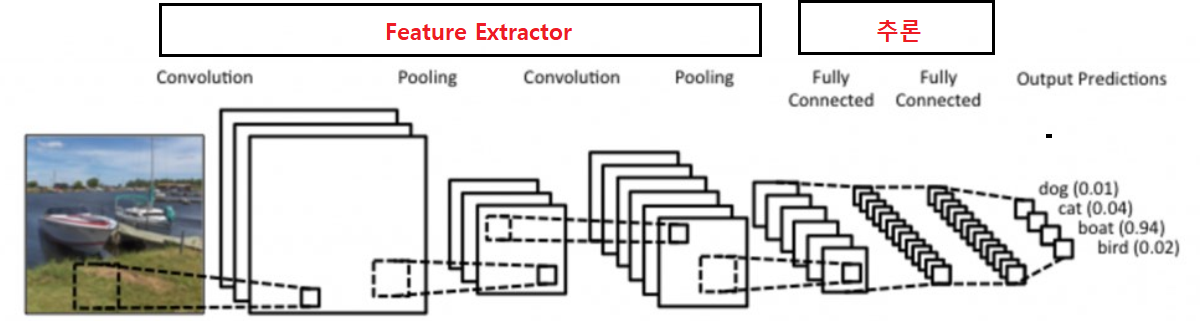
5.CNN(Convolution Neural Network)
이미지로 부터 부분적 특성을 추출하는 Feature Extraction 부분과 분류
를 위한 추론 부분으로 나눈다.
Feature Extraction 부분에 이미지 특징 추출에 성능이 좋은
Convolution Layer를 사용한다.
Feature Exctraction : Convolution Layer
추론 : Dense Layer (Fully connected layer) 등
6.영상처리에서 Feature Exctractor를 Dense Layer사용했을 때 문제점
일단 우리가 숙지해야 할 것은 Dense Layer는 '많다'.
그냥.....그냥 많다.
그래서 문제가 생긴다.
보통 이미지를 input으로 사용하면 weight의 양이 매우 크다.
그렇기 때문에 weight가 많으면 학습 대상이 많은 것이므로 학습을 하기가
그만큼 어려워진다. 정확히는 학습에 오랜 시간이 걸린다.
당장 500*500 픽셀 이미지여도
25000개의 학습 파라미터가 있다.
자, 근데 컬러도 있지?
컬러의 channel은 보통 3개이다.
그래서 총 3*25000개의 학습 파라미터가 있다.
그리고 학습 파라미터가 많으면 그걸 거르는 layer도 많아야 한다.
이게 다 실행 시간에 포함이 된다.
이런 문제를 해결하는 것이 cnn layer이다.
7.convolution이란
convolution layer는 이미지와 필터간의 합성곱 연산을 통해 이미지의 특
징을 추출해 낸다.
7.1.1D Convolution 연산
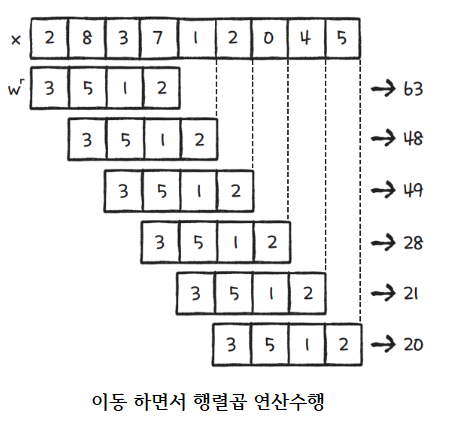
이런 식으로 이동시키면서 행렬곱 연산을 수행한다.
첫번째 줄에서 63이 나온 이유는 (23+85+31+72)가 된 것이다.
이런 식으로 계산을 하면,
x의 크기가 9개에서 90개, 9만개가 되더라도
weight인 w의 숫자는 4개이기 때문에(매우 적기 때문에), 계산을 더 빠르게 할 수 있다.
특성별로 filter를 만들고, 연산을 시킨다.
그러면 그 값과 filter를 대입시키면, 그 특징을 더 빠르게,부분별로 찾을
수 있을 것이다.
7.2.2D Convolution 연산
input 행렬과 Filter 행렬간에 행렬곱 연산을 한다.
동일한 index의 값끼리 곱한 뒤 더해준다.
음..... 말로는 감이 잘 안온다.
걍 직관적인 그림을 보도록 하자.
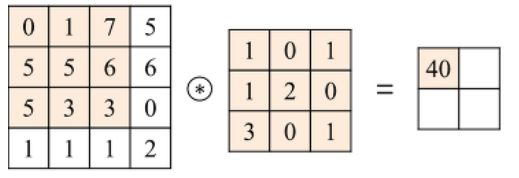
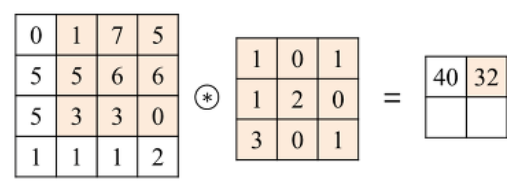
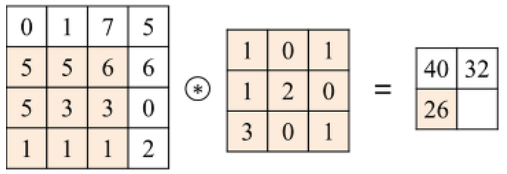
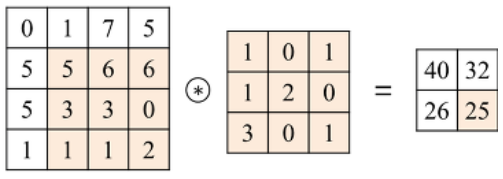
결과의 숫자들은 '추출하고자 하는 특징이 얼마나 있나'를 나타내 주는 지표이다.
(이미지 참조:https://untitledtblog.tistory.com/150)
이를 더 직관적으로 표현한 그림이 있다.
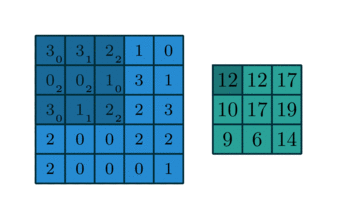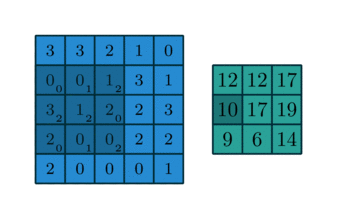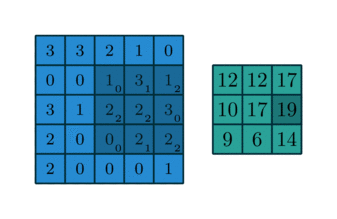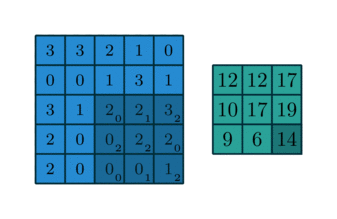
이거 보니까 훨씬 더 이해가 잘 가지?
7.3. feature 추출과 합성공
filter
-이미지와 합성곱 연산을 통해 feature들을 추출한다.
예시(대상 이미지)
위 그림의 일부를 추출해서,filter와 대상을 각각 추출해서 곱한다.
filter/Kernel
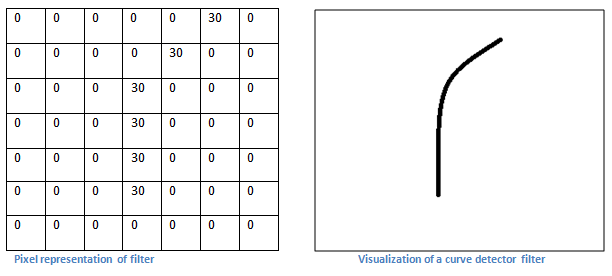
(계산하는 과정)
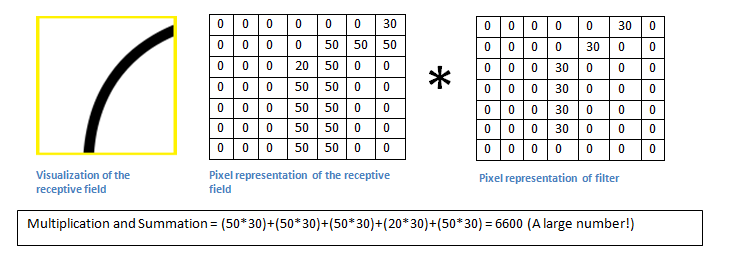
필터와 이미지의 노란 박스 부분을 합성곱하면 6600 이 나온다.
이미지의 밑 부분에서도 볼 수 있듯이, 이는 매우 large한 number이다.
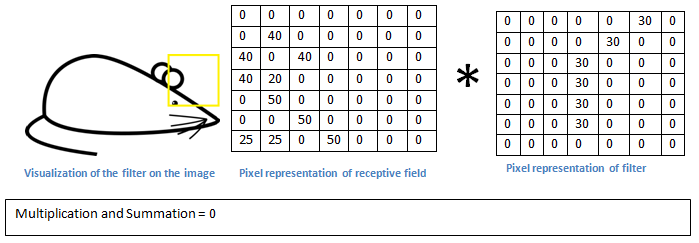
필터와 이미지의 노란 박스 부분을 합성곱하면 0 이 나온다.
필터와 부분 이미지의 합성곱 결과가 값이 나온다는 것은 그 부분 이미지에 필터가 표현하는 이미지특성이 존재한다는 것이다.
7.4. Hand Craft 방식의 Filter
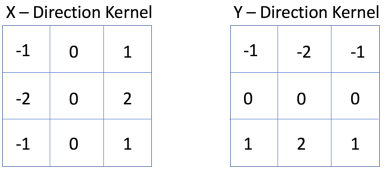
영상으로 부터 윤곽선 특성(Edge Feature)을 찾는다.
여기서, 필터를 쓰는 것은 똑같은데, 필터는 우리가 찾는 것이 아니라 모델이 찾게끔 하는 것이다.
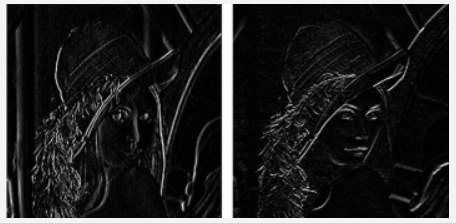
Sobel 필터
X-Direction Kernel: 이미지에서 수평 윤곽선(edge)를 찾는다.
Y-Direction Kernel: 이미지에서 수직 윤곽선(edge)를 찾는다.
아래의 그림들의 왼쪽은 X-Direction Kernel을 적용한 것이고,
오른쪽은 Y-Direction Kernel을 적용한 것이다.

이렇게 해서, 특정 윤곽선만 추출을 해낸다.
영상의 윤곽선이 문제 해결에 도움이 되는 특성이라면 영상으로 부터
윤곽선을 추출할 수 있는 Filter를 개발자가 연구를 통해 찾아 내야 한다.
필요한 특성이 n개 있다면 그것들을 찾기 위한 필터 n개를 만들어 특성을
추출한다.
추출된 특성들을 머신러닝 모델의 입력으로 넣어 학습시킨다.
8.deep learning 에서의 filter
Convolution Layer는 특성을 추출하는 Filter(Kernel)들로 구성되 있
다.
Filter(Kernel)를 구성하는 값들은 데이터를 학습해 찾아낸다.
그래서 Filter를 구성하는 원소(element)들이 Parameter(weight)가 된
다.
한 Layer를 구성하는 Filter들은 Input(input image 또는 feature
map) 에서 각각 다른 패턴(특징)들을 찾아낸다.
Convolution Layer도 여러층을 쌓는다.
1.입력층(Bottom)과 가까운 Convolution 레이어일 수록 input image의 작은 영역에서의 특징들을 찾는다. 작은 영역에서의 특징을 찾기 때문에 이미지의 엣지나 경계선등 일반화가 쉬운 이미지의 기초적인 표현을 찾는다.(선,질감 등)
2.출력층(Top)과 가까운 Convolution 레이어일 수록 input image의 넒은(큰) 영역에서의 특징들을 찾는다. 넓은 영역에서의 특징을 찾기 때문에 일반화가 곤란한 구체적인 이미지의 표현을 찾는다.(눈,코,의자,나무,고양이 등)
3.이렇게 서로 상이한 부분을 찾아야 하기 때문에, layer를 여러개를 쌓는 것이다.
아래의 이미지 예시를 보면 이해가 빠를 것이다.
9.Convolutional Layer 클래스 및 작동방식
파이토치에서는 torch.nn.Conv2d를 쓴다.
9.1.torch.nn.Conv2d
torch.nn.Conv2d에서는 입력으로 (N, Channel, Height, Width)
shape의 tensor를 받는다.
숙지해야 할 점은 입력으로 Channel을 먼저 받는다는 것이다.
(N은 batch size이다.)
아래는 파라미터들에 대한 설명들이다.

9.2.Feature Map
그 앞에 합성곱의 결과 행렬 있지?
그게 바로 Feature Map이다.
그 숫자들이 Feature에 대한 지표이기 때문에
Feature Map이라고 표현을 하는 것이다.
Feature map의 크기(shape)는 Filter의 크기(shape), Stride,
Padding 설정에 따라 달라진다.
9.3.input shape
(데이터개수, channel, height, width)
Channel: 하나의 data를 구성하는 행렬의 개수
이미지: 색성분
흑백(Gray scale) 이미지는 하나의 행렬로 구성
컬러 이미지는 RGB의 각 이미지로 구성되어 3개의 행렬로 구성
Feature map: 특성개수
Height: 세로 길이
Width: 가로 길이
9.4.Feature 추출 연산
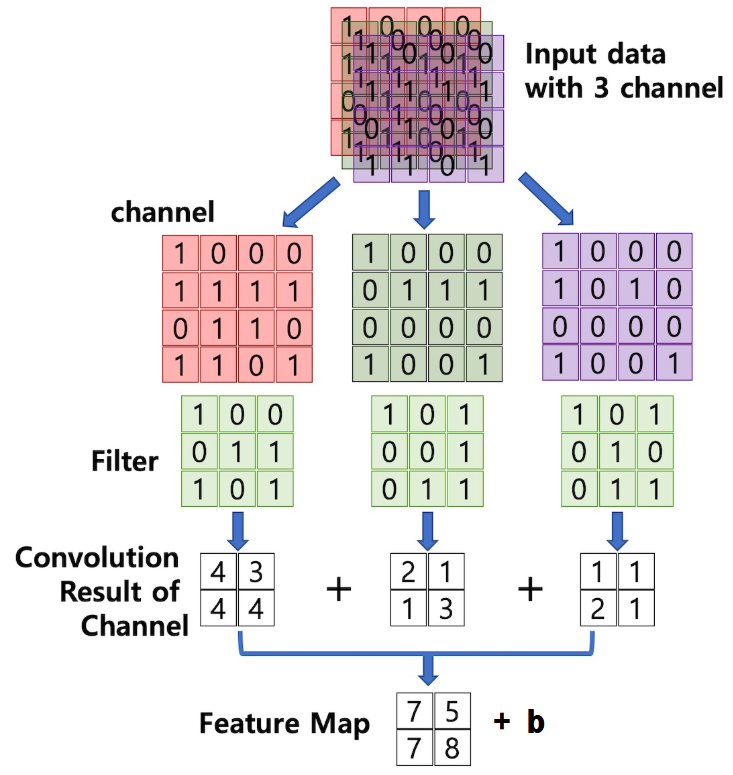
그림을 자세히 보자!
그림을 설명해보자면,
data를 각각의 channel로 나누고,
그 각각의 channel을 filter를 통해 거른다.(합성곱을 이용)
그 합성곱의 결과를 모두 더해서,
Feature Map을 구한다.
9.5.예시
input image는 366이다.(채널,높이,너비)
filter는 333 크기의 필터 1개이다.
output은 4*4 feature map 1개를 생성한다.
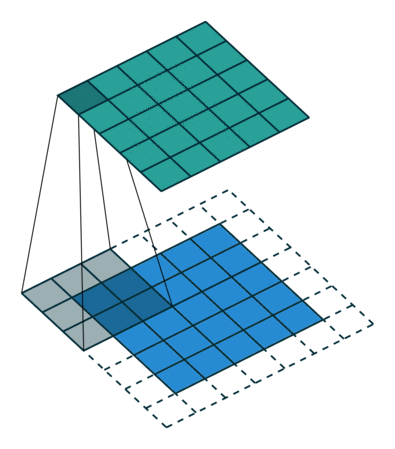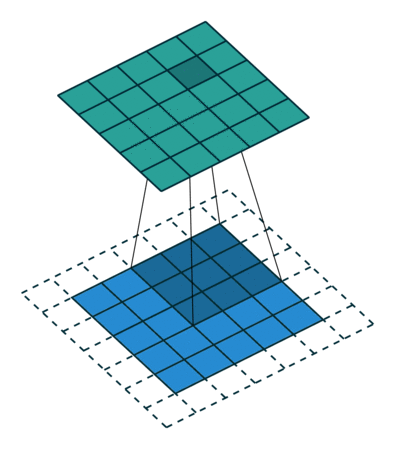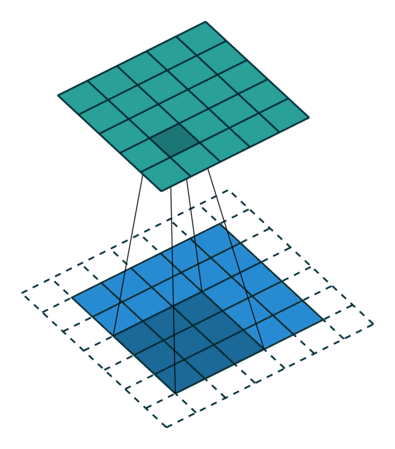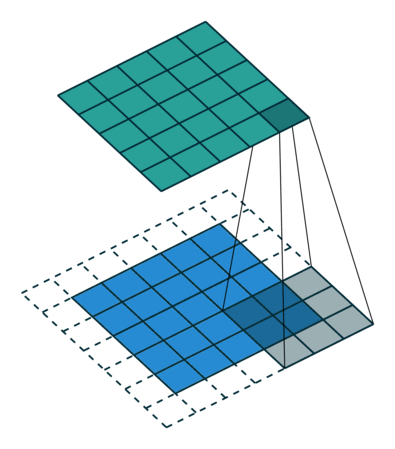
이 때, feature map은 특성을 찾은 결과값의 집합에 해당한다.
자, 근데 특성을 2개를 찾고 싶으면 아래와 같이 하면 된다.
그냥 필터를 2개로 두면 된다.
9.6.padding
아래는 padding에 대한 이미지이다.
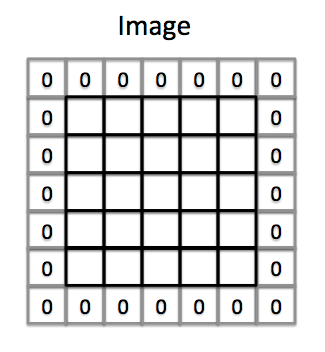
padding을 쓰는 근본적인 이유는
input size와 output size를 똑같이 만들어보게 하기 위함이다.
아래는 계산을 할 때 padding을 포함해서 계산한다는 것을 설명하는 gif이다.

9.7.Strides
Filter가 한번 Convolution 연산을 수행한 후 옆 혹은 아래로 얼마나 이동할 것인가를 설정한다.
stride=(2,2)
라고 하면, 이동 시 2칸씩 이동을 하게 되다.
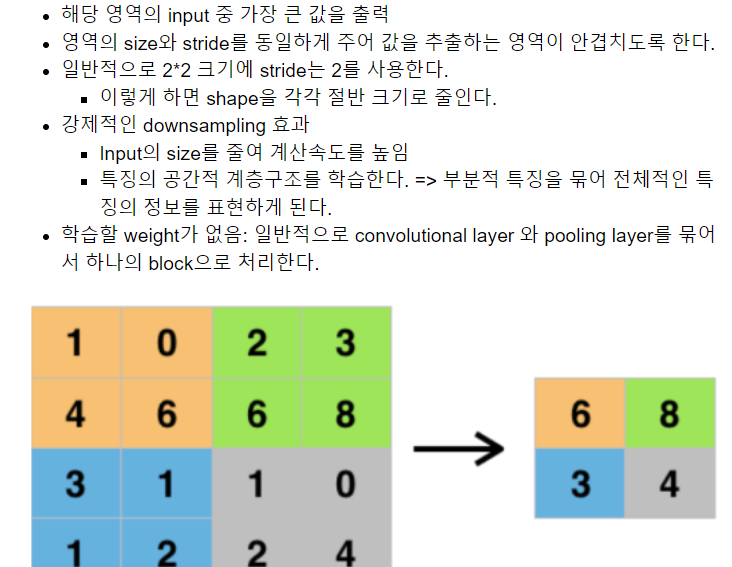
9.8.Max Pooling Layer
Pooling Layer는 Feature map의 특정 영역 값들 중 그 영역을 대표할
수 있는 한 개의 값을 추출해서 output을 만든다.
한마디로 대표값이라는 것이다.
이는 Feature map의 size를 줄이는 역활을 한다.
torch.nn.MaxPool2d
강제적으로 size를 줄어들게 한다.
이러면 다음 layer에서의 연산의 양이 줄어든다.
참고
downsampling과 반대되는 upsampling이 있는데, 이는 이미지의 크기를 크게 키우는 것을 말한다.
9.9. Example of CNN architecture
input 다음에 바로 convolution을 하는 것이 특이점이다.
그리고, input 과 convolution의 side가 동일한 것도 특이점이다.
convolution을 한 다음 pooling을 통해 size를 줄여준다.
그런 다음, 다음 convilution에 이미지를 보내준다.
이런 과정을 거치고 거쳐서 결과를 만들어 내는 것이다.
근데 의문이 있다.
이미지를 분류하는 작업을 할 때, 작은 영역을 통해서 이미지를 분류하려고 하면 특성을 추출할 수 없기 때문에 이미지에 대한 정보가 부족할 것이고, 그렇기 때문에 이미지를 분류할 수 없다. 그래서 분류 시 이미지가 크면 분류하기 쉬울 건데....왜 size를 줄이는 것일꼬?
이유는 간단하다.
parameter가 많아지니까. 애초에 cnn을 쓰는 이유가 parameter가 많은 문제를 해결하기 때문이다!
그래서 넓은 범위를 보고 싶은데, 그게 안되니까, 합성곱을 통해
이미지의 사이즈를 줄여서, 비록 작은 영역을 보더라도 합성곱을 해서 실제로 보는 영역은 넓도록 만드는 것이다.
한 마디로, 우리 눈의 시야는 제한적이니, 너무 크기가 큰 큰 그림이 있으면
그걸 멀리서 본다거나 해서 우리의 시야에 그림의 더 많은 부분을 담는 것
과 비슷하다.
위의 그림은 자동차 사진을 집어 넣으면, 자동차의 특성들을 뽑아낸 다음,
이 사진이 자동차일 확률,트럭일 확률,비행기일 확률 등을 정하는 그림이다.
아래는 자세한 설명이다.
