1.Convolutional Neural Network 모델 정의
코드와, 코드의설명으로 대체한다.
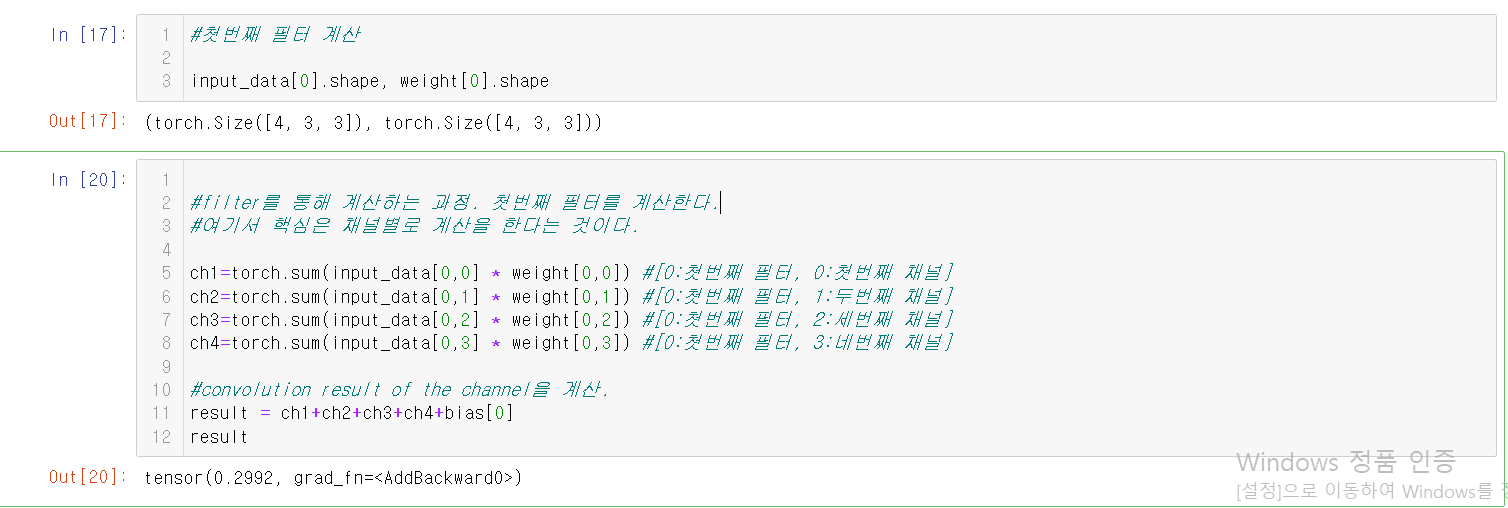
유의할 것은 bias와 filter의 개수가 같다는 것이다.
bias 자체가 filter당 1개씩 붙는 값이기 때문이다.



첫번째 필터를 계산하는 과정이다.
두번째 필터를 계산하기 위해서는
weight[0,0]을 weight[1,0]으로 바꾸면 된다.
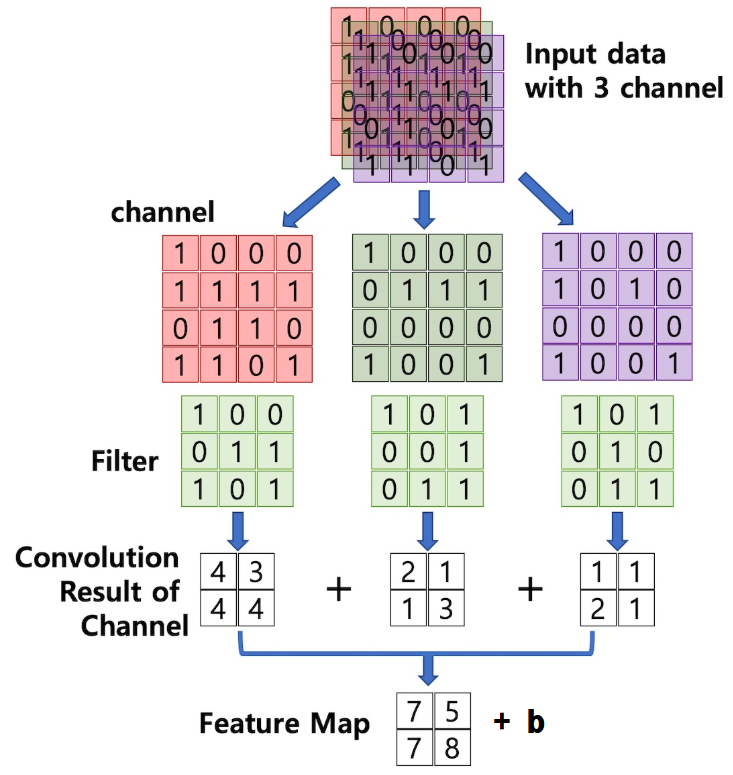
필터를 계산하는 과정을 이렇게 보기만 하면 많이 혼동스러울 것이다.
이 그림을 보면 과정이 잘 이해가 간다.
2.MaxPool2d


3.MNIST
자, 이번에는 cnn을 통해 mnist 문제를 다뤄보도록 하자.
본격적인 코딩을 하기 전에, import와 hyper parameter를 정의하자.


4.Data 준비
5.CNN 모델 정의
cnn 모델을 정의한다.
이름은 MNISTCNNModel로 한다.
원래 정의했던 모델과 뭐 비슷한데,
그거에 cnn에 관한 내용이 들어갔다는 차이가 있다.
여기서 주의해야 할 것은 stride와 padding에 관한 것이다.
이 둘이 서로 같아야 데이터를 다루는 데에 있어서 골치가 줄어든다.
아래는 모델을 정의하는 코드이다.
#CNN ->Convolution Layer: filter개수(out_channels로 설정) 뒤로 갈수록 크게 잡는다.
#Max Pooling Layer를 이용해서 출력 결과의 size는 줄여나간다.(보통 2배씩 줄인다.)
#conv block을 만드는 패턴
#1. conv + relu + maxpooling
#2. Conv + BatchNorm + ReLU + MaxPooling
##3. Conv + BatchNorm + ReLU + Dropout + MaxPooling
class MNISTCNNModel(nn.Module):
def __init__(self):
super().__init__()
self.b1 = nn.Sequential(
#Conv2d():3*3 필터,stride와 padding이 1로 같다. 이는 입력 size와 출력 size가 같다는 것을 의미한다.
nn.Conv2d(1,32,kernel_size=3, stride=1,padding=1),
nn.BatchNorm2d(32), #channel을 기준을 정규화한다. -> 입력 channel수를 지정한다.
nn.ReLU(),
nn.Dropout2d(p=0.3),
nn.MaxPool2d(kernel_size=2,stride=2)
#kernel_size와 stride가 같은 겨우에는 stride를 생략할수 있다.
#MaxPool2d() 에서도 padding을 지정할 수 있다.
)
self.b2 = nn.Sequential(
nn.Conv2d(32,64,kernel_size=3,padding="same"), #더 늘려나간다.
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.b3 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,padding="same"),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Dropout2d(p=0.3),
nn.MaxPool2d(kernel_size=2,padding=1) #입력: 7*7이고 2등분으로 줄이면 3.5이다.
#이를 살리기 위해 padding을 지정한다.
)
#결과 출력레이터 =>Linear() 사용.
self.output_block = nn.Sequential(
#MaxPool2d(), #출력결과를 입력으로 받는다. =>4차원이다.
#3차원 => 1차원
nn.Flatten(),
nn.Linear(in_features=128*4*4,out_features=512),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(512,10) #out=>클래스 개수
)
def forward(self,X):
out = self.b1(X)
out = self.b2(out)
out = self.b3(out)
out = self.output_block(out) #이를 통해 결국 10개의 값을 출력받는다.
#이름이 output_block인 것을 숙지하자.
return out
summary를 통해 간략한 정보를 보도록 하자.
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
MNISTCNNModel [1, 10] --
├─Sequential: 1-1 [1, 32, 14, 14] --
│ └─Conv2d: 2-1 [1, 32, 28, 28] 320
│ └─BatchNorm2d: 2-2 [1, 32, 28, 28] 64
│ └─ReLU: 2-3 [1, 32, 28, 28] --
│ └─Dropout2d: 2-4 [1, 32, 28, 28] --
│ └─MaxPool2d: 2-5 [1, 32, 14, 14] --
├─Sequential: 1-2 [1, 64, 7, 7] --
│ └─Conv2d: 2-6 [1, 64, 14, 14] 18,496
│ └─BatchNorm2d: 2-7 [1, 64, 14, 14] 128
│ └─ReLU: 2-8 [1, 64, 14, 14] --
│ └─MaxPool2d: 2-9 [1, 64, 7, 7] --
├─Sequential: 1-3 [1, 128, 4, 4] --
│ └─Conv2d: 2-10 [1, 128, 7, 7] 73,856
│ └─BatchNorm2d: 2-11 [1, 128, 7, 7] 256
│ └─ReLU: 2-12 [1, 128, 7, 7] --
│ └─Dropout2d: 2-13 [1, 128, 7, 7] --
│ └─MaxPool2d: 2-14 [1, 128, 4, 4] --
├─Sequential: 1-4 [1, 10] --
│ └─Flatten: 2-15 [1, 2048] --
│ └─Linear: 2-16 [1, 512] 1,049,088
│ └─ReLU: 2-17 [1, 512] --
│ └─Dropout: 2-18 [1, 512] --
│ └─Linear: 2-19 [1, 10] 5,130
==========================================================================================
Total params: 1,147,338
Trainable params: 1,147,338
Non-trainable params: 0
Total mult-adds (M): 8.55
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.71
Params size (MB): 4.59
Estimated Total Size (MB): 5.30
==========================================================================================6.Train
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=LR)
result = fit(train_loader,test_loader,model,loss_fn,optimizer,N_EPOCH,
save_best_model=False,early_stopping=True,device=device,mode="multi")
밑은 결과를 캡쳐한 것이다.
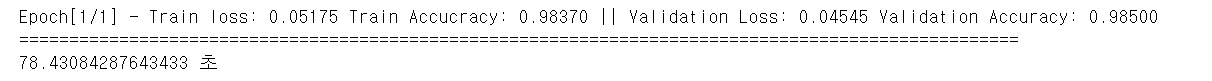
7.참고사항
학습을 할 때 gpu가 중요하다. cnn을 할 때 gpu를 쓰지 않으면 실행 시간이 매우 오래 걸린다.
그래서 ,cnn을 할 때는 colab을 쓰게 될 것이다.
colab은 구글 드라이브에서 설치를 할 수 있다.
자세한 설명은 아래 블로그 참고!
https://blog.naver.com/PostView.naver?blogId=hellojinny_&logNo=222132892482
8.구글 코랩에 대해서
코랩은 기본적으로 파이썬 개발 환경이 구축이 되어 있으므로 굳이
뭔가를 따로 할 필요는 없다.
그리고, 데이터쪽과 관련된 왠만한 라이브러리들이 다 설치가 되어 있다.
구글 코랩은 우리가 컴퓨터에서 파이썬을 쓰는 것과는 약간 다르다.
네트워크 내에서 파이썬 환경을 유사하게 쓸 수 있게 한 것이다.
컴퓨터 한대를 빌리는 것이라고 생각하면 된다.
더 정확히는, 가상환경을 이용하는 것이다.
9.런타임 유형 변경
'런타임' 에서 '런타임 유형 변경'에 들어가 'T4 GPU'를 선택한다.
10.주피터 노트북의 파일을 colab에서 사용
주피터 노트북의 파일을 다운 받아서, 관련 구글 드라이브에 업로드 하면
코랩에서 코드를 그대로 사용할 수 있다.
(코랩에서도 코드를 그대로 사용할 수 있다.)
11.추가 설치
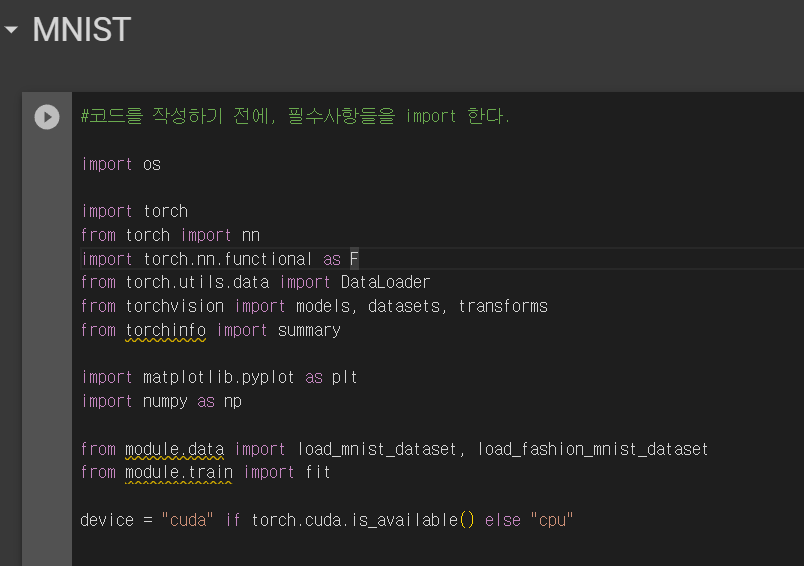
위 사진을 보면, torchinfo 등에 밑줄이 그어져 있다.
코랩에서도 관련된 것을 install을 해야 한다는 의미이다.
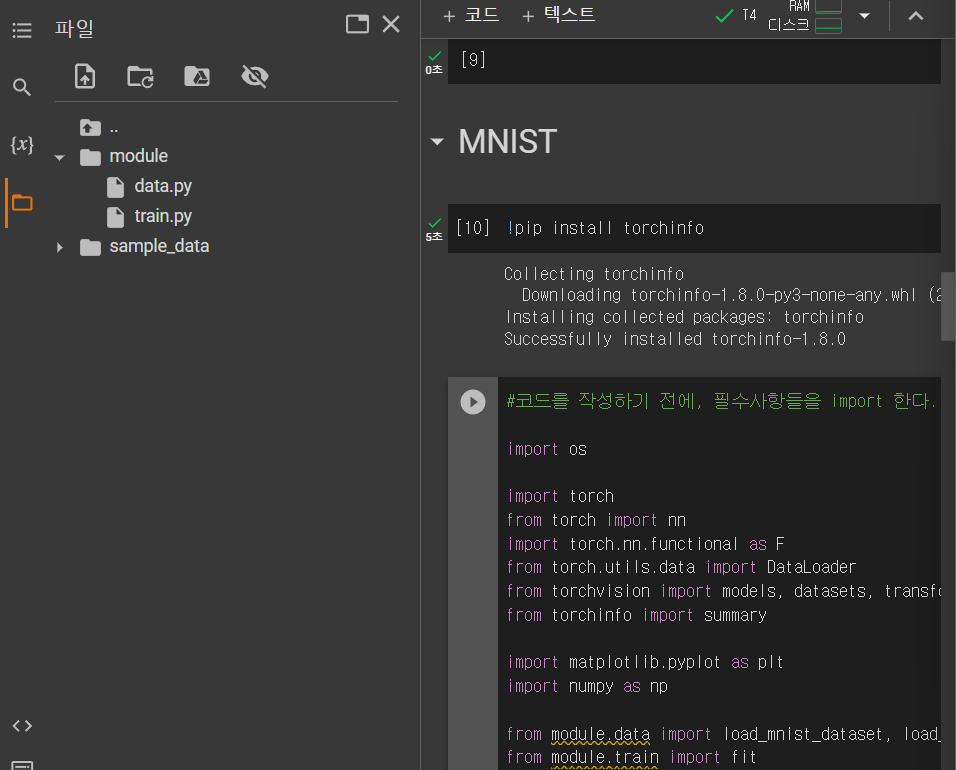
그리고, 관련 데이터들도 새롭게 파일을 만들어서 업로드를 해야 한다.
이런 점이 약간 번거롭다.
12.코랩으로 Train 하기
첫 epoch만 시험삼아 돌려보자.
원래는 80초 정도 걸렸었는데, 지금은 18초만에 끝장이 났다.
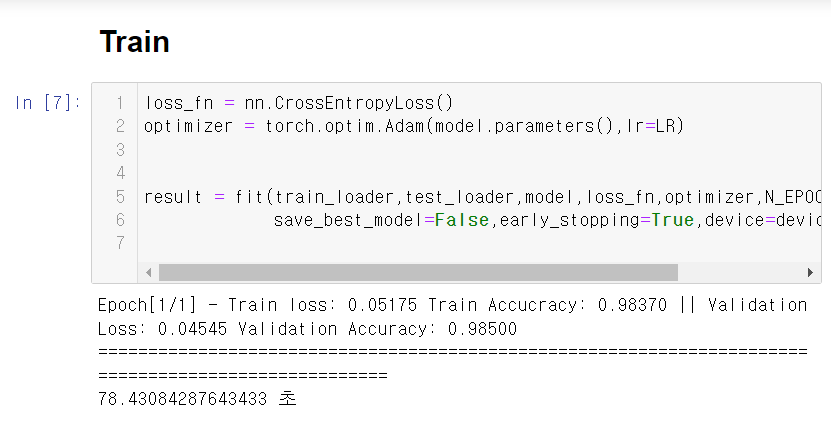
(주피터 노트북에서 실행)
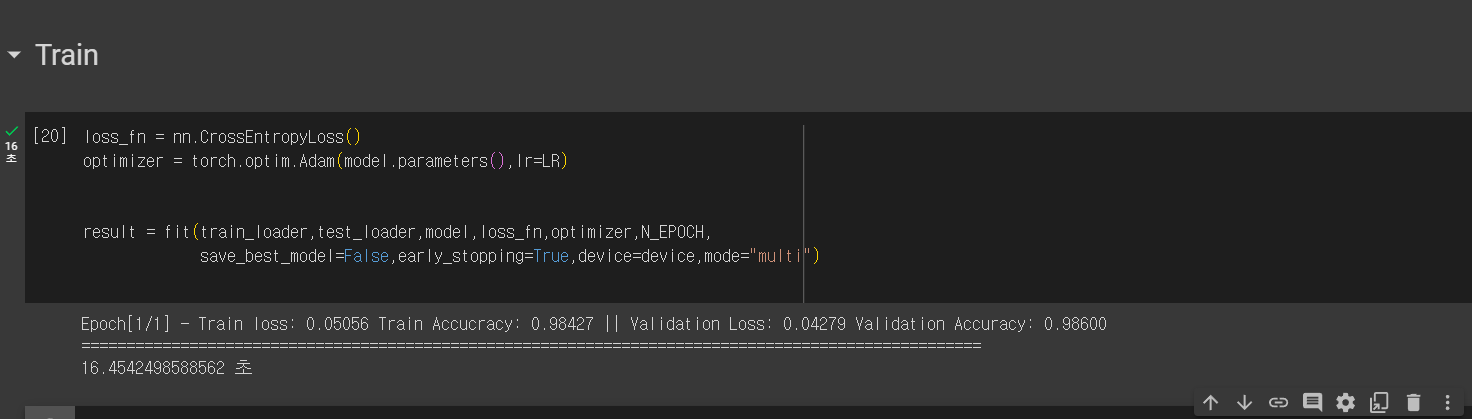
(코랩에서 실행)
판타스틱! JONNA 좋군?

속도가 4~5배 정도 빨라진 것이니... 정말 획기적으로 개선이 되었다고 할 수 있다.
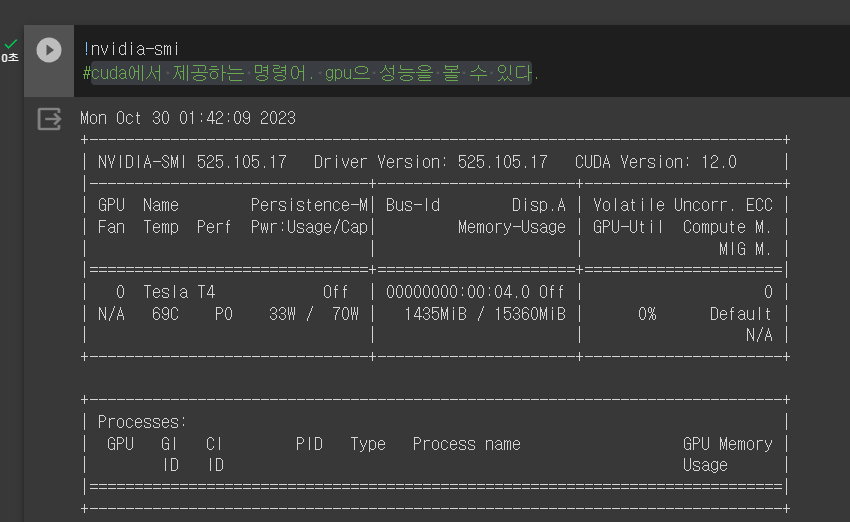
13.!nvidia-smi
cuda에서 제공하는 명령어. gpu으 성능을 볼 수 있다.
14.저장을 할 때, 계속 사용할 것들은 google drive에 저장을 하는 것이 옳다.
from google.colab import drive
drive.mount('/content/drive')이 코드를 입력하면
이런 문구가 뜨고, 연결한다고 하면 구글 계정에 연결하면 된다.
그렇게 되면,

와 같은 문구가 뜬다.
그런 다음
path = "/content/drive/MyDrive/pytorch/models"
os.makedirs(path,exist_ok=True)와 같이 만들면, 해당 경로에 파일이 만들어진다.
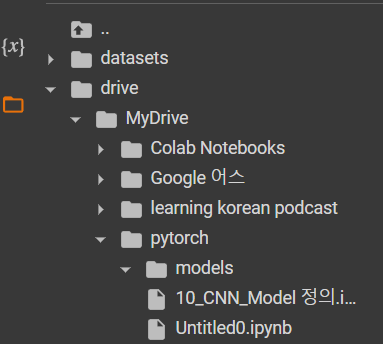
(마음의 눈을 뜨고 잘 보면 해당 경로에 파일이 만들어지는 것을 볼 수 있다.)
그런 다음, 저장을 하고 싶다면
torch.save(model,path+"/cnn_model.pth")와 같이 코드를 적어 주면 된다.
이런 식으로 구글 드라이브에 저장을 해 놔야 연결이 끊겨도 잘 쓰게 될 수 있다.
- 15분 정도 지나면, colab이 알아서 런타임 연결을 끊어버린다.
그렇기 때문에 드라이브에 저장을 하는 것이 좋다고 볼 수 있다.
