0.들어가기 전에
모델 생성 문제 뿐만 아니라, 필자의 블로그에 정리한 모든 딥러닝에 관한
파일이 이 저장소 안에 들어가 있다. 그러니 원본을 보고 싶다면 이 링크를
타서 봐주시길 바란다.
https://github.com/guraudrk/bootcampcode_Deeplearning_pytorch
딥러닝을 배우면서 많이 접했던 것은 바로 함수들이다.
그런데, 이 함수들이 상황에 따라 쓰이는 분야가 상이하다.
이에 대한 설명을 주피터 노트북에 자세히 적었다.
아래는 주피터 노트북의 캡쳐본이다.

1.모델 저장
학습한 모델을 파이레 따로 저장하고 나중에 불러와서 쓸 수 있게 하는 것이다.
저장 함수는 다음과 같다.
torch.save(저장할 객체, 저장경로)
2.모델 전체 저장하기, 불러오기
저장하는 코드
torch.save(model, 저장경로)
불러오는 코드
load_model = torch.load(저장경로)
저장하는 코드와 불러오는 코드가 서로 다르기 때문에 이를 유의해야 한다.
3.모델의 파라미터만 저장
모델의 구조는 저장하지 않고, 파라미터만 저장한다.
그렇기 때문에 모델을 먼저 생성하고 생성한 모델에 불러온 파라미터를 덮어씌운다.
4.checkpoint를 저장 및 불러오기
opitmizer,loss 함수 등 학습에 필요한 객체들을 저장해야 한다.
dictionary에 필요한 요소들을 key-value 쌍으로 저장한 뒤 torch.save()을 이용해서 저장한다.
캡쳐 사진은 예시 코드이다.

- 1부터 4까지의 예시 코드
주피터 노트북의 화면을 캡쳐하거나 코드를 가져오고, 각 부분에 대한 설명을 하겠다.
-모델 생성
import torch
import torch.nn as nn
#단순하게 생각해서, 객체 안에 모듈이 들어가 있다고 생각하면 된다.
class Network(nn.Module):
def __init__(self):
super().__init__()
self.lr = nn.Linear(784,64)
self.out = nn.Linear(64,10)
self.relu = nn.ReLU()
#이런 흐름에 따라서 데이터가 정리가 된다.
def forward(self,X):
X = torch.flatten(X,start_dim=1)
X = self.lr(X) #self.lr에 값을 입력하고, 그 값을 다시 가져갈 것이다.
X = relu(X)
X = out(X)
return X
이렇게 모델을 정의한 다음에, 모델을 생성하고 이를 저장한다.

그 다음에는 파라미터들만 저장을 하고, 이를 조회를 해 보자.
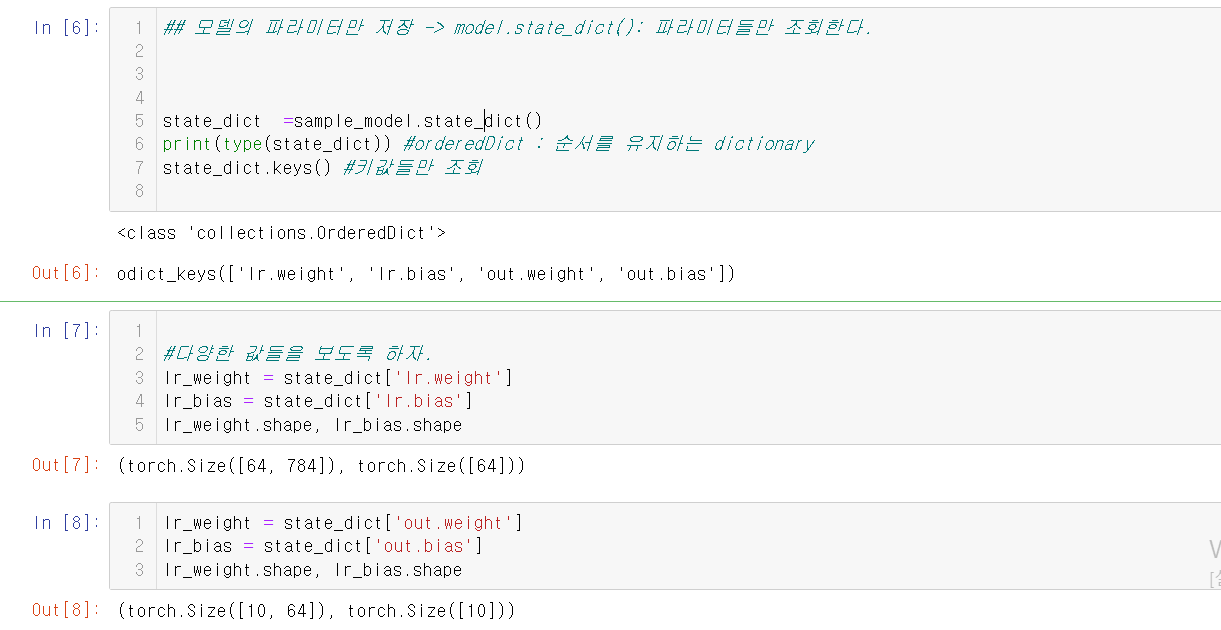
그런 다음, 파라미터들을 저장한다.
여러번 저장을 하면 안되기 때문에 조심하자.

그런 다음, 파라미터들을 로드한다.

파리미터들을 로드하는 것을 성공시켰으면, 새로운 모델 객체를 생성한 다음, 파리미터들을 매칭한다. 매칭이 성공이 되었으면
라는 문구가 떴을 것이다.

6.문제 유형별 mlp 네트워크-회귀(Boston Housing Dataset)
보스턴 주택가격 dataset은 다음과 같은 속성을 바탕으로 해당 타운 주택 가격의 중앙값을 예측하는 문제이다.

6.1.scikit-learn과 여러가지 라이브러리들을 import를 한다.
scikit-learn은 파이썬의 머신러닝 라이브러리이다.


6.2.Dataset, DataLoader 생성
데이터를 읽어오고, 그런 다음 x와 y를 분리한다.
y는 target data라고 할 수 있다. 그래서 가장 중요한 데이터인 MEDV을 기준으로 target을 설정한다.
코드 중간중간에 to_frame 같은 함수들을 잘 파악하자.

그런 다음 trainset과 testset으로 데이터를 분리한다.

그런 다음 feature scaling을 한다.
이는 컬럼들의 scaling을 맞춰주는 작업이다.


아래는 위의 과정을 매소드를 이용해서 간단하게 한 버전이다.

그런 다음, TensorDataset을 통해 Dataset을 생성한다.

그런 다음, DataLoader를 생성한다.
#DataLoader 생성
boston_trainloader = DataLoader(boston_trainset,batch_size=200,shuffle=True,drop_last=True) #drop_last를 통해 '몫'이 아닌 '나머지'들을 정리해 낼 수 있다.
boston_testloader = DataLoader(boston_testset,batch_size=len(boston_testset)) #나중에 사이즈가 바뀌더라도 잘 할 수 있도록 len으로 설정한다.
print("epoch당 step수:",len(boston_trainloader),len(boston_testloader)) print의 결과는
epoch당 step수: 2 1
와 같이 나온다.
6.3.모델정의
dataset과 dataloader를 생성했으니, 이제 모델을 생성하자.
#dataset이랑 dataloader를 생성했으니, 이제 모델을 정의해야 한다.
class BostonModel(nn.Module):
def __init__(self):
#nn.Module의 __init__() 실행 =>초기화
super().__init__()
#forward propagation(예측) 할 때 필요한 layer들을 생성한다.
self.lr1 = nn.Linear(in_features=13,out_features=32) #13은 우리가 하는 예시의 데이터의 수이다.
#입력이 13이고 출력이 32라는 것은 weight를 13*32짜리를 만들겠다는 것이다.
self.lr2 = nn.Linear(32,16) #들어가는 것이 32이니까 나가는 것을 약수인 16으로 설정.(사실 무슨 값으로 해도 무방하긴 하다.)
##lr3을 출력 layer로 만든다. out_features를 지정해야 하는데, 이는 모델이 출력해야 할 값의 개수에 맞춰준다.
self.lr3 = nn.Linear(16,1) # 최종적으로 1개를 출력한다. 집값 하나를 예측해야 하기 때문이다.
def forward(self,X):
out = self.lr1(X) #선형
out = nn.ReLU()(out) #비선형 #lr1을 한 다음 relu함수에 이를 집어 넣는다. relu객체를 생성한 다음, 그 안에다 넣는 것이다.
out = self.lr2(out)#선형
out = nn.ReLU()(out)#비선형 #다시 한번 relu를 쓴다.
out=self.lr3(out) #출력 레이어(이 값이 모델의 예측값이 된다.)
#회귀의 출력결과에는 activation 함수를 정의하지 않는다.
# 예외: 출력값의 범위가 정해져 있고 그 범위값을 출력하는 함수가 있는 경우에는 예외이다.
# 범위: 0~1 -> logistic (nn.sigmoid())
# -1~1 -> tanh(nn.Tanh())
return out #out을 최종적으로 return 한다.
이렇게 함수를 정의했으면, 모델을 생성하고 모델의 구조를 확인한다.

summary 메소드를 통해 모델의 구조를 확인한다.

아래는 출력된 정보이다.
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
BostonModel [100, 1] --
├─Linear: 1-1 [100, 32] 448
├─Linear: 1-2 [100, 16] 528
├─Linear: 1-3 [100, 1] 17
==========================================================================================
Total params: 993
Trainable params: 993
Non-trainable params: 0
Total mult-adds (M): 0.10
==========================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 0.04
Params size (MB): 0.00
Estimated Total Size (MB): 0.05
==========================================================================================6.4.학습
#학습 + 검증
boston_model = boston_model.to(device) #모델: 1. 생성 2. device를 설정
#loss 함수 정의 - 회귀: mse
loss_fn = nn.MSELoss()
#하이퍼파라미터(우리가 설정함.) 정의
LR=0.001
N_EPOCH =1000
#optimizer를 정의한다.
optimizer = torch.optim.RMSprop(boston_model.parameters(),lr=LR) #torch.optim 모듈에 최적화알고리즘들이 정의되어 있다. (모델의 파라미터, 학습률)
#최적화할 대상이 boston_model의 파라미터들임을 알려준다.
이렇게 정의를 했으면, 에폭별 학습 결과를 저장할 리스트가 필요하다.
#에폭별 학습 결과를 저장할 리스트
##train loss와 validation loss를 저장한다. (valid는 학습 중에 성능을 체크하는 것이기 때문이다.)
train_loss_list =[]
valid_loss_list =[]이렇게 까지 잘 했으면, 자, 이제는 for문을 통해 epoch을 돌릴 차례이다.
import time
##train(학습/훈련)
## 두 단계 ->Train+Validation => step 별로 train => epoch 별로 검증한다.
s=time.time() #시간을 알려주는 함수이다.
for epoch in range(N_EPOCH):
# 한 epoch에 대한 train 코드
########################################
# train - 모델을 train mode로 변경한다.
########################################
boston_model.train() #train 모드로 변경
train_loss = 0.0 #현재 epoch의 train_loss를 저장할 변수
### batch 단위로 학습 =>step
for X,y in boston_trainloader:
# 한 step에 대한 train 코드
# 1. X,y를 device로 옮긴다. =>모델과 동일한 device에 위치시켜야 한다.
X,y =X.to(device), y.to(device)
#2.모델 추정(예측) =>forward propagation
pred = boston_model(X)
#3. loss 계산,파라미터 초기화
loss = loss_fn(pred,y) #오차 계산 ->grad_fn
optimizer.zero_grad()
#4.back propagation ->파라미터들의 gradient값들을 계산한다.
loss.backward() #loss에 대한 모든 parameter들에 대한 gradient를 계산한다. ---- 변수의 grad 속성에 저장.
#5. 파라미터 업데이트
optimizer.step()
#이렇게 하면 weight,bias가 업데이트가 된다.
#6.현 step의 loss를 train_loss에 누적한다.
train_loss += loss.item()
#train_loss의 전체 평균을 계산한다. step수로 나눠서 전체 평균을 계산한다.
train_loss /= len(boston_trainloader) #step수로 나누기.
######################################
# validation - 모델을 평가(eval) mode로 변경
# - 검증,평가,서비스를 할 때.
# -validation/test dataset으로 모델을 평가한다.
######################################
boston_model.eval() #평가 모드로 변경
# 검증 loss를 저장할 변수
valid_loss= 0.0
#검증은 gradient 계산할 필요가 없음. forward propagation시 도함수를 구할 필요가 없다.
with torch.no_grad():
for X_valid,y_valid in boston_testloader:
#1.device로 이동한다.
X_valid,y_valid = X_valid.to(device),y_valid.to(device)
#2.모델을 이용해 예측
pred_valid = boston_model(X_valid)
#3. 평가 -MSE
valid_loss += loss_fn(pred_valid,y_valid).item()
#반복문을 빠져 나오면, 검증셋에 대한 것이 끝난것이다.
# valid_loss 평균
valid_loss /=len(boston_testloader)
# 현 epcoh에 대한 학습 결과 로그를 출력한다. +list에 추가.
print(f"[{epoch+1}/{N_EPOCH}] train loss: {train_loss:.4f},valid loss: {valid_loss:.4f}")
train_loss_list.append(train_loss)
valid_loss_list.append(valid_loss)
e = time.time()
#코드를 다시 한번 한 호흡에 실행을 해 보면, train loss와 valid loss가 둘 다 줄어들고 있음을 알 수 있다.
아래는 출력결과를 일부 따 온것이다.
[1/1000] train loss: 6.2860,valid loss: 21.0379
[1000/1000] train loss: 1.8609,valid loss: 22.2795
훈련을 하면 할수록 loss가 줄어야 하는데, train loss는 많이 줄었지만 valid loss는 줄지 않았다. 왜 이럴까? 그 이유를 살펴보자.
6.5.그래프 그리기
print("걸린 시간:",(e-s),"초")
#이렇게 데이터가 적은 예제는, 걸린 시간이 그렇게 길지 않다. 그래서 시간차를 비교하는 것이 적합하지 않을 지도 모른다.
#train loss, valid loss의 epoch별 변화의 흐름을 시각화하자.
plt.plot(range(1,N_EPOCH+1),train_loss_list,label="Train Loss")
plt.plot(range(1,N_EPOCH+1),valid_loss_list,label="Validation Loss")
#그래프를 통해 값의 추세를 알 수 있다.
plt.xlabel("EPOCH")
plt.ylabel("Loss")
#plt.ylim(3,50)
plt.legend()
plt.show()
#코드의 과정을 여러번 반복해서는 안되는게, train_loss_list에 많은 값이 들어가게 되면 고정된 epoch보다 크기가 커지므로 오류가 난다.아래는 걸린 시간과 그래프를 캡쳐한 것이다.
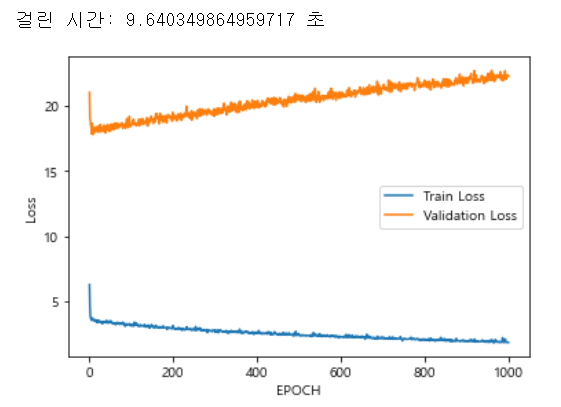
6.6.모델 저장
아래는 모델을 저장하는 코드이다.

아래는 모델을 불러오고, 그 정보를 summary 메소드를 통해 알아내는 코드이다.
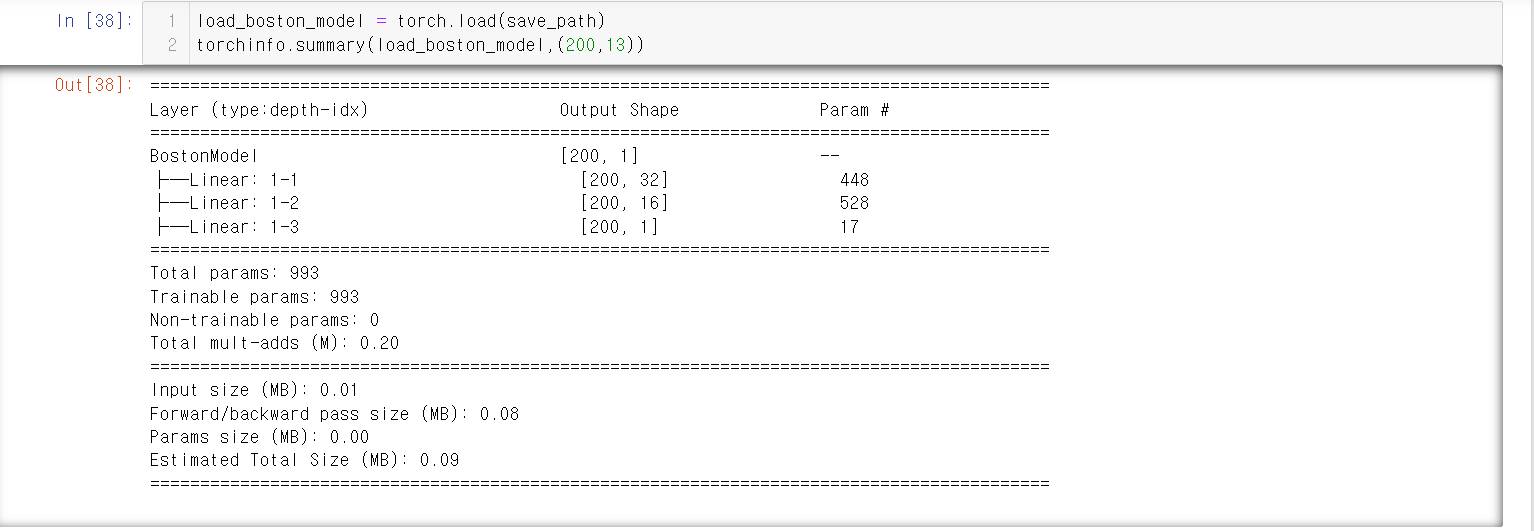
6.7.예측 서비스
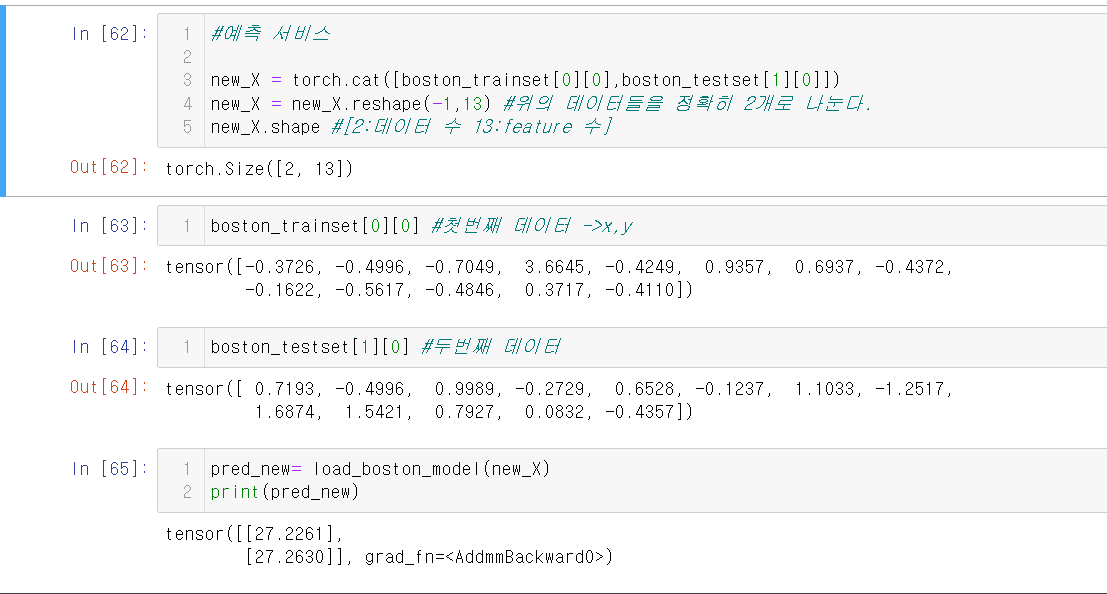
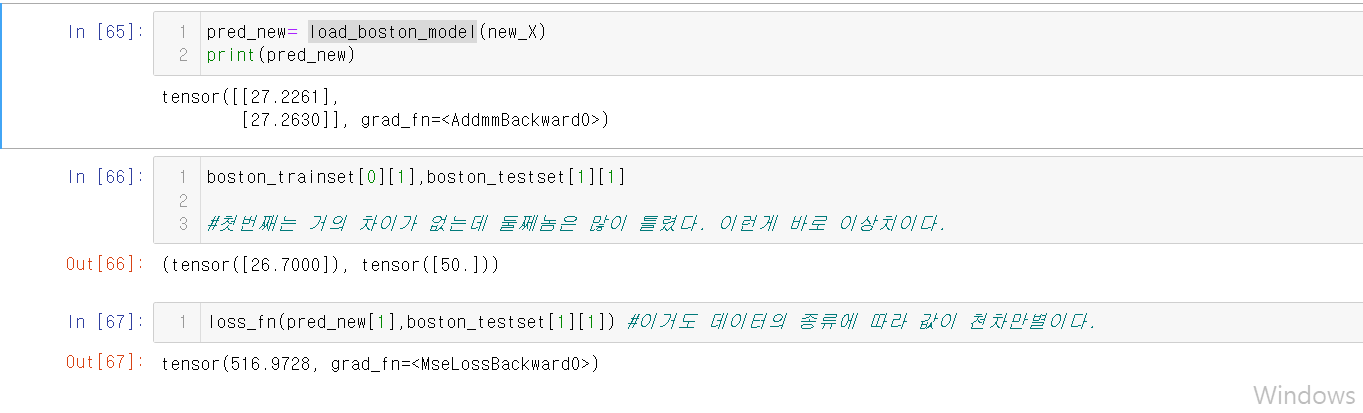
위의 그림들과 같이 데이터를 예측해 볼 수 있다.
