0.들어가기 전에
분류에도 종류가 있다.
2가지가 존재한다.
1.다중분류: 범주값이 여러개인 경우
2.이진분류: positive와 negative를 구분하는 것
1.Fashion MNIST Dataset - 다중분류(Multi-Class Classification) 문제
10개의 범주와 7만개의 흑백 이미지로 구성된 패션 MNIST 데이터셋이다.

이미지는 28*28이고 GRAY SCALE이다.
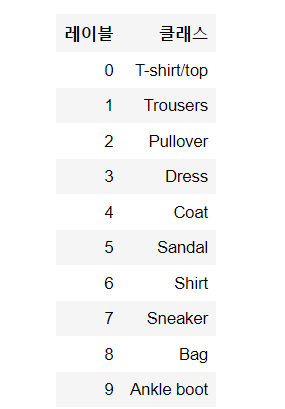
레이블은 0에서 9까지의 정수 배열이다.
레이블과 클래스들의 예시는 다음과 같다.
2.import
라이브러리들을 import하자. 하나라도 빠지면 오류가 쉽게 나기 때문에 유의해야 한다.
#import 구문 따로 설정하기.
#문제가 새롭게 시작될 때 마다 import를 따로 한다고 보면 편하다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#from sklearn.preprocessing import StandardScaler
#from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import torchinfo
#이렇게 import 하는 구문을 따로 두는 것이 중요하다.
device = "cuda" if torch.cuda.is_available() else "cpu"
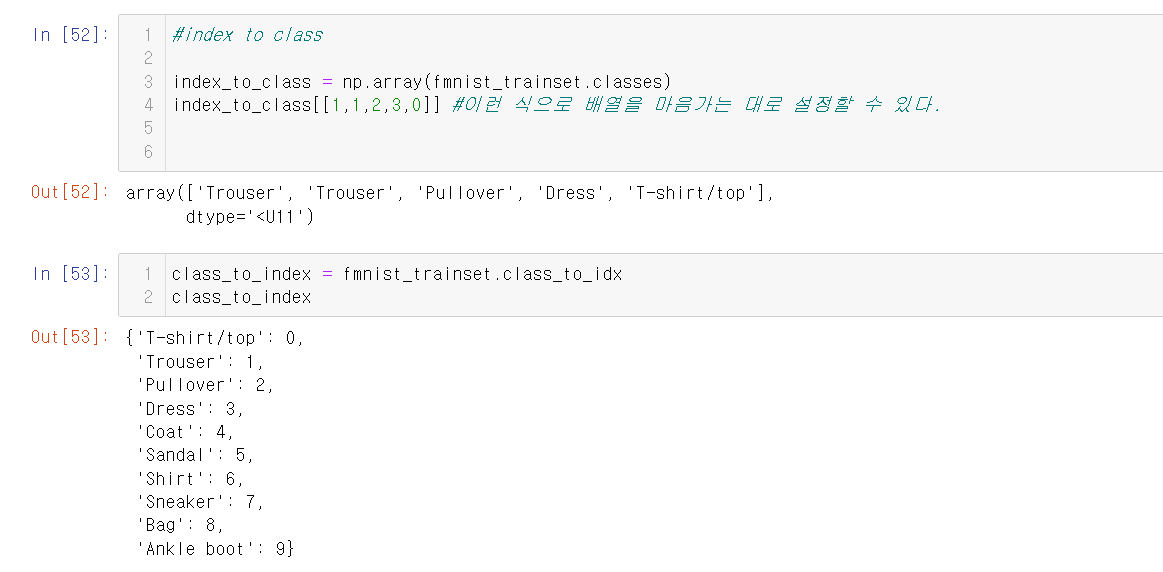
print(device)그런 다음, index_to_class을 통해 라벨들을 정의한다.
index_to_class = np.array(['T-shirt/top', 'Trousers', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'])3.dataset,dataloader 생성
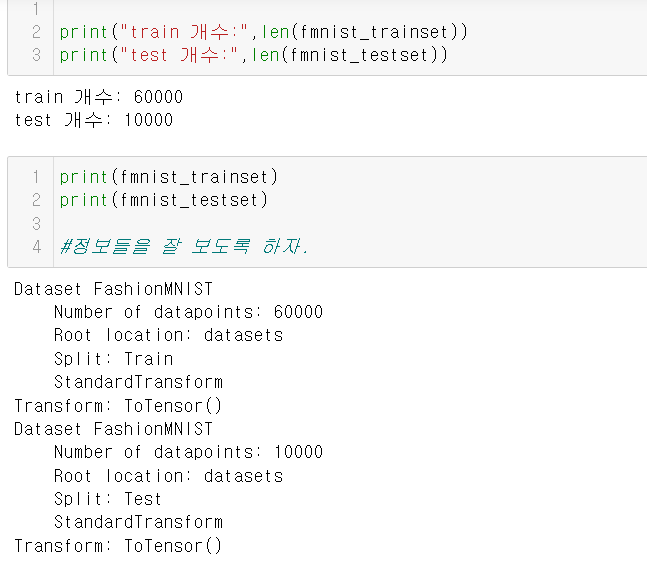
먼저 MNIST 데이터를 다운로드 한다.
#Dataset, DataLoader 생성
#Built in Dataset
#이 코드를 통해 download를 한다.
fmnist_trainset = datasets.FashionMNIST(root="datasets",train=True,download=True,transform=transforms.ToTensor())
그런 다음, testset data를 다운로드한다.
#testset data를 다운로드한다.
fmnist_testset = datasets.FashionMNIST(root="datasets",train=False,download=True,transform=transforms.ToTensor())이 둘의 차이점은 train을 True로 하느냐 False로 하느냐의 차이이다.
관련 정보들을 잘 보도록 하자.
4.index to class
5.이미지 확인

5.dataloader
DataLoader라는 메소드를 통해 DataLoader를 생성한다.
#dataloader
#train이느냐 test이느냐에 따라서 코드를 따로 코딩하면 된다.
fmnist_trainloader = DataLoader(fmnist_trainset,batch_size=128,shuffle=True,drop_last=True)
fmnist_testloader = DataLoader(fmnist_testset,batch_size=128)6.모델 정의
##모델 정의
class FashionMNIST(nn.Module):
def __init__(self):
super().__init__()
#입력 이미지를 받아서 처리후 리턴====입력 이미지의 feature수만큼!(28*28=784)
#가면 갈수록 feature 수를 줄이는 이유는, 전체 이미지 중에서 핵심적인 부분만 찾기 위해서 이렇게 하는 것이다.
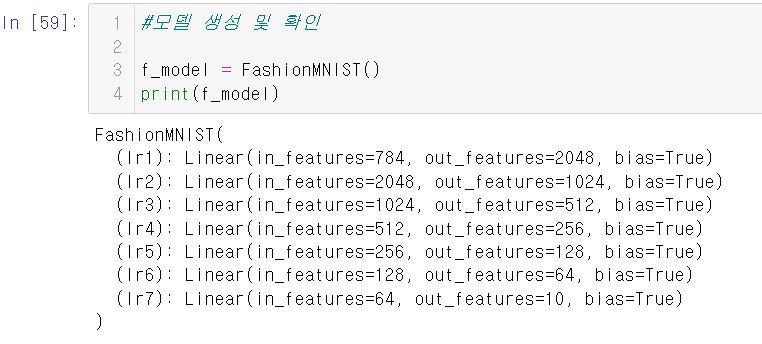
self.lr1 = nn.Linear(784,2048) #784-> 2048
self.lr2 = nn.Linear(2048,1024) #2048-> 1024
self.lr3 = nn.Linear(1024,512) #1024->512
self.lr4 = nn.Linear(512,256) #512->256
self.lr5 = nn.Linear(256,128) #256->128
self.lr6 = nn.Linear(128,64) #128->64
#output----옷 종류(정답 클래스 개수)의 수에 맞춘다.
self.lr7 = nn.Linear(64,10) #각 클래스별 확률이 출력이 되도록 한다.
def forward(self,X):
#X -> (batch,channel,height,width) ==> (batch,all_feature)
#out = torch.flatten(X,start_dim=1)
out = nn.Flatten()(X)
out = nn.ReLU()(self.lr1(out))
out = nn.ReLU()(self.lr2(out))
out = nn.ReLU()(self.lr3(out))
out = nn.ReLU()(self.lr4(out))
out = nn.ReLU()(self.lr5(out))
out = nn.ReLU()(self.lr6(out))
##output
out = self.lr7(out)
return out
#lr1 ~ lr7
## forward 처리를 구현한다. => Linear -> ReLU()
#lr6까지는 처리를 해 주고, 7은 하지 말자......
7.모델 생성 및 확인
8.학습
모델을 잘 생성했고, 확인도 잘 했다면, 이제부터 본격적으로 학습을 시킬 차례이다.
먼저 하이퍼파라미터들을 정의하자.
###학습(train)
LR=0.001
N_EPOCH=200
#모델을 device로 이동한다.
f_model = f_model.to(device)
#loss fn ==>다중분류
loss_fn = nn.CrossEntropyLoss() #다중 분류용 log loss
#optimizer
optimizer = torch.optim.Adam(f_model.parameters(),lr=LR)
그런 다음, 모델을 본격적으로 학습을 시키자.
# train
import time
N_EPOCH=20
## 각 에폭별 학습이 끝나고 모델 평가한 값을 저장.
train_loss_list = []
valid_loss_list = []
valid_acc_list = [] # test set의 정확도 검증 결과 => 전체데이터 중 맞은데이터의 개수
s = time.time()
for epoch in range(N_EPOCH):
######### train
f_model.train()
train_loss = 0.0 # 현재 epoch의 tain set의 loss
for X_train, y_train in fmnist_trainloader:
# 1. device로 옮기기. model과 같은 device로 옮긴다.
X_train, y_train = X_train.to(device), y_train.to(device)
# 2. 예측 - 순전파
pred_train = f_model(X_train)
# 3. Loss 계산
loss = loss_fn(pred_train, y_train) # (예측, 정답)
# 4 모델 파라미터 업데이트
## 4-1 gradient 초기화
optimizer.zero_grad()
## 4-2 grad 계산 - (오차) 역전파
loss.backward()
## 4-3 파라미터 업데이트
optimizer.step()
# train loss를 누적
train_loss += loss.item()
# 1에폭 학습 종료 => train_loss의 평균을 list에 저장.
train_loss /= len(fmnist_trainloader) # 누적_train_loss/step수
train_loss_list.append(train_loss)
######### validation
f_model.eval()
valid_loss = 0.0 # 현재 epoch의 validation loss 저장할 변수
valid_acc = 0.0 # 현재 epoch의 validation accuracy(정확도)를 저장할 변수
### 정확도: 맞은것의 개수 / 전체 개수
with torch.no_grad(): # 도함수 구할 필요가 없으므로 no grad context manager에서 실행.
for X_valid, y_valid in fmnist_testloader:
# 1. device로 옮기기
X_valid, y_valid = X_valid.to(device), y_valid.to(device)
# 2. 예측
pred_valid = f_model(X_valid) # class별 정답일 가능성을 출력 (batch, 10)
pred_label = pred_valid.argmax(dim=-1) # 정답 class를 조회. (pred_valid에서 가장 큰값을 가진 index)
# 3. 평가
## 3.1 loss 계산
loss_valid = loss_fn(pred_valid, y_valid) ## loss_fn() batch만큼 평균을 계산.
valid_loss += loss_valid
## 3.2 정확도 계산
valid_acc += torch.sum(pred_label == y_valid).item()
# 한 epoch에 대한 평가 완료 => valid_loss_list, valid_acc_list에 추가
valid_loss /= len(fmnist_testloader) # step수로 나눠서 평균을 계산
valid_acc /= len(fmnist_testloader.dataset) # testset의 총 데이터 개수로 나눔.
valid_loss_list.append(valid_loss)
valid_acc_list.append(valid_acc)
print(f"[{epoch+1:02d}/{N_EPOCH}] train loss: {train_loss} valid loss: {valid_loss} valid acc: {valid_acc}")
e = time.time()
#정확도는 뭐 한 89퍼센트 정도 나오는 것 같다.
아래는 출력 결과이다. 출력 결과에서 train loss와 valid loss를 볼 수 있다.
[01/20] train loss: 0.6138021254386657 valid loss: 0.4780694544315338 valid acc: 0.8259
[02/20] train loss: 0.4010523445904255 valid loss: 0.3975680470466614 valid acc: 0.8577
[03/20] train loss: 0.35366268032509035 valid loss: 0.3910999000072479 valid acc: 0.8648
[04/20] train loss: 0.3245452255902127 valid loss: 0.38254648447036743 valid acc: 0.8553
[05/20] train loss: 0.30370562061922163 valid loss: 0.3613075315952301 valid acc: 0.8695
[06/20] train loss: 0.2894981934283024 valid loss: 0.3518320620059967 valid acc: 0.8724
[07/20] train loss: 0.27316433807405144 valid loss: 0.35553109645843506 valid acc: 0.8733
[08/20] train loss: 0.25936859327121675 valid loss: 0.32939621806144714 valid acc: 0.8881
[09/20] train loss: 0.25055358950526285 valid loss: 0.3308366537094116 valid acc: 0.8846
[10/20] train loss: 0.24118317515613177 valid loss: 0.3311608135700226 valid acc: 0.8826
[11/20] train loss: 0.23363791995196262 valid loss: 0.32998690009117126 valid acc: 0.8849
[12/20] train loss: 0.22380322948671305 valid loss: 0.32938218116760254 valid acc: 0.8909
[13/20] train loss: 0.21311531752411628 valid loss: 0.3324180543422699 valid acc: 0.8894
[14/20] train loss: 0.20777273931118667 valid loss: 0.3586808145046234 valid acc: 0.8868
[15/20] train loss: 0.20002475476417786 valid loss: 0.32383593916893005 valid acc: 0.889
[16/20] train loss: 0.1902962986730103 valid loss: 0.33027198910713196 valid acc: 0.8934
[17/20] train loss: 0.18666476904390714 valid loss: 0.375872403383255 valid acc: 0.8815
[18/20] train loss: 0.18245970523064461 valid loss: 0.35894808173179626 valid acc: 0.8932
[19/20] train loss: 0.17226054501106852 valid loss: 0.3313908874988556 valid acc: 0.8919
[20/20] train loss: 0.1672223322173087 valid loss: 0.38105931878089905 valid acc: 0.8947
9.결과 시각화
#결과 시각화
#loss는 내려갈 수록 즣은거고, valid는 올라갈 수록 좋다.
#허나, 중요한 것은 과대적합이 나올 수도 있다는 것이다. 그래서 중간에 끊어주는 것이 중요하다.
#그리고, loss나 정확도가 왔다리갔다리 하는 경우가 많다.
#그 중에서 성능이 가장 좋은 놈을 찾는게 중요한데.... 그 놈을 찾는 것도 감이고 실력이다.
#근데..... 특정 시점에서 더 이상 정확도 등이 획기적으로 개선되지 않으면 중간에 종료시키는 것도 중요하다.
plt.rcParams["font.family"] = "Malgun gothic"
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.plot(train_loss_list,label="train")
plt.plot(train_loss_list,label="validation")
plt.title("Epoch 별 loss 변화")
plt.legend()
plt.subplot(1,2,2)
plt.plot(valid_acc_list)
plt.title("Validation Accuracy")
plt.tight_layout()
plt.show()결과는 아래 그래프대로 나온다.
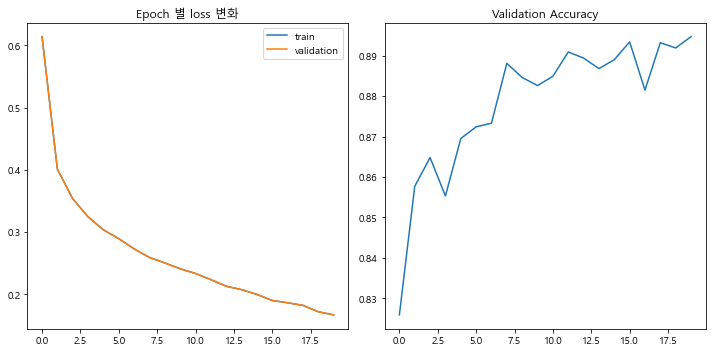
10.숙지해야 할 점
#모델 학습이 진행이 되면 어느 시점부터는 성능이 떨어지기 시작한다.
#학습도중 성능 개선될 때마다 저장.(가장 좋은 성능의 모델을 서비스 할 수 있게한다.)
#1. 학습 도중 성능이 개선 될 때마다 저장한다.
#2. 더 이상 성능이 개선이 안되면 학습을 중지한다.
11.중간에 중단하는 코드
학습의 결과가 더 나아지지 않으면 중단에 중단하는 코드이다.
import time
LR = 0.001
N_EPOCH = 1000
# 모델을 device 로 이동.
f_model = FashionMNIST()
f_model = f_model.to(device)
# loss fn -> 다중분류: nn.CrossEntropyLoss() ==> 다중 분류용 Log loss
loss_fn = nn.CrossEntropyLoss()
# optimizer
optimizer = torch.optim.Adam(f_model.parameters(), lr=LR)
########################################
# 조기종료 + 모델 저장을 위한 변수 추가
########################################
###### 모델 저장을 위한변수
# 학습 중 가장 좋은 성능 평가지표를 저장. 현 epoch의 지표가 이 변수값보다 좋으면 저장
# 평가지표: validation loss
best_score = torch.inf
save_model_path = "models/fashion_mnist_best_model.pth"
###### 조기 종료를 위한 변수: 특정 epoch동안 성능 개선이 없으면 학습을 중단
patience = 5 # 성능이 개선 될지를 기다릴 epoch 수. patience 번 만큼 개선이 안되면 중단.(보통 10이상 지정)
trigger_cnt = 0 # 성능 개선을 몇번 째 기다리는 지 정할 변수. patience==trigger_cnt : 중단
# train
## 각 에폭별 학습이 끝나고 모델 평가한 값을 저장.
train_loss_list = []
valid_loss_list = []
valid_acc_list = [] # test set의 정확도 검증 결과 => 전체데이터 중 맞은데이터의 개수
s = time.time()
for epoch in range(N_EPOCH):
######### train
f_model.train()
train_loss = 0.0 # 현재 epoch의 tain set의 loss
for X_train, y_train in fmnist_trainloader:
# 1. device로 옮기기. model과 같은 device로 옮긴다.
X_train, y_train = X_train.to(device), y_train.to(device)
# 2. 예측 - 순전파
pred_train = f_model(X_train)
# 3. Loss 계산
loss = loss_fn(pred_train, y_train) # (예측, 정답)
# 4 모델 파라미터 업데이트
## 4-1 gradient 초기화
optimizer.zero_grad()
## 4-2 grad 계산 - (오차) 역전파
loss.backward()
## 4-3 파라미터 업데이트
optimizer.step()
# train loss를 누적
train_loss += loss.item()
# 1에폭 학습 종료 => train_loss의 평균을 list에 저장.
train_loss /= len(fmnist_trainloader) # 누적_train_loss/step수
train_loss_list.append(train_loss)
######### validation
f_model.eval()
valid_loss = 0.0 # 현재 epoch의 validation loss 저장할 변수
valid_acc = 0.0 # 현재 epoch의 validation accuracy(정확도)를 저장할 변수
### 정확도: 맞은것의 개수 / 전체 개수
with torch.no_grad(): # 도함수 구할 필요가 없으므로 no grad context manager에서 실행.
for X_valid, y_valid in fmnist_testloader:
# 1. device로 옮기기
X_valid, y_valid = X_valid.to(device), y_valid.to(device)
# 2. 예측
pred_valid = f_model(X_valid) # class별 정답일 가능성을 출력 (batch, 10)
pred_label = pred_valid.argmax(dim=-1) # 정답 class를 조회. (pred_valid에서 가장 큰값을 가진 index)
# 3. 평가
## 3.1 loss 계산
loss_valid = loss_fn(pred_valid, y_valid) ## loss_fn() batch만큼 평균을 계산.
valid_loss += loss_valid.item()
## 3.2 정확도 계산
valid_acc += torch.sum(pred_label == y_valid).item()
# 한 epoch에 대한 평가 완료 => valid_loss_list, valid_acc_list에 추가
valid_loss /= len(fmnist_testloader) # step수로 나눠서 평균을 계산
valid_acc /= len(fmnist_testloader.dataset) # testset의 총 데이터 개수로 나눔.
valid_loss_list.append(valid_loss)
valid_acc_list.append(valid_acc)
print(f"[{epoch+1:02d}/{N_EPOCH}] train loss: {train_loss} valid loss: {valid_loss} valid acc: {valid_acc}")
##################################
# 조기종료여부, 모델 저장 처리
# 저장: 현 epoch valid_loss 가 best_score 보다 개선된 경우 저장(작으면 개선)
#################################
if valid_loss < best_score: # 성능이 개선된 경우.
#저장 로그 출력
print(f"====> 모델저장: {epoch+1} Epoch - 이전 valid_loss: {best_score}, 현재 valid_loss: {valid_loss}")
# best_score교체
best_score = valid_loss
# 저장
torch.save(f_model, save_model_path)
# trigger_cnt 를 0으로 초기화
trigger_cnt = 0
else: # 성능개선이 안된경우.
# trigger_cnt를 1 증가
trigger_cnt += 1
if patience == trigger_cnt: # patience 만큼 대기 ==> 조기 종료
#로그
print(f"=====> {epoch+1} Epoch에서 조기종료-{best_score}에서 개선 안됨")
break
e = time.time()결과
[01/1000] train loss: 0.6496741068032053 valid loss: 0.4531976199602779 valid acc: 0.8362
====> 모델저장: 1 Epoch - 이전 valid_loss: inf, 현재 valid_loss: 0.4531976199602779
[02/1000] train loss: 0.3880012427958158 valid loss: 0.4072249775068669 valid acc: 0.8586
====> 모델저장: 2 Epoch - 이전 valid_loss: 0.4531976199602779, 현재 valid_loss: 0.4072249775068669
[03/1000] train loss: 0.352161408521426 valid loss: 0.36911332965651644 valid acc: 0.8698
====> 모델저장: 3 Epoch - 이전 valid_loss: 0.4072249775068669, 현재 valid_loss: 0.36911332965651644
[04/1000] train loss: 0.321003187320426 valid loss: 0.3762322586925724 valid acc: 0.8652
[05/1000] train loss: 0.3025762515986322 valid loss: 0.35094515847254404 valid acc: 0.8764
====> 모델저장: 5 Epoch - 이전 valid_loss: 0.36911332965651644, 현재 valid_loss: 0.35094515847254404
[06/1000] train loss: 0.28432955529190534 valid loss: 0.34837701633761203 valid acc: 0.8805
====> 모델저장: 6 Epoch - 이전 valid_loss: 0.35094515847254404, 현재 valid_loss: 0.34837701633761203
[07/1000] train loss: 0.2712523322074841 valid loss: 0.3442836813157118 valid acc: 0.879
====> 모델저장: 7 Epoch - 이전 valid_loss: 0.34837701633761203, 현재 valid_loss: 0.3442836813157118
[08/1000] train loss: 0.26057134926892245 valid loss: 0.34120869881744625 valid acc: 0.8849
====> 모델저장: 8 Epoch - 이전 valid_loss: 0.3442836813157118, 현재 valid_loss: 0.34120869881744625
[09/1000] train loss: 0.24514237944132242 valid loss: 0.3468181351317635 valid acc: 0.8787
[10/1000] train loss: 0.24046144659957316 valid loss: 0.3381842834096921 valid acc: 0.8848
====> 모델저장: 10 Epoch - 이전 valid_loss: 0.34120869881744625, 현재 valid_loss: 0.3381842834096921
[11/1000] train loss: 0.2289039466339044 valid loss: 0.3322570786068711 valid acc: 0.8855
====> 모델저장: 11 Epoch - 이전 valid_loss: 0.3381842834096921, 현재 valid_loss: 0.3322570786068711
[12/1000] train loss: 0.21838627486593193 valid loss: 0.34056916776337204 valid acc: 0.8834
[13/1000] train loss: 0.21135685075488356 valid loss: 0.35757308632512635 valid acc: 0.8867
[14/1000] train loss: 0.20625789589288399 valid loss: 0.3297886515059803 valid acc: 0.8896
====> 모델저장: 14 Epoch - 이전 valid_loss: 0.3322570786068711, 현재 valid_loss: 0.3297886515059803
[15/1000] train loss: 0.19638435173238444 valid loss: 0.34945273154144046 valid acc: 0.8907
[16/1000] train loss: 0.18816609726820746 valid loss: 0.3405876886099577 valid acc: 0.8955
[17/1000] train loss: 0.18111535287501976 valid loss: 0.3677117658566825 valid acc: 0.8843
[18/1000] train loss: 0.17889012716328487 valid loss: 0.38315039837756487 valid acc: 0.8885
[19/1000] train loss: 0.17681389878320897 valid loss: 0.38808519084336635 valid acc: 0.8885
=====> 19 Epoch에서 조기종료-0.3297886515059803에서 개선 안됨12.test_dataloader로 평가
#### test_dataloader 로 평가
best_model = best_model.to(device)
best_model.eval()
valid_loss = 0.0 # 현재 epoch의 validation loss 저장할 변수
valid_acc = 0.0 # 현재 epoch의 validation accuracy(정확도)를 저장할 변수
### 정확도: 맞은것의 개수 / 전체 개수
with torch.no_grad(): # 도함수 구할 필요가 없으므로 no grad context manager에서 실행.
for X_valid, y_valid in fmnist_testloader:
# 1. device로 옮기기
X_valid, y_valid = X_valid.to(device), y_valid.to(device)
# 2. 예측
pred_valid = best_model(X_valid) # class별 정답일 가능성을 출력 (batch, 10)
pred_label = pred_valid.argmax(dim=-1) # 정답 class를 조회. (pred_valid에서 가장 큰값을 가진 index)
# 3. 평가
## 3.1 loss 계산
loss_valid = loss_fn(pred_valid, y_valid) ## loss_fn() batch만큼 평균을 계산.
valid_loss += loss_valid.item()
## 3.2 정확도 계산
valid_acc += torch.sum(pred_label == y_valid).item()
# 한 epoch에 대한 평가 완료 => valid_loss_list, valid_acc_list에 추가
valid_loss /= len(fmnist_testloader) # step수로 나눠서 평균을 계산
valid_acc /= len(fmnist_testloader.dataset) # testset의 총 데이터 개수로 나눔