1.이진분류 문제 처리 모델의 두가지 방법
1.positive일 확률을 출력하도록 구현한다.
2.negative일 확률과 positive일 확률을 출력하도록 구현한다.
2.우리가 풀 문제는 위스콘신 대학교에서 제공한 종양의 악성/양성 여부 분류를 위한 데이터셋이다.
3.주의해야 할 점
이진 분류는 주로 양성일 확률을 출력하도록 구현하는 경우가 많다.
그런데, 양성이라고 꼭 좋지는 않다.
코로나도 음성이면 좋은 것처럼 말이다.
4.import
from sklearn.datasets import load_breast_cancer
#관련 데이터에 관한 것을 import 한다.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
import numpy as np
import matplotlib.pyplot as pltdevice가 cpu에 있는지 확인하기 위해서는 아래의 코드를 실행하는 것이 좋다.
아래의 코드의 결과는 cpu이다.
device = "cpu" if torch.cuda.is_available() else "cpu"
device5.Dataset, DataLoader 생성
X,y = load_breast_cancer(return_X_y=True)
print(type(X),type(y))
print(X.shape,y.shape)
print(np.unique(y))코드의 결과는 다음과 같다.
<class 'numpy.ndarray'> <class 'numpy.ndarray'>
(569, 30) (569,)
[0 1]
그런 다음, 악성과 양성에 관해 class와 index를 정의한다.

6.train/test set 분리
### train/test set 분리
X_train, X_test, y_train, y_test = train_test_split(X,y, #나눌 대상 X,y
test_size=0.25, #비율을 정한다.
stratify=y #클래스 별 비율을 맞춰서 나눈다.
)
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)결과는
(426, 30) (143, 30) (426, 1) (143, 1)
와 같이 나온다.
7.전처리
## 전처리 - Feature Scaling (컬럼들의 scale을 맞춘다.)
#StandardScaler ===> 평균:0, 표준편차 :1 을 기준으로 맞춘다.
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) #trainset으로 fit한 scaler를 이용해 변환.
8.Tensor의 변환
#### ndarray => Tensor 변환 =====> dataset을 구성 =====> dataloader 구성
#ndarray =>torch.Tensor
X_train_tensor = torch.tensor(X_train_scaled,dtype=torch.float32)
X_test_tensor = torch.tensor(X_test_scaled,dtype=torch.float32)
y_train_tensor = torch.tensor(y_train,dtype=torch.float32)
y_test_tensor = torch.tensor(y_test,dtype=torch.float32)
9.Dataset/dataloader의 생성
# Dataset 생성 ==> 매모리의 tensor를 dataset으로 생성 => tensordataset
#TensorDataset을 활용하면 더 쉽게 data를 구분할 수 있다.
trainset = TensorDataset(X_train_tensor,y_train_tensor)
testset = TensorDataset(X_test_tensor,y_test_tensor)
#dataloader
train_loader = DataLoader(trainset, batch_size=200, shuffle=True, drop_last=True)
test_loader = DataLoader(testset, batch_size=len(testset))
10.Model 클래스 정의
class BCModel(nn.Module):
def __init__(self):
super().__init__()
self.lr1 = nn.Linear(30,32)
self.lr2 = nn.Linear(32,8)
#출력 layer: 이진 분류 - positive의 확률 값 한 개를 출력한다.
self.lr3 = nn.Linear(8,1)
def forward(self,X):
# X (입력) shape: (batchsize,30)
#out = self.lr1(X)
#out = nn.ReLU(out)
out = nn.ReLU()(self.lr1(X)) #이런 식으로 해도 된다.
out = nn.ReLU()(self.lr2(out))
#이진분류 출력값 처리 ->Linear()는 한 개의 값을 출력한다. =>확률값으로 변경한다. ==> Sigmoid 함수를 Activation 함수로 사용한다.
out = self.lr3(out)
out = nn.Sigmoid()(out)
return out
이 코드에서 유의해야 할 점은, 이진분류이므로 한 개의 값을 출력해야 하기 때문에 마지막 linear에서 1을 출력한다는 것이다.
결과 출력
model = BCModel()
tmp_x = torch.ones(5,30)
print(tmp_x.shape)
tmp_y = model(tmp_x)
tmp_y
#0.xxxx->1(양성)일 확률
출력 결과는 다음과 같다.

11.일정 값보다 더 큰지/작은지 구분
#일정 값보다 더 큰지/작은지를 파악하는 것이 좋다.
#tensor객체.type(타입을 지정) ===> Tensor 데이터타입을 반환.
# bool -> int : False: 0, True :1
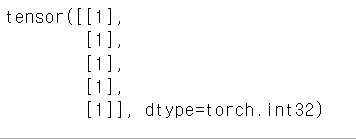
(tmp_y>0.5).type(torch.int32)이런 식으로 코드를 짜면 결과는 다음과 같이 나온다.
12.Train
아래는 train의 코드이다. 각 부분에 대한 설명을 자세히 했으니 코드를 읽으면서 잘 숙지하면 괜찮을 것이다.
#모델 생성
import time
#하이퍼파라미터
LR=0.001
N_EPOCH=1000
model = BCModel().to(device)
#loss 함수
loss_fn = nn.BCELoss() #binary cross entropy loss
# optimizer
optimizer = torch.optim.Adam(model.parameters(),lr=LR)
s=time.time()
######################################################
#에폭별 검증 : train loss, validation loss, validation accuracy
#조기종료(early stop) -성능 개선이 안되면 학습을 중단한다.
#가장 좋은 성능을 내는 에폭의 모델을 저장.
# 조기종료/모델 저장 ==>validation loss 기준.
#결과 정할 리스트
train_loss_list,valid_loss_list,valid_acc_list =[],[],[]
###모델 저장, 조기종료 관련 변수
best_score = torch.inf #validation loss
save_bcmodel_path = "models/bc_best_model.pth"
patience = 20 #20번 정도는 기다려 보지 뭐.
#성능이 개선 될 때까지 몇 에폭 기다릴 것인지....
trigger_cnt = 0
#성능이 개선 될 때까지 현재 몇 번째 기다렸는지.
for epoch in range(N_EPOCH):
#train
model.train()
train_loss=0.0
#step
for X_train,y_train in train_loader:
X_train,y_train = X_train.to(device),y_train.to(device)
#예측
pred_train =model(X_train) #예측
loss = loss_fn(pred_train, y_train) #오차 계산
#파라미터 업데이트
optimizer.zero_grad() #초기화
loss.backward() #grad 계산
optimizer.step() #파라미터 update
train_loss+=loss.item()
train_loss /= len(train_loader) #현재 epoch의 평균 train loss 계산.
###vaildation
model.eval()
valid_loss,valid_acc =0.0,0.0
with torch.no_grad():
for X_valid,y_valid in test_loader:
X_valid,y_valid = X_valid.to(device),y_valid.to(device)
pred_valid = model(X_valid) #값 1개 - positive일 확률
pred_label = (pred_valid >= 0.5).type(torch.int32) #label ==>정확도 계산
#loss
loss_valid = loss_fn(pred_valid,y_valid)
valid_loss += loss_valid.item()
#정확도
valid_acc += torch.sum(pred_label == y_valid).item()
#valid 검증 결과 계산
valid_loss /= len(test_loader)
valid_acc /= len(test_loader.dataset)
print(f"[{epoch+1}/{N_EPOCH}] train loss: {train_loss}, valid loss: {valid_loss}, valid accuracy: {valid_acc}")
#데이터를 저장한다.
train_loss_list.append(train_loss)
valid_loss_list.append(valid_loss)
valid_acc_list.append(valid_acc)
### 모델 저장 및 조기종료 처리
if valid_loss < best_score: # 성능 개선
print(f"======> {epoch+1}에폭에서 모델 저장. 이전 score: {best_score}, 현재 score: {valid_loss}")
torch.save(model,save_bcmodel_path)
best_score = valid_loss
trigger_cnt = 0
else: #성능개선이 되지 않았다는 이야기이다.
trigger_cnt += 1
if patience == trigger_cnt:
print(f"########### Early Stop: {epoch+1}")
#이렇게 하면, 언제 중단을 했는지 알 수 있다.
break
e=time.time()
print(f"학습시간: {e-s}초")
이런 식으로 코드를 짜면
[1/1000] train loss: 0.6575140953063965, valid loss: 0.6532841324806213, valid accuracy: 0.7552447552447552
======> 1에폭에서 모델 저장. 이전 score: inf, 현재 score: 0.6532841324806213
[2/1000] train loss: 0.6452004909515381, valid loss: 0.6390107870101929, valid accuracy: 0.7692307692307693
======> 2에폭에서 모델 저장. 이전 score: 0.6532841324806213, 현재 score: 0.6390107870101929
[3/1000] train loss: 0.6319022476673126, valid loss: 0.6254581212997437, valid accuracy: 0.8041958041958042
======> 3에폭에서 모델 저장. 이전 score: 0.6390107870101929, 현재 score: 0.6254581212997437
(이하 생략)이런 결과가 나온다.
12.학습결과 그래프로 그리기
#학습 결과를 그래프로 그려보자.
plt.plot(train_loss_list, label="train")
plt.plot(valid_loss_list, label="validation")
plt.legend()
plt.show()
#보다 보면, validation의 수치가 적어졌다가 확 올라간 것을 알 수 있다.
#그러므로, 중간에 모델을 stop 하는 것이 중요하다는 것을 알 수 있다.
그래프는 다음과 같다.
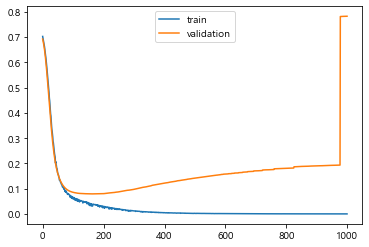
그런데, 여기에서 의문이 생긴다.
validation같은 경우에는 loss가 잘 줄어들다가 왜 갑자기 수직상승을 하는 거야?
이 의문점을 해결하기 위해, 우리는 과적합에 대한 공부를 해야 한다.
과적합에 대한 개념도 이 블로그에 있다. '딥러닝'이라는 카테고리에 있으니, 궁금하면 그 글도 봐주시길 바란다. ('딥러닝모델_성능개선'에 있다.)
