0.들어가기 전에
우리가 딥러닝의 모델을 설계를 잘 하려 해도, 실제 성능은 실망스러울 때가
많을 것이다.
그렇다면, 딥러닝 모델의 성능이 왜 떨어지는지, 그에 대한 것들을 공부하는
것이 필요하다.
1.모델의 성능
일반화,과대적합,과소적합이 있다.
1.일반화(Generalization)
훈련된 모델이 처음보는 데이터에 대해서 잘 추론할 수 있는 상태이다.
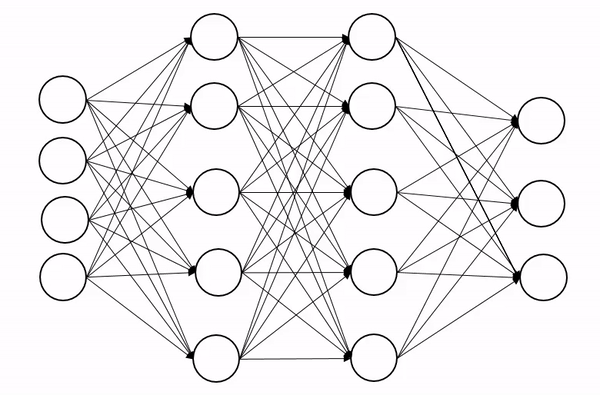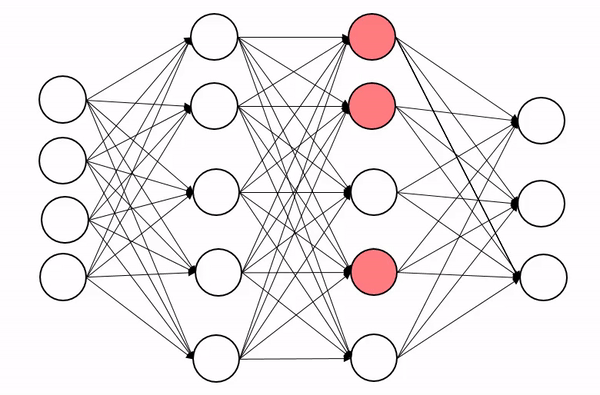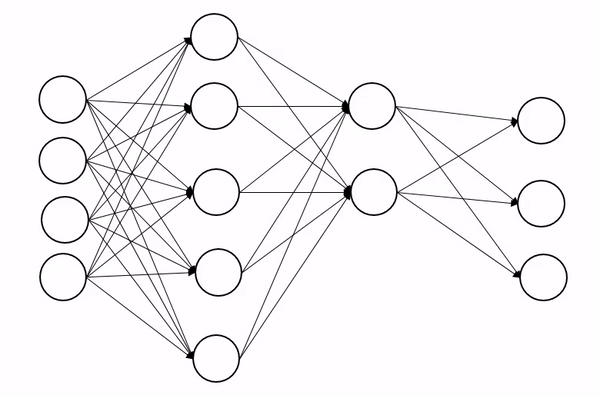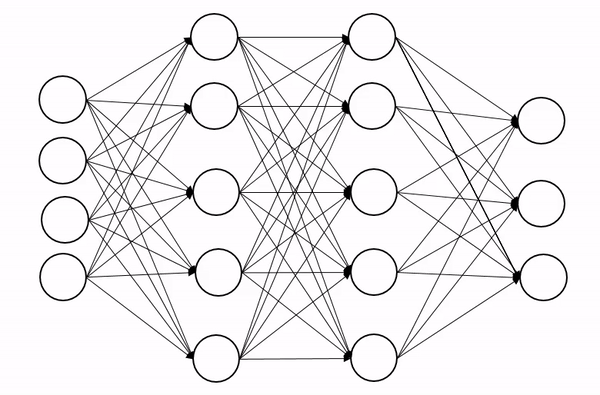
2.과대적합(Overfitting)
검증 결과 Train set에 대한 성능은 좋은데 Validation set에 대한 성능은 안좋은 상태로 모델이 학습을 과하게(overfitting)한 상태를 말한다.
이렇게 되면, 처음본 데이터에 대한 예측 성능이 떨어진다.
공부를 많이 하기는 했는데,문제를 푸는 것만 풀다 보니, 다른 문제가 나와버리면 약간 어리버리를 타는 개념이다.
3.과소적합(Underfitting)
검증 결과 Train set과 Validation set 모두 성능이 안좋은 상태로 모델의 학습이 덜(underfitting)된 상태를 말한다.
그냥 공부를 덜 한 것이다.....
따라서 과소적합의 경우에는 이런 정신이 필요하다.

(문제집을 부술 기세로~~)
아래는 이에 대한 설명을 보충해주는 이미지이다. 순서대로
일반화,과대적합,과소적합이다.
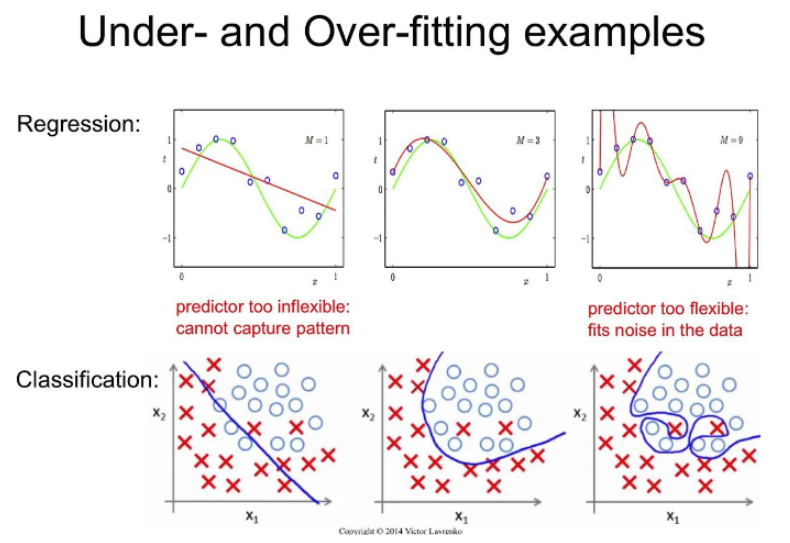
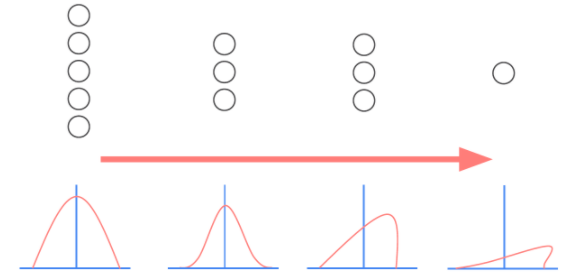
2.모델 복잡도에 따른 train/test set에 대한 성능 변화
왼쪽으로 갈수록 underfitting이고, 오른쪽으로 갈 수록 overfitting이다.
중간에 test data와 training data 둘 다 낮은 구간이 있는데,
우리는 이 구간을 찾아내야 한다.
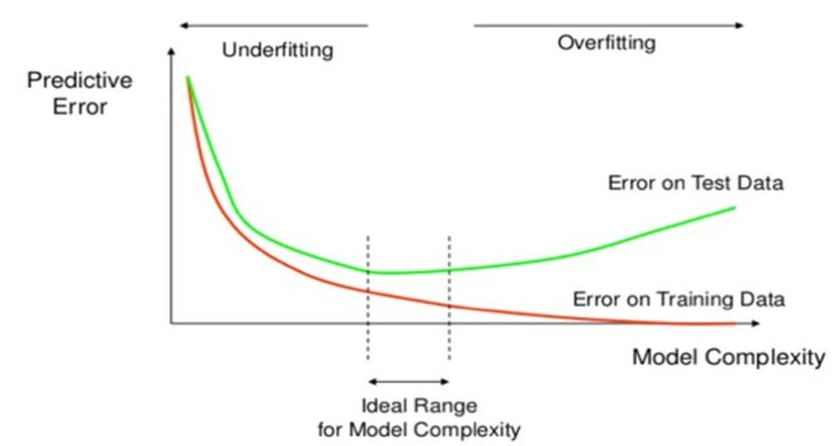
3.과소적합/과대적합 개선
아래의 설명 캡쳐본이 복잡하다면, 필자가 직관적인 해결책을 설명하겠다.
1.과소적합 개선
공부를 더 시킨다.
2.과대적합 개선
문제집을 더 산다.
간단하지?
....그래도 자세한 설명을 위해 이미지를 캡쳐해서 첨부하겠다.


이 외에도, epoch의 수를 적절하게 선정하는 것도 중요하다.
4.DNN 모델 크기 변경
앞서 이야기한 문제와 연관이 되어 있는 문제이기도 하다.
문제에 따라, 모델의 layer나 unit의 수를 적절하게 조절하는 것이 필요하다.
5.데이터와 모델의 특징

6.Dropout Layer 추가를 통한 Overfitting 규제
그런데, 잠시 생각해 보자.
Overfitting이 발생하는 이유가 뭘까?
그 이유는
모델이 너무 복합하니까!
이다. 간단하지?
공부를 하는데, 같은 내용을 공부하더라도 문제집이 설명을
개x만큼 해 놓은 것이다.
이를 개선하기 위해 dropout을 사용한다.
캡쳐 사진은 dropout에 대한 상세한 설명이다.

7.Dropout의 효과
Dropout은 overfitting의 원인인 co-adaptation 현상을 감소/방지하는 효과가 있다.
그래.... 그렇구나....
근데.... 용어가 어째 복잡하다.
그래서 준비했다.
필자가 강의를 dropout의 효과에 대해 어려운 용어를 쓰지 않고 정리한 내용이다.
#상세 설명
#예를 들어, 어떤 프로그램을 만든다고 치면, 어떤 사람은 프론트엔드를 하게 하고 어떤 사람은 백엔드를 공부하게 한다.
#이런걸 딥러닝에서는 '학습' 이라고 한다. 그렇게 하고, 그 사람들을 한데 묶어서 프로그램을 만들게 한다.
#근데 성과물이 잘 안나오면, 더 시간을 줘서 공부를 시킨다. 이게 바로 train을 반복하는 것이다.
#자, 근데, 여기서 따질 것이 있다.
"""
결과가 잘 안나오는 게 전체의 잘못일까?
그럴 수도 있지만... 어느 한 놈이 농땡이를 부렸을 가능성이 있다.
그래서 어느 부분이 잘못되었는지 그걸 세세하게 검증할 필요가 있다.
안그러면 연대책임이라는 군대식 용어를 다시 한번 꺼내야 하거든.
어떤 서람은 실책을 적게 냈을 것이고 어떤 사람은 실책을 많이 냈을 것이다.
실책을 적게 낸 사람은 그냥 내비두고 많이 낸 사람은 더 학습을 시키도록 조치를 취해야 할 것이다.
이게 바로 dropout layer의 역활이다.
그리고, 실책을 적게 낸 사람과 많이 낸 사람을 찾는 것이 dropout의 효과이다.
문제를 덜 일으킨 부분을 찾아야 하는데, 기계는 그걸 감으로 찍을 능력이 없으니,
데이터를 돌아가면서 검증을 시키는 것이다.
근데 일부분만 돌리다 보니, epoch이 평소보다 더 필요하다.
"""아래는 이와 관련된 캡쳐본이다.
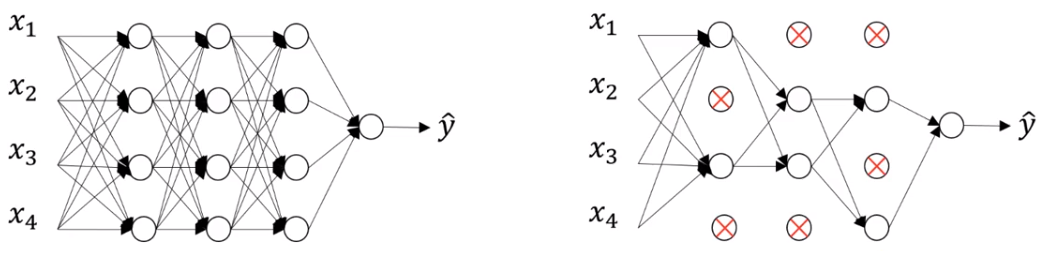
8.dropout의 적용
dropout은 학습시에만 적용을 하고, 검증,테스트,새로운 데이터 추론시에는 적용이 되지 않는다.
9.배치 정규화
배치 정규화는 각 Layer 에서 출력된 값을 평균=0, 표준편차=1로 정규화 하여 각 Layer의 입력분포를 균일하게 만들어 준다.
또한, batch 단위를 normalization을 하는 것이 바로 배치정규화이다.
이는 딥러닝을 방해하는 문제인 내부 공변량 문제 (Internal Covariate Shift)를 막기 위함이다.
10.내부 공변량 문제 (Internal Covariate Shift)
요상한(?)영어를 써서 그런지 약간 아리까리할 수도 있는데, 간단한 문제이다.
학습과정에서 각 층을 통과할 때 마다 입력 데이터 분포가 달라져서, 정규분포가 무너지는 문제이다. 이렇게 되면 엉뚱한 것을 학습하게 되는 가능성도 있다.

11.batch normalization의 효과
랜덤하게 생성되는 초기 가중치에 대한 영향력을 줄일 수 있다.
원래는 초기 가중치에 따라 성능차이가 나는 뭐같은 상황이 많았었는데, 이를 줄여준다.
학습하는 동안 과대적합에 대한 규제의 효과를 준다.
12.예시 코드
우선 관련 라이브러리들을 import한다.
import torch
import torch.nn as nn그런 다음,
임의의 tensor a와 이를 batch normalization을 한 b를 정의해 보자.
a = torch.rand(10,5) #(10-data수,5-feature수)
print(a)
#bn=batch normalization
bn = nn.BatchNorm1d(5)
#features => 1차원: BatchNorm1d(), 3차원(이미지)=>BatchNorm2d()
## BatchNorm1d(feature수)
## BatchNorm2d(channel수)
b = bn(a)결과는 다음과 같이 나온다.(a)
tensor([[0.2551, 0.3503, 0.8899, 0.6958, 0.4907],
[0.9337, 0.9639, 0.8402, 0.2269, 0.9163],
[0.2757, 0.7085, 0.7543, 0.3167, 0.7024],
[0.1504, 0.5733, 0.7742, 0.9999, 0.9557],
[0.6217, 0.5481, 0.9480, 0.6428, 0.4681],
[0.9676, 0.0757, 0.8692, 0.6167, 0.7341],
[0.2703, 0.0946, 0.0955, 0.8563, 0.0342],
[0.2439, 0.8385, 0.6496, 0.2585, 0.4532],
[0.4666, 0.5114, 0.1061, 0.5794, 0.5782],
[0.5809, 0.1372, 0.6164, 0.3077, 0.1401]])아래의 사진과 같이, a의 평균/표편과 b의 평균/표편을 비교하면 그 차이를 한눈에 볼 수 있다.
평균은 0에 가까워지고, 표준편차는 1에 가까워지는 것을 볼 수 있다.
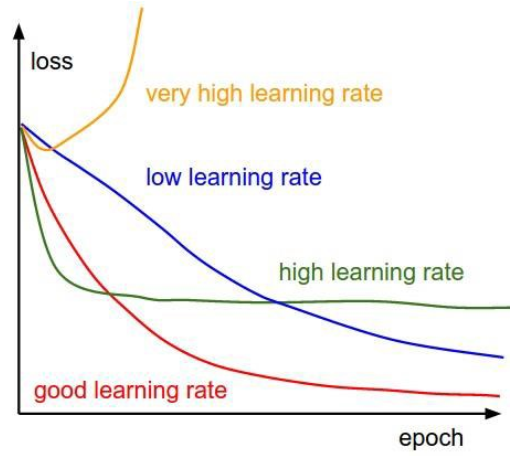
13.Optimizer의 Learning rate(학습율) 조정을 통한 성능향상
Optimizer의 Learning rate이 너무 크거나 너무 작으면 최적의 파라미터를 찾지 못할 수 있다. 그래서 Learning rate는 모델 성능과 밀접한 관계가 있는 아주 중요한 Hyper Parameter이다.
학습 하는 동안 고정된 하나의 Learning rate를 사용할 수도 있으나 학습이 반복되는 동안 학습률을 변경하여 성능을 향상시킬 수 있다.
학습 도중 학습률을 어떻게 조정할 지 다양한 알고리즘들이 있다.이와 관련된 것이 바로 hyper parameter tuning인데,
이는 아래 링크에 자세한 설명이 나와 있다.
아는 분의 블로그는 아니지만, 내용을 참고하고 엄청하게 많은 도움이 되었으니 여러분도 참고 바란다.
