Transfer Learning : 전이 학습
우수한 딥러닝 모델을 만들기 위해서는 많은 수의 데이터가 필수적입니다. 하지만 데이터의 수가 많지 않은 경우나 비용이 많이 드는 경우가 존재할 수 있습니다.
이를 해결하기 위한 방법이 Transfer Learning이며, 이는 특정 분야에서 학습된 신경망의 일부 능력을 유사하거나 전혀 새로운 분야에서 사용되는 신경망의 학습에 이용하는 방법입니다.
보통 전이학습에서 이용되는 학습된 신경망, 즉 pretrained model은 ImageNet, ResNet, gooGleNet 등이 있습니다. 대규모 데이터셋으로 잘 훈련된 이 pretrained model들을 통해 사용자가 적용하려는 문제에 맞게 모델의 가중치를 약간씩 변화하여 사용합니다. 아는 처음부터 가중치를 초기화하여 사용하는 것 보다 훨씬 우수한 성능을 나타냅니다.
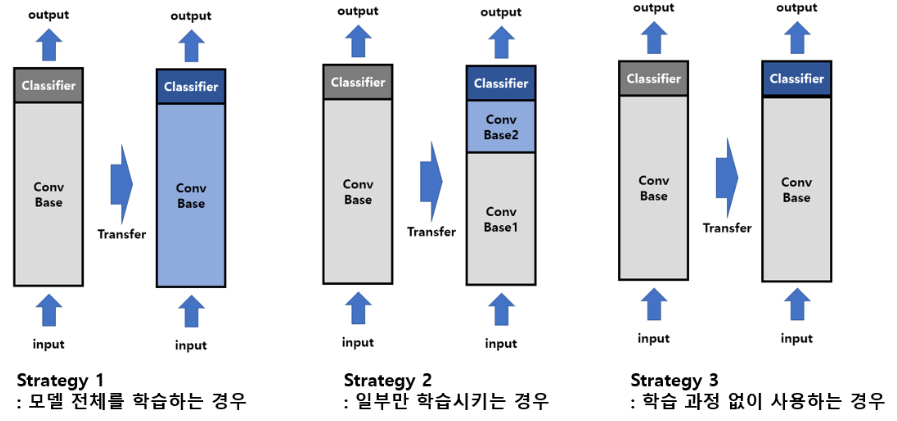
이렇게 pretrained model을 재정의했다면, 기존의 classifier는 삭제하고 목적에 맞는 새로운 classifier를 추가합니다. 이렇게 새롭게 만들어진 모델을 다음의 세 가지 전략을 이용하여 Fine-tuning을 진행하게됩니다.
Fine-tuning
Fine-tuning은 기존에 학습되어있는 모델을 기반으로 아키텍쳐를 새로운 목적에 맞게 변형하고 이미 학습된 모델의 가중치를 미세조정하여 학습시키는 방법을 말합니다.
즉, 모든 것을(미세하게) 업데이트 시키고, 임베딩까지 모두 업데이트하는 기법입니다.
-
전략1
모델 전체를 새로 학습
사전 학습 모델의 구조만 사용하면서, 자신의 데이터셋에 맞게 모델을 전부 새롭게 학습시키는 방법 -
전략2
base의 일부분 고정(Freezing), 나머지 계층과 Classifier를 새로 학습
Classifier는 주로 FC layer로 이루어져있으며, 알맞은 class로 classify하는 부분임
낮은 레벨의 계층은 일반적으로 독립적인 특징을 추출하고, 높은 라벨의 계층은 보다 구체적이고 명확한 특징을 추출함
이런 특징들을 고려하여 오느 정도까지 재학습시킬 것인지 정해야 함 -
전략3
Base는 아예 Freezing하고 Classifier만 새로 학습
데이터 셋이 기존 pretrained model의 데이터셋과 유사하거나, 데이터 셋이 너무 작을 때 사용
어떤 상황에 맞게 전략을 수립해야 할까?
-
상황 1 : 크기가 크고 유사성이 작은 데이터 셋일 때
이 경우 전략1을 사용합니다. 데이터셋의 크기가 크기기에, 모델을 처음부터 원하는대로 학습시키는 것이 가능하며 pretrained model의 구조만 사용합니다. -
상황 2 : 크기가 크고 유사성도 높은 데이터셋일 때
이 경우는 어떤 전략을 사용해도 무방하지만, 주로 전략2를 사용하는 것이 효과적입니다.
데이터 셋의 크기가 크기 때문에 과적합 현상은 문제가 되지 않지만, 데이터의 유사도가 높기에 굳이 처음부터 새롭게 학습시키지 않고 pretrained model이 이전에 학습한 지식을 활용하는 것이 효과적입니다. -
상황 3 : 크기가 작고 유사성도 작은 데이터셋일 때
가장 좋지 않은 상황입니다. 이런 경우에는 전략2를 사용하는데, 얼마나 Freezing시켜야 하는지 잘 조절해야 합니다. 너무 많은 계층을 학습시킨다면 과적합의 위험이 존재하고, 너무 적은 계층만 학습시킨다면 학습이 제대로 이루어지지 않기 때문입니다.
이러한 경우는 Data Augmentation을 사용해서 데이터 증강을 시키기도 합니다.
- 상황 4 : 크기는 작지만 유사성이 높은 데이터 셋일 때
이 경우는 전략3을 사용합니다. 유사도가 높기에 Classifier부분만을 변경하여 학습시킵니다.
Feature-based
이는 임베딩은 그대로 두고 그 위에 레이어만 학습하는 방법으로, 대표적으로 feature-based approach에는 ELMo가 포함됩니다.
이 Feature-based의 핵심은 "어떤 특정한 task를 해결하기 위한 architecture를 task specific하게 구성하고, 이것에 pre-trained representations(embedding layer)를 부가적인 feature로 사용" 하는 것 입니다.
BERT의 Experiments 부분에서 (Embedding만 사용, 두번째 부터 마지막 hidden을 사용, 마지막 hidden만 사용, 마지막 4개의 hidden의 가중합, 마지막 4개의 hidden을 concat, 모든 12개 층의 값을 가중합) 으로 feature-based approach가 사용되었으며 괜찮은 성능을 나타냈습니다.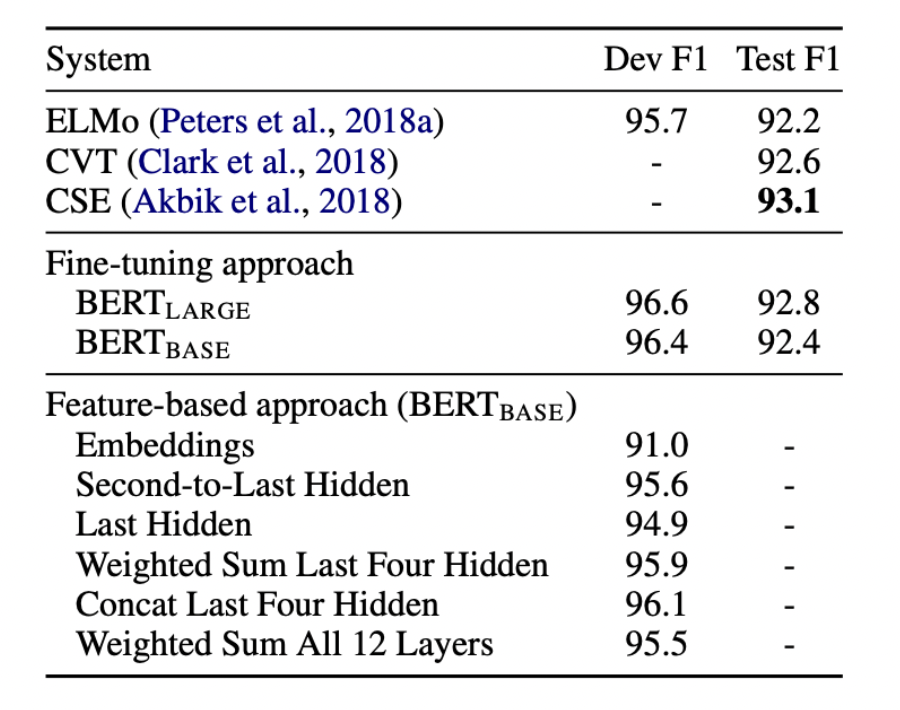
- 최근 트렌드는 fine-tuning으로 변화하고 있는데, 이에 대한 이유는 성능 뿐 아니라
위와 같이 모델 자체를 task에 맞게 변형시켜주는 feature-based에 비해 fine-tuning이 학습에 대한 cost가 비교적 낮기 때문이라고 말하며 포스터를 마치겠습니다!
