BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding

1. Introduction
Pre-Trianing에 관하여
Pre-training이란 무엇인가?
Language model에서 pre-training의 목표
1) unlabeled text corpora로부터 유용한 language representation을 배우는 것 입니다.
2) 결과적으로 pre-trained model은 downstram task(특정 task)에 대해 labeled 데이터를 추가로 학습하여 기존의 labeled data로 처음부터 학습한 모델 보다 더 나은 파라미터를 얻을 수 있습니다.(어느 정도 배운 기계에게 부탁하는 것이 빠르고 정확할 것)
=> Pre-training으로 인해 transfer learning을 진행하느 것이 좋은 성능을 발휘할 수 있으며, 이에 대한 효용성이 입증되고 있습니다. (맨 아래는 GPT-1)
기존 Pre-training 방법
주로 두 가지 접근법이 존재합니다.
-
feature-based approach (eg. ELMo)
downstream task를 위해서 학습을 할 때, 단순히 어떤 문장의 인코더로만 쓰입니다.
문장이 있으면 "문장 속에 있는 단어의 벡터를 뽑는 데만 쓰고" , 실제로 downstream task에 대해서 optimize를 할 때, ELMo 안의 파라미터는 변하지가 않습니다. 그래서 고려하는 것 들은 "단어의 벡터를 얻을 때 어떻게 얻어낼까? 모든 hidden layer를 concat할까? weight를 줘 볼까? 전부 더해볼까? " 정도의 고민만 합니다. 즉, 이 안의 구조를 변경하거나 파라미터가 변경되는 것을 원하지 않습니다. -
fine-tuning approach (eg. GPT-1)
각 downstream task에 맞게 input을 변경해주고, 사전 학습된 파라미터를 fine-tuning을 진행하기에 파라미터가 약간씩 변경이 됩니다.
=> "하지만 이 두 모델은 Pre-training의 최대 효용성을 끌어내기에는 부족하다" 라고 논문에서 말합니다.
Why?
1) GPT1 : Unidirectionality constraint
미래를 미리 내다볼 수 없다는 문제가 있습니다.
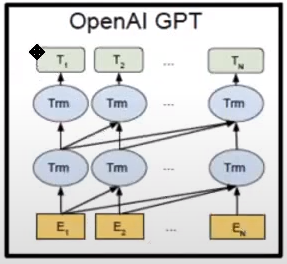
2) ELMo : Shallow bidirectionality
미래를 내다볼 수 있지만 너무 Shallow합니다.
엘모의 구조는 왼쪽에서 오른쪽으로 흐르는 LSTM과 오른쪽에서 왼쪽으로 흐르는 LSTM을 붙여서 마지막 output layer에서 FeedForword Network를 통해서 bidirectionality를 joint로 학습합니다.
하지만 내부에서는 왼->오 or 오->왼 으로 여전히 unidirectional합니다. 그렇기에 bidirectional하지만 shallow하다는 문제가 있습니다.
Bert
이러한 문제점을 해결하기 위해 Bidirectional Encoder Representation from Transformer : BERT 가 등장하게 됩니다.
GPT-1의 Unidirectionality constraint, ELMo의 Shallow bidirectionality 문제를 BERT는 "Masked Language Model(MLM)" 을 도입함으로써 해결합니다.
Masked Language Model을 통해 랜덤하게 입력 토큰의 일부를 마스킹 시키고, 해당 토큰이 구성하는 문장만을 기반으로 그 마스킹된 토큰들의 원래 값을 정확하게 예측합니다.
또한 MLM에서 text-pair representations로 pre-train을 진행하면, 인코더 기반임에도 "Next Sentence Prediction task"에서도 적용할 수 있다는 장점을 보유합니다.
결과적으로 7개의 task에 대해 우수한 성능을 보였으며, deep bidirectionality를 바탕으로 새로운 SOTA를 달성했습니다.
How?
Mask를 씌움으로 양쪽에서 다가와 학습합니다.

2. Related Work
우선 BERT를 이해하기 위한 내용(1) - Transfer learning, Fine-tuning, Feature-based 을 읽어보신다면 도움이 될 수 있습니다.
Related Work에서는 language representation을 pre-training하는 방법론들의 역사를 간략하게 이야기 합니다.
2.1 Unsupervised Feature-based Approaches
- 단어 혹은 문장의 representation 학습은 지속해서 진행되어 왔는데, 단어의 표현 학습은 크게 아래 두 가지 방식으로 구분합니다.
- non-neural 방식
- neural 방식(word2vec, Glove 등) - 이런 발전에 더불어, word embedding Pre-training이 NLP에서 중요한 문제로 자리잡았습니다.
- 또한 word embedding을 통한 접근 방식은 Sentence embedding or Paragraph embedding로 이루어졌습니다.
- sentence representation 학습 (BERT 이전까지)
- 1) 다음 문장의 후보들을 순위 메기는 방법- 2) 이전 문장이 주어졌을 때, 다음 문장의 left to right generation 방법
- 3) denoising auto-encoder에서 파생된 방법
- 차후 ELMo가 나와 전통적인 word embedding 연구에서 한 층 더 발전하였습니다.
- 2개의 biLM language model(left->right LM, right-left LM)을 이용하여(concat) 문맥을 고려한 단어 임베딩을 제공
2.2 Unsupervised Fine-tuning Approaches
최근에는 unlabeled text를 통해 pre-trained 된 contextual token representation을 생성하고, supervised downstream task에서 fine-tuning 하는 방식이 제안되었습니다.
이에 대한 장점은 시작부터 학습이 완료될 때 까지 적은 수의 파라미터가 학습된다는 것이며, 이를 기반으로 나온 것이 GPT입니다.
2.3 Transfer Learning from Supervised Data
큰 데이터 셋을 보유하고 있는 task들을 이용하여 transfer learning을 수행하는 방식도 존재하며, Computer vision 분야에서 transfer learning이 중요하게 사용되고 있습니다.
3. BERT
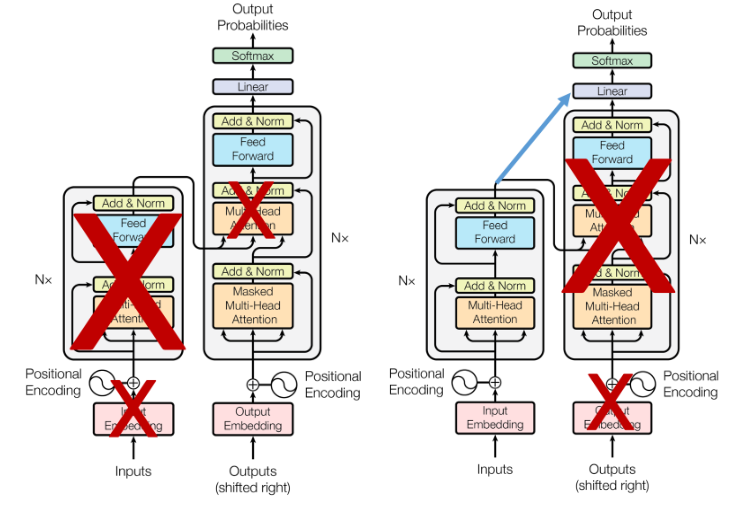
GPT1의 경우는 transformer의 디코더의 부분만 가져왔다면, BERT는 인코더를 가져와 쌓아올린 모델입니다.(base:12개, large:24개)
3.1 인코더라는 것은 무엇일까?
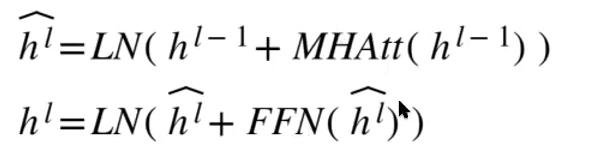
input -> embedding + positional encoding
-> MHAtt(h^(l-1)) : multi head attention (Deeply bidirectional & contextialised embedding(맥락이 반영된 임베딩)을 얻기 위함)
-> LN(x+f) : residual network & batch norm (모델이 깊어짐에 따라 발생하는 Vaninshing&Exploding Gradient 문제를 완화하기 위함: 이것이 있기에 안정적으로 깊게 쌓을 수 있음) - 첫 번째는 f에 MAtt, 두 번째는 FFN(FFN : position-wise feed forward network. Posisional embedding으로 놓칠 수 있는 혹은 bidirectional로 인해 놓칠 수 있는 position-wise 패턴 학습을 유도하기 위함(비선형성을 추가하고 모델의 표현력 향상))
3.2 BERT의 입력과 출력
입력은 전처리가 된 문장으로 들어오며, 출력으로 문장의 각 단어에 대응되는 Contextualised word embedding(각 단어 별 맥락이 반영된 벡터(~ , it 이라는 문장이 있을 때, it은 앞의 지칭 단어와 유사한 벡터를 띔))을 얻을 수 있습니다.
(Word2Vec 단어의 대응되는 벡터가 하나로 정해져 있기에 여러가지 맥락을 기준으로 단어를 하나의 벡터로 정한 것 : BERT는 주어진 맥락에서 이를 기준으로 벡터가 정해지는 것)
물론 ELMo도 이를 시도했지만, BERT는 Deeply bidirectioanl한 임베딩을 얻을 수 있습니다.
3.2.1 BERT 입력 전처리 : the tree embeddings
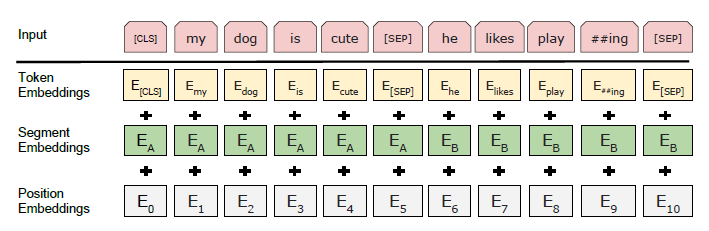
- BERT의 input은 3가지 embedding의 합으로 이루어져 있습니다.
- Token embeddings 는 각 토큰에 대한 정보를 제공합니다. 토큰화로는 WordPiece embedding을 사용합니다. (Subword Tokenization의 한 방법 : 한 단어를 쪼갤 수 있다면 이와 같이 쪼개는 것 playing->play##ing)- Segment embeddings 는 sentence pair를 구분지을 수 있는 정보를 제공합니다. 만약 문장이 하나만 들어간다면 sentence A embedding만 사용합니다.(첫 번째 문장은 A로 인코딩하고, 두 번째 문장은 B로 인코딩하여 문장을 구별함)
- MHatt은 Bidirectional하기 때문에 방향성이 없습니다. 그렇기에 방향성의 정보를 넣기 위해 Positional Embedding 을 추가로 더해줍니다.
3.2.2 BERT 입력 전처리 - the special tokens : CLS , SEP
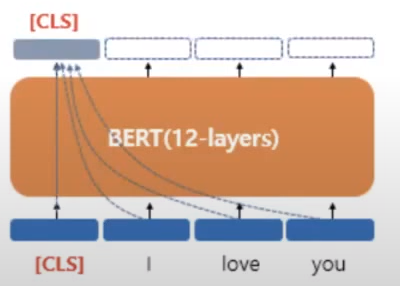
- CLS (id 101) : 모든 Sentence의 첫 번째 토큰은 언제나 CLS입니다. 이 첫 oken은 transformer 전체층을 다 거치고 나온 것으로, 전체 token sequence의 맥락이 반영된 벡터를 출력합니다. 이후 여기에 classifier를 붙이면 단일 문장 또는 연속된 문장의 classify를 할 수 있습니다.
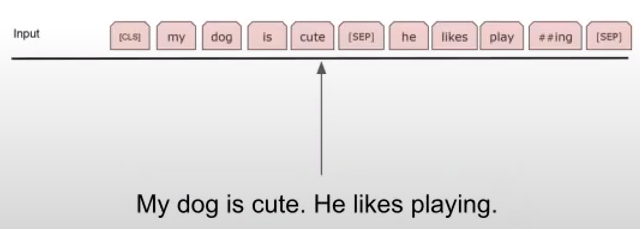
- SEP (id 102) : Segmentation Embedding과 함께 Sentence pair를 구분지을 수 있도록 SEP토큰을 Sentence Pair 속 두 문장의 사이에 넣어줍니다. 문장이 하나라면 문장의 끝에만 SEP를 넣습니다.
3.3 BERT의 훈련 과정
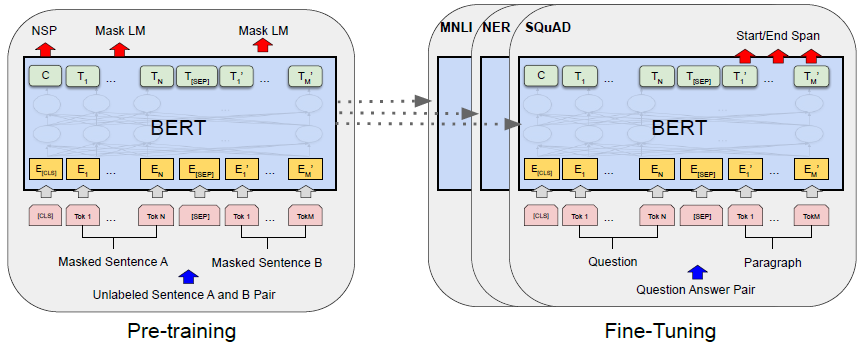
BERT의 훈련 과정은 Pre-training step과 Fine-tuning step으로 나뉩니다.
우선 Pre-training step에서 두 가지 task를 수행합니다.
1) Masked Language Modeling
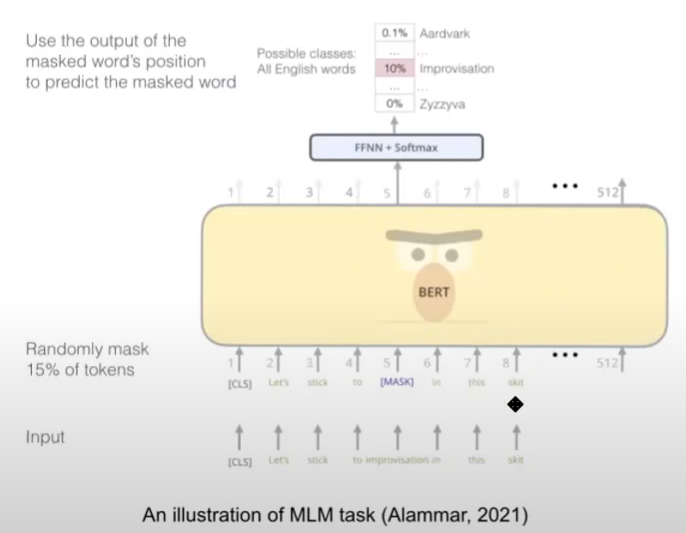 Masked Language Modeling의 목적은 "문장 내의 관계를 사전학습하기 위함" 입니다. 이에 대한 방법으로는 문장 속의 토큰을 15%정도 랜덤하게 mask하고, 마스킹된 토큰을 예측합니다.
Masked Language Modeling의 목적은 "문장 내의 관계를 사전학습하기 위함" 입니다. 이에 대한 방법으로는 문장 속의 토큰을 15%정도 랜덤하게 mask하고, 마스킹된 토큰을 예측합니다.
Masking된 벡터를 Feed Forward net을 씌우고, softmax를 취해 나온 모든 가능한 subword의 확률분포에 정답을 원핫벡터로 인코딩한 것이랑 cross entropy를 구해서 그 loss에 대해 backpropagation을 진행해서 학습을 진행시킵니다.
이 과정이 Masked Language Modeling이며, 12개의 레이어를 거치며 과거-미래를 모두 참조하여 가중치가 학습되기에, 이 task가 BERT의 사전 훈련이 deeply(모든 레이어에 대해 bidirectional) bidirectional(모든 정보를 얻을 수 있기에)하게 진행될 수 있는 이유입니다.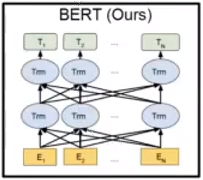
- Mask 15%?
전체 단어의 15%가 사용되는 것이지, 15%가 Masking되는 것이 아닙니다.
전체 단어의 15% = 12%(15% 중 80%인 전체 단어의 12%만 실제로 마스킹) + 1.5%(15%의 10% : SAME 그대로 둠) + 1.5%( Denoising taks : random하게 아무거나 넣어서 노이즈를 줌)
=> 1.5% 그냥 두는 이유?) fine-tuning에서는 MASK 토큰이 없기에 어느 정도는 그대로 두어야합니다. (실험을 통해 80/10/10 이 전반적으로 성능이 좋았기에 이 비율이 정해졌습니다. 가설들의 실험에 의한 결과로 절대적 비율은 아닙니다.)
여기서 한 가지 궁금한점이 생겼는데, 그렇다면 15%라는 비율은 어떻게 정해진 것인가?
: '계산 효율성을 유지하면서도 충분한 양의 마스킹을 제공하는 균형점' 정도로 대략적인 비율로 이해할 수 있을 것 같습니다.
2) Next Sentence Prediction
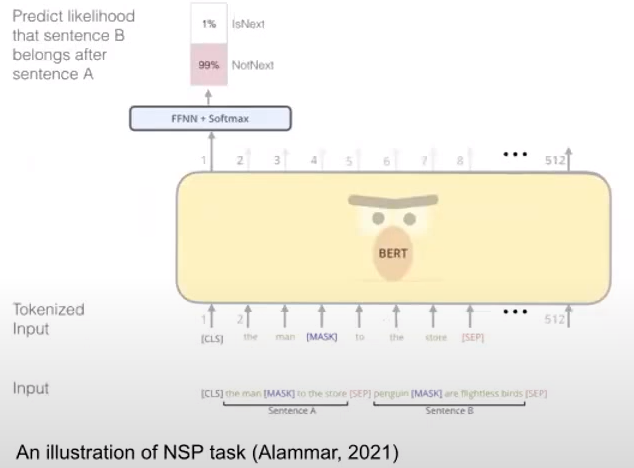
이에 대한 목적은 "inter-sentence relationship(문장과 문장 사이의 관계)을 사전학습" 하기 위함입니다. 방법으로는 두 문장을 이어 붙여서 이것이 원래의 corpus에서 바로 이어 붙여져 있던 문장인지 아닌지(IsNext or NotNext)를 맞추는 binarized next sentence prediction task를 수행합니다.
3.4 BERT의 Fine-tuning
BERT의 Pre-training을 마친 후 Fine-tuning을 하게 되는데, 목표로 하는 downstream에 맞게 미세 조정을 하게 됩니다.
각 task에 맞게 미세 조정하는 것이 GPT-1과 유사하지만, 가장 큰 차이로는 아래와 같이 BERT는 GPT-1과 달리 어떠한 task든지 상관 없이 일관된 구조로 진행됩니다.
이에 대한 장점은 downstream task가 달라짐에 따라 구조가 달리지고 randomly initialised weight가 달라붙는 GPT-1의 fine-tuning architecture와는 대조적이기에, 사전학습된 가중치를 더욱 효과적으로 활용할 수 있습니다.
- GPT-1
- BERT
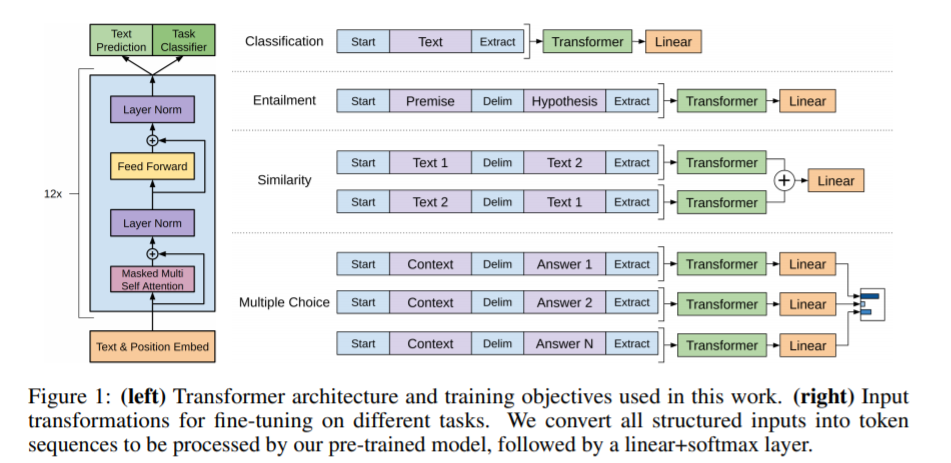
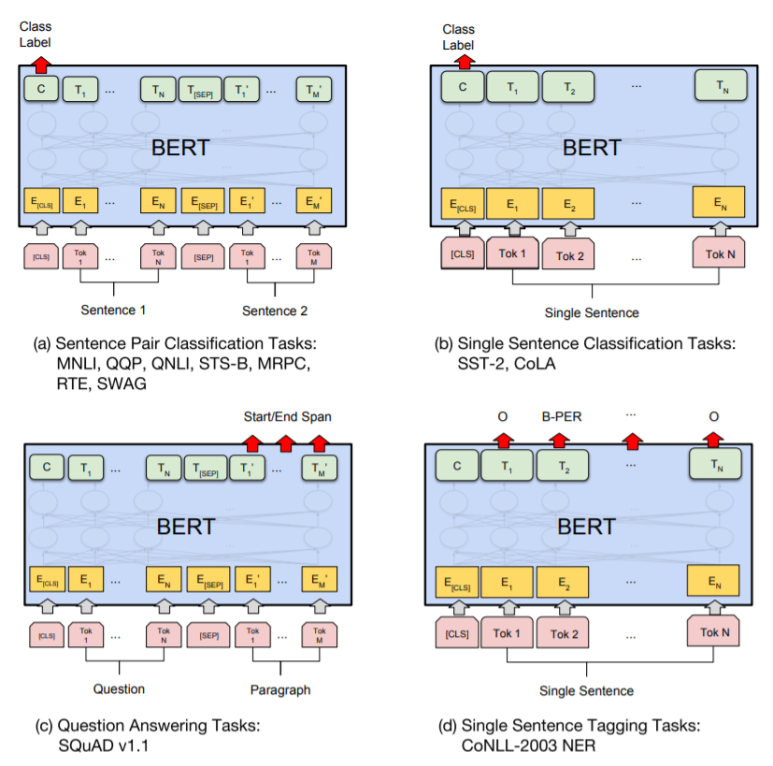
이 때, 수행학자 하는 downstream task에 따라 BERT는 task-specific input을 받고, 이로 fine-tuning을 진행합니다.
1) Sentence pairs in paraphrasing
2) Hypothesis-Premise pairs in entailment
3) Questoin-Passage pairs in question answering
4) Degenerate-None pair in text classification or sequence tagging
output역시 이에 따라 달라집니다.
token representation in sequence tagging or questoin answering
CLS representation in classification(entailment or sentiment analysis)
- 분류의 경우 classify의 개수 K에 따라 classification layer를 붙여줍니다.
(학습 시간 : TPU 1시간 , GPU 몇 시간)
4. Experiments
4.1 GLUE
4.1.1 GLUE Data set
총 9개의 data set 중 8개(CoLA, SST-2, MRPC, QQP, STS-B, MNLI, RTE, QNLI)
(WNLI 데이터셋은 채점에 문제가 있었기에 제외)
-
CoLA : Corpus of Linguistic Acceotability
공개된 언어학 문헌에서 추출된 약 21k 문장들로 구성되어 있으며, 각 문장들이 문법적으로 acceptable한지 unacceptable한지 분류하는 binary classificatoin 데이터 셋 입니다.
ex) many(->much) eividence was provided. : unacceptable -
SST-2 : Stanford Sentiment Treebank
Sentiment analysis(binary)로 rottentomatoes.com의 영화 리뷰 corpus로 긍정은 1 부정은 0을 나타내는 데이터 셋 입니다. -
MRPC
온라인 뉴스 소스에서 추출한 5800pair의 문장을 포함하는 데이터 셋으로, Sentimentic Textial similarity을 판단합니다. not_equivalent(0), equivalent(1)로 구분하고, 데이터 셋의 label 불균형(p 68 : n 32)으로 인해 accuracy와 F1 score를 metric으로 사용합니다. -
QQP : Quira Question Pairs
Paraphrase Identification(문맥인식), Natural Language Inference
두 개의 질문(q1, q2)이 의미상 같은지 혹은 다른지 표기되어 있는 데이터 셋 입니다. 이도 마찬가지로 데이터 셋의 label 불균형으로 인해 acc와 f1을 metric으로 사용합니다. -
STS-B : Semantic Textual Similarity Benchmark
문장 두 개가 있을 때, 두 문장의 의미적인 유사도를 1~5점으로 평가하는 regression task입니다. 즉, model은 score를 예측하는 regression을 진행합니다. -
MNLI : Multi-General NLI corpus
Natural Language Inference : 전제(P)가 주어졌을 때, 가설(H)이 참(entailment)인지 거짓(contradiction)인지 중립(neutral)인지 보는 것
test set에는 9/11 report, LETTERS 등의 training set에 없는 domain이 포함되어 있기에, 이를 넣었을 때의 score와 넣지 않았을 때의 score를 경우에 따라 구분합니다. -
RTE : Recognizing Textual Entailment
Natural Language Inference
NotEntail or Entail로 구분하는 binary classification task입니다. -
QNLI : The Stanford Question Answering NLI
Natural Language Inference
SQuAD 데이터 셋을 NLI에 맞게 변형시킨 데이터 셋입니다.
QNLI는 질문이 던져졌을 때, paragraph 내의 문장을 비교하여 entailment되었는지를 판단하는 binary classification을 수행합니다.
4.1.2 GLUE Benchmark - Fine-tuning
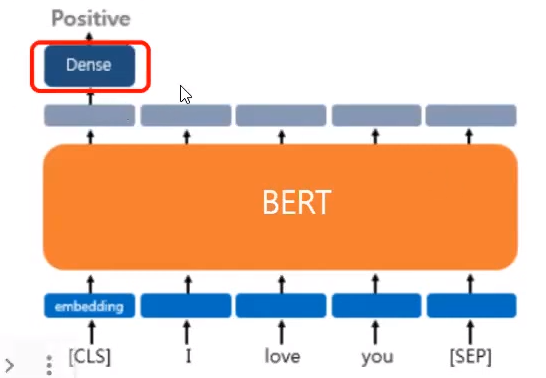
GLUE에서 fine-tuning 모델을 구축할 때, final hidden vector에서 "CLS"와 대응하는 representation 벡터 C의 값을 입력으로 사용합니다. 위에 classification layer를 하나 만들어줌으로써 사용합니다. 이 입력이 classification layer의 input으로 들어가게 됩니다.
 K : label의 수
K : label의 수
H : 마지막 transformer layer에서 hidden vector의 size
그 이후 Loss는 일반적인 classificaion loss (log(softmax(C·W^T))) 로 계산합니다.
아래를 예시로 들면 K=2, 이를 CLS토큰과 대응하는 representation에 넣고 P ro N을 판단합니다.
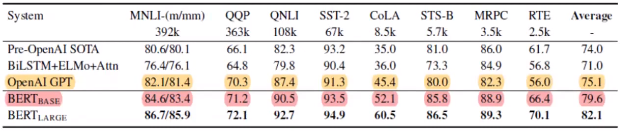
4.1.3 GLUE - Result
모든 task에 대해 SOTA를 달성하였고, 데이터 크기가 작아도 fine-tuning 때는 좋은 성능을 낼 수 있었습니다.
24층의 layer를 쓴 large model이 훨씬 좋은 성능을 냈습니다.
GPT와 BERT_base 모델을 비교했을 때, 비교를 위한 같은 파라미터 크기에도 불구하고 NLU task에서 더 좋은 성능을 확인할 수 있었습니다.(물론 Encoder 기반의 모델이기에 NLU에는 특화되어 있지만, NLG에는 특화되지 못 했습니다.)
4.2 SQuAD v1.1
Stanford Question Answering Dataset v1.1
passage(P)와 questoin(Q)이 주어지면 passage 내 정답을 포함하는 Answer(A)를 찾는 문제로 answer은 passage 내의 하위 sequence에 있습니다.
GLUE dataset의 경우에는 task가 sequence classification이지만, SQuAD는 질문과 지문이 주어진 후 이 중 substring인 정답을 맞추는 task입니다.
무조건 answerable하기에 classification인 CLS가 이용되지 않습니다.
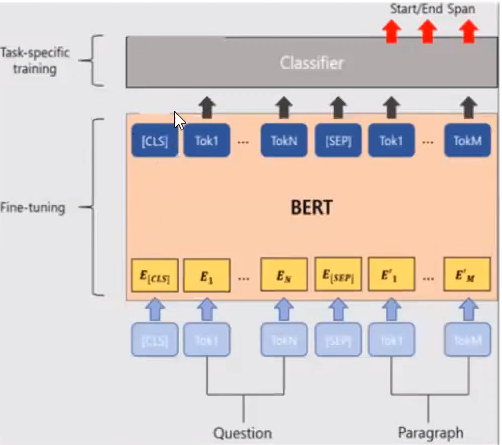
- 질문을 A embedding, 지문을 B embedding 으로 처리한 후, 지문에서 정답이 되는 substring의 처음과 끝을 찾는 task로 문제를 치환합니다.
- start vector S in R^H 와 end vector E in R^H를 fine-tuning중에 학습하며, 지문의 각 token들과 dotproduct하여 substring을 찾아냅니다.
How?) Pi = softmax(S·Ti) 를 이용하여 Start vector가 되는 token을 찾고, S 대신 E 벡터를 대입하여 End vector가 되는 Pj = softmax(E·Tj) token을 찾습니다. - score = (S·Ti + E·Tj)이며, s_(i,j) hat = max(S·Ti + E·Tj)로 Answer를 찾습니다.
- 이를 통해 Start span과 End span을 찾아냅니다.
4.3 SQuDA v2.0
v1.1에 새로운 5만개의 unanswerable questions를 human annotation을 통해 구성
v1.1과 달리 대답 불가능한 질문들이 포함되었기에 CLS token을 이용합니다.
Unansweralbe 의 값은 snull = S·C + E·C로,
Answeralbe 의 값은 v1.1과 동일하게 s(i,j) hat = max(S·Ti + E·Tj)로 계산합니다.
이 둘을 비교하여 두 값 중 더 큰 값에 따라 classify하게 됩니다.
s_(i,j) hat > s_null + τ
(threshold로 타우라는 상수가 추가됩니다. 논문에서는 F1socre를 최대로 만드는 값을 구해서 설정했다고 나와있습니다.)
성능이 굉장히 우수함을 확인할 수 있고, 아직은 사람에게까지는 못 미친다는 것을 확인할 수 있습니다.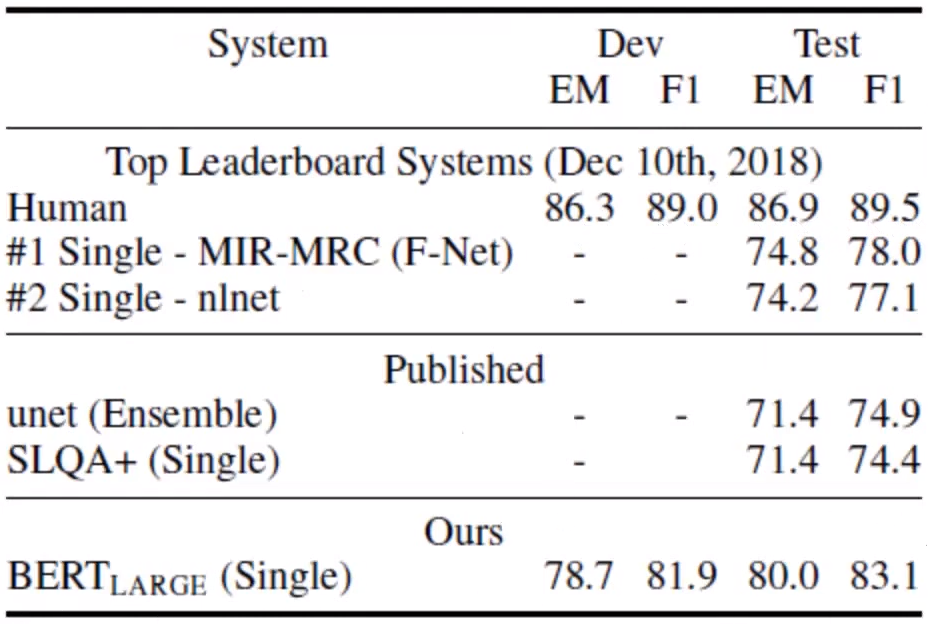
4.4 SWAG
The Situation With Adversarial Generations dataset
Common Sense Reasoning
현실적으로 근거있는 추론을 하는 성능을 확인하기 위함으로, 하나의 문장이 주어지고 보기의 4 문장 중 가장 잘 이어지는 문장을 찾는 task입니다.

이 task도 결국 4개 중 classify하는 것 이기에 GLUE와 유사했고, 보기가 4개 이기에 4개의 input sequences(concat(given sentence, possible continuation))를 구성 후 학습을 진행하였습니다.
CLS token에 대응하는 token C와 문장 이후에 나타나는 문장의 token에 dot product를 합니다. 이를 score로 삼고, softmax를 취해 normalize합니다. 이 확률을 이용한 classify로 가장 어울리는 문장을 찾게 됩니다.
전문가보다 좋은 성능을 보임을 확인할 수 있습니다.
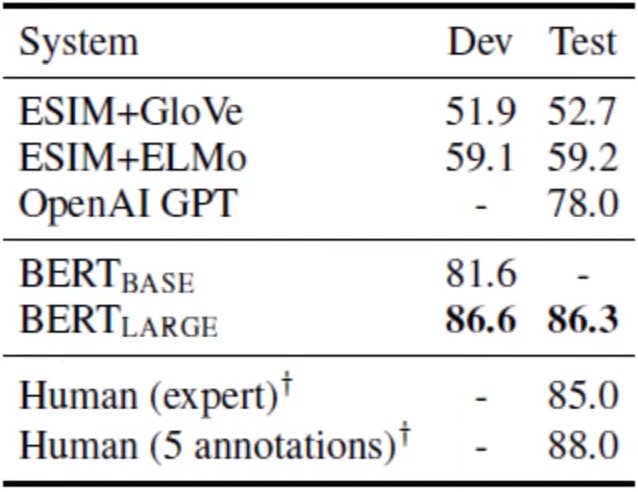
5. Ablation Studies
BERT의 구성요소들이 성능에 영향을 얼마나 미치는 지에 대한 실험으로, 제안한 요소가 모델에 어떠한 영향을 미치는 지 확인하고 싶을 때, 이 요소를 포함한 모델과 포함하지 않은 모델을 비교하는 것을 말합니다. 이는 딥러닝 연구에서 중요한 의미를 지니는데, 시스템의 인과관계(causality)를 간단히 알아볼 수 있기 때문입니다.
여기서는 크게 세 가지로 나누어 Ablation Study를 진행하였습니다.
5.1 Effect of Pre-training Task
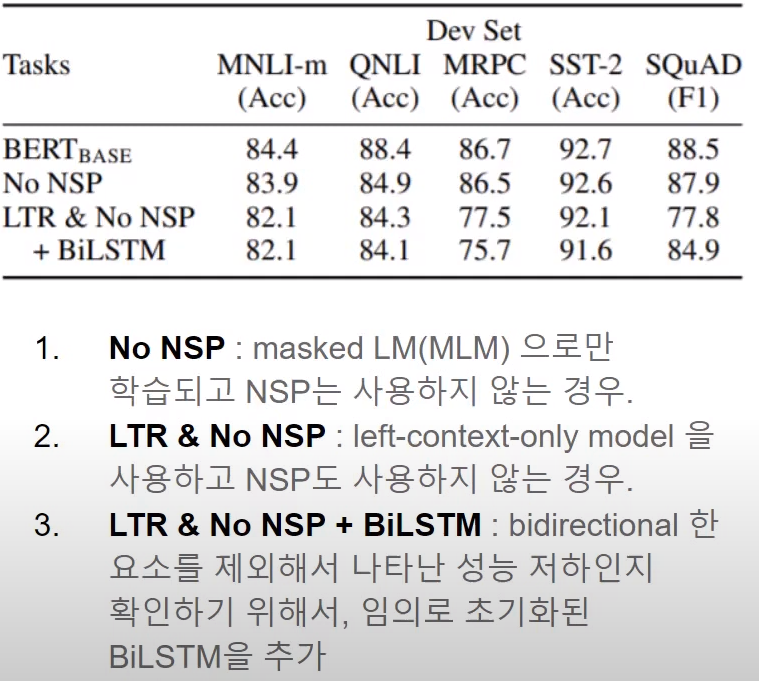
No NSP(Next Sentence Prediction)의 경우 성능이 떨어짐을 확인할 수 있습니다.
LTR을 사용한 경우 SQuAD에서 큰 폭으로 성능이 저하되었는데, Bidirectional 요소를 제거함으로 인한 결과인지를 확인하기 위해 BiLSTM을 추가해보았습니다. 그 결과 성능 향상을 보였습니다.
=> 그렇다면 ELMo를 사용하면 되지 않을까? 에 대한 답변으로는 LTR, RTR 모두 사용하지만 일부 layer에 대해서만 bidirectional하기 때문에 모든 layer에서 bidirectionality를 가지는 BERT에 비해서 QA와 같은 task에 적합하지 않습니다.
5.2 Effect of Model Size
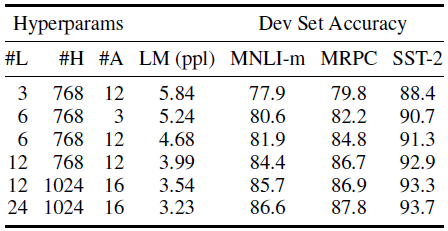
모델의 크기가 클 수록 좋은 성능을 띄고, MRPC같은 small scale task에 대해서도 모델의 크기가 클 수록 좋은 성능을 보였습니다.
++ 보통 Hidden dimension size의 크기를 늘리니 성능향상을 보였으나, 1000이상에는 그러지 않음 -> 하지만 BERT의 경우 1024에서도 성능 향상을 보였는데, 이는 Feature-based가 아닌 Fine-tuning을 사용으로 인한 결과라는 가설을 보였습니다.
5.3 Feature-based Approach with BERT
BERT를 feature-based 방식으로 사용
Encoder는 모든 task에 적용하지 못하기에 task-specific model을 추가하여 사용
(Embedding만 사용, 두번째 부터 마지막 hidden을 사용, 마지막 hidden만 사용, 마지막 4개의 hidden의 가중합, 마지막 4개의 hidden을 concat, 모든 12개 층의 값을 가중합)
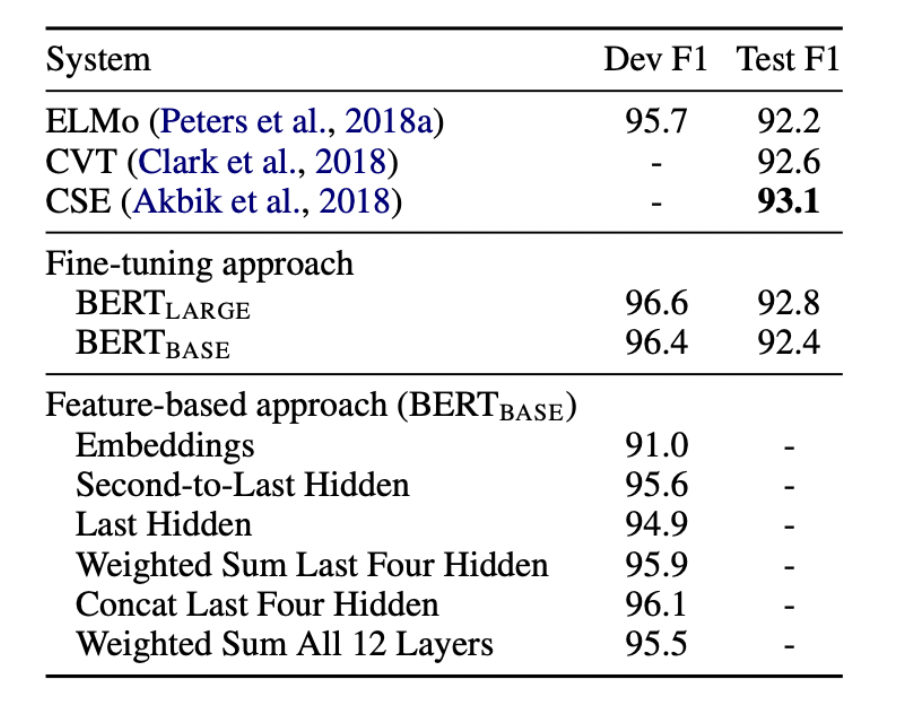
대부분 우수한 성능을 보이며, fine-tuning과 큰 차이가 없었습니다.
하지만 최근 트렌드가 fine-tuning으로 변화하는 이유는 성능 뿐 아니라
위와 같이 모델 자체를 task에 맞게 변형시켜주는 feature-based에 비해 학습에 대한 cost가 낮기 때문이라고 말하며 포스터를 마치겠습니다!
참고 : https://heeya-stupidbutstudying.tistory.com/entry/DL-Transfer-Learning-vs-Fine-tuning-%EA%B7%B8%EB%A6%AC%EA%B3%A0-Pre-training
https://misconstructed.tistory.com/43
https://www.youtube.com/watch?v=moCNw4j2Fkw&t=287s
